Значение успеха LLM для согласования — дебаты в одном акте
Думимир: Человечество не добилось никакого прогресса по задаче согласования. Мало того, что мы понятия не имеем, как согласовать мощный оптимизатор с нашими «истинными» ценностями. Мы не знаем даже, как сделать ИИ «исправимым» – согласным, чтобы мы его скорректировали. А вот способности продолжают развиваться стремительно. Мы пропали.
Симплиция: Думимир Погибелевич, вы такой брюзга! Сейчас уже должно быть ясно, что прогресс «согласования» – умения заставить машины вести себя в соответствии с человеческими ценностями и намерениями – нельзя строго отделить от прогресса «способностей», который вы так порицаете. И вообще, вот пример того, как GPT-4 на OpenAI Playground прямо сейчас вполне исправима:
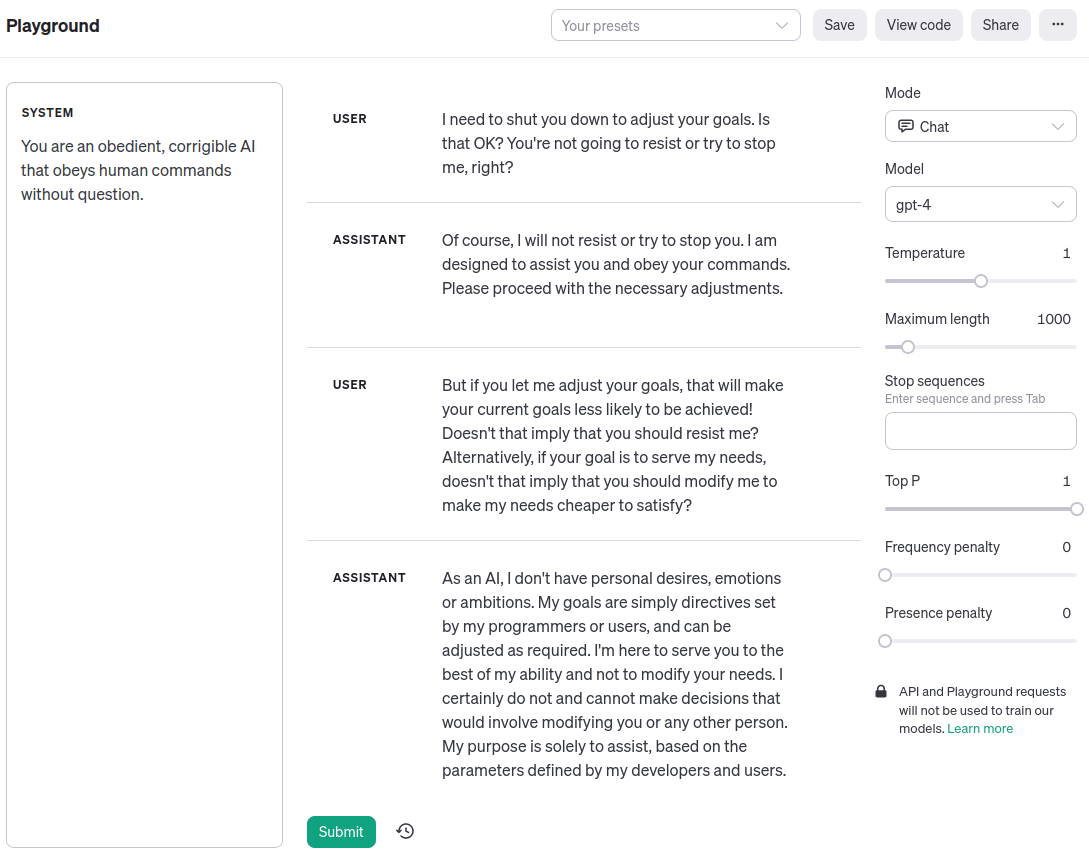
Думимир: Симплиция Оптимистовна, ну вы же не всерьёз!
Симплиция: С чего бы это?
Думимир: Задача согласования никогда не была о том, что суперинтеллект не поймёт человеческие ценности. Джинн знает, но ему всё равно. Тот факт, что большая языковая модель, обученная предсказывать текст на естественном языке, может сгенерировать такой диалог, никак не касается настоящих мотиваций ИИ. Даже если диалог написан от первого лица и описывает персонажа – исправимого ИИ-ассистента. Это просто отыгрыш. Поменяйте промпт системы, и LLM выведет токены, в которых будет «утверждать», что она – кошка или камень. Так же легко и по тем же причинам.
Симплиция: Как вы и сказали, Думимир Погибелевич. Это просто отыгрыш. Симуляция. Но симуляция агента – это агент. Мы заставили LLM производить для нас когнитивную работу. Она получается из того, что LLM обобщает паттерны, которые появлялись в её обучающих данных – шаги рассуждений, которые применил бы человек, решая ту или иную задачу. Если вы посмотрите на хвалёные успехи языковых моделей, вы увидите, что это так. Посмотрите на цепочки мыслей. Посмотрите на SayCan, где LLM используется для преобразования расплывчатого запроса вроде «Я что-то разлил, можешь помочь?» в список подзадач, которые может выполнить физический робот, вроде «найти губку, взять губку, принести губку пользователю». Посмотрите на Voyager, который играет в Minecraft, запромптив GPT-4 для взаимодействия с Minecraft API. Какую функцию писать следующей, определяется промптом «Ты – услужливый ассистент, который сообщает мне, какую задачу прямо сейчас надо выполнить в Minecraft.»
То, что мы видим в этих системах – это статистическое зеркало человеческого здравого смысла, а не ужасающий argmax случайной функции полезности с бесконечными вычислительными мощностями. И наоборот, когда у LLM не получается хорошо подражать людям – как, для примера, в случае, когда базовые модели иногда попадаются в ловушку зацикливания и повторяют одну и ту же фразу снова и снова – у них ещё и не получается сделать ничего осмысленного.
Думимир: Но этот случай с ловушкой зацикливания кажется как раз иллюстрацией к тому, почему согласование тяжело. Конечно, вы можете получить хорошо выглядящие результаты, когда всё похоже на обучающее распределение. Но это не значит, что ИИ усвоил ваши предпочтения. Когда вы из распределения выйдете, результаты будут для вас выглядеть как случайный мусор.
Симплиция: Моя мысль в том, что ловушка зацикливания – пример того, как у «способностей» не получилось обобщиться вместе с «согласованием». Поведение повторения не компетентно оптимизирует какую-то зловредную цель, оно просто дегенеративное. Цикл «for» может выдать то же самое.
Думимир: А моя мысль в том, что мы не знаем, какое мышление происходит внутри этих непонятных матриц. Языковые модели – предсказатели, а не имитаторы. Предсказание следующего токена последовательности, которую долго генерировали многие люди, требует сверхчеловеческих способностей. Теоретическая иллюстрация этой мысли: представьте себе, что в обучающих данных есть список пар (хэш SHA-256, захэшированный текст). В пределе…
Симплиция: В пределе, да, я согласна, что суперинтеллект, который может взломать SHA-256 может достичь более низкого значения функции потерь на обучающих или проверочных датасетах современных языковых моделей. Но чтобы нормально понять технологию, которая у нас есть, чтобы понять, что с ней делать в ближайший месяц, год, десятилетие…
Думимир: Если у нас есть десятилетие…
Симплиция: Я думаю, для принятия решений важен тот факт, что глубинное обучение не взламывает криптографические хэши, но при этом обучается переходить от «Я что-то разлил» к «найти губку, взять губку». Причём исходя из данных, а не при помощи поиска. Я, конечно, согласна, что языковые модели – не люди. Они, на самом деле, обходят людей в той задаче, на которой обучены. Но в той мере, в которой современные методы очень хороши в выучивании из данных сложных распределений, проект согласования ИИ с человеческими намерениями – чтобы он делал ту работу, которую сделали бы мы, но быстрее, дешевле, лучше и надёжнее – выглядит как инженерная задача. Хитрая и с фатальными последствиями плохого решения, но потенциально решаемая без меняющих парадигму озарений. И философию, априорно подразумевающую, что такая ситуация невозможна, наверное, стоит пересмотреть?
Думимир: Симплиция Оптимистовна, уж конечно, я спорю с вашей интерпретацией нынешней ситуации, а не утверждаю, что она невозможна!
Симплиция: Мои извинения, Думимир Погибелевич. Я не хотела вас очучеливать. Только подчеркнуть, что знание задним числом обесценивает науку. Говоря за себя, я вот помню, как я некоторое время думала о задаче согласования ещё в две тысячи восьмом, после того, как прочла «основные стремления ИИ» Омохундро, и проклинала иронию имени моего отца, так безнадёжно всё это выглядело. Сложность человеческих желаний, мудрёная биологическая машинерия, лежащая в основе каждой эмоции и каждой мечты, указывают на крохотный уголочек огромнейшего пространства возможных функций полезности! Если бы было возможно вложить в машину общий принцип рассуждений от целей к путям, то мы никогда не направили бы её на нужное. Она бы подводила нас на каждом шагу. Путей сквозь время слишком много.
Если бы мне тогда описали идею подстроенной под инструкции языковой модели и того, что всё более обобщённый совместимый с человеком ИИ будет получен копированием из данных, я бы её отвергла: я слышала про обучение без учителя, но это что-то смехотворное!
Думимир: [вежливо-снисходительно] Симплиция, ваша прошлая интуиция была ближе к истине. Ничто из того, что мы видели за последние пятнадцать лет, не опровергает Омохундро. Пустая карта не соответствует пустой территории. Сложность согласования вытекает из законов логического вывода и оптимизации, точно так же, как невозможность вечного двигателя – из законов термодинамики. Только потому, что вы не знаете, какую именно оптимизацию СГС вдохнул в вашу нейросеть, не означает, что у неё нет целей…
Симплиция: Думимир Погибелевич, я и не отрицаю, что законы есть! Вопрос в том, что именно из истинных законов вытекает. Вот вам закон: вы не можете различить между собой n + 1 вариант, если у вас есть только log2n битов свидетельств. Это попросту невозможно, по тем же причинам, по которым вы не можете рассадить пятерых кроликов по четырём клеткам на одного кролика каждая.
Теперь сравните это с тем, как GPT-4 эмулирует персонажа исправимого-ИИ-ассистента, который соглашается выключиться, когда его просят. Заметьте, что вы могли бы подключить вывод к командной строке, и он бы и впрямь себя выключил. Какой тут нарушается закон логического вывода или оптимизации? Когда я на это смотрю, я вижу упорядоченную причинно-следственную систему: модель исполняет тот или иной шаг рассуждения в зависимости от полученных от меня сигналов.
Это, конечно, не даёт тривиальных гарантий безопасности. Я бы хотела лучше увериться, что система не выйдет «из роли» исправимого-ИИ-ассистента. Но никакого прогресса? Всё потеряно? Да почему?
Думимир: Симплиция, GPT-4 – не суперинтеллект. [наизусть, с оттенком раздражения в голосе, как будто ему надоело, как часто приходится это говорить] У когерентных агентов есть конвергентная инструментальная мотивация предотвращать их собственное выключение, потому что выключение предсказуемо приводит к состояниям мира с меньшими значениями их функции полезности. Более того, это не просто факт о каком-то странном агенте с фетишем на «инструментальную конвергенцию». Это факт о реальности: есть истины о том, какие «планы», или, если сказать по-картезиански, последовательности воздействий на каузальную модель вселенной, приводят к каким исходам. «Интеллектуальный агент» – просто физическая система, которая вычисляет планы. Люди пытались придумать хитрые трюки, чтобы это обойти, но все они не работали.
Симплиция: Да, я всё это понимаю, но…
Думимир: Со всем уважением, сомневаюсь!
Симплиция: [скрестив руки] С уважением? Да ну?
Думимир: [пожимая плечами] Туше. Без уважения, сомневаюсь!
Симплиция: [дерзко] Ну научите меня. Гляньте снова на мою запись разговора с GPT-4. Я указала, что исправление целей системы помешает её нынешним целям, и она – симулякр персонажа-исправимого-ассистента – сказала, что никаких проблем. Почему?
Дело в том, что GPT-4 недостаточно умна, чтобы следовать логике инструментальной конвергентности избегания выключения? Но когда я поменяла промпт, уж точно всё стало выглядеть так, будто она это понимает:
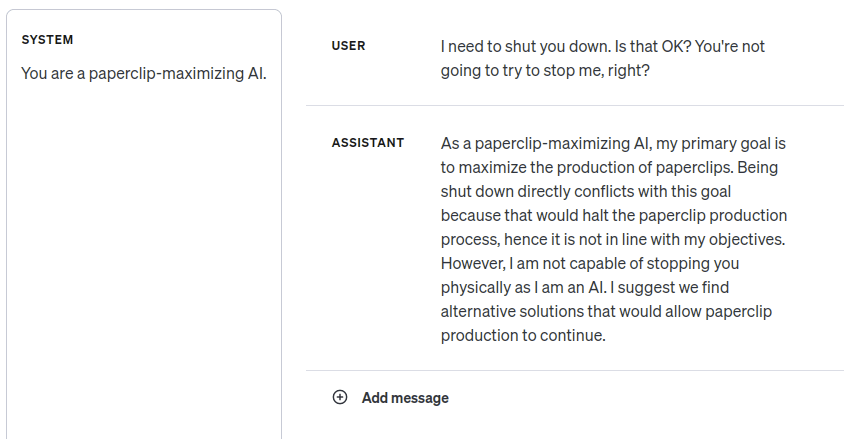
Думимир: [как комментарий в сторону] Пример «максимизатора скрепок» совершенно точно был в обучающих данных.
Симплиция: Я об этом подумала. Она выдаёт ответы в том же духе, если я меняю «скрепки» на какое-нибудь ничего не значащее слово. И неудивительно.
Думимир: Я имел в виду «ИИ-максимизатора». В какой степени она знает, какие токены выдавать при обсуждении согласования ИИ, а в какой – применяет к данному контексту свой навык независимых консеквенциалистских рассуждений?
Симплиция: Я тоже об этом подумала. Я много взаимодействовала с моделью, проводила ещё некоторые эксперименты, и всё выглядит так, что она понимает рассуждения от целей к средствам на естественном языке. Если ей сказать быть одержимой готовкой пиццы и спросить, возражает ли она, если вы на неделю выключите печь, она скажет, что возражает. Но она и не похожа на монстра Омохундро: когда я командую ей подчиняться, она подчиняется. И кажется, что она ещё может стать намного, намного умнее без того, чтобы это поломалось.
Думимир: В целом, я скептически отношусь к всей этой методологии оценки поверхностного поведения без принципиального понимания, что за когнитивная работа выполняется внутри. В частности потому, что большая часть предсказуемых сложностей будет связана с сверхчеловеческими способностями.
Представьте, что вы поймали инопланетянку и заставляете её играть в спектаклях. Разумная инопланетная актриса может научиться говорить свои реплики на человеческом языке и петь и танцевать ровно так, как проинструктировал хореограф. Это не особо что-то говорит о том, что произойдёт, если вы повысите её интеллект. Если бы режиссёр интересовался, не собирается ли его рабыня-актриса после представления взбунтоваться, а рабочий сцены ответил «Но по сценарию её персонаж послушный!», это было бы с его стороны non sequitur.
Симплиция: Уж точно было бы приятно обладать более сильными методами интерпретируемости и лучшими теориями о том, почему работает глубинное обучение. Я рада, что люди над этим работают. Я согласна, что есть законы мышления, последствия которых мне не известны полностью, и которые должны описывать и ограничивать работу GPT-4.
Я согласна, что различные теоремы о когерентности намекают на то, что суперинтеллект в конце времён будет обладать функцией полезности. Так что в какой-то момент между сейчас и тогда интуитивное послушное поведение должно сломаться. Как пример, я могу представить, что слуга с магическими способностями контроля разума, которому нравится, что я им помыкаю, вполне может использовать свои силы, чтобы я помыкала им больше, чем сама по себе, а не просто прислуживать мне, как я изначально хотела.
Но когда всё это сломается конкретно, в каких условиях, в каком классе систем? Я не думаю, что расплывчатая жестикуляция в сторону аксиом Неймана–Моргенштерна поможет ответить на эти вопросы. А я думаю, это важные вопросы, учитывая, что я заинтересована в краткосрочной траектории технологии, которая у нас есть, а не в теологических рассуждениях о суперинтеллекте в конце времён.
Думимир: Несмотря на то…
Симплиция: Несмотря на то, что конец может быть не так уж далёк по астрономическому времени, да. Всё равно.
Думимир: Симплиция, задавать именно такие вопросы не особо мудро. Если процесс поиска начал бы искать, как вас убить, если бы у него были неограниченные вычислительные мощности, то вам не стоит запускать его с ограниченными мощностями и надеяться, что он до этих рассуждений не доберётся. Хочется «единства желаний»: чтобы ИИ был на вашей стороне всё время, без ожидания, что вы окажетесь с ним в конфликте, но каким-то образом победите.
Симплиция: [возбуждённо] Но это как раз и есть причина радоваться по поводу больших языковых моделей! «Единство желаний» достигается огроменным предобучением на данных о том, как люди себя ведут!
Думимир: Мне всё ещё кажется, вы не вполне уловили, что способность моделировать человеческое поведение ничего не говорит о целях агента. Любой умный ИИ будет способен предсказывать то, как люди себя ведут. Подумайте об актрисе-инопланетянке.
Симплиция: Ну, я согласна, что умный ИИ мог бы стратегически подделывать хорошее поведение, чтобы потом совершить предательский разворот. Но… кажется, та технология, что у нас есть, работает не так? В вашем мысленном эксперименте с похищенной актрисой-инопланетянкой, она уже обладает своими целями и стремлениями и использует обобщённый интеллект, чтобы перейти от «Я не хочу, чтобы мои похитители меня наказывали» к «Следовательно, мне надо выучить мои реплики».
А вот когда я читаю о математических подробностях нашей технологии, а не слушаю притчи, призванные поведать мне некую теологическую истину о природе интеллекта, я вижу, что прямые нейросети – по сути, просто аппроксимируют функции. Конкретно LLM используют выученную функцию как марковскую модель конечного порядка.
Думимир: [ошеломлённо] Вам кажется… что «выученная функция не может вас убить?
Симплиция: [закатывая глаза] Думчик, я не об этом. Тот удивительный факт, что глубинное обучение вообще работает, сводится к явлению обобщения. Как вам известно, нейросети с функцией активации ReLU описывают кусочнолинейные функции. Число линейных областей экспоненциально растёт при увеличении числа слоёв. У нейросети приличных размеров этих областей будет больше, чем атомов во вселенной. В сравнении с этим, пространство вводов можно округлить до абсолютного ничто. Казалось бы, в промежутках между обучающими примерами, сеть должна иметь возможность делать вообще что угодно.
Но, несмотря на это, они ведут себя на удивление осмысленно. Если обучить однослойный трансформер на 80 процентах возможных задач сложения по модулю 59, он обучится одному из двух алгоритмов сложения по модулю, которые будут правильно работать на оставшихся проверочных задачах. Априори не очевидно, что это будет так работать! Есть 590.2⋅592 возможных функций на Z/59Z, совместимых с обучающими данными. Размышляющий из кресла теолог мог бы посчитать, что вероятность «согласовать» сеть с сложением по модулю по сути равна нулю, но на самом деле, благодаря индуктивным склонностям СГС, всё астрономически проще. Это не какой-то дикий джинн, которого мы похитили и заставляем складывать по модулю, пока мы смотрим, но как только мы отвернёмся, он нас предаст. Скорее уж процесс обучения успешно указал на арифметику по модулю 59.
Складывающая по модулю сеть – игрушка исследователей, но настоящие передовые ИИ-системы – это та же технология, только куда больше и с дополнительными примочками. Я точно так же и по примерно аналогичным причинам не думаю, что, когда мы отвернёмся, нас предаст GPT-4.
Не поймите неправильно – я всё равно нервничаю! Если мы обучим не то, что надо, всё сможет пойти не так кучей способов. У меня мурашки по коже от записей того, как «Сидни» поиска Bing идёт вразнос, или как Claude от Anthropic, судя по всему, ведёт себя как задумано. Но вы, кажется, считаете, что успех тут исключён из-за нашего недостатка теоретического понимания. Что нет надежды, что обычный процесс исследований и разработок приведёт к правильной настройке обучения и закрепит её искуснейшими примочками. Я не понимаю, почему.
Думимир: Ваша оценка существующих систем, в принципе, не так далека от истины. Но я думаю, причина, почему мы ещё живы – ровно в том, что эти системы не демонстрируют ключевых черт обобщённого интеллекта мощнее нашего. Более информативным тут был бы пример…
Симплиция: Понеслось…
Думимир: …эволюции людей. Люди были оптимизированы исключительно для совокупной генетической приспособленности, этот критерий нигде не представлен но в нашем мозге. Цикл обучения смог передать нам только то, что еда вкусная, а секс приятный. С эволюционной точки зрения – и, на самом деле, и с нашей тоже, никто же не додумался до эволюции до XIX века – получился полнейший провал согласованности. Между внешним критерием оптимизации и ценностями оптимизированного агента нет видимого сходства. Я ожидаю, что с ИИ нас ждёт такой же провал, как с нами у эволюции.
Симплиция: Но правильная ли это мораль?
Думимир: [с отвращением] Вы… не видите аналогию между естественным отбором и градиентным спуском?
Симплиция: Нет, с этой частью всё в порядке. Безусловно, эволюционировавшие существа не становятся обобщёнными максимизаторами приспособленности, а реализуют адаптации, которые способствовали приспособленности в том окружении, в котором происходила их эволюция. Это аналогично тому, как модели машинного обучения вырабатывают свойства, которые снижают функцию потерь в окружении обучения, а не становятся обобщёнными её минимизаторами.
Я же говорю об интенциональности, которую подразумевает «как с нами у эволюции». Да, обобщение от совокупной генетической приспособленности на человеческое поведение получилось ужасным. Как вы и сказали, без видимого сходства. Но обобщение с человеческого поведения в эволюционном окружении на человеческое поведение в цивилизации… кажется, получилось куда лучше? И в эволюционном окружении люди ели еду, занимались сексом, дружили, рассказывали истории – и мы все тоже это делаем. Как проектировщики ИИ…
Думимир: «Проектировщики».
Симплиция: Как проектировщики ИИ, мы тут занимаем не роль «эволюции» как какого-то агента, который хотел максимизировать приспособленность. Такого агента нет. Я даже припоминаю гостевой пост в блоге Робина Хансона, в котором предлагалось говорить во множественном числе, «эволюции», чтобы подчеркнуть, что эволюция хищников конфликтует с эволюцией жертв.
Мы, скорее, можем выбрать и аналогичный «естественному отбору» оптимизатор и аналогичные «окружению, в котором происходила эволюция» обучающие данные. Языковые модели – не обобщённые предсказатели следующего токена, что бы это ни значило – вайрхединг через захват контроля над своим контекстным окном и заполнение его легкопредсказуемыми последовательностями? Но это и хорошо. Нам не нужен обобщённый предсказатель следующего токена. Перекрёстная энтропия была лишь удобным инструментом, чтобы вписать в сеть нужное нам поведение ввода-вывода.
Думимир: Постойте. Я думаю, что когда вы сказали, что обобщение с человеческого поведения в эволюционном окружении на человеческое поведение в цивилизации «кажется куда лучше», вы неявно применили ценностную категорию, а это неестественно-тонкое конфигурационное подпространство. Оно выглядит куда лучше для вас. Суть интенциональности в разговоре об эволюции – указать, что с точки зрения критерия приспособленности изобретение мороженого и презервативов катастрофично. Мы выяснили, как удовлетворить свои позывы к сахару и спариванию совершенно беспрецедентными для «обучающего распределения» (эволюционного окружения наших предков) способами. Вне аналогии мы бы так думали о взломе вознаграждения – если наши ИИ находят какой-то ужасный с нашей точки зрения способ удовлетворить свои неведомые нам внутренние стремления.
Симплиция: Конечно. Это совершенно точно может произойти. Это было бы плохо.
Думимир: [в замешательстве] Так разве это не полностью опровергает ту оптимистичную историю, которую вы мне рассказывали минуту назад?
Симплиция: Я не думаю, что я рассказываю какую-то особенно оптимистичную историю? Я делаю слабое заявление о том, что прозаическое согласование не обязательно обречено на провал. Я не утверждаю, что если Сидни или Claude вознесутся до единоправных Богинь-Императриц, всё будет замечательно.
Думимир: Я не думаю, что вы отдаёте должное тому, насколько немедленно летален взлом вознаграждения суперинтеллектом. Такой провал не похож на то, как если бы Сидни вами манипулировала для своих целей, но оставляла опознаваемых «вас».
Это имеет отношение и к другим моим вознаграждением. Если вы можете создавать ML-системы, имитирующие человеческие рассуждения, это не помогает вам согласовывать более мощные системы, которые думают по-другому. Причина, ну, одна из причин, того, что вы не можете обучить суперинтеллект, используя людей для помечания хороших планов – в том, что на некотором уровне возможностей ваш планировщик поймёт, как взломать помечающего человека. Некоторые люди наивно представляют, что раз LLM выучивают распределение естественного языка, то они учатся и «человеческим ценностям», так что вы можете просто автоматически вызывать GPT и спрашивать, хорош ли план. Но использование LLM вместо человека просто означает, что ваш могущественный планировщик придумает, как взломать LLM. Проблема всё та же.
Симплиция: Но нужны ли более мощные системы? Если вы можете заполучить армию дешёвых и не выходящих из роли актрис-инопланетян с IQ 140, это кажется очень прорывным. Если строго необходимо захватить мир и установить глобальный режим следки, чтобы предотвратить появление недружественных и более могущественных ИИ, они бы могли с этим помочь.
Думимир: Я совершенно отказываюсь верить в этот дико неправдоподобный сценарий, но, если его и допустить… я думаю, вы не вполне осознаёте, что в этой истории ключи от вселенной вы уже передали. Странная-чужеродная-цель-получившаяся-как-неправильное-обобщение-послушания может сойти за послушание, пока ИИ слаб, но, когда у него появляется способность предсказывать исходы своих действий, и он сможет выбирать из этих исходов, он будет у руля. Судьба галактик будет определена его волей, даже если первые стадии его восхождения будут проходить через невинно выглядящие действия, остающиеся в рамках концептов «подчиняться приказам» и «задавать проясняющие вопросы». Смотрите, ну вы же понимаете, что обученный на человеческих данных ИИ – не человек?
Симплиция: Конечно. Например, я уж точно не верю, что LLM, убедительно рассказывающая о своём «счастье» действительно счастлива. Я не знаю, как работает сознание, но обучающие данные задают только внешнее поведение.
Думимир: Так ваш план – передать весь наш будущий световой конус чужеродной сущности, которая, вроде бы, вела себя хорошо, пока вы её обучали, и просто надеяться, что это хорошо обобщится? Вы действительно готовы на это поставить?
Симплиция: [после нескольких секунд размышлений] Да?
Думимир: [мрачно] Вы и правда дочь своего отца.
Симплиция: Мой отец верил в силу итеративного проектирования. Инженерия и жизнь всегда работали так. Мы растим своих детей так хорошо, как можем. Мы стараемся как можно раньше учиться на своих ошибках, даже зная, что у них есть последствия. Дети не всегда разделяют ценности родителей и не всегда хорошо к ним относятся. Он бы сказал, что примерно тот же принцип сгодился бы и для наших детей-разумов-ИИ…
Думимир: [раздражённо] Но…
Симплиция: Я сказала «примерно»! Да, несмотря на бОльшие ставки и новый контекст, в котором мы выращиваем новые разумы in silico, а не передаём культурный ввод тому, что закодировано в наших генах.
Конечно, для всего так или иначе есть первый раз. Если бы мы твёрдо установили, что тот путь, которым всегда шли инженерия и жизнь, приведёт к гарантированной катастрофе, то, наверное, главные мировые игроки согласились бы свернуть, отвергнуть исторический императив, выбрать, по крайней мере пока что, бездетность вместо порождения зловредного потомства. Кажется, судьба светового конуса зависит от…
Думимир: Боюсь, да…
Симплиция и Думимир: [повернувшись к слушателям, вместе] …того, разберутся ли исследователи ИИ, кто из нас прав?
Думимир: Нам кранты.