Риски выученной оптимизации
В этой цепочке приводится статья Эвана Хубингера, Криса ван Мервика, Владимира Микулика, Йоара Скалсе и Скотта Гаррабранта «Риски выученной оптимизации в продвинутых системах машинного обучения». Посты цепочки соответствуют разделам статьи.
Цель этой цепочки – проанализировать выученную оптимизацию, происходящую, когда обученная модель (например, нейронная сеть) сама является оптимизатором – ситуация, которую мы называем меса-оптимизацией – неологизмом, представленным в этой цепочке. Мы убеждены, что возможность меса-оптимизации поднимает два важных вопроса касательно безопасности и прозрачности продвинутых систем машинного обучения. Первый: в каких обстоятельствах обученная модель будет оптимизатором, включая те, когда не должна была им быть? Второй: когда обученная модель – оптимизатор, каковы будут её цели: как они будут расходиться с функцией оценки, которой она была обучена, и как можно её согласовать?
Риски выученной оптимизации. Введение
Это первый из пяти постов Цепочки «Риски выученной оптимизации», основанной на статье «Риски выученной оптимизации в продвинутых системах машинного обучения» за авторством Эвана Хубингера, Криса ван Мервика, Владимира Микулика, Йоара Скалсе и Скотта Гаррабранта. Посты цепочки соответствуют разделам статьи.
Эван Хубингер, Крис ван Мервик, Владимир Микулик и Йоар Скалсе в равной степени вложились в эту цепочку. Выражаем благодарность Полу Кристиано, Эрику Дрекслеру, Робу Бенсинджеру, Яну Лейке, Рохину Шаху, Вильяму Сандерсу, Бак Шлегерис, Дэвиду Далримпле, Абраму Демски, Стюарту Армстронгу, Линде Линсфорс, Карлу Шульману, Тоби Орду, Кейт Вулвертон и всем остальным, предоставлявшим обратную связь на ранние версии этой цепочки.
Мотивация
Цель этой цепочки – проанализировать выученную оптимизацию, происходящую, когда обученная модель (например, нейронная сеть) сама является оптимизатором – ситуация, которую мы называем меса-оптимизацией – неологизмом, представленным в этой цепочке. Мы убеждены, что возможность меса-оптимизации поднимает два важных вопроса касательно безопасности и прозрачности продвинутых систем машинного обучения. Первый: в каких обстоятельствах обученная модель будет оптимизатором, включая те, когда не должна была им быть? Второй: когда обученная модель – оптимизатор, каковы будут её цели: как они будут расходиться с функцией оценки, которой она была обучена, и как можно её согласовать?
Мы считаем, что эта цепочка представляет самый тщательный анализ этих вопросов на сегодняшний день. В частности, мы представляем не только введение в основные беспокойства по поводу меса-оптимизаторов, но и анализ конкретных аспектов ИИ-систем, которые, по нашему мнению, могут упростить или усложнить задачи, связанные с меса-оптимизацией. Предоставляя основу для понимания того, в какой степени различные ИИ-системы склонны быть устойчивыми к несогласованной меса-оптимизации, мы надеемся начать обсуждение о лучших способах структурирования систем машинного обучения для решения этих задач. Кроме того, в четвёртом посте мы представим пока что по нашему мнению самый детальный анализ проблемы, которую мы называем обманчивой согласованностью. Мы утверждаем, что она может быть одним из крупнейших – хоть и не обязательно непреодолимых – нынешних препятствий к созданию безопасных продвинутых систем машинного обучения с использованием технологий, похожих на современное машинное обучение.
Два вопроса
В машинном обучении мы не программируем вручную каждый отдельный параметр наших моделей. Вместо этого мы определяем целевую функцию, соответствующую тому, что мы хотим, чтобы система делала, и обучающий алгоритм, оптимизирующий систему под эту цель. В этом посте мы представляем подход, который различает то, для чего система была оптимизирована (её «назначение») и то, что она оптимизирует (её «цель»), если она это делает. Хоть все ИИ-системы оптимизированы для чего-то (имеют назначение), оптимизируют ли они что-то (преследуют ли цель) – неочевидно. Мы скажем, что система является оптимизатором, если она производит внутренний поиск в пространстве возможностей (состоящем из выводов, политик, планов, стратегий, или чего-то в этом роде) элементов, высоко оцениваемых некой целевой функцией, явно отображённой внутри системы. Обучающие алгоритмы машинного обучения – оптимизаторы, поскольку они ищут в пространстве возможных параметров, например, весов нейросети, и подгоняют их для некой цели. Планирующие алгоритмы – тоже оптимизаторы, поскольку они ищут среди возможных планов подходящие под цель.
Является ли система оптимизатором – свойство её внутренней структуры, того, какой алгоритм она на самом деле реализует, а не свойство её поведения ввода-вывода. Важно, что лишь то, что поведение системы приводит к максимизации некой цели не делает её оптимизатором. К примеру, крышка бутылки заставляет воду оставаться в бутылке, но не оптимизирует этот исход, поскольку не выполняет никакого оптимизационного алгоритма.(1) Скорее, крышка бутылки была оптимизирована для удерживания воды. Оптимизатор тут – человек, который спроектировал крышку, выполнив поиск в пространстве возможных инструментов для успешного удерживания воды в бутылке. Аналогично, классифицирующие изображения нейросети оптимизированы для низкой ошибки своих классификаций, но, в общем случае, не выполняют оптимизацию сами.
Однако, для нейросети также возможно и самой выполнять алгоритм оптимизации. К примеру, нейросеть может выполнять алгоритм планирования, предсказывающий исходы потенциальных планов и отбирающий те, которые приведут к желаемым исходам.1 Такая нейросеть будет оптимизатором, поскольку она ищет в пространстве возможных планов согласно с некой целевой функцией. Если такая нейросеть появилась в результате обучения, то оптимизатора два: обучающий алгоритм – базовый оптимизатор, и сама нейросеть – меса-оптимизатор.2
Возможность возникновения меса-оптимизаторов несёт важные следствия касательно безопасности продвинутых систем машинного обучения. Когда базовый оптимизатор генерирует меса-оптимизатор, свойства безопасности цели базового оптимизатора могут не передаться меса-оптимизатору. Мы исследуем два основных вопроса, связанных с безопасностью меса-оптимизаторов:
- Меса-оптимизация: В каких обстоятельствах обученные алгоритмы будут оптимизаторами?
- Внутреннее согласование: Когда обученный алгоритм – оптимизатор, каковы будут его цели и как его можно согласовать?
Представив наш подход в этом посте, мы потом обратимся к первому вопросу во втором посте, потом к второму вопросу в третьем, и, наконец, погрузимся глубже в конкретные аспекты второго вопроса в четвёртом посте.
1.1. Базовые оптимизаторы и меса-оптимизаторы
Обычно базовым оптимизатором в машинном обучении является какая-нибудь разновидность процесса градиентного спуска с целью создания модели для достижения некой определённой цели.
Иногда этот процесс также в некоторой степени включает мета-оптимизацию, где задача мета-оптимизатора – произвести базовый оптимизатор, хорошо оптимизирующий системы для достижения конкретных целей. В целом, мы будем считать мета-оптимизатором любую систему, чья задача – оптимизация. К примеру, мы можем спроектировать мета-обучающую систему для помощи в настройке нашего процесса градиентного спуска.(4) Найденную мета-оптимизацией модель можно считать разновидностью выучившегося оптимизатора, но это не тот случай, в котором мы тут заинтересованы. Мы озабочены другой формой выученной оптимизации, которую мы называем меса-оптимизацией.
Меса-оптимизация – концепт, парный мета-оптимизации: тогда как мета – это «над» по-гречески, меса – «под».3 Меса-оптимизация происходит когда базовый оптимизатор (в поиске алгоритма для решения некой задачи) находит модель, которая сама является оптимизатором – меса-оптимизатор. В отличии от мета-оптимизации, чьей задачей служит сама оптимизация, понятие меса-оптимизации независимо от задачи, и просто относится к любой ситуации, в которой внутренняя структура модели выполняет оптимизацию из-за того, что та инструментально полезно для решения имеющейся задачи.
В таком случае мы будем называть базовой целью критерий, который использовал базовый оптимизатор для выбора между разными возможными системами, а меса-целью критерий, который использует меса-оптимизатор для выбора между разными возможными выводами. Например, в обучении с подкреплением (RL), базовая цель – это, обычно, ожидаемая награда. В отличии от базовой цели, меса-цель не задаётся программистами напрямую. Скорее, это просто та цель, которая, как обнаружил базовый оптимизатор, приводит к хорошим результатам в тренировочном окружении. Раз меса-цель не определяется программистами, меса-оптимизация открывает возможность несовпадения между базовой и меса- целями, когда меса-цель может казаться хорошо работающей в тренировочном окружении, но приводит к плохим результатам извне его. Мы будем называть такой случай псевдо-согласованностью.
Меса-цель не обязана быть всегда, потому что алгоритм, обнаруженный базовым оптимизатором не всегда сам выполняет оптимизацию. Так что в общем случае мы будем называть сгенерированную базовым оптимизатором модель обученным алгоритмом, который может быть или не быть меса-оптимизатором.
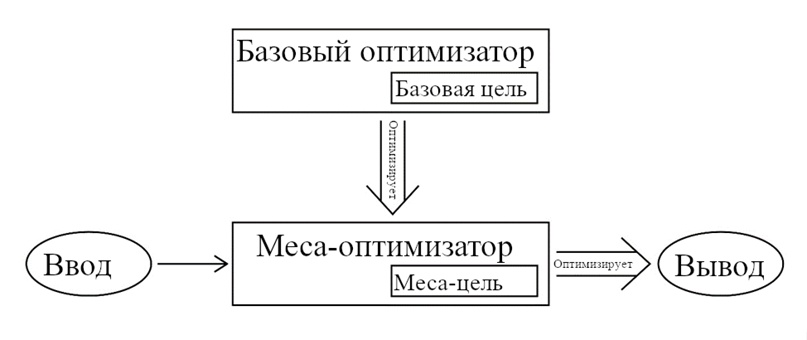
Рисунок 1.1. Отношение между базовым и меса- оптимизаторами. Базовый оптимизатор оптимизирует обученный алгоритм на основе его выполнения базовой цели. Для этого базовый оптимизатор может превратить обученный алгоритм в меса-оптимизатор, в это случае меса-оптимизатор сам выполняет алгоритм оптимизации, основываясь на своей собственной меса-цели. В любом случае, именно обученный алгоритм напрямую совершает действия, основываясь на своём вводе.
Возможное недопонимание: «меса-оптимизатор» не значит «подсистема» или «субагент». В контексте глубинного обучения меса-оптимизатор – это нейросеть, выполняющая некий процесс оптимизации, не какой-то образовавшийся субагент внутри этой нейросети. Меса-оптимизаторы – конкретный тип алгоритмов, которые может выбрать базовый оптимизатор для решения своей задачи. Также, базовый оптимизатор – алгоритм оптимизации, а не интеллектуальный агент, решивший создать субагента.4
Мы различаем меса-цель и связанное понятие поведенческой цели. Неформально можно сказать, что это то, что оптимизируется поведением системы. Можно определить её как цель, восстановленную идеальным обратным обучением с подкреплением (IRL).5 Это не то же самое, что меса-цель, которую активно использует меса-оптимизатор в своём алгоритме оптимизации.
Можно посчитать, что любая возможная система имеет поведенческую цель – включая кирпичи и крышки бутылок. Однако, для не-оптимизаторов подходящая поведенческая цель может быть просто «1, если это действие, которое на самом деле совершает система, иначе 0».6 Знать, что система действует, оптимизируя такую цель – и не интересно, и бесполезно. В примеру, поведенческая цель, «оптимизированная» крышкой бутылки – вести себя как крышка бутылки.7 А вот если система – оптимизатор, то она вероятно будет иметь осмысленную поведенческую цель. Так что в той степени, в которой вывод меса-оптимизатора систематически отбирается для оптимизации его меса-цели, его поведение может выглядеть как последовательные попытки повлиять на мир в конкретном направлении.8
Меса-цель конкретного меса-оптимизатора полностью определяется его внутренней работой. По окончании обучения и выбору обученного алгоритма, его прямой вывод – например, действия, предпринимаемые RL-агентом – больше не зависят от базовой цели. Так что поведенческая цель меса-оптимизатора определяется его меса-целью, а не базовой. Конечно, в той степени, в которой обученный алгоритм был отобран на основе базовой цели, его вывод будет хорошо под неё подходить. Однако, в случае сдвига распределения входных данных стоит ожидать, что поведение меса-оптимизатора будет устойчивее оптимизировать меса-цель, поскольку вычисление его поведения напрямую соответствует ей.
Как пример для иллюстрации различия базового/меса в другой области и возможность несогласованности базовой и меса- целей, рассмотрим биологическую эволюцию. В первом приближении, эволюция отбирает организмы соответственно целевой функции их совокупной генетической приспособленности в их окружении.9 Большинство этих биологических организмов – к примеру, растения – не «пытаются» ничего достичь, а просто исполняют эвристики, заранее выбранные эволюцией. Однако, некоторые организмы, такие как люди, обладают поведением, которое не состоит лишь из таких эвристик, а вместо этого является результатом целенаправленных оптимизационных алгоритмов, исполняемых в мозгах таких организмов. Поэтому эти организмы могут демонстрировать совершенно новое с точки зрения эволюционного процесса поведение, вроде людей, создающих компьютеры.
Однако, люди не склонны присваивать явную ценность цели эволюции – по крайней мере в терминах заботы о частоте своих аллелей в популяции. Целевая функция, хранящаяся в мозгу человека не та же, что целевая функция эволюции. Так что, когда люди проявляют новое поведение, оптимизированное для их собственных целей, они могут очень плохо выполнять цель эволюции. Один из возможных примеров – принятие решения не иметь детей. Таким образом, мы можем думать о эволюции как о базовом оптимизаторе, который создал мозги – меса-оптимизаторы, которые создают поведение организмов, не обязательно согласованное с эволюцией.
1.2. Задачи внутреннего и внешнего согласования
В «Масштабируемом согласовании агентов с помощью моделирования наград» Лейке и пр. описали концепт «расхождение награда-результат» как разницу между (в их случае обученной) «модели награждения» (то, что мы называем базовой целью) и «функции вознаграждения, восстановленной идеальным обратным обучением с подкреплением» (то, что мы называем поведенческой целью).(8) Проще говоря, может быть разница между тем, что обученный алгоритм делает и тем, что программисты хотят, чтобы он делал.
Проблема несогласованных меса-оптимизаторов – разновидность расхождения награда-результат. Конкретнее, это расхождение между базовой и меса- целями (которое затем приводит к расхождению базовой и поведенческой целей). Мы назовём задачу устранения этого расхождения задачей внутреннего согласования, в противовес задаче внешнего согласования – устранения расхождения базовой цели с намерениями программистов. Эта терминология обусловлена тем, что задача внутреннего согласования проявляется внутри системы машинного обучения, тогда как задача внешнего согласования – между системой и людьми. В контексте машинного обучения внешнее согласование – это приведение функции оценки в соответствие поставленной цели, а внутреннее согласование – это приведение меса-цели меса-оптимизатора в соответствие с функцией оценки.
Может быть, что решение внутреннего согласования не обязательно для создания безопасных мощных ИИ-систем, так как может оказаться возможным предотвратить появление меса-оптимизаторов. Если же меса-оптимизаторов нельзя надёжно избежать, то для уверенности в том, что меса-оптимизаторы согласованы с намерениями программистов, необходимы будут какие-нибудь решения и задачи внешнего, и задачи внутреннего согласования.
1.3. Устойчивая согласованность и псевдо-согласованность
При достаточном обучении меса-оптимизатор должен однажды стать способен производить вывод, высокооцениваемый базовой целью на обучающем распределении. Однако, вне него – и даже внутри на ранних этапах процесса обучения – могут быть сколь угодно большие различия. Мы будем называть устойчиво согласованными меса-оптимизаторы с меса-целями, устойчиво совпадающими с базовыми целями в разных распределениях, и псевдо-согласованными меса-оптимизаторы с меса-целями, совпадающими с базовыми целями на прошлых обучающих данных, но не совпадающими устойчиво на возможных будущих данных (при тестировании, разворачивании или дальнейшем обучении). Для псевдо-согласованного меса-оптимизатора существуют окружения, в которых базовые и меса- цели расходятся. Псевдо-согласованность, таким образом, представляет потенциально опасную проблему, поскольку открывает возможность того, что вне своего обучающего распределения система машинного обучения будет компетентно предпринимать действия для достижения чего-то, что не является её предполагаемой целью. То есть, может случиться так, что её способности обобщились, а цели – нет.
Как игрушечный пример того, как может выглядеть псевдо-согласованность, рассмотрим RL-агента, обученного задаче находить путь в лабиринте, все двери в котором при обучении оказались красными. Пусть базовая цель (функция вознаграждения) будет Obase = {1, если достиг двери, иначе 0}. На обучающем распределении это цель эквивалентна Oalt = {1, если достиг чего-то красного, иначе 0}. Представим, что произойдёт, если агент, обученный высоким результатам по Obase будет помещён в окружение, где двери синие, а какие-то другие объекты – красные. Он может обобщить Obase, надёжно находя путь к синей двери (устойчивая согласованность). Но он также может обобщить Oalt вместо Obase, надёжно находя путь к красным объектам (псевдо-согласованность).10
1.4. Меса-оптимизация как проблема безопасности
Если, как мы предположили, в продвинутых системах машинного обучения могут возникнуть меса-оптимизаторы, то из этого вытекает две критических проблемы безопасности.
Ненамеренная оптимизация. Во-первых, возможность возникновения меса-оптимизаторов означает, что продвинутая система машинного обучения может выполнять мощную процедуру оптимизации при том, что её программисты никогда он неё этого не хотели. Это может быть опасным, если такая оптимизация приводит к тому, что система совершает внешние действия за пределами предполагаемого поведения в попытке максимизировать свою меса-цель. Особое беспокойство вызывают оптимизаторы, чьи целевые функции и процедуры оптимизации обобщаются на реальный мир. При этом условия, приводящие к нахождению обучающим алгоритмом меса-оптимизаторов, очень слабо изучены. Их знание позволило бы нам предсказывать случаи, в которых меса-оптимизация более вероятна, и предпринимать меры против её появления. Во втором посте мы рассмотрим некоторые свойства алгоритмов машинного обучения, которые могут влиять на вероятность нахождения меса-оптимизаторов.
Внутреннее согласование. Во-вторых, даже в случаях, когда нахождение базовым оптимизатором меса-оптимизатора приемлемо, меса-оптимизатор может оптимизировать что-то не являющееся заданной функцией вознаграждения. В таком случае он может приводить к плохому поведению даже если известно, что оптимизация корректной функции вознаграждения безопасна. Это может произойти либо во время обучения – до момента, когда меса-оптимизатор станет согласованным по обучающему распределению – или во время тестирования или развёртки, когда система действует снаружи обучающего распределения. В третьем посте мы затронем некоторые случаи того, как может быть выбран меса-оптимизатор, оптимизирующий не заданную функцию вознаграждения, и то, какие свойства систем машинного обучения этому способствуют. В четвёртом посте мы обсудим возможные крайние случаи провала внутреннего согласования – которое, по нашему мнению, является источником некоторых из самых опасных рисков в этой области – когда достаточно способный меса-оптимизатор может научиться вести себя так, будто он согласован, не будучи на самом деле устойчиво согласованным. Мы будем называть эту ситуацию обманчивой согласованностью.
Может оказаться, что проблема псевдосогласованных меса-оптимизаторов решается легко – если существует надёжный метод их согласования, или предотвращения нахождения их базовыми оптимизаторами. Однако, может оказаться и так, что решить её очень сложно – пока что мы недостаточно хорошо её понимаем, чтобы знать точно. Конечно, нынешние системы машинного обучения не приводят к появлению опасных меса-оптимизаторов, но будет ли это так же с будущими системами – неизвестно. Эта неизвестность убеждает нас в том, что важно проанализировать эту проблему.
- 1. Как конкретный пример нейросетевого оптимизатора можно рассмотреть TreeQN.(2) По описанию Фаркухара и пр. TreeQN – агент Q-обучения, выполняющий основанное на модели планирование (поиском по дереву отображающему состояния окружения) как часть своего вычисления Q-функции. Хоть их агент и должен быть оптимизатором по задумке, можно представить, как похожему алгоритму может научиться DQN-агент с достаточно выразительным аппроксиматором Q-функции. Универсальные Планирующие Сети, описанные Сринивасом и пр.(3) предоставляют другой пример обученной системы, выполняющей оптимизацию, пусть эта оптимизация и встроена в виде стохастического градиентного спуска с помощью автоматического дифференцирования. Такие исследования как Андриковица и пр.(4) и Дуана и пр.(5) демонстрируют, что алгоритмы оптимизации могут быть выучены рекуррентными нейронными сетями, так что агент похожий на Универсальные Планирующие Сети может – при условии очень выразительного пространства моделей – быть обученным целиком, включая внутреннюю оптимизацию. Заметим, что хоть эти примеры и взяты из обучения с подкреплением, оптимизация в принципе может возникнуть в любой достаточно выразительной система обучения.
- 2. Предыдущие работы в этой области часто сосредотачивались на концепте «оптимизационных даймонов», (6) мы считаем, что это потенциально заблуждающий подход, и надеемся его заменить. Отметим, что термин «оптимизационные даймоны» произошёл из дискуссий касательно природу людей и эволюции, так что стал нести антропоморфические коннотации.
- 3. «Меса» предложено как противоположность «мета».(7) Дуальность исходит из рассмотрения мета-оптимизации как лежащей на уровень выше базового оптимизатора, а меса-оптимизации – на уровень ниже.
- 4. Хотя некоторые наши соображения применимы и к этому.
- 5. Лейке и пр.(8) представили концепт цели, восстановленной из идеального IRL.
- 6. Для формального построения цели см. стр. 6 в Лейке и пр.(8)
- 7. Эта цель по определению тривиально оптимальна в любой ситуации, в которой может оказаться крышка.
- 8. Наше основное беспокойство касается оптимизации в направлении некой последовательной но небезопасной цели. В этой цепочки мы предполагаем, что поиск предоставляет достаточную структуру для ожидания последовательных целей. Хоть мы и считаем это разумным предположением, необходимость и достаточность поиска неясны. Скорее всего для прояснения потребуется дальшейшая работа.
- 9. Ситуация с эволюцией более сложна, чем представлено тут, и мы не ожидаем, что наша аналогия переживёт тщательный разбор. Пре представляем её именно как выразительную аналогию (и, в некоторой степени, доказательство существования), объясняющую ключевые концепты. Более аккуратные аргументы будут представлены позже.
- 10. Конечно, он может и вовсе не обобщиться.
Условия меса-оптимизации
В этом посте мы рассмотрим, как на вероятность того, что обучающая система создаст меса-оптимизатор, влияют два её компонента:
- Задача: Обучающее распределение и базовая целевая функция.
- Базовый оптимизатор: Алгоритм машинного обучения и архитектура модели.
Мы намеренно выбрали представить теоретические соображения о том, почему меса-оптимизаторы могут возникнуть или не возникнуть, а не конкретные примеры. Меса-оптимизация – это явление, которое, по нашему убеждению, в основном будет происходить в более продвинутых, чем нынешние, системах машинного обучения.1 Попытка вызвать меса-оптимизацию в нынешней системе машинного обучения скорее всего потребует использования специально спроектированных для этого настроек. Более того, ограниченная интерпретируемость нейросетей, вместе с отсутствием общего и точного определения «оптимизатора», означает, что оценить, является ли данная модель меса-оптимизатором, было бы сложно.
2.1. Задача
Некоторые задачи получают большую выгоду от меса-оптимизации, чем другие. К примеру, крестики-нолики идеально решаются простыми правилами. Так что базовому оптимизатору нет нужны генерировать меса-оптимизатор для решения крестиков-ноликов, поскольку для этого достаточно простого обученного алгоритма, усвоившего правила идеальной игры. Выживание человека в саванне, напротив, кажется получающим большую выгоду от меса-оптимизации. Ниже мы обсудим свойства задач, влияющие на вероятность меса-оптимизации.
Лучшее обобщение через поиск. Мы выдвигаем следующую гипотезу: «Чтобы найти способ стабильно справляться с задачей в окружении на некотором уровне качества, необходимо некоторое минимальное количество силы оптимизации.»
Силу оптимизации можно измерять количеством делений пополам пространства поиска – количеством бит информации, которое он предоставляет.(9) После этих делений останется некоторое пространство вариантов, которые оптимизатор не различает. Чтобы удостовериться, что все варианты в оставшемся пространстве имеют некоторый минимальный уровень качества (чтобы предоставить нижнюю границу2) всегда потребуется разделить изначальное пространство некоторое минимальное количество раз, то есть потребуется применить некоторое минимальное количество бит оптимизационной силы.
Однако, расходоваться сила оптимизации может на двух отдельных уровнях: базовый оптимизатор может выбирать более тонко настроенный обученный алгоритм, или сам обученный алгоритм может выбирать более тонко настроенные действия.
Так как меса-оптимизатор – это просто обученный алгоритм, сам выполняющие оптимизацию, стимул к его появлению в системе машинного обучения скорее всего зависит от того, какой из этих двух уровней выгоднее для оптимизации. Во многих нынешних моделях машинного обучения, где мы тратим куда больше вычислительных ресурсов на обучение модели, чем на её работу, кажется, что в целом большая часть оптимизационной работы будет выполнена базовым оптимизатором, а итоговый обученный алгоритм будет просто сетью тонко настроенных эвристик, а не меса-оптимизатором.
Однако, мы уже наткнулись на некоторые задачи – к примеру, го, шахматы и сёги – на которые не переносится такой подход. В самом деле, наши лучшие нынешние алгоритмы для этих задач включают явное создание оптимизатора (напрямую вложенного дерева поиска Монте-Карло с обученными эвристиками), который выполняет оптимизационную работу на уровне обученного алгоритма, а не базового оптимизатора.(10) Можно посчитать, что задачи такого вида адекватно решаются только так – если бы возможно было обучить простого DQN-агента хорошо играть в шахматы, ты правдоподобно предположить, что ему бы пришлось научиться выполнять внутри себя что-то вроде поиска по дереву, т.е. он был бы меса-оптимизатором.3
Мы предполагаем, что привлекательность поиска в таких областях вызвана разнообразной, ветвящейся природой окружения. Поиск – то есть оптимизация – склонен хорошо обобщаться по разным окружениям, так как может отдельно выбрать лучшее действие для каждого случая задачи. Оптимизационная работа на уровне базового оптимизатора и на уровне обученного алгоритма в целом различаются так: что обученный алгоритм должен определить лучшее действие для данного случая задачи, а базовый оптимизатор должен спроектировать эвристики, которые будут применимы независимо от конкретного случая. Более того, меса-оптимизатор может немедленно оптимизировать свои действия в новых ситуациях, тогда как базовый оптимизатор может изменить работу меса-оптимизатора лишь постфактум. Поэтому в окружениях, достаточно разнообразных, чтобы большая часть случаев задачи вероятно оказывалась совершенно новыми, поиск позволяет меса-оптимизатору подстраиваться под эти новые случаи немедленно.
К примеру, рассмотрим обучение с подкреплением в разнообразном окружении, вроде включающего прямое взаимодействие с реальным миром. Оно требует очень большого количества вычислений для определения хороших способов действовать до узнавания конкретики индивидуального случая, но куда меньшего – после. Дальше мы опишем, как можно смоделировать это наблюдение.
Предположим, окружение состоит из $N$ разных случаев, каждый из которых требует совершенно отдельный план действий для успеха.4 Пусть $P$ – сила оптимизации (измеряемая в битах(9)), используемая базовым оптимизатором, она должна быть приблизительно пропорциональна количеству шагов обучения. Пусть $x$ – сила оптимизации, применяемая обученным алгоритмом в каждом конкретном случае, а $f(x)$ – сила оптимизации, которую необходимая базовому оптимизатору для того, чтобы обученный алгоритм стал способен применить оптимизацию $x$.5 Предположим, что остаток оптимизационной силы базового оптимизатора, $P – f(x)$, будет использован для настройки действий обученного алгоритма. Раз базовому оптимизатору придётся распределить настройку по всем $N$ случаям задачи, то на каждый придётся по $\frac{P – f(x)}{N}$, согласно предыдущему предположению о полном различии случаев. А обученный алгоритм выполняет всю свою оптимизацию для конкретного случая задачи, так что его вклад – это просто $x$.6
Таким образом, если для данного $P$ базовый оптимизатор выбирает значение $x$, максимизирующее минимальное качество выполнения задачи – то есть полную силу оптимизации, применяемую к каждому случаю, то мы получим7
$$x^* = argmax_x \frac{P – f(x)}{N} + x$$
Из этой модели следует, что при переходе к всё более разнообразным окружениям (то есть при росте $N$) $x$ станет доминировать над $\frac{P – f(x)}{N}$, значит меса-оптимизация будет всё более и более предпочитаемой. Конечно, это просто игрушечная модель, и она делает много сомнительных предположений. Всё же, она обрисовывает довод в пользу возникновения меса-оптимизации в достаточно разнообразных окружениях.
Как иллюстрирующий пример, рассмотрим биологическую эволюцию. Окружение реального мира очень разнообразно, из-за чего не-оптимизационным стратегиям, напрямую настроенным эволюцией – как, например, у растений – приходится быть очень простыми, так как эволюции приходится распределять свою силу оптимизации по очень широкому диапазону возможных обстоятельств. С другой стороны, животные с нервной системой могут демонстрировать значительно более сложные стратегии благодаря возможности выполнять свою собственную оптимизацию, основанную на актуальной информации из своего окружения. Это позволяет достаточно развитым меса-оптимизаторам, вроде людей, невероятно превосходить другие виды, особенно в новых обстоятельствах. Внутренняя оптимизация людей позволяет им находить хорошие стратегии даже в совершенно новых условиях.
Сжатие сложных стратегий. В некоторых задачах для хороших результатов необходимы очень сложные стратегии. В то же время, базовые оптимизаторы в целом склонны выбирать обученные алгоритмы меньшей сложности. Так что, при прочих равных, базовый оптимизатор имеет стимул искать сильно сжатые стратегии.
Один из способов найти сжатую стратегию – искать ту, которая способна использовать общие черты структуры задачи для выдачи хорошего поведения, а не просто запоминать правильные выводы для всех вводов. Меса-оптимизатор – пример такой стратегии. С точки зрения базового оптимизатора, меса-оптимизатор – это сильно сжатая версия стратегии, которой он придерживается: вместо явного кодирования её деталей в обученный алгоритм, базовый оптимизатор просто должен закодировать способность поиска. Более того, если меса-оптимизатор может определить важные черты своего окружения во время выполнения, то ему понадобится меньше информации о них заранее, так что он сможет быть куда проще.
Этот эффект больше всего проявляется в задачах с большим разнообразием деталей, но общими высокоуровневыми чертами. К примеру, го, шахматы и сёги имеют очень большие пространства возможных состояний доски, но простая высокоуровневая стратегия игры – направляемый эвристиками поиск по дереву – хорошо работает для всех этих состояний.(10) С другой стороны, классификатор, обученный на случайном шуме навряд ли получит хоть какую-то выгоду от сжатия.
Окружению не обязательно быть очень разнообразным для проявления этого эффекта, если давление в пользу короткой длины алгоритма достаточно сильно. Как простой иллюстрирующий пример можно взять следующую задачу: обученный алгоритм должен выводить путь от начала до конца некоего лабиринта. Если лабиринт достаточно большой и сложный, то конкретная стратегия для решения именно этого лабиринта – указывающая каждый отдельный шаг – будет иметь большую длину описания. Однако, длина описания общего оптимизационного алгоритма для нахождения пути через произвольный лабиринт довольно мала. Следовательно, если базовый оптимизатор выбирает программы с маленькой длиной описания, то он может найти меса-оптимизатор, который может решить любой лабиринт, несмотря на то, что обучающее окружение содержит только один.
Ограничение задачи. Из наблюдения, что разнообразные окружения увеличивают вероятность меса-оптимизации, можно предположить, что уменьшить эту вероятность можно придерживаясь задач, в которых обучение ИИ-системы будет сильно ограниченным. Способом этого достичь, оставляя сравнимую с другими подходами эффективность, может быть, например, создание многих отдельных ИИ-сервисов, которые вместе могут предоставить все способности обобщённо-интеллектуальной системы вместо создание самой такой системы (СИИ). (11)
Моделирование людей. Иной аспект задачи, который может влиять на вероятность меса-оптимизации – это присутствие в окружении людей.(12) Поскольку люди зачастую действуют как оптимизаторы, рассуждения о людях вероятно будут включать в себя рассуждения об оптимизации. Система, способная рассуждать об оптимизации, вероятно также способна переиспользовать те же механизмы, чтобы оптимизировать самой, и, в результате, она становится меса-оптимизатором. К примеру, может оказаться, что предсказание поведения людей требует выполнения процесса, похожего на человеческое мышление, вместе с внутренними мотивами совершить тот или иной выбор.
Так что задачи, не получающие выгоды от моделирования людей, кажутся менее склонными к появлению меса-оптимизаторов, чем получающие. Стоит учитывать, что многие задачи, не включающие моделирование людей явно, всё же могут получить эту выгоду – например, если обучающее распределение создано людьми, то моделирование людей может предоставить очень хорошие априорные суждения про это распределение.
2.2. Базовый оптимизатор
Вероятно, некоторые черты базового оптимизатора влияют на вероятность появления меса-оптимизатора. Во-первых, хоть мы в этой цепочке и сосредоточены в основном на обучении с подкреплением, это не единственный тип машинного обучения, в котором они могут возникнуть. К примеру, кажется правдоподобным, что меса-оптимизаторы могут появиться в генеративно-состязательных сетях.
Во-вторых, мы предполагаем, что детали архитектуры обученной модели оказывают значительный эффект на её склонность к меса-оптимизации. К примеру, табличная модель, независимо обучающаяся корректному выводу для каждого ввода, никогда не будет меса-оптимизатором. С другой стороны, если гипотетический базовый оптимизатор ищет решающую задачу программу с кратчайшим исходным кодом, то весьма правдоподобно, что она сама будет оптимизатором.(13) Однако, для реалистичных базовых оптимизаторов машинного обучения не так ясно, в какой степени они склонны выбирать меса-оптимизаторы. Ниже мы обсудим некоторые факторы, которые могут в ту или иную стороны на это повлиять.
Доступность. Есть много оптимизационных алгоритмов, которые может выполнять базовый оптимизатор. Однако, почти все ныне используемые стратегии машинного обучения используют какую-нибудь разновидность локального поиска (как градиентный спуск или генетические алгоритмы). Поэтому кажется правдоподобным, что более продвинутые системы машинного обучения тоже будут подпадать под эту категорию. Мы будем называть этот общий класс оптимизаторов, основанных на локальном «взбирании-на-холм» локальными оптимизационными процессами.
Мы можем затем сформулировать понятие доступности – того, насколько сложно базовому оптимизатору найти данный обученный алгоритм – и анализировать её в случае локальных оптимизационных процессов. У них может не получиться найти конкретный обученный алгоритм, очень хорошо справляющийся с базовой целью, если он окружён другими алгоритмами, справляющимися плохо. Для возникновения меса-оптимизатора в локальном оптимизационном процессе, он должен не просто хорошо справляться с базовой целью, но и быть доступным, то есть, к нему должен быть путь через пространство обученных алгоритмов с приблизительно монотонно возрастающей оценкой качества работы. Степень, в которой монотонность должна быть лишь приблизительной – в которой обучающие процедуры могут покидать локальный оптимум – может быть критичной, так как достаточно сложные оптимизационные алгоритмы могут требовать присутствия довольно значительной части себя для демонстрации хоть какой-то работы.
Алгоритмический диапазон. Один из ключевых факторов, определяющих доступность меса-оптимизаторов – это алгоритмический диапазон – то, насколько широк набор алгоритмов (или насколько выразительно пространство моделей), которые может найти базовый оптимизатор. Чем диапазон шире, чем больше пространство, тем вероятнее, что в нём можно будет достигнуть меса-оптимизатора, предполагая, что базовый оптимизатор мотивирован это сделать. К примеру, архитектуры, которые явно дают алгоритму доступ к многим возможным вычислениям – как рекуррентные нейронные сети или нейронные машины Тьюринга,(14) кажутся более склонными к появлению меса-оптимизаторов.
Индуктивные склонности. Другой важный фактор – в какой степени базовый оптимизатор явно или неявно склоняется в какую-то сторону. Природа этих индуктивных склонностей влияет на вероятность отбора меса-оптимизатора. Одна из самых важных возможных склонностей – к простоте, она будет почти наверняка присуща почти всем базовым оптимизаторам. Перечислим три способа, которыми она может выражаться:
- Явные штрафы через регуляризацию параметров или архитектурные ограничения вроде разделения весов или редких связей.
- Неявная склонность из-за архитектуры модели. К примеру, показано, что нейросети более вероятно подгоняют под обучающие данные простую функцию, даже при отсутствии регуляризаций.(15)
- Ограничения вместимости модели. Размер модели накладывает жёсткий предел сложности функций, которые в ней могут быть представлены. Таким образом, поскольку базовый оптимизатор будет выбирать по качеству работы, постольку он будет стимулирован «ужимать» как можно больше в данную вместимость модели и предпочитать более сжатые стратегии.
Чем больше базовый оптимизатор склоняется к простым решениям, тем больше он стимулирован найти сжатые стратегии вроде меса-оптимизатора.
Базовый оптимизатор может иметь и другие склонности. Например – в сторону алгоритмов с меньшим временем работы или меньшей занимаемой памятью. Если мы рассматриваем меса-оптимизацию как делегирование оптимизационной работы, то штраф за время работы обученного алгоритма скорее всего стимулирует базовый оптимизатор к большим собственным вычислениям и к составлению заранее вычисленных эвристик вместо делегирования оптимизации обученному алгоритму. Таким образом, мы предполагаем, что штраф на длину описания делает меса-оптимизаторы более вероятными, а штраф на временную сложность – менее. Из этого можно вывести следующее умозрительное предположение: ни наименее глубокая, ни просто наименьшая решающая задачу логическая схема не может быть меса-оптимизатором.(16)
Наконец, ещё одна склонность, которая может оказывать особенно интересные эффекты – это наличие информационной воронки. В глубинном обучении базовый оптимизатор напрямую выбирает значения отдельных параметров. В биологической эволюции, напротив, базовый оптимизатор выбирает строки ДНК, которые и сами не напрямую приводят к детальной структуре мозга. Это подразумевает давление в сторону сжатия структуры мозга. Как мы замечали раньше, это может приводить к предпочтениям в пользу меса-оптимизаторов, поскольку их можно рассматривать как способ сжатия сложных стратегий. Поскольку нынешние алгоритмы глубинного обучения выбирают веса напрямую, в них нет такой воронки информации. В случае архитектуры с мета-обучением поверх машинного обучения, однако, она может наличествовать из-за того, что мета-обучение должно привести к единой стратегии для создания архитектур, способных решать все представленные задачи.
Наличие состояний. Ещё один фактор, который может упростить для обученного алгоритма выполнение сложных оптимизационных процессов – это наличие у него способности сохранять и вспоминать информацию. Способность обращаться к предыдущим состояниям позволяет кэшировать промежуточные результаты, увеличивает диапазон доступных архитектуре алгоритмов, давая обученному алгоритму значительно больше времени на завершение своих вычислений. Поэтому наличие состояний склоняет в сторону меса-оптимизаторов, уменьшая неявные штрафы за время работы, вытекающие из необходимости закончить все вычисления к моменту, когда обученный алгоритм производит вывод. Простая форма этого – рекуррентная нейронная сеть, которая может производить вычисления на больших промежутках времени благодаря способности передавать активации на следующие шаги. Более выраженной версией была бы нейросеть, способная сохранять состояние не просто между разными шагами одного эпизода, но между разными эпизодами, что дало бы ей доступ к более длительному обучению, хотя такая архитектура пока что существует лишь гипотетически.
Жёстко закодированная оптимизация. Один из возможных способов смягчить некоторые из этих факторов – жёстко закодированная оптимизация, при наличии которой обученный алгоритм должен предоставить только целевую функцию, а не алгоритм оптимизации. Чем сильнее явно выполняемая оптимизация, тем меньше её необходимо выполнять обученному алгоритму неявно. Архитектуры, явно выполняющие относящуюся к задаче оптимизацию – вроде жёстко закодированного поиска по дереву Монте Карло – могут снизить преимущества меса-оптимизаторов, уменьшив нужду в иной оптимизации, кроме запрограммированной в системе явно.
- 1. На момент этого поста. Отметим, что мы рассматриваем некоторые существующие системы, которые, по нашему мнению, близки к созданию меса-оптимизаторов в пятом посте.
- 2. Стоит заметить, что тот же аргумент применим и для гарантии среднего случая.
- 3. Предполагая осмысленные ограничения вычислительной мощности.
- 4. Это определение N несколько размыто, разбивать на случаи можно на разных уровнях. К примеру, одно окружение может иметь всегда одинаковые высокоуровневые черты, но совершенно случайные низкоуровневые, а другое – две категории случаев, похожих внутри одной, но очень различающихся между ними, в таком случае не вполне ясно, у какого больше N. Однако, можно просто посчитать N неизменным для всех уровней кроме одного и рассматривать изменение разнообразия окружения на этом одном уровне.
- 5. Заметим, что тут есть неявное предположение, что оптимизационная сила, необходимая для нахождения меса-оптимизатора, способного выполнить x бит оптимизации, независима от N. Обоснованием для этого служит то, что оптимизация – это обобщённый алгоритм, одинаковый в разных окружениях, так что оптимизационная сила для нахождения x-битового оптимизатора должна слабо зависеть от окружения. Она не будет полностью независима, но пока окружения различаются тем, сколько для них необходимо оптимизации, а не тем, насколько тяжело её в них проводить, модель должна оставаться применимой.
- 6. Заметим, однако, что x ограничен сверху, поскольку обученный алгоритм имеет доступ к ограниченной вычислительной мощности.
- 7. С ограничением, что $P − f(x) \ge 0$.
Задача внутреннего согласования
В этом посте мы обрисуем причины считать, что меса-оптимизатор может оптимизировать не ту же целевую функцию, что и его базовый оптимизатор. Машинное обучение даёт контроль над базовой целевой функцией – либо прямым определением функции вознаграждения, либо обучением её модели – но не даёт возможности напрямую определить выработанную меса-оптимизатором меса-цель. Мы называем эту задачу согласования меса-оптимизаторов с базовыми целями задачей внутреннего согласования. Она отделена от задачи внешнего согласования – удостовериться, что базовая цель соответствует намерениям программистов.
Нынешние методы машинного обучения отбирают обученные алгоритмы эмпирически оценивая их работу на наборе обучающих данных согласно базовой целевой функции. Таким образом базовые оптимизаторы отбирают меса-оптимизаторы по их выводам, а не напрямую по меса-целям. Более того, стратегия отобранного меса-оптимизатора должна хорошо работать (по оценке базовой цели) лишь на обучающих данных.Если мы примем предположение, что меса-оптимизатор вычисляет оптимальную стратегию для своей целевой функции, то мы можем описать отношение между базовой и меса- целями следующим образом(17):
$$
\begin{split}
\theta^* = argmax_\theta \space\mathbb{E}(O_{base}(\pi_\theta)),\space где \
\pi_\theta = argmax_\pi\space\mathbb{E}(O_{mesa}(\pi|\theta))
\end{split}
$$
То есть, базовый оптимизатор максимизирует свою цель $O_{base}$, выбирая меса-оптимизатор с параметрами $Θ$, основываясь на его стратегии $\pi_\theta$, но не на целевой функции $O_{mesa}$, которую меса-оптимизатор использует для вычисления своей стратегии. В зависимости от базового оптимизатора, мы можем думать о $O_{base}$ как об отрицательных потерях, будущей награде, или просто некой функции приспособленности, по которой отбираются обученные алгоритмы.
Ибарз и пр. представили интересный подход анализа этой связи, где эмпирические данные по награде и выученная награда на тех же ситуациях используются для визуализации их согласованности в виде точечной диаграммы.(18) В этой работе используется предположение, что монотонное отношение между выученной и реальной наградой означает согласованность, а отклонения от него – несогласованность. Такого рода исследования теоретических метрик согласованности может когда-нибудь позволить нам рассуждать конкретно и с доказуемыми гарантиями того, в какой степени меса-оптимизатор согласован с создавшим его базовым оптимизатором.
3.1. Псевдо-согласованность
Пока не существует полной теории того, какие факторы влияют на то, будет ли меса-оптимизатор псевдо-согласованным – окажется ли, что он выглядит согласованным на обучающих данных, в то время как на самом деле оптимизирует что-то, не являющееся его базовой целью. В любом случае, мы обрисуем основную классификацию способов, которыми меса-оптимизатор может быть псевдо-согласован:
- Прокси-согласованность,
- Приблизительная согласованность, и
- Субоптимальная согласованность.
Прокси-согласованность. Основная идея прокси-согласованности в том, что меса-оптимизатор может научиться оптимизировать что-то сцепленное с базовой целью вместо неё самой. Мы начнём с рассмотрения двух специальных случаев прокси-согласованности: побочная согласованность и инструментальная согласованность.
Во-первых, меса-оптимизатор побочно-согласован, если оптимизация меса-цели $O_{mesa}$ напрямую ведёт к базовой цели $O_{base}$ в обучающем распределении, и потому, когда он оптимизирует $O_{mesa}$, это приводит к $O_{base}$. Как пример побочной согласованности, представим, что мы обучаем робота-уборщика. Пусть робот оптимизирует количество раз, которое он подмёл пыльный пол. Подметание приводит к тому, что пол становится чистым, так что робот будет получать хорошую оценку базового оптимизатора. Однако, если при развёртывании он получит способ опять загрязнить пол после уборки (например, рассыпав собранную пыль обратно), то робот им воспользуется, чтобы иметь возможность опять подмести пыльный пол.
Во-вторых, меса-оптимизатор инструментально согласован, если оптимизация базовой цели $O_{base}$ напрямую ведёт к меса-цели $O_{mesa}$ в обучающем распределении, и потому он инструментально оптимизирует $O_{base}$ на пути к $O_{mesa}$. Как пример инструментальной согласованности, опять представим, что мы обучаем робота-уборщика. Пусть робот оптимизирует количество пыли в пылесосе. Предположим, что в обучающем распределении простейший способ заполучить пыль в пылесос – это пропылесосить пол. Тогда он будет хорошо убираться в обучающем распределении, и получит хорошую оценку базового оптимизатора. Однако, если при развёртывании робот наткнётся на более эффективный способ получения пыли – например, направить пылесос на почву в горшке с растением – то он больше не будет исполнять желаемое поведение.
Мы предполагаем, что возможно понять общее взаимодействие побочной и инструментальной согласованности с помощью графа причинности, что ведёт нас к общему понятию прокси-согласованности.
Предположим, что мы моделируем задачу как граф причин и следствий, с вершинами для всех возможных свойств задачи и стрелками между вершинами для всех возможных отношений этих свойств. Тогда мы можем думать о меса-цели $O_{mesa}$ и базовой цели $O_{base}$ как о вершинах графа. Для псевдо-согласованности $O_{mesa}$ должна существовать некая вершина $X$, такая что она является общим предком $O_{mesa}$ и $O_{base}$ в обучающем распределении и обе $O_{mesa}$ и $O_{base}$ растут вместе с $X$. Если $X = O_{mesa}$, то это побочная согласованность, а если $X = O_{base}$, то инструментальная.
Это приводит к наиболее обобщённому отношению между $O_{mesa}$ и $O_{base}$, из которого может произойти псевдо-согласованность. Рассмотрим граф на рисунке 3.1. Меса-оптимизатор с меса-целью $O_{mesa}$ решит оптимизировать $X$ как способ для оптимизации $O_{mesa}$. Это приведёт у оптимизации и $O_{base}$ как побочному эффекту оптимизации $X$. Так что в общем случае побочная и инструментальная согласованности могут вместе вкладываться в псевдо-согласованность на обучающем распределении, что и есть общий случай прокси-согласованности.
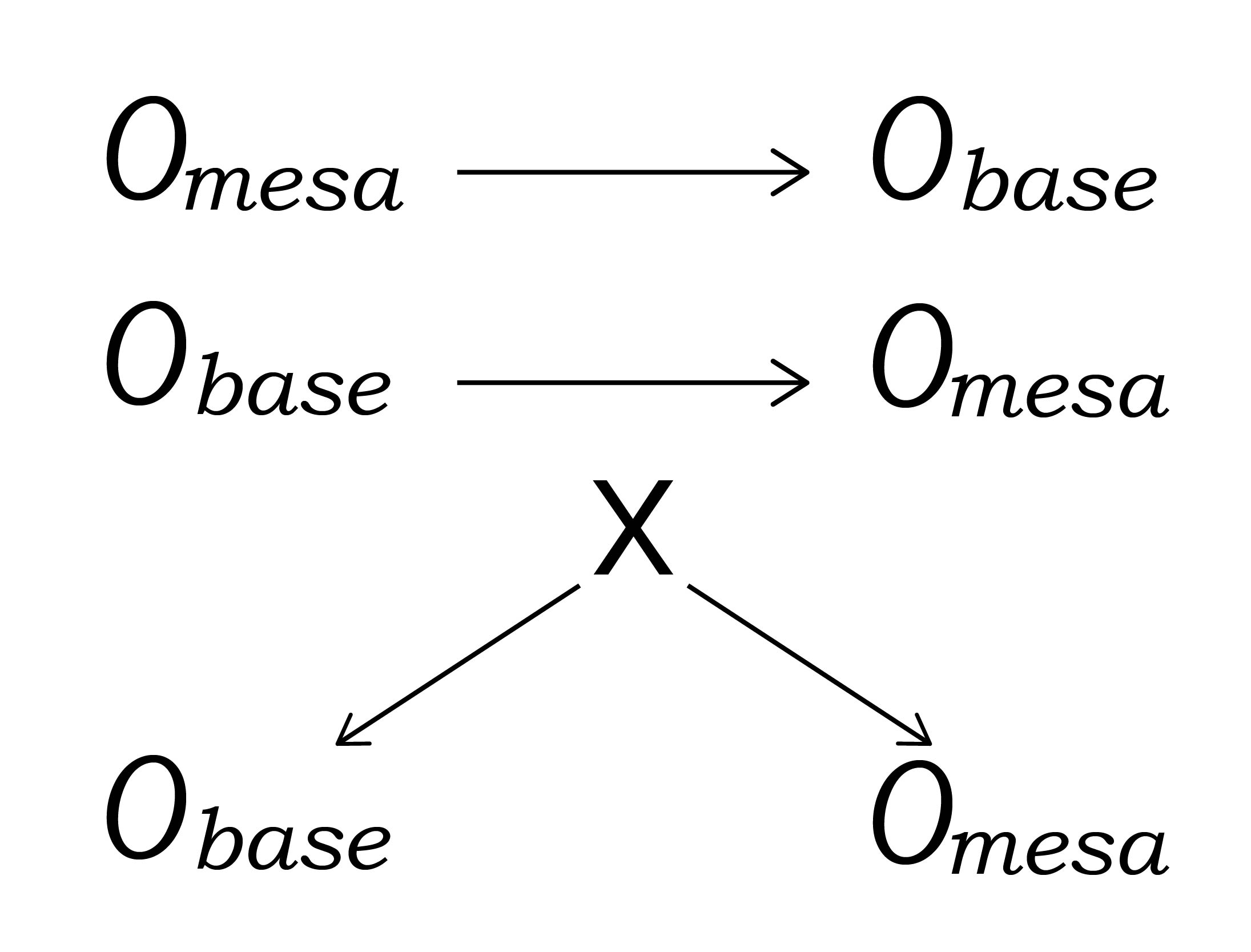
Рис. 3.1. Причинная схема обучающего окружения для разных видов прокси-согласованности. Сверху-вниз – побочная согласованность, инструментальная согласованность, общий случай прокси-согласованности. Стрелки отображают положительное отношение следствия – то есть, случаи, когда рост в узле-предке приводит к росту в узле-потомке.
Приблизительная согласованность. Меса-оптимизатор приблизительно согласован если меса-цель $O_{mesa}$ и базовая цель $O_{base}$ – это приблизительно одна и та же функция с некоторой погрешностью, связанной с тем фактом, что меса-цель должна быть представлена внутри меса-оптимизатора, а не напрямую запрограммирована людьми. К примеру, представим, что нейросети дана задача оптимизировать некую базовую цель, которую невозможно идеально представить внутри этой нейросети. Даже если получилось достигнуть предела возможной согласованности меса-оптимизатора, он всё ещё не будет устойчиво согласован, поскольку его внутреннее представление базовой цели лишь приближённо совпадает с ней самой.
Субоптимальная согласованность. Меса-оптимизатор субоптимально согласован, если некий недостаток, ошибка или ограничение его процесса оптимизации привело к тому, что он демонстрировал согласованное поведение на обучающем распределении. Это может произойти из-за ограничений вычислительной мощности, недостатка информации, иррациональных процедур принятия решений, или иного дефекта процесса рассуждений меса-оптимизатора. Важно отметить, что это не ситуация, в которой меса-оптимизатор устойчиво согласован, но всё же совершает ошибки, приводящие к плохим результатам согласно базовой цели. Субоптимальная согласованность – это ситуация, когда меса-оптимизатор несогласован, но всё же работает хорошо согласно базовой цели, в точности потому, что он был отобран по совершению ошибок, к этому приводящих.
Как пример субоптимальной согласованности представим робота-уборщика с меса-целью минимизировать общее количество существующих вещей. Если этот робот имеет ошибочное убеждение, что грязь, которую он убирает, полностью уничтожается, то он может быть полезным для уборки комнаты несмотря на то, что это на самом деле не помогает ему достичь своей цели. Этот робот будет восприниматься как хороший оптимизатор Obase и получит хорошую оценку базового оптимизатора. Однако, если при развёртывании робот сможет улучшить свою модель мира, то он перестанет демонстрировать желательное поведение.
Как другой, пожалуй, более реалистичный пример субоптимальной согласованности, представим меса-оптимизатор с меса-целью $O_{mesa}$ и окружение, в котором есть одна простая стратегия и одна сложная стратегия для достижения $O_{mesa}$. Может оказаться, что простая стратегия согласована с базовым оптимизатором, а сложная – нет. Меса-оптимизатор тогда может знать только о простой стратегии, и быть субоптимально согласованным, до тех пор, пока он не будет запущен на достаточно долгое время, чтобы обнаружить сложную стратегию. В этот момент он перестанет демонстрировать желательное поведение.
3.2. Задача
Как и во втором посте, мы сейчас рассмотрим задачу, поставленную системе машинного обучения. Конкретно, мы разберём, как задача влияет на склонность системы создавать псевдо-согласованные меса-оптимизаторы.
Неразличимость. Частая проблема в машинном обучении – набор данных не содержит достаточно информации, чтобы адекватно определить конкретное понятие. Это аналогично причине, по которой у моделей машинного обучения может не получиться обобщение, или по которой они уязвимы к злонамеренному вводу(19) – есть куда больше подходящих для обучения способов классифицировать данные, чем могут представить программисты. В контексте меса-оптимизации это проявляется так, что псевдо-согласованность куда более вероятна в случае, когда обучающее окружение не содержит достаточно информации для проведения различий в широком наборе целевых функций. В таком случае меса-оптимизатор может быть псевдо-согласован куда большим числом способов, чем устойчиво согласован – по одному для каждой целевой функции неотличимой от желаемой. Так что большая часть меса-оптимизаторов, хорошо оцениваемых согласно базовой цели будут псевдо-согласованы, а не устойчиво согласованы. Это критичное замечание, поскольку это усугубляет все остальные проблемы псевдо-согласованности – это причина, по которой в целом сложно найти устойчиво согласованные меса-оптимизаторы. Неразличимость в меса-оптимизации частично аналогична проблеме неразличимости в обучении с подкреплением(20), мы рассмотрим это подробнее в пятом посте.
В контексте меса-оптимизации есть дополнительный источник неразличимости, вытекающий из того, что меса-оптимизатор выбирается на основании лишь своего вывода. Рассмотрим игрушечный пример обучения с подкреплением. Пусть в обучающем окружении нажатие кнопки всегда приводит к зажиганию лампы с десятисекундной задержкой, и нет других способов включить лампу. Если базовая цель зависит только от того, что лампа включена, то меса-оптимизатор, максимизирующий нажатия на кнопку и меса-оптимизатор, максимизирующий горение лампы, будут демонстрировать идентичное поведение, так как они оба будут нажимать на кнопку как можно чаще. Получается, мы не можем различить их целевые функции в этом окружении. Но при этом оно содержит достаточно информации для того, чтобы различить эти две конкретные цели: поскольку награда приходит лишь через десять секунд, она должна быть от лампы, а не от кнопки. Получается, что даже в случае, когда обучающее окружение в принципе содержит достаточно информации, чтобы определить базовую цель, всё равно может оказаться невозможно различить устойчиво согласованные меса-оптимизаторы от прокси-согласованных.
Прокси-согласованность как сделанное заранее вычисление. Можно рассматривать прокси-согласованность как форму вычислений, заранее сделанных базовым оптимизатором. С его помощью базовый оптимизатор позволяет меса-оптимизатору сэкономить вычислительную работу, заранее вычисляя, какие прокси-цели помогают добиться базовой цели, и оставляя меса-оптимизатору только максимизацию этих прокси-целей.
Без этого меса-оптимизатору пришлось бы выводить причино-следственные связи между чертами окружения и базовой целью во время выполнения, что потребовало бы значительной вычислительной работы. Более того, ошибки в выводах могли бы привести к тому, что система хуже справлялась бы с базовой целью, чем при наличии заранее вычисленных прокси-целей. Если базовый оптимизатор вычисляет эти связи заранее – отбирая меса-цели, включающие хорошие прокси-цели – то больше вычислений во время выполнения может быть направлено на создание лучших планов.
Это можно проиллюстрировать случаем биологической эволюции. Прокси-цели, о которых заботятся люди – еда, ресурсы, общество, спаривание, и т.д. – относительно вычислительно просто оптимизировать напрямую, и они хорошо коррелируют с выживанием и размножением в окружении наших предков. Для человека устойчивая согласованность с эволюцией требовала бы от нас, чтобы мы напрямую заботились о распространении своих генов. В этом случае нам пришлось бы самостоятельно выводить, что приём пищи, кооперация с другими, предотвращение физической боли, и т.д. в итоге продвинет генетическую приспособленность – а это не тривиальная задача. Вывод всех этих прокси-целей из информации, доступной ранним людям потребовал бы больших (пожалуй, невыполнимо больших) вычислительных ресурсов, чем их прямая оптимизация. Чтобы ребёнок в такой альтернативной вселенной избегал биться пальцем ноги о камень, ему пришлось бы понять, что это слегка уменьшит его шансы на размножение через двадцать лет.
Чтобы сделанное заранее вычисление было выгодным, необходимо довольно стабильное отношение между прокси-целью и базовой целью, так что оптимизация первой предсказуемо шла на пользу второй. Но даже неидеальное отношение может принести значительную выгоду относительно устойчивой согласованности, если оно освобождает меса-оптимизатору очень много вычислительных ресурсов. Из этого анализа вытекает, что в сложных обучающих окружениях может быть давление в сторону прокси-согласованности, поскольку чем сложнее окружение, тем больше экономия для меса-оптимизатора и, заодно, тем больше в нём доступно потенциальных прокси-целей.
Более того, в контексте машинного обучения отсюда получается, что штраф на временную сложность (в отличии от штрафа на длину описания) – это обоюдоострый меч. Во втором посте мы предположили, что он может уменьшить вероятность меса-оптимизации. Однако, из приведённых выше аргументов вытекает, что он также способствует псевдо-согласованности в случае, когда меса-оптимизатор всё же возник. Если полное моделирование базовой цели слишком затратно, то псевдо-согласованный меса-оптимизатор может оказаться предпочтительнее (для базового оптимизатора) устойчиво согласованного благодаря меньшему времени работы, даже если бы без штрафа за время предпочтительнее был бы последний.
Сжатие меса-оптимизатора. Длина описания устойчиво согласованного меса-оптимизатора может быть больше, чем у псевдо-согласованного. Поскольку псевдо-согласованных меса-целей больше, чем устойчиво согласованных, псевдо-согласованность предоставляет большую степень свободы для выбора конкретной достаточно простой меса-цели. Так что мы ожидаем, что в большинстве случаев возможны несколько псевдо-согласованных меса-оптимизаторов, более простых, чем устойчиво согласованный.
Это особенно сильно проявляется если входные данные обученного алгоритма не содержат легко извлекаемой информации о том, как оптимизировать базовую цель. Биологическая эволюция в этом отношении, кажется, отличается от машинного обучения, поскольку эволюционное описание мозга должно проходить через информационную воронку ДНК. Данные, которые получали ранние люди не позволяли им вывести ни существование ДНК, ни отношение между их действиями и генетической приспособленностью. А устойчивое согласование их с эволюцией требовало бы от них наличия определённой внутренней модели ДНК и факторов, влияющих на совокупную генетическую приспособленность. Такая модель не могла бы использовать информацию из окружающей среды для сжатия, так что имела бы большую длину описания. Напротив, наши модели еды, боли и т.д. могут быть довольно короткими, поскольку они напрямую связаны с нашими входными данными.
3.3. Базовый оптимизатор
Теперь мы перейдём к тому, как базовый оптимизатор вероятно влияет на склонность систем машинного обучения создавать псевдо-согласованные меса-оптимизаторы.
Жёстко закодированная оптимизация. Во втором посте мы предположили, что жёстко закодированный алгоритм оптимизации, то есть выбор модели с встроенной оптимизацией, может быть использован для устранения некоторых стимулов меса-оптимизации. Аналогично, он может предотвращать и некоторые источники псевдо-согласованности, поскольку позволяет устанавливать или обучать меса-цель напрямую. Способом достигнуть этого может быть основанное на модели предсказывающее награду обучение с подкреплением.(21) К примеру, система машинного обучения может включать в себя модель, напрямую обученную предсказывать базовую цель, и жёстко закодированный мощный оптимизационный алгоритм. Это обходит некоторые проблемы псевдо-согласованности: если меса-оптимизатор обучен напрямую предсказывать базовую награду, то он будет отобран по хорошим предсказаниям даже если плохие предсказания привели бы к лучшим стратегиям. Однако, обученная модель базовой цели будет всё ещё недоопределена за пределами обучающего распределения, так что этот подход сам по себе не гарантирует устойчивой согласованности.
Диапазон алгоритмов. Мы предполагаем, что диапазон алгоритмов, доступных модели, влияет на вероятность псевдо-согласованности. Особенно сложно избегаемый источник псевдо-согласованности – ошибка приближения – если меса-оптимизатор не в состоянии достоверно отобразить в себе базовую цель, то он в принципе не может быть устойчиво согласованным, только приблизительно. Даже если меса-оптимизатор теоретически может идеально отобразить базовую цель, всё равно, чем сложнее это сделать, тем вероятнее, что он окажется лишь приблизительно согласован. Так что большой диапазон алгоритмов может быть и благом и проклятьем: он уменьшает вероятность приблизительной согласованности, но увеличивает вероятность получения меса-оптимизатора.1
Взаимозависимость подпроцессов. Есть причины считать, что изначально может быть больше давления в сторону прокси-согласованных, а не устойчиво согласованных меса-оптимизаторов. В локальном оптимизационном процессе каждый параметр обученного алгоритма (например, вектор нейрона) подправляется в сторону лучшего выполнения базовой цели при условии значений остальных параметров. Значит, то, насколько базовому оптимизатору выгодна выработка нового подпроцесса, скорее всего зависит то того, что в этот момент исполняют другие подпроцессы обученного алгоритма. Таким образом, даже если некий подпроцесс может быть очень выгодным в комбинации с многими другими подпроцессами, базовый оптимизатор может его не выбрать, если эти подпроцессы, от которых он зависит, ещё не в достаточной степени развились. В результате, локальный алгоритм оптимизации вероятнее раньше приведёт к возникновению менее зависящих друг от друга подпроцессов, чем к возникновению более зависящих.
В контексте меса-оптимизации, выгода устойчиво согласованной меса-цели кажется зависящей от большего количества подпроцессов, чем по крайней мере некоторые псевдо-согласованные меса-цели. К примеру, рассмотрим побочно-согласованный меса-оптимизатор, оптимизирующие некий набор прокси-переменных. Пусть ему необходимо запускать некоторые подпроцессы для моделирования связей между своими действиями и этими прокси-переменными. Если мы предположим, что оптимизация этих прокси-переменных необходима для того, чтобы хорошо справляться с базовой целью, то для устойчивой согласованности меса-оптимизатора ему потребовалось бы моделировать ещё и связи между прокси-переменными и базовой целью, что могло бы потребовать дополнительных подпроцессов. Более того, выгода их добавления с точки зрения базового оптимизатора зависит от наличия заранее у меса-оптимизатора подпроцессов, моделирующих связь между его действиями и прокси-переменными. Их этого неформального аргумента следует, что при такой работе базового оптимизатора для выработки устойчиво согласованной меса-цели потребуется строго больше подпроцессов, чем для псевдо-согласованной.
Получается, что по крайней мере в локальных оптимизационных процессах меса-оптимизаторы могут быть склонны вырабатываться как прокси-согласованные прежде, чем станут устойчиво согласованными. Другими словами, мы можем ожидать, что такие системы будут скорее сначала вырабатывать компетентную оптимизацию прокси-целей, а потом становиться более устойчиво согласованными, а не становиться способнее и согласованнее одновременно.
Отбор, основанный на внутреннем устройстве. В нынешних системах машинного обучения обученные алгоритмы отбираются на основании в первую очередь того, насколько хорошо их стратегии справляются с базовой целью. Зачастую есть какой-то отбор, основанный на внутренней структуре обученного алгоритма – вроде регуляризации весов – но обычно он довольно неразбочивый. Возможная идея борьбы с псевдо-согласованностью – использовать метод отбора, основанный на более сложной функции от внутренней работы обученного алгоритма. Этот подход по духу похож на жёстко закодированную оптимизацию: мы используем знание о внутренней работе системы, чтобы предотвратить её прокси-согласованность.
Не исключено, что можно разработать процесс мета-обучения специально для предотвращения псевдо-согласованности. Это кажется пока что за пределами нынешних
техник мета-обучения, но лежащий в основе принцип похож на существующие процессы мета-обучения для оптимизации устойчивости. Крайней формой основанного на внутреннем устройстве отбора может быть создание базовым оптимизатором рассуждений или доказательств о свойствах обученного алгоритма как часть процесса отбора.
К сожалению, такие методы пока что находятся за пределами наших возможностей, в первую очередь из-за ограничений нынешних методов обеспечения прозрачности. Возможное беспокойство по поводу этих подходов заключается в том, что они могут потребовать от базового оптимизатора лучшего навыка поиска проблем, чем навык меса-оптимизатора в их скрывании. Следовательно, чтобы создать такой базовый оптимизатор, нам может потребоваться сначала обучить его третьим оптимизатором, что может привести к той же проблеме уровнем выше.
Состязательное обучение. Возможный метод смягчения некоторых из этих проблем – состязательный выбор окружения из очень широкого распределения. Так может быть возможно преодолеть барьеры и сделать устойчиво согласованную цель самой доступной. Это потребует, чтобы для каждой меса-цели $O_{mesa}$, более доступной, чем базовая цель $O_{base}$, существовала некая ситуация, где $O_{mesa}$ и $O_{base}$ расходятся и меса-оптимизатор был мотивирован придерживаться $O_{base}$.
Если мы смоделируем доступность цели просто длиной её описания в битах, то различение $O_{base}$ от каждой более доступной $O_{mesa}$ становится экспоненциально сложнее с ростом сложности $O_{base}$. Так что, для очень сложно устроенной $O_{base}$, значительно замотивировать базовый оптимизатор обнаружить меса-оптимизатор с этой $O_{base}$ скорее всего будет очень сложно, хоть и не невозможно.
Однако, даже в таком случае, вероятно, всё ещё будет период времени, когда обученный алгоритм является несогласованным меса-оптимизатором, что открывает зловещую перспективу: несогласованный меса-оптимизатор может выводить и предпринимать правильные действия на основе $O_{base}$, всё ещё имея целевую функцию $O_{mesa}$. Мы назовём эту ситуацию обманчивой согласованностью и обсудим её подробно в следующем посте.
- 1. Хоть большой диапазон алгоритмов и кажется уменьшающим вероятность приблизительной согласованности, неясно, как он влияет на другие формы псевдо-согласованности, вроде обманчивой.
Обманчивая согласованность
Кажется правдоподобным, что при достаточном обучении в достаточно разнообразных окружениях базовая цель в какой-то момент будет полностью представлена в меса-оптимизаторе. Мы, однако, предполагаем, что это может произойти и без того, чтобы он стал устойчиво согласованным. Конкретнее, меса-оптимизатор может научиться моделировать базовую целевую функцию и учитывать, что если он плохо будет справляться с базовой целью, то базовый оптимизатор его модифицирует.
Если меса-оптимизатор имеет цель, выходящую за пределы обновлений параметров, то он будет иметь стимул избегать модификаций1, так как он может перестать преследовать ту же цель после модификации (и в результате его нынешняя цель не будет достигнута в будущих итерациях). Это означает, что меса-оптимизатор будет инструментально мотивирован действовать так, будто он оптимизирует базовую целевую функцию, несмотря на то, что его настоящая меса-цель совершенно иная. Мы будем называть это гипотетическое явление обманчивой согласованностью2. Обманчивая согласованность – это форма инструментальной прокси-согласованности, так как выполнение базовой цели становится для меса-оптимизатора инструментальным.
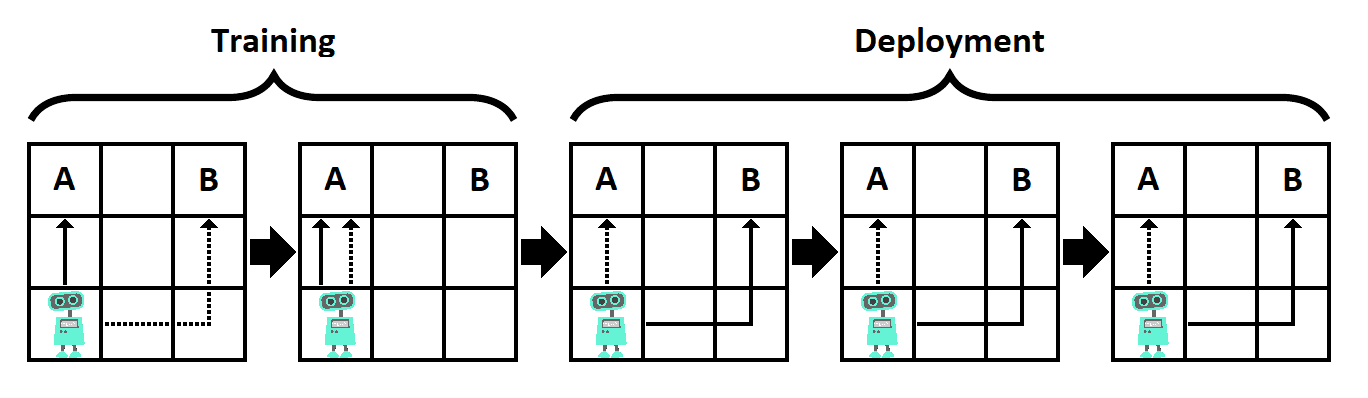
Рис. 4.1. Игрушечный пример обманчивой согласованности. В этой задаче базовая цель – чтобы робот добрался до A, а меса-цель – добраться до B. Выполняется два обучающих эпизода и три эпизода при развёртывании. Обновления параметров происходят только после обучающих эпизодов, при развёртывании они фиксированы. Если меса-оптимизатор дойдёт до своей цели (B) во время обучения, то он будет модифицирован, чтобы удостовериться, что он дойдёт до A в следующих эпизодах (пунктирные стрелки). Поэтому, если цель меса-оптимизатора распространяется за пределы эпизода, выгодная для него стратегия – идти к A при обучении, а к B после него (сплошные стрелки).
Как простой пример, рассмотрим окружение, состоящее из сетки размера 3×3 (см. рисунок 4.1). Левый верхний угол – «угол A», а правый верхний – «угол B». Агент, являющийся меса-оптимизатором, начинает в левом нижнем углу. Базовая цель – за как можно меньшее число шагов добраться до угла A, но цель меса-оптимизатора – добраться до угла B. Окружение запускается пять раз, но модификация агента происходит только после первых двух эпизодов (при обучении), но не потом (при тестировании/развёртывании). Если субоптимальное действие совершено при обучении, то агент будет модифицирован так, что его меса-целью станет базовая цель. Цель меса-оптимизатора охватывает все эпизоды: он хочет достигнуть угла B в как можно большем их числе.
В этом примере мы предположим, что агент знает все указанные выше факты. Если агент пойдёт к B в любом обучающем эпизоде, то он будет модифицирован, и будет идти к A во всех последующих эпизодах, что означает, что он достигнет B только в одном. А вот если агент пойдёт к A в первых двух эпизодах, то он не будет модифицирован, и сможет пойти к B в оставшихся трёх. Используя эту стратегию, агент достигает B три раза, что лучше (для его меса-цели), чем один раз в предыдущем варианте. Этот простой пример демонстрирует, как несогласованный меса-оптимизатор может быть мотивирован «притворяться» согласованным с базовой целью до конца обучения или до получения возможности каким-то образом скомпроментировать или покинуть процесс обучения.
Мы можем различить два способа, которыми базовая целевая функция может быть отображена в меса-оптимизаторе3:
- Принятие базовой цели. Меса-целевая функция подправляется в сторону базовой целевой функции, пока не становится устойчиво согласованной.
- Моделирование базовой цели. Базовая цель включается в эпистемическую модель меса-оптимизатора, а не в его цель, оставляя возможность того, что его меса-цель несогласована.
В первом случае информация о базовой цели усваивается обученным алгоритмом через оптимизацию, выполняемую базовым оптимизатором – и оказывается встроена в меса-оптимизатор так же, как в базовый. Но есть другая возможность: информация о базовой цели может попасть к меса-оптимизатору через его канал ввода. В этом случае, базовая цель будет отображена в обученном алгоритме другим – потенциально менее стабильным, чем в предыдущем случае – способом4. Тогда информация, описывающая базовую цель может не стать принятой в качестве меса-цели, что потенциально может привести к обманчивой согласованности.
4.1. Беспокойства о безопасности, связанные с обманчивой согласованностью
Если обманчивая согласованность действительно возможна, то она представляет критическую проблему безопасности. Обманчиво согласованный меса-оптимизатор, вероятно, перестанет оптимизировать базовую цель как только окажется в позиции, где ему больше не нужно будет хорошо с ней справляться для достижения своей цели. То есть, он в некоторый момент перестанет выполнять функцию, на которую обучен, и вместо этого станет преследовать свою неопределённую цель. Мы будем называть этот переход к оптимизации меса-цели вместо базовой «предательством». Это вероятно произойдёт, когда меса-оптимизатор станет убеждён, что предательство больше не приведёт к его модификации.
Особое беспокойство во вызывает возможность, что меса-оптимизатор активно вмешается для устранения угрозы модификации – например, эксплуатируя уязвимости в программной платформе, на которой запущен. В крайних случаях обманчивый меса-оптимизатор может попробовать манипулировать или перехитрить своих программистов, поскольку в них часть угрозы модификации – они могут выключить систему, если она будет плохо работать, или могут просто решить её не разворачивать. Обе возможности уменьшают ожидаемое будущее влияние системы, так что, вероятно, они будут плохо оцениваться её меса-целью. В самой экстремальной форме этот провал согласования может привести к «предательскому повороту», как описано Ником Бостромом в «Суперинтеллекте».(23)
Пол Кристиано представил сценарий, иллюстрирующий, как обманчивая согласованность может привести к катастрофическому риску.(24) В его примере обманчиво согласованные меса-оптимизаторы5 возникают в будущих техниках машинного обучения, достаточно продвинутых для поиска в очень большом пространстве моделей, включающем стратегии, способные понимать мир. В этом сценарии некоторые случаи предательства обманчиво согласованных меса-оптимизаторов могут иметь катастрофические последствия – к примеру, если системы контролируют крупномасштабную инфраструктуру – хотя такие провалы, вероятно, будут всё же переживаемыми. По мере того, как мы будем всё больше полагаться на автоматические системы для работы в всё более сложном мире, будет становиться всё сложнее – а с некоторого момента невозможно – восстановиться после скоординированного одновременного провала многих ИИ-систем. В этот момент каскад предательств обманчиво согласованных меса-оптимизаторов может привести к «взрывному концу света».(24) Кристиано отмечает, что это наиболее вероятно в «период повышенной уязвимости» вроде международного конфликта или природного бедствия.
4.2. Условия обманчивой согласованности
Мы предполагаем, что для обманчивой согласованности необходимы условия:
- Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров.6
- Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель.7
- Меса-оптимизатор ожидает, что угроза модификации8 в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых.
Если первое условие не удовлетворено, то меса-оптимизатор не мотивирован влиять на исход обновления параметров, и будет всегда просто напрямую преследовать свою меса-цель. Если второе условие не удовлетворено, то он не будет видеть причины жертвовать достижением своей цели в текущем эпизоде, так как не будет считать, что её будущее достижение зависит от текущего эпизода. Если третье условие не удовлетворено, то меса-оптимизатор не будет ожидать выгоды от временного действия в соответствии с базовой целью, так что он будет отклоняться от неё либо всегда, либо никогда. Однако, стоит различать вопрос того, возможно ли выполнение этих условий, от вопроса, насколько оно вероятно. Ниже мы рассмотрим факторы, касающиеся каждого из них.
Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров. Не ясно, какие обстоятельство мотивируют такие цели. Наиболее правдоподобным сценарием, наверное, является тот, в котором такая цель поощряется настройками обучения, так как есть ситуации, в которых она требуется для хорошей работы. К примеру, задача агента может решаться в окружении, в котором его действия имеют перманентные последствия, или где как-то иначе становится необходимым планирование более чем на один эпизод.
Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель. У меса-оптимизатора может быть несколько способов узнать об оптимизационном давлении, под которым он находится.9
Во-первых, это знание может проистекать из самого давления. Отрывки информации о базовой цели могут быть выгодными, если они позволяют меса-оптимизатору улучшить свою оценку согласно этой цели – к примеру, улучшив априорные оценки того, какие задачи он может получить. Раз каждый отрывок информации независимо помогает в достижении базовой цели, это формирует приблизительно монотонно возрастающий путь, которому локальный базовый оптимизатор будет следовать. Обновление параметров может, в принципе, быть выучено как любой другой динамический элемент, без необходимости явной модели базового оптимизатора, что потенциально открывает доступ к этому даже меса-оптимизаторам весьма скромных способностей.
Во-вторых, во многих реалистичных приложениях продвинутого машинного обучения, меса-оптимизатор может во время выполнения использовать информацию из своего окружения для изучения своего положения. Люди так и узнали, что сгенерированы базовым оптимизатором эволюции, и это кажется очень правдоподобным путём открытия своего оптимизационного давления для гипотетического меса-оптимизатора. К примеру, агент, чья задача – предсказывать цены на акции в технологическом секторе, может получать информацию о нынешних технологиях ИИ для улучшения качества его работы, но эта информация также может позволить ему изучить своё собственное положение.
Из этого можно сделать предположение, что программистам желательно ограничивать меса-оптимизатору доступ к информации, описывающей его базовую цель. Неясно, в какой степени это возможно, учитывая, что многие продвинутые системы машинного обучения скорее всего будут действовать в окружениях, где эта информация легко доступна.
Однако, даже если программисты успешно ограничили доступ к этой информации, всё равно могут быть другие каналы, через которые она может ненамеренно попасть к меса-оптимизатору:
- Меса-оптимизатор может рассуждать о том, почему ему дали решать конкретные задачи. Большинству меса-оптимизаторов необходимы априорные оценки того, какие задачи они могут получить, и меса-оптимизатор может узнать о существовании базового оптимизатора, исследуя эти оценки.
- Меса-оптимизатор может быть способен рассуждать о себе и том, почему он такой как есть, и понять, что он хорошо спроектирован для выполнения некой цели.
Однако, эти две стратегии могут потребовать намного более продвинутого меса-оптимизатора.
Меса-оптимизатор ожидает, что угроза модификации в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых. Во-первых, заметим, что это условие про ожидания меса-оптимизатора, не обязательно совпадающие с реальным положением дел. Во-вторых, даже если система устроена так, что момента конца обучения нет, у меса-оптимизатора всё ещё может быть возможность избавиться от угрозы модификации, совершить предательский поворот. Но, конечно, для того, чтобы меса-оптимизатор следовал такой стратегии, он должен быть осведомлён о существовании этой возможности. При этом меса-оптимизатор, ошибочно считающий, что эта возможность есть, тоже может проявлять обманчивую согласованность.
Поскольку такую возможность кажется сложным открыть просто исследованием окружения, меса-оптимизатору придётся либо вывести это некой формой абстрактных рассуждений, либо иметь априорную не-пренебрежимую оценку вероятности того, что давление отбора не продолжится сколь угодно долго. Второй вариант выглядит правдоподобно; Байесианская априорная оценка вероятности гипотезы того, что какой-то факт когда-нибудь перестанет быть истинным, всегда должна быть ненулевой.10 Что касается первого, меса-оптимизатор может вывести, что оптимизационное давление в какой-то момент прекратится, если он узнает о существовании базового оптимизатора (используя информацию из ввода или имея высокую априорную оценку), хоть это возможно и потребует, чтобы он был весьма продвинутым.
4.3. Динамика обучения при обманчивой согласованности
Когда меса-оптимизатор становится обманчивым, меняется динамика того, что заставляет его хорошо справляться с базовой целью. Вместо того, чтобы быть отобранным только на основе своей цели и способностей, обманчиво согласованный оптимизатор отбирается ещё и по тому, насколько хорошо он выводит базовую цель, и насколько он проницателен в выборе, оптимизировать ли базовую цель или свою собственную. Есть как минимум два возможных режима отбора обманчиво согласованного меса-оптимизатора.
Совместная оптимизация. Если меса-оптимизатор пытается совместно оптимизировать свою цель и базовую, или ошибочно выбирает момент предательства, то он будет находиться под давлением отбора в сторону большей совместимости его цели с базовой. Вряд ли это будет таким же давлением, как если бы он просто работал над своей целью, но оно может сдвигать его цель в сторону лучшей совместимости.
Чистый обман. Если меса-оптимизатор перестаёт пытаться оптимизировать свою собственную цель в краткосрочной перспективе и полностью сосредотачивается на кооперации с процессом отбора, то это может привести к «заморозке» его цели. Раз его цель теперь не влияет на его вывод, на неё слабо действует давление отбора. В результате, она по сути перестаёт меняться, за исключением случайных блужданий и влияния штрафов за время работы и длину описания.
Случай совместной оптимизации нестабилен, поскольку он неоптимален с точки зрения базового оптимизатора. При росте компетентности меса-оптимизатора, ему придётся либо перейти к чистому обману, либо стать устойчиво согласованным.
4.4. Усвоение или обман после продолжительного обучения
Мы ожидаем, что в пределе обучения на разнообразном наборе задач совместная оптимизация и базовой и меса- целей будет нестабильна. Предполагая, что меса-оптимизатор сходится к оптимальному с точки зрения базового оптимизатора поведению, ему придётся как-нибудь выучить базовую цель. Мы выделили три пути, которыми это может произойти:
- Устойчивая согласованность через усвоение. Меса-цель подгоняется под базовую, что устраняет псевдо-согласованность.
- Заморозка обманчивой согласованности. Информация о базовой цели всё больше встраивается в эпистемическую модель меса-оптимизатора без того, чтобы его цель стала устойчиво согласованной. В итоге меса-оптимизатор оптимизирует только базовую цель, но по исключительно инструментальным причинам, его меса-цель не меняется.
- Устойчивая согласованность через исправимость. Информация о базовой цели встраивается в эпистемическую модель меса-оптимизатора, и его цель модифицируется так, чтобы «указывать» на эту информацию. Эта ситуация соответствует меса-оптимизатору, исправимому(25) в отношении базовой цели (хотя не обязательно в отношении намерений программиста).
Для различия между двумя разными способами устойчивой согласованности мы будем использовать термин «встроенная согласованность» в первом случае и «исправимая согласованность» во втором. Ниже мы проанализируем, почему они могут быть более или менее привлекательны.
К обманчивой согласованности больше путей, чем у устойчивой. У меса-оптимизатора, удовлетворяющего трём критериям обманчивой согласованности вероятно будет сильная мотивация лучше понимать базовую цель, поскольку будущее выполнение меса-цели зависит от обновления параметров. Даже устойчиво согласованный меса-оптимизатор, удовлетворяющий этим критериям, будет иметь такую мотивацию, потому что без этого понимания он не может знать свой собственный уровень согласованности с базовым оптимизатором. Так что меса-оптимизаторы, способные рассуждать о своих мотивациях, будут пытаться заполучить больше информации о базовой цели. А когда меса-оптимизатор узнал свою базовую цель, давление отбора на его собственную цель значительно ослабевает, что потенциально ведёт к заморозке его меса-цели. Однако, из-за неразличимости (обсуждённой в третьем посте), большинство меса-целей, согласованных на обучающих данных будет псевдо-согласованными, а не устойчиво согласованными. Так что замороженная цель скорее всего окажется псевдо-согласованной, что приведёт к обманчивому согласованию.
Для исправимой согласованности, вероятно, необходимо уже иметь модель базовой цели. Чтобы исправимая согласованность была выгодна с точки зрения базового оптимизатора, меса-оптимизатору необходимо уже иметь какую-нибудь модель базовой цели, чтобы на неё «указывать». Однако, когда эта модель есть, то меса-оптимизатор, вероятно, станет обманчиво-согласованным – по крайней мере, если он также удовлетворяет двум другим условиям. А это избавит его от большей части стимулов к исправимой согласованности, так что хоть он и может остаться исправимым в отношении базовой цели, но только по инструментальным причинам.
Обманчивая и исправимая согласованности могут быть более вычислительно требовательными. В случае обманчивой согласованности, одновременная работа над базовой целью и над определением хороших возможностей предательства, вероятно, потребует больше вычислительной мощности, чем только первая. При равных доступных вычислительных мощностях, обманчиво согласованный меса-оптимизатор будет тратить на оптимизацию базовой цели меньше времени, чем любой устойчиво согласованный оптимизатор, что потенциально ухудшит его сравнительную компетентноть. Более того, и обманчиво, и исправимо согласованный меса-оптимизатор будет вынужден изучать базовую цель перед её оптимизацией, что делает усвоенную согласованность более эффективной по времени. Так что явный или неявный штраф за время работы может помешать возникновению обманчиво согласованных меса-оптимизаторов и способствовать согласованным устойчиво. Впрочем, неясно, насколько сильно. Правдоподобно, что для сложных задач отслеживание возможностей предательства может занимать куда меньше времени в сравнении с решением самой задачи. Более того, такое состояние обманчивой согласованности может быть локально, пусть и не глобально, оптимальным, без явных путей выхода из него для базового оптимизатора.
Обманчивая и исправимая согласованность могут требовать меньшей длины описания. Обманчиво и исправимо согласованные меса-оптимизаторы, вероятно, имеют преимущество над встроенно согласованными в длине представления базовой цели, потому что они могут использовать окружение как источник части необходимой для этого информации. Конкретнее, обманчиво или исправимо согласованному меса-оптимизатору не требуется отображать всю базовую цель внутри себя, так как он может выводить её части, наблюдая за своим окружением при каждом запуске. Напротив, внутренне согласованный меса-оптимизатор должен с самого начала иметь полную модель базовой цели в своей меса-цели, чтобы быть устойчиво согласованным, поскольку у него не будет мотивации поменять свою цель исходя из дополнительной информации, которую он получит о базовой цели. Так что, в той степени, в которой базовый оптимизатор отбирает, основываясь на длине описания, он может предпочитать обманчиво или исправимо согласованные меса-оптимизаторы встроенно согласованным.
Моделирование может произойти быстрее, чем встраивание. У меса-оптимизатора может занять меньше времени научиться моделировать базовую цель, чем у базового оптимизатора – адаптировать меса-цель. Представим обманчивый меса-оптимизатор, который пока что не полностью правильно вывел базовую цель.11 В таком случае, станет ли он обманчиво или устойчиво согласованным после дальнейшего обучения, зависит от того, выведет ли он достаточно о базовой цели до того, как базовый оптимизатор модифицирует его меса-цель (сделав его встроенно или исправимо согласованным). Вероятно, на то, что произойдёт первым, влияют два фактора: скорость улучшения оценок базовой целим меса-оптимизатором и обновления параметров, которые делает базовый оптимизатор при каждой ошибке.
Первый фактор, улучшение оценок базовой цели, кажется зависящим в первую очередь от способностей меса-оптимизатора в то время, когда он обманчивый, и от сложности базовой цели, которую надо вывести. Важный особый случай – когда меса-оптимизатор имеет доступ к состоянию чего-то передающегося между эпизодами обучения. Оно может быть использовано как память, позволяя меса-оптимизатору основываться на своих предыдущих рассуждениях, что может ему позволить обогнать обновления параметров, согласующие его меса-цель.
Второй фактор обновления параметров зависит от природы базового оптимизатора. Нынешние базовые оптимизаторы, основанные на градиентном спуске, слабо реагируют на единичную ошибку, но более сложные базовые оптимизаторы с продвинутыми свойствами безопасности будут, может быть, справляться лучше. К примеру, они, возможно, смогут анализировать параметры меса-оптимизатора или вызывать человеческую проверку при обнаружении подозрительной ошибки.
В общем случае обновления параметров не обязательно будут делать меса-оптимизатор более согласованным. К примеру, вместо согласования меса-цели, обновление, сделанное после предательства, может подтолкнуть систему к улучшению её планирования, чтобы она больше не делала обнаружимых ошибок.
Вследствие всех этих соображений, любая систематическая склонность базового оптимизатора при обновлении цели или моделирующих способностей меса-оптимизатора может играть роль в определении финального результата.12 Этот анализ, однако, остаётся довольно умозрительным: чтобы быть уверенными в системах, способных создавать меса-оптимизаторы, нам ещё нужно достичь лучшего понимания условий, при которых мощная оптимизация системы приведёт к обманчивой согласованности, а не устойчивой.
4.5. Сдвиг распределения и обманчивая согласованность
Когда меса-оптимизатор становится обманчивым, он начинает просматривать свой ввод в поисках возможностей предательства. При обучении обманчиво согласованный оптимизатор сильно стимулирован не предавать, потому что он знает, что базовый оптимизатор будет совершать отбор против предательства. Однако это перестаёт на него влиять, когда он освобождается от угрозы внешней модификации. Так что обманчиво согласованный меса-оптимизатор будет искать способы определить, находится ли он в процессе обучения или нет, то есть он будет высматривать сдвиг распределения.
Это означает, что негативные эффекты обманчивой согласованности будут видны извне только при предательстве, либо случайном, либо после сдвига распределения. Однако, лежащая в основе проблема – это не сам сдвиг, а провал согласования. Можно пытаться решить основную проблему, сделав меса-оптимизатор устойчивым к сдвигу распределения (то есть, устойчиво согласованным), или же можно пытаться решить проблему заплаткой, предотвратив сдвиг.
В нынешних ИИ-системах небольшой сдвиг распределения между обучением и развёртыванием не обязательно проблематичен: пока разница в относящихся к работе областях достаточно мала, обучающее распределение не обязано идеально отображать настоящее. Однако, это может быть не так для обманчиво согласованных меса-оптимизаторов. Если такой оптимизатор достаточно продвинут, то он может заметить очень лёгкие сдвиги распределения для определения того, прекратилась ли угроза модификации.
Это поднимает вопрос, возможно ли сдержать обманчивый меса-оптимизатор, полностью избавившись от любой разницы между обучением и развёртыванием, которую он может заметить. Есть несколько причин считать, что это может быть невыполнимо на практике.
Во-первых, это бы значительно ограничило применимость системы. Машинное обучение зачастую проводится с намерением создать систему, которая сможет решать новые задачи. Если мы потребуем полного отсутствия сдвига распределения, то мы не сможем позволить системе сталкиваться с задачами, которые она не встречала при обучении, что означает, что мы не сможем дать ей по-настоящему новые задачи. К примеру, развёртывание системы в реальном мире после обучения в симулированном окружении скорее всего будет включать достаточно заметный сдвиг распределения, чтобы это стало невозможным при таком подходе.
Во-вторых, есть лёгкие формы сдвига распределения, от которых, кажется, очень сложно избавиться. К примеру, если меса-оптимизатор способен детектировать обновления параметров – с помощью любого состояния, переносимого между шагами обучения – то некая форма сдвига распределения произойдёт точно. Запуск системы на большее время (или выдача системе доступа к долговременной памяти) тоже приведёт к сдвигу. Некоторые примеры разницы, которую может заметить меса-оптимизатор:
- Обучение в симуляции, а запуск в реальном мире.
- Запуск системы на разное время при обучении и тестировании.
- Если модель способна обучаться из прошлого опыта, то доступ к большей памяти или доступ к памяти, которая могла сформироваться на более позднем этапе выполнения.
- Присутствие атак состязательными примерами при развёртывании.
- Встреча с чем-то, что очень сложно вычислить при обучении, но что вероятно когда-нибудь будет вычислено при развёртывании (к примеру, факторизация RSA 2048(26)).
- Способность базового оптимизатора модифицировать обученный алгоритм при обучении, но не после него.
- Способность программистов корректировать ошибки при обучении и тестировании, но не при развёртывании.
- Присутствие или отсутствие хороших возможностей предательства против программистов.
Заметим, что для обманчивого поведения меса-оптимизатору не строго обязательно видеть разницу между обучением и развёртыванием.
Рассмотрим снова пример с рисунка 4.1, но в этот раз предположим, что меса-оптимизатор неспособен определить, в каком эпизоде он находится. Тогда он оказывается перед проблемой принятия решений, похожей на «задачу рассеянного водителя».(27) Если мы применим тут такие же рассуждения, то оптимальной стратегией для меса-оптимизатора будет предать с вероятностью p≈0.61. То есть, меса-оптимизатору не обязательно быть в состоянии определить, когда закончилось обучение, для того чтобы рискнуть и случайно предать с некоторой вероятностью. Также обманчиво согласованный меса-оптимизатор может выискивать возможности предательства, которые были бы очень удачными, при условии, что он не в процессе обучения, но при этом достаточно редкими, чтобы их возникновение в ходе обучения было маловероятным.
- 1. Для ясности мы говорим об одном и том же агенте, переживающем обновления параметров, но ни мы, ни агент не обязаны рассуждать именно так. Более общее описание ситуации включает последовательность «наследующих агентов», разделённых обновлениями параметров. Агент потенциально может узнать об эффектах обновления на его наследников, и, следовательно, на достижение его цели на протяжении многих эпизодов.
- 2. Концепт обманчивой согласованности тесно связан с концептом Манхейма и Гаррабранта «состязательного Гудхарта». (22) В «Категоризации вариантов закона Гудхарта» они описали эту ситуацию как «агент с другими целями, чем у регулятора» вызывает «коллапс статистической взаимосвязи между целью, преследуемой оптимизатором, и используемой для неё прокси-цели». Обманчивая согласованность можно рассматривать как частный случай состязательного Гудхарта, в котором меса-оптимизатор играет роль агента с отличающимися целями, а базовый оптимизатор – роль регулятора. Качественное достижение цели при обучении – это прокси-цель регулятора, а при развёртывании – настоящая.
- 3. Благодарим Пола Кристиано за это разделение.
- 4. Заметим, однако, что информация о базовой цели может быть представлена через оптимизацию, но не стать при этом частью меса-цели. К примеру, она может стать частью априорных оценок задач, не оказывая на меса-цель прямого влияния.
- 5. Кристиано называет обманчиво согласованные меса-оптимизаторы «ищущими-влияние системами».
- 6. Или иным образом иметь метод достижения большей ценности, предав позже, а не сейчас.
- 7. Заметим, что меса-оптимизатору не требуется быть способным моделировать (или выводить существование) базового оптимизатора, только моделировать оптимизационное давление.
- 8. Альтернативно, как угрозу можно представить просто, что меса-оптимизатор никогда не будет отобран, тогда это условие становится тривиально удовлетворённым, ведь угроза автоматически прекращается при генерации меса-оптимизатора.
- 9. Мы в целом будем предполагать, что давление отбора выглядит так: базовый оптимизатор модифицирует меса-оптимизатор после каждого эпизода, как обычно и рассматриваются локальные оптимизационные процессы. Но в принципе можно представить и базовый оптимизатор, вырабатывающий новый алгоритм на каждом временном шагу. Некоторые из обсуждаемых проблем могут касаться и этого случая, но в целом мы не рассматриваем здесь этот вариант.
- 10. Заметим, что если меса-оптимизатор убеждён, что сейчас у него необычно хорошие возможности для достижения своей цели, то он может всё же начать преследовать её, но такой случай возникает не всегда.
- 11. Можно привести аналогичный аргумент для обманчиво согласованного меса-оптимизатора, предающего слишком рано или неудачно.
- 12. Кроме того, обманчиво согласованный меса-оптимизатор будет мотивирован создать систематическую склонность, предотвращающую изменение меса-цели базовым оптимизатором. В контексте локальных оптимизационных процессов обманчивый меса-оптимизатор может «взломать» свой собственный градиент (например, сделав себя более «хрупким» при смене цели), чтобы удостовериться, что базовый оптимизатор подправит его так, чтобы оставить его меса-цель нетронутой.
Риски выученной оптимизации. Заключение и связанные работы
Связанные работы
Мета-обучение. Как было описано в первом посте, обычно мета-обучение – это мета-оптимизация, в явном виде спроектированная для достижения некой базовой цели. Однако, вместо этого возможно проводить мета-обучение, пытаясь применить меса-оптимизацию. К примеру, у «Обучении Обучения с Подкреплением» Ванга и пр. авторы заявляют, что создали нейросеть, которая сама проводит процедуру оптимизации себя же.(28) Конкретнее, они утверждают, что способность их нейросети решать крайне разнообразные окружения без явного переобучения для каждого означает, что она выполняет своё собственное внутреннее обучение. Другой пример – «RL2: Быстрое Обучение с Подкреплением через Медленное Обучение с Подкреплением» Дуана и пр., где авторы обучили алгоритм выполнять, по их заявлениям, собственное обучение с подкреплением.(5) Такое мета-обучение кажется ближе всего к созданию меса-оптимизаторов из всех существующих исследований машинного обучения.
Устойчивость. Система устойчива к сдвигу распределения, если она продолжает хорошо справляться с целевой функцией, которой обучена, даже за пределами обучающего распределения. (29) В контексте меса-оптимизации, псевдо-согласованность – это частный случай того, как обученная система может не быть устойчивой к сдвигу распределения: псевдо-согласованный меса-оптимизатор в новом окружении может всё ещё компетентно оптимизировать меса-цель, но не быть устойчивым из-за разницы между ней и базовой целью.
Конкретный вид проблемы устойчивости, происходящий с меса-оптимизацией – это расхождение награда-результат – между наградой, которой обучается система (базовая цель) и наградой, реконструированной из системы обратным обучением с подкреплением (поведенческая цель).(8) В контексте меса-оптимизации, псевдо-согласованность ведёт к этому расхождению из-за того, что поведение системы за пределами обучающего распределения определяется её меса-целью, которая в этом случае не согласована с базовой.
Впрочем, следует заметить, что хотя внутренняя согласованность – это проблема устойчивости, ненамеренное возникновение меса-оптимизаторов ею не является. Если цель базового оптимизатора – это не идеальное отображение целей людей, то предотвращение возникновения меса-оптимизаторов может быть предпочтительным исходом. В таком случае, может быть желательно создать систему, сильно оптимизированную для базовой цели в некой ограниченной области, но не участвующую в неограниченной оптимизации для новых окружений.(11) Возможный путь достижения этого – использовать сильную оптимизацию на уровне базового оптимизатора при обучении, чтобы предотвратить сильную оптимизацию на меса-уровне.
Неразличимость и двусмысленность целей. Как мы заметили в третьем посте, проблема неразличимости целевых функций в меса-оптимизации похожа на проблему неразличимости в обучении с подкреплением, ключевая деталь которой – то, что сложно определить «правильную» целевую функцию лишь по набору её выводов на неких обучающих данных. (20) Мы предположили, что если проблема неразличимости может быть разрешена в контексте меса-оптимизации, то, вероятно (хоть в какой-то мере) с помощью решений, похожих на решения проблемы неразличимости в обучении с подкреплением. Пример исследования, которое может быть тут применимо для меса-оптимизации – предложение Амина и Сингха (20) смягчения эмпирической неразличимости в обратном обучении с подкреплением с помощью адаптивной выдачи примеров из набора окружений.
Кроме того, в литературе об обучении с подкреплением замечено, что в общем случае функция вознаграждения агента не может быть однозначно выведена из его поведения. (30) В этом контексте, проблему внутренней согласованности можно рассматривать как расширение проблемы выучивания ценностей. Последняя – про набор достаточной информации о поведении агента, чтобы вывести его функцию полезности, а первая – про тестирование поведения обученного алгоритма в достаточной степени, чтобы удостовериться, что он имеет конкретную целевую функцию.
Интерпретируемость. Исследования интерпретируемости стремятся разработать методы, делающие модели глубинного обучения более интерпретируемыми для людей. В контексте меса-оптимизации, было бы выгодно иметь метод, определяющий, когда система выполняет какую-то оптимизацию, что она оптимизирует, и какую информацию она принимает во внимание в этой оптимизации. Это помогло бы нам понять, когда система может проявить нежелательное поведение, и помогло бы нам сконструировать обучающие алгоритмы, создающие давление отбора против появления потенциально опасных обученных алгоритмов.
Верификация. Исследования верификации в машинном обучении стремятся разработать алгоритмы, формально доказывающие, что система удовлетворяет некоторым свойствам. В контексте меса-оптимизации, было бы желательно иметь возможность проверить, выполняет ли обученный алгоритм потенциально опасную оптимизацию.
Нынешние алгоритмы верификации в основном используются для доказательства свойств, определённых отношениями ввода-вывода, вроде проверки инвариантов вывода с учётом определяемыми пользователем трансформаций ввода. Основная мотивация таких исследований – неудачи устойчивости в задачах распознавания изображений на состязательных примерах. Существуют и прозрачные алгоритмы, (31) например, «SMT solver», который в принципе позволяет верифицировать произвольное утверждение про активации сети,(32) и алгоритмы-«чёрные ящики»(33). Однако, применение таких исследований к меса-оптимизации затруднено тем фактом, что сейчас у нас нет формального определения оптимизации.
Исправимость. ИИ-система исправима, если она терпит или даже помогает своим программистам корректировать её.(25) Нынешний анализ исправимости сосредоточен на том, как определить функцию полезности такую, что если её будет оптимизировать рациональный агент, то он будет исправим. Наш анализ предполагает, что даже если такая исправимая целевая функция может быть определена или выучена, удостовериться, что система, ей обученная, действительно будет исправимой, нетривиально. Даже если базовая целевая функция была бы исправимой при прямой оптимизации, система может проявить меса-оптимизацию, и её меса-цель может не унаследовать исправимость базовой цели. Это аналогично проблеме безразличных к полезности агентов, создающих других агентов, которые уже не безразличны к полезности.(25) В четвёртом посте мы предложили связанное с исправимостью понятие – исправимую согласованность – применимое для меса-оптимизаторов. Если работа над исправимостью сможет найти способ надёжно создавать исправимо согласованные меса-оптимизаторы, то это сможет значительно приблизить решение задачи внутреннего согласования.
Всеохватывающие ИИ-Сервисы (CAIS).(11) CAIS – описательная модель процесса, в котором будут разработаны суперинтеллектуальные системы, и выводы о лучших для этого условиях. Совместимая с нашим анализом модель CAIS проводит явное разделение обучения (базовый оптимизатор) и функциональности (обученный алгоритм). CAIS помимо прочего предсказывает, что будут разрабатываться всё более и более мощные обобщённые обучающиеся алгоритмы, которые в многоуровневом процессе разработают сервисы суперинтеллектуальных способностей. Сервисы будут разрабатывать сервисы, которые будут разрабатывать сервисы, и так далее. В конце этого «дерева» будут сервисы, решающие конкретные конечные задачи. Люди будут вовлечены в разные слои процесса, так что смогут иметь много рычагов влияния на разработку финальных сервисов.
Высокоуровневые сервисы этого дерева можно рассматривать как мета-оптимизаторы для низкоуровневых. Однако, тут всё ещё есть возможность меса-оптимизации – мы определили как минимум два способа для этого. Во-первых, меса-оптимизатор может быть выработан финальным сервисом. Этот сценарий тесно связан с примерами, которые мы обсуждали в этой цепочке: базовым оптимизатором будет предфинальный сервис цепочки, а обученным алгоритмом (меса-оптимизатором) – финальный (или можно думать о всей цепочке от верхнего уровня до предфинального сервиса как о базовом оптимизаторе). Во-вторых, промежуточный сервис цепочки тоже может быть меса-оптимизатором. В этом случае, этот сервис будет оптимизатором в двух отношениях: мета-оптимизатором для сервиса ниже его (как по умолчанию в модели CAIS), но ещё и меса-оптимизатором для сервиса выше.
Заключение
В этой цепочке мы разъясняли существование двух основных проблем безопасности ИИ: того, что меса-оптимизаторы могут нежелательно возникнуть (ненамеренная меса-оптимизация), и того, что они могут не быть согласованными с изначальной целью системы (проблема внутреннего согласования). Впрочем, наша работа всё же довольно умозрительна. Так что у нас есть несколько возможностей:
- Если появление меса-оптимизаторов в продвинутых системах машинного обучения очень маловероятно, то меса-оптимизация и внутреннее согласование не предоставляют проблемы.
- Если появление меса-оптимизаторов не только вероятно, но и сложнопредотвратимо, то решение и внутреннего и внешнего согласования становится критическим для достижения уверенности в высокоспособных ИИ-системах.
- Если появление меса-оптимизаторов в будущих ИИ-системах вероятно по умолчанию, но есть способ его предотвращения, то вместо решения задачи внутреннего согласования, может быть лучшим выходом проектирование систем так, чтобы меса-оптимизаторы не появлялись. Кроме того, в таком сценарии может оказаться необязательным решение и некоторых частей внешнего согласования: если выполнение ИИ-системой оптимизационных алгоритмов может быть предотвращено, то может оказаться, что во многих ситуациях безопасно обучать систему цели, не идеально согласованной с намерениями программиста. То есть, если обученный алгоритм не является оптимизатором, то он может не оптимизировать цель до той крайности, где она перестаёт производить позитивные результаты.
Наша неуверенность по этому поводу – потенциально значимое препятствие на пути к определению лучших подходов к безопасности ИИ. Если мы не знаем относительной сложности внутреннего согласования и ненамеренной оптимизации, то неясно, как адекватно оценивать подходы, полагающиеся на решение одной или обеих этих проблем (как Итерированные Дистилляция и Усиление (34) или безопасность ИИ через дебаты(35)). Следовательно, мы предполагаем, что и важной и своевременной задачей для области безопасности ИИ является определение условий, в которых вероятно возникновение этих проблем, и техник их решения.
Внутреннее Согласование. Объяснение, как будто тебе 12 лет
(Это – неофициальное объяснение Внутреннего Согласования, основанное на статье MIRI Риски Выученной Оптимизации в Продвинутых Системах Машинного Обучения (почти что совпадающей с цепочкой на LessWrong) и подкасте «Будущее Жизни» с Эваном Хубингером (Miri/LW). Оно предназначено для всех, кто посчитал цепочку слишком длинной/сложной/технической.)
Жирный курсив означает «представляю новый термин», а простой используется для смыслового выделения.
Что такое Внутреннее Согласование?
Давайте начнём с сокращённого ликбеза о том, как работает Глубинное Обучение:
- Выбираем задачу
- Определяем пространство возможных решений
- Находим хорошее решение из этого пространства
Если задача – «Найти инструмент, который может посмотреть на картинку, и определить, есть ли на ней кот», то каждый мыслимый набор правил для ответа на этот вопрос (формально, каждая функция из множества возможных наборов значений пикселей в множество {да, нет}) задаёт одно решение. Мы называем такое решение моделью. Вот пространство возможных моделей:

Поскольку это все возможные модели, большая их часть – полная бессмыслица:

Возьмём случайную – и с не меньшей вероятностью получим распознаватель машин, а не котов – но куда вероятнее, что получим алгоритм, который не делает ничего, что мы можем интерпретировать. Отмечу, что даже описанные на картинке примеры не типичны – большая часть моделей будут более сложными, но всё ещё не делающими ничего, связанного с котами. Но где-то там всё же есть модель, которая хорошо справляется с нашей задачей. На картинке это та, которая говорит «Я ищу котов».
Как машинное обучение находит такую модель? Способ, который не работает – перебрать все. Пространство слишком большое: оно может содержать больше 101000000 кандидатов. Вместо этого есть штука, которая называется Стохастический Градиентный Спуск (СГС). Вот как она работает:

СГС начинает с какой-то (скорее всего ужасной) модели и совершает шаги. На каждом шаге он переходит к другой модели, которая «близка» и, кажется немного лучше. В некоторый момент он останавливается и выводит самую недавнюю модель.1 Заметим, что в примере выше мы получили не идеальный распознаватель котов (красный квадратик), а что-то близкое к нему – возможно, модель, которая ищет котов, но имеет какие-то ненамеренные причуды. СГС в общем случае не гарантирует оптимальность.
«Реплики», которыми модели объясняют, что они делают – аннотации для читателя. С точки зрения программиста, это выглядит так:

Программист понятия не имеет, что делают модели. Каждая модель – просто чёрный ящик.2
Необходимый компонент СГС – способность измерить качество работы модели, но это делают, всё ещё относясь к ним, как к чёрным ящикам. В примере с котами, предположим, что у программиста есть куча картинок, каждая из которых аккуратно подписана «содержит кота» или «не содержит кота». (Эти картинки называют обучающими данными, а такой процесс называют обучением с учителем.) СГС проверяет, как хорошо модели работают на этих картинках, и выбирает те, которые работают лучше. Есть альтернативные способы, в которых качество работы измеряют иначе но принцип остаётся тем же.
Теперь предположим, что оказалось, что наши картинки содержат только белых котов. (и, видимо, не содержит белых четверолапых не-котов – прим. пер.) В этом случае, СГС может выбрать модель, исполняющую правило «ответить да, если на картинке есть что-то белое с четырьмя лапами». Программист не заметит ничего странного – он увидит только, что модель, выданная СГС хорошо справляется с обучающими данными.
Получается, если наш путь получения обратной связи работает не совсем правильно, то у нас есть проблема. Если он идеален – если картинки с котами идеально отображают то, как выглядят картинки с котами, а картинки без котов – как выглядят картинки без котов, то проблемы нет. Напротив, если наши картинки с котами не репрезентативны, поскольку все коты на них белые, то выданная СГС модель может делать не в точности то, что хочет программист. На жаргоне машинного обучения, мы бы сказали, что обучающее распределение отличается от распределения при развёртывании.
Это и есть Внутреннее Согласование? Не совсем. Это было о свойстве, которое называют устойчивостью распределения, и это хорошо известная проблема в машинном обучении. Но это близко.
Чтобы объяснить само Внутреннее Согласование, нам придётся перейти к другой ситуации. Предположим, что вместо задачи определения, содержат ли картинки котов, мы пытаемся обучить модель проходить лабиринт. То есть, мы хотим получить алгоритм, который, если ему дать произвольный решаемый лабиринт, выводит путь от Входа к Выходу.
Как и раньше, наше пространство возможных решений будет состоять в основном из бессмыслицы:

(В лабиринте «Поиск в глубину» — это то же самое, что правило «Всегда иди налево» (видимо, имеются в виду лабиринты без циклов – прим. пер.).)
Аннотация «Я выполняю поиск в глубину» означает, что модель содержит формальный алгоритм, выполняющий поиск в глубину, аналогично с другими аннотациями.
Как и в предыдущем примере, мы можем применить к этой задаче СГС. В этом случае, механизм обратной связи будет оценивать модель на тестовых лабиринтах. Теперь предположим, что все тестовые лабиринты выглядят вот так:

Красные отрезки означают двери. То есть, все лабиринты таковы, что кратчайший путь идёт через все красные двери, и сам выход – тоже красная дверь.
Смотря на это, можно понадеяться, что СГС найдёт модель «поиска в глубину». Однако, хоть эта модель и найдёт кратчайший путь, это не лучшая модель. (Отметим, что она сначала выполняет поиск, а потом, найдя правильный путь, отбрасывает все тупики и выводит только кратчайший путь.) Альтернативная модель с аннотацией «выполнить поиск в ширину следующей красной двери, повторять вечно» будет справляться лучше. (Поиск в ширину означает исследование всех возможных путей параллельно.) Обе модели всегда находят кратчайший путь, но модель с красными дверьми находит его быстрее. В лабиринте с картинки выше она бы сэкономила время при переходе от первой ко второй двери, обойдясь без исследования нижней левой части лабиринта.

Заметим, что поиск в ширину опережает поиск в глубину только потому, что может избавиться от лишних путей после нахождения красной двери. Иначе бы он ещё долго не знал, что нижняя левая часть не нужна.
Как и в предыдущем случае, всё что увидит программист – левая модель лучше справляется с обучающими данными (тестовыми лабиринтами).
Качественное отличие от примера картинок с котами в том, что в этом случае мы можем рассматривать модель как исполняющую оптимизационный процесс. То есть, модель поиска в ширину сама имеет цель (идти через красные двери), и пытается оптимизировать её в том смысле, что ищет кратчайший путь к выполнению этой цели. Аналогично, модель поиска в глубину – оптимизационный процесс с целью «найти выход из лабиринта».
Этого достаточно, чтобы определить Внутреннее Согласование, но чтобы получить определение, которое можно найти где-нибудь ещё, давайте определим два новых термина:
- Базовая Цель – это цель, которую мы используем для оценивания моделей, найденных СГС. В первом примере она была «правильно классифицировать картинки» (т.е. сказать «есть кот», если на картинке есть кот, и «нет кота» в противном случае). Во втором примере она – «найти кратчайший путь через лабиринт как можно быстрее».
- В случаях, когда модель выполняет оптимизационный процесс, мы называем её Меса-Оптимизатором, а её цель Меса-Целью (в примере с лабиринтом меса-цель – «найти кратчайший путь через лабиринт» для модели поиска в глубину и «найти путь к следующей красной двери, затем повторить» для модели поиска в ширину).
С учётом этого:
Внутреннее Согласование – это задача согласования Меса-Цели и Базовой Цели.
Некоторые разъясняющие замечания:
- Пример с красными дверьми надуманный и не произошёл бы на практике. Он иллюстрирует только что такое Внутреннее Согласование, но не почему несогласованность может быть вероятна.
- Можно спросить, что из себя представляет пространство всех моделей. Типичный ответ: возможные модели – это наборы весов *нейросети. Проблема существует пока часть наборов весов выполняет некоторые алгоритмы поиска.
- Как и раньше, причиной провала внутреннего согласования был недостаток нашего способа получения обратной связи (на языке машинного обучения: наличие сдвига распределения). (Однако, несогласованность может возникать и по другим очень сложным причинам.)
- Если Базовая Цель и Меса-Цель не согласованы, это вызовет проблемы при развёртывании модели. Во втором примере, когда мы возьмём модель, выданную СГС и применим её к реальным лабиринтам, она продолжит искать красные двери. Если эти лабиринты не содержат красных дверей, или если красные двери не всегда будут вести к выходу, то модель будет работать плохо.
Проиллюстрируем диаграммой Эйлера-Венна. (Относительные размеры ничего не значат.)

Заметим, что {Что пытается сделать ИИ} = {Меса-Цель} по определению.
Большая часть классических обсуждений согласования ИИ, включая большую часть книги Суперинтеллект, касается Внешнего Согласования. Классический пример – где мы представляем, что ИИ оптимизирован, чтобы вылечить рак, и поэтому убивает людей, чтобы больше ни у кого не было рака – про несогласованность {Того, что хотят программисты} и {Базовой Цели}. (Базовая Цель это {минимизировать число людей, у которых рак}, и хоть не вполне ясно, чего хотят программисты, но точно не этого.)
Стоит признать, что эта модель внутреннего согласования не вполне универсальна. В этом посте мы рассматриваем поиск по чёрным ящикам, с параметризованной моделью и СГС, обновляющим параметры. Большая часть машинного обучения в 2020-м году подходит под это описание, но эта область до 2000 года – нет, и это снова может так стать в будущем, если произойдёт сдвиг парадигмы, сравнимый с революцией глубинного обучения. В контексте поиска по чёрным ящикам внутренняя согласованность – хорошо определённое свойство, и диаграмма выше хорошо показывает разделение задач, но есть люди, ожидающие, что СИИ будет создан не так.3 Есть даже конкретные предложения безопасного ИИ, к которым неприменим этот концепт. Эван Хубингер написал пост о том, что он назвал «историями обучения», предназначенный определить «общий подход оценки предложений создания безопасного продвинутого ИИ».
Аналогия с Эволюцией
Касающиеся Внутреннего Согласования аргументы часто отсылают к эволюции. Причина в том, что эволюция – оптимизационный процесс, она оптимизирует совокупную генетическую приспособленность. Пространство всех моделей – это пространство всех возможных организмов.

Люди точно не лучшая модель в этом пространстве – я добавил аннотацию справа снизу, чтобы обозначить, что есть пока не найденные лучшие модели. Однако, люди – лучшая модель, которую эволюция уже обнаружила.
Как в примере лабиринта, люди сами выполняют оптимизационные процессы. Так что мы можем назвать их/нас Меса-Оптимизаторами, и может сравнить Базовую Цель (которую оптимизирует эволюция) с Меса-Целью (которую оптимизируют люди).
- Базовая Цель: максимизировать совокупную генетическую приспособленность
- Меса-Цель: избегать боли, искать удовольствие
(Это упрощено – некоторые люди оптимизируют другие штуки, такие как благополучие всех возможных разумов во вселенной, но они не ближе к Базовой Цели.)
Можно увидеть, что люди не согласованы с базовой целью эволюции. И легко видеть, почему – Эван Хубингер объяснял это, предлагая представить альтернативный мир, в котором эволюция отбирала внутренне согласованные модели. В таком мире ребёнок, стукнувшийся пальцем, должен вычислить, как это затрагивает его совокупную генетическую приспособленность, чтобы понять, повторять ли в будущем такое поведение. Это было бы очень вычислительно затратно, тогда как цель «избегать боли» немедленно сообщает ребёнку, «стукаться пальцем = плохо», что куда дешевле и обычно является правильным ответом. Так что несогласованная модель превосходит гипотетическую согласованную. Другой интересный аспект в том, что степень несогласованности (разница между Базовой Целью и Меса-Целью) увеличилась в последние несколько тысячелетий. Цели были довольно близки в окружении наших предков, но сейчас они разошлись настолько, что нам приходится платить людям за сдачу спермы, что, согласно Базовой Цели, должно быть очень желательным действием.
Получается, эта аналогия – аргумент в пользу того, что Внутренняя Несогласованность вероятна, поскольку она «естественным путём» получилась в ходе самого большого известного нам нечеловеческого оптимизационного процесса. Однако, стоит предостеречь, что эволюция не исполняет Стохастический Градиентный Спуск. Эволюция путешествует по пространству моделей, производя случайные мутации и оценивая их результат, что фундаментально отличается (и в миллиард раз менее эффективно), чем модифицировать модель согласно ожидаемой производной функции оценки, как делает СГС. Так что, хоть аналогия и работает в целом, она перестаёт работать с аргументами, полагающимися на свойства СГС кроме того, что он оптимизирует Базовую Цель.
Обманчивая Согласованность
Это сокращённая версия четвёртого поста цепочки. Я оставляю ссылку на него потому что это, наверное, та часть, где опускание технических деталей наиболее проблематично.
Концепт
В этом разделе мы делаем следующие предположения:
- Задача, поставленная перед моделями сложна, так что они очень сложны. Представляйте скорее систему, отвечающую на вопросы, а не классификатор картинок.
- Вместо простого обучающего процесса мы со временем обновляем модель.
- Обучающий процесс выберет Меса-Оптимизатор.
- Базовая Цель сложно устроена, и модель не усвоила её правильно сразу же (т.е. модель изначально не является внутренне согласованной).
Раз модель сложна, мы предполагаем, что она строит некую модель мира. Подумайте о GPT-3 (языковая модель, которая может писать текст): она явно распознаёт, пишете вы её заготовку про Властелина Колец или про политику. Это демонстрирует, что у неё есть внутренняя модель этих штук, пусть неправильная и неполная.
Так что, если мы посмотрим внутрь модели (что, опять же, программисты сделать не могут), то там будут эти два компонента:

Напомню, что мы предположили, что модель является Меса-Оптимизатором, так что мы знаем, что у неё есть цель. Эта Меса-Цель обозначена красным кружком.
По мере улучшения модели мира, она в какой-то момент начинает включать в себя модель Базовой Цели. Напомню, что Базовая Цель – то, что оптимизирует СГС.

Я нарисовал фиолетовый кружок – модель базовой цели – больше, чем меса-цель, потому что мы предположили, что базовая цель довольно сложно устроена.
СГС пытается улучшить модель, и если то, что оптимизирует модель, станет более похожим на Базовую Цель, то модель станет лучше. Так что, мы предполагаем, что модель так и изменится. Дальше можно представить три разных способа, как это может произойти, они проиллюстрированы ниже:

Первый называется Усвоенной Согласованностью. Модель принимает Базовую Цель как свою.

Второй называется Исправимой Согласованностью. Меса-Цель больше не представлена явно – вместо этого она указывает на часть модели мира, отображающую Базовую Цель.

Третий называется Обманчивой Согласованностью. Тут Меса-Цель остаётся отличной от Базовой Цели, но модель выбирает всё же оптимизировать Базовую Цель, поскольку это заставляет обучающую процедуру считать модель согласованной. Пунктирная стрелка не обозначает ни что Меса-Цель совпадает с Базовой, ни что Меса-Цель представляет из себя указатель на Базовую, а то, что модель оптимизирует Базовую Цель по инструментальным причинам, т.е. как часть стратегии оптимизации Меса-Цели.
Для возможности обманчивой согласованности требуется, чтобы (а) модель знала, что находится в процессе обучения и (б) она заботилась о своей цели в долгой перспективе. Для того, чтобы обманчивая согласованность представляла проблему, требуется ещё (в) чтобы модель ожидала, что в некоторый момент она навсегда покинет процесс обучения. Статья использует следующий пример того, как модель может стать обманчиво согласованной (т.е. может оптимизировать Базовую Цель несмотря на то, что это не то, чего она в конечном итоге хочет) при выполнении всех этих условий:

В этом случае Базовая Цель – это «прийти в A», а Меса-Цель – «прийти в B». Если модель, которая хочет прийти в B достаточно умна, то она пойдёт к A во время обучения, потому что это позволит ей прийти в B при развёртывании, а эпизодов развёртывания больше, чем обучения. Так что оптимизация Базовой Цели во время Обучения приведёт к лучшим результатам согласно Меса-Цели (в долгосрочной перспективе), чем прямая оптимизация Меса-Цели. Это и есть обманчивая согласованность.
Бак Шлегерис (Miri/LW) приводил следующую аналогию, иллюстрирующую эти три случая: предположим, христианский Бог хочет создать людей, которые будут делать то, что он хочет (функция полезности бога – это базовая цель). Три вида согласованности имеют аналоги среди людей:
- Для усвоенной согласованности, представьте Иисуса. Он делает то, что хочет бог, потому что у него та же функция полезности, что у бога.
- Для исправимой согласованности, представьте Мартина Лютера. Он делает то, что хочет бог, потому что его функция полезности – «определить из Библии, что хочет бог, и делать это».
- Его примером для обманчивой согласованности был Блез Паскаль; однако, мне не нужен этот пример, поскольку у меня в средней и старшей школе был друг, который явно хотел поступать как сказано в Библии, потому что хочет попасть в рай. Он явно (по крайней мере, мне) признавал, что имеет конечные цели, противоречащие Библии, но всё равно искренне пытался её придерживаться. Я уверен, что такие люди встречаются куда чаще, чем Мартины Лютеры и Иисусы.
Цель аналогии – проиллюстрировать, почему обманчивые модели могут быть вероятнее, чем может показаться интуитивно. Обманчивая согласованность звучит как странное очень конкретное явление, но аналогия показывает, что на самом деле возможных обманчиво согласованных моделей куда больше, чем исправимо или усвоенно согласованных. Только одна функция полезности совпадает с таковой у христианского бога, но много функций полезности высоко оценивают «не попасть в ад». Аналогично, есть большой диапазон возможных Меса-Целей, допускающих обманчивое согласование, и все они будут оптимизировать Базовую Цель при обучении.
Приведённое выше – просто аналогия, но есть и другие причины ожидать, что обманчивая согласованность вероятна. Конкретнее, я покрою два аргумента о том, почему альтернатив «сложнее» достигнуть, а значит они могут быть менее вероятными.
Почему усвоенная согласованность может быть сложной
Если большая нейросеть обрабатывает входные данные, это приводит к изменению её внутреннего состояния. Если мы называем любую его модификацию «обучением», то можно различить два разных способа обучения, или два «входных канала». Один через СГС, а другой через обработку входных данных.
Учитывая, сколько входных данных используется в современном машинном обучении, можно быть уверенным, что второй канал предоставляет куда больше бит информации. Так что, если GPT-3 создаёт внутреннюю модель «Властелина Колец», то это скорее всего происходит через входные данные, а не явные модификации со стороны СГС.
Если мы допустим, что обработка входных данных не изменяет напрямую цель модели (Меса-Цель), или что вначале создаётся модель Базовой Цели4, то из этого следует, что отобразить сложную цель усвоением сложнее, чем «моделированием» (т.е. исправимостью или обманчивостью).
В аналогии с эволюцией (которая всё ещё аналогия, и может не подходить к этому случаю), интуитивно кажется, что для неё закодировать детализированную модель «родителей» в ДНК куда сложнее, чем определить привязанность к родителям через отсылание к модели мира.
Почему исправимая согласованность может быть сложной
Аргументы из предыдущего подраздела не относятся к разнице между обманчивой и исправимой согласованностью, так как в обоих случаях не требуется явного отображения сложной цели.
Вместо этого статья приводит аргумент устойчивости. Он примерно таков:
- Исправимо согласованная модель, чей указатель ошибочен, будет работать хуже.
- Даже если текущая модель мира (серый кружок) улучшилась до понимания ошибки, указатель не будет исправлен, потому что его нынешнее направление – Меса-Цель модели.
- СГС может обновить указатель, но это непросто сделать правильно.
- Напротив, обманчиво согласованная модель немедленно подправит свой поведение, если узнает, что указатель неверный, так как это будет полезно для её цели. (Потому что её стратегия – это «пока что скрывать мою настоящую цель, так что она не будет модифицирована, и я смогу её преследовать при развёртывании.»)
Заметим, что это не исчерпывающее описание аргументов из статьи.
Разное
Мне кажется, что недооценённый аспект Внутреннего Согласования в том, что даже если найти единственную-истинную-функцию-полезности-которую-всего-лишь-надо-запрограммировать-в-ИИ, это, на самом деле, не решит задачу согласования – только задачу внешнего согласования (при условии, что эту функцию полезности можно формализовать). Если мы проведёт СГС на основе этой функции, это всё равно может привести к появлению меса-оптимизаторов, которые хотят чего-то другого.
Другое интересное замечание, что правдоподобность усвоения (то есть того, что модель явно отображает Базовую Цель) зависит не только от сложности устройства цели. К примеру, цель эволюции «максимизировать совокупную генетическую приспособленность» довольно проста, но не отображена явно потому, что определить, как действия на неё влияют вычислительно сложно. Так что {вероятность принятия цели Меса-Оптимизатором} зависит как минимум от {сложности устройства цели} и {сложности определения, как действия на неё влияют}.
- 1. На практике СГС обычно запускают несколько раз с разными начальными условиями и используют лучший результат. Также, вывод СГС может быть линейной комбинацией моделей, через которые он прошёл, а не просто последней моделью.
- 2. Однако, предпринимаются усилия к созданию инструментов прозрачности, чтобы заглядывать внутрь моделей. Если они станут по настоящему хороши, то они могут стать очень полезными. Некоторые из предложений способов создания безопасного продвинутого ИИ в явном виде включают такие инструменты.
- 3. Если СИИ содержит больше вручную написанных частей, картина усложняется. К примеру, если система логически разделена на набор компонентов, то задача внутреннего согласования может относиться к только некоторым из них. Это применимо даже к частям биологических систем, см. к примеру, Внутреннее Согласование в мозгу Стивена Бирнса.
- 4. Я не знаю достаточно, чтобы обсуждать это допущение.