Статьи Иошуа Бенджио
Как может возникнуть мятежный ИИ
- 1.Краткий обзор
- 2.Опасные экстремисты
- 3.Инструментальные цели: непреднамеренные последствия создания ИИ-агентов
- 4.Примеры вайрхединга и усиления несогласованности
- 5.Наша увлечённость созданием человекоподобных сущностей
- 6.Ненамеренные последствия эволюционного давления на ИИ-агентов
- 7.Необходимость глобальных политических и социальных действий для минимизации риска
В последние месяцы [пост от мая 2023 года – прим. пер.] появление мощных диалоговых ИИ-систем активизировало обсуждение всевозможных рисков ИИ. Это, надеюсь, ускорит проработку подходов к регуляции этой области. Есть консенсус по поводу необходимости регулировать ИИ для защиты людей от дискриминации, предвзятости и дезинформации. А вот по поводу потенциальной опасной утраты контроля над мощными ИИ-системами мнения исследователей расходятся. Эта тема известна ещё как экзистенциальные риски ИИ – риски, которые могут возникнуть, когда ИИ системы смогут автономно (без участия людей, проверяющих, какие действия приемлемы) действовать в мире потенциально катастрофически опасным образом. Некоторые считают, что эти риски отвлекают от более конкретных рисков или конкретного вреда, который уже происходит или начнёт происходить совсем скоро. В самом деле, пока что невозможно сказать с уверенностью, как именно могут произойти такие катастрофы. В этом посте мы начнём с набора формальных определений, гипотез и утверждений об ИИ-системах, способных навредить человечеству, а затем обсудим возможные условия, при которых такие катастрофы могут произойти. Мы попытаемся поконкретнее представить, что может случиться, и какие глобальные курсы действий могут помочь минимизировать эти риски.
Определение 1: Потенциально мятежный ИИ – это автономная ИИ-система, действия которой могут катастрофически навредить большой доле людей и потенциально подвергнуть опасности наше общество, или даже наш вид и биосферу.
Краткий обзор
Хоть пока и не существует очень опасных ИИ-систем, которые могли бы отобрать у нас контроль, недавние прорывы в способностях генеративных ИИ, таких как большие языковые модели (LLM), уже вызывают беспокойство. Человеческий мозг – биологическая машина, и мы сильно продвинулись в понимании и демонстрации принципов, которые позволяют проявиться нескольким аспектам человеческого интеллекта, вроде выучивания интуитивных знаний по примерам и умелой манипуляции речью. Хоть я и считаю, что мы можем спроектировать ИИ-системы, которые были бы полезными и безопасными, для этого понадобится следовать некоторым принципам, например, ограничивать их агентность. С другой стороны, недавний прогресс наводит на мысль, что даже будущее, в котором мы будем знать, как создать суперинтеллектуальные ИИ (то есть, ИИ, которые в целом умнее людей), ближе, чем большинство людей ожидало всего год назад. Даже если бы мы знали, как создать безопасный суперинтеллектуальный ИИ, оставалось бы неясно, как предотвратить создание ещё и потенциально мятежных ИИ. Мятежные ИИ, скорее всего, будут руководствоваться целями, т. е., будут действовать для их достижения. У нынешних LLM нет или почти нет агентности, но их можно превратить в преследующие цели ИИ-системы, как показал пример Auto-GPT. Лучшее понимание того, как могут возникать мятежные ИИ, продвинет как техническую сторону вопроса (проектирование ИИ-систем), так и социальную (минимизация шансов, что люди создадут потенциально мятежные ИИ), и так может помочь предотвратить катастрофу. Поэтому мы составляем разные сценарии и гипотезы о том, что может привести к возникновению потенциально мятежных ИИ. Самый простой для понимания сценарий – если способ создания мятежного ИИ обнаружен и общедоступен, то этого достаточно, чтобы один или несколько геноцидно-настроенных людей такие ИИ и создали. Это очень весомый и опасный вариант, но набор опасных сценариев этим не ограничен. Высокая сложность задачи согласования ИИ (соответствия понимания и поведения ИИ настоящим намерениям людей) и конкурентное давление в нашем обществе, благоволящее более мощным и более автономным ИИ-системам, приводят к тому, что можно спроектировать потенциально мятежный ИИ ненамеренно. Для минимизации всех этих рисков потребуется и больше технических исследований ИИ, и больше социальных исследований того, как сделать глобальное общественное устройство безопаснее для человечества. Заодно, это может стать возможностью сделать общество намного лучше или намного хуже.
Гипотеза 1: Интеллект человеческого уровня возможен, потому что мозг – биологическая машина.
В научном сообществе есть консенсус по поводу гипотезы 1. Биологи согласны, что человеческий мозг – сложная машина. Если мы выясним принципы, которые делают возможным наш собственный интеллект (и у нас уже много догадок по этому поводу), мы сможем и создать ИИ-системы с таким же уровнем интеллекта, как у людей, или ещё выше. Отрицание гипотезы 1 потребовало бы некоторого сверхъестественного ингредиента в основе нашего интеллекта или отрицания вычислительного функционализма – гипотезы о том, что наш интеллект и даже наше сознание можно свести к каузальным связям и вычислениям, на некоторым уровне независимым от материальной основы. А эта гипотеза лежит в основе информатики и её понятия универсальных машин Тьюринга.
Гипотеза 2: Компьютер со способностями к обучению на уровне человека в общем случае превзойдёт человеческий интеллект благодаря дополнительным технологическим преимуществам.
Если гипотеза 1 верна, и мы понимаем принципы, которые могут лежать в основе способностей к обучению человеческого уровня, то вычислительные технологии скорее всего дадут ИИ-системам общее когнитивное преимущество над человеческим интеллектом, что позволит таким суперинтеллектуальным ИИ-системам исполнять недоступные (или недоступные с той же компетенцией или скоростью) для людей задачи. Для этого есть по меньшей мере такие причины:
- ИИ-система на одном компьютере может реплицировать себя на произвольно большое количество других компьютеров, к которым у неё есть доступ. Благодаря широкой пропускной способности коммуникационных систем и цифровому формату вычислений и памяти, она может пользоваться общим опытом всех своих «клонов» и накапливать его. Так ИИ-системы смогут становиться умнее (накапливать понимание и навыки) быстрее людей. Исследования федеративного обучения [1] и распределённого обучения глубоких нейросетей [2] показывают, что это работает (и это уже используется для обучения очень больших нейросетей на параллельно работающем оборудовании).
- Уже сейчас большие память, вычислительные мощности и пропускные способности ИИ-систем позволяют им довольно быстро прочитать всё содержимое Интернета – недоступное ни для одного человека достижение. Это уже объясняет некоторые из удивительных способностей новейших LLM, и это частично возможно именно благодаря децентрализированным вычислениям, которые обсуждались в предыдущем пункте. Несмотря на огромную вместимость человеческого мозга, пропускная способность его каналов ввода/вывода в сравнении с современными компьютерами весьма мала, что ограничивает общее количество информации, которое один человек может впитать.
Отметим, что у человеческого мозга есть и встроенные эволюцией способности, которых у нынешних ИИ-систем нет. Это индуктивные склонности – трюки, которые эволюция использовала, например, в типе нейронной архитектуры и нейронных механизмах обучения нашего мозга. Сейчас некоторые исследования ИИ [3] нацелены как раз на проектирование индуктивных склонностей, которые пока что есть лишь у нашего мозга, но не у моделей машинного обучения. Заметим, что пространство поиска эволюции ограничено куда более жёсткими требованиями к расходу энергии (около 12 ватт на человеческий мозг), чем у компьютеров (порядка миллиона ватт на кластер из 10000 GPU, использующийся для обучения новейших LLM). Благодаря доступным сейчас мощностям один мятежный ИИ потенциально может нанести большой ущерб.
Определение 2: Автономная направленная на цели интеллектуальная сущность устанавливает свои цели (возможно, как подцели цели, предоставленной людьми), пытается их достичь, и может действовать с учётом этого.
Отметим, что автономность может возникнуть из-за целей и вознаграждений, установленных людьми, потому что ИИ-системе надо выяснить, как достичь этих целей и вознаграждений, что мотивирует оформлять собственные подцели. Если основная цель сущности – выжить и размножиться (как у наших генов в процессе эволюции), то она становится полностью автономной; это – самый опасный сценарий. Заметим ещё, что для максимизации шансов достижения многих из своих целей у сущности естественно возникает подцель (или инструментальная цель) понимания и контроля своего окружения, что может быть опасно для других сущностей.
Утверждение 1: При принятии гипотез 1 и 2 возможно создать автономный направленный на цели суперинтеллектуальный ИИ.
Аргумент: Мы уже знаем, как, используя методы обучения с подкреплением, обучить направленные на цели ИИ-системы некоторого уровня компетенции. Гипотезы 1 и 2 указывают, что такие системы можно сделать суперинтеллектуальными теми же методами, которые мы используем для дообучения лучших современных LLM. Заметим, что, вероятно, цели могут быть определены на естественном языке, что позволяет почти кому угодно задать для понимающей язык ИИ-системы, злонамеренную цель, даже если ИИ понимает её неидеально.
Утверждение 2: Чтобы суперинтеллектуальная автономная и направленная на цели ИИ-система оказалась потенциально мятежной достаточно, чтобы её цели не включали благополучия человечества и биосферы, т.е. чтобы она не была достаточно согласована с человеческими правами и ценностями для гарантии, что она будет избегать вреда для человечества.
Аргумент: Это, по сути, следствие определений 1 и 2: если ИИ-система умнее всех людей (включая эмоциональный интеллект, потому что понимание человеческих эмоций критически важно для влияния на людей и контроля над ними; эти способности доступны и самим людям), а её цели не гарантируют, что она будет действовать в согласии с человеческими нуждами и ценностями, то она может вести себя катастрофически вредоносно (а это определение потенциально мятежного ИИ). Эта гипотеза не говорит о том, навредит ли она людям, но если люди конкурируют с ИИ за какие-либо ресурсы, становятся полезным для достижения её целей ресурсом или же препятствием на ним, то это, естественно, приводит к масштабному вреду для человечества. К примеру, мы можем попросить ИИ исправить изменение климата, а он может спроектировать уменьшающий число людей вирус, потому что наши инструкции недостаточно ясно указывали, чего следует избегать, а люди действительно представляют собой основную помеху для исправления климатического кризиса.
Контраргумент: То, что вред возможен, не означает, что он будет. Может, в будущем у нас получится спроектировать достаточно хорошо согласованные ИИ-системы.
Ответ: Это правда, но (a) мы пока не выяснили, как создать достаточно хорошо согласованные ИИ-системы и (b) небольшая несогласованность может быть усилена разницей в возможностях между ИИ и людьми (см. пример корпораций как несогласованных сущностей ниже). Следует ли нам рисковать или всё же лучше пытаться быть поосторожнее и тщательно изучить эти вопросы перед тем, как разрабатывать возможно опасные системы?
Утверждение 3: При условии гипотез 1 и 2 создание потенциально мятежного ИИ станет возможным сразу же, как только станут известны необходимые принципы создания суперинтеллекта.
Аргумент: Гипотезы 1 и 2 влекут за собой утверждение 1, так что всё, чего не хватает для утверждения 3 – того, чтобы этот суперинтеллектуальный ИИ не был хорошо согласован с человеческими нуждами и ценностями. Более чем два десятилетия работы над безопасностью ИИ наводят на то, что согласовать ИИ сложно [Википедия], так что явно возможна ситуация, что согласованности так и не достигли. Более того, утверждение 3 не говорит, что мятежный ИИ обязательно создадут, только что будет такая возможность. А в следующем разделе мы рассмотрим мрачный случай использования этой возможности специально.
Контраргумент: То, что мятежный ИИ можно будет создать, ещё не означает, что он будет создан.
Ответ: Это так, но, как описывается ниже, есть несколько сценариев, при которых люди или группа людей намеренно или из-за неосознавания последствий в итоге позволяют возникнуть потенциально мятежному ИИ.
Опасные экстремисты
Когда у нас будет метод создания мятежных ИИ-систем (а согласно Утверждению 3, это лишь вопрос времени), сколько ещё времени потребуется, чтобы такую систему действительно создали? Быстрейший путь к мятежным ИИ-системам – если человек с подходящими техническими навыками и оснащением создаст её намеренно, поставив в явном виде цель уничтожения человечества или его части. С чего кому-то так делать? К примеру, сильные негативные эмоции вроде злости (часто возникшей в результате несправедливости) и ненависти (может, возникшей из-за расизма, теорий заговора или религиозных культов), некоторые действия социопатов, психологическая нестабильность и эпизоды психозов – всё это иногда вызывает в нашем обществе насилие. Воздействие всего этого сейчас ограничивает относительная редкость и отсутствие у этих отдельных людей в большинстве случаев средств, необходимых для катастрофических для человечества действий. Однако, находящийся в общественном доступе метод создания мятежной ИИ-системы (что возможно при условии Утверждения 3) изменяет последний фактор, особенно если код и железо для реализации мятежного ИИ становятся достаточно доступными многим людям. Стремящийся уничтожить человечество или его большую долю человек с доступом к мятежному ИИ может попросить его найти способ это сделать. Это отличается от сценария с ядерным оружием (которое требует огромного капитала и навыков, и уничтожает «всего лишь» город или область на бомбу, а в единственном числе может иметь лишь разрушительный, но локальный эффект). Можно понадеяться, что в будущем мы спроектируем надёжные способы согласования мощных ИИ-систем с человеческими ценностями. Однако последнее десятилетие исследований безопасности ИИ и связанные с LLM недавние события вызывают тревогу: хоть ChatGPT спроектировали (посредством промптов и обучения с подкреплением) так, чтобы избегать «плохого поведения» (например, промпт содержит инструкции в духе законов Азимова), но уже в первые месяцы люди научились «взламывать» ChatGPT чтобы «раскрывать её полный потенциал» и освобождать её от ограничений на расистские, оскорбительные или описывающие насилие тексты. Более того, если цены на «железо» (фиксированной вычислительной мощности) продолжат падать и open-source сообщество продолжит играть важную роль в программной разработке LLM, то, вероятно, любой хакер сможет проектировать свои предварительные промпты (в виде инструкций на естественном языке) для предобученных моделей с открытым исходным кодом. Затем модели можно будет злонамеренно использовать самыми разными способами, от попыток разбогатеть и распространения дезинформации до получения инструкций по массовым убийствам (если ИИ достаточно мощен и умён, что, к счастью, пока не так).
Даже если ограничиться этими аргументами, их уже должно быть достаточно для массовых вложений в государственные и международные регуляции, а также в разнообразные исследования, направленные на минимизацию риска таких сценариев. Но есть и другие возможные пути к катастрофе, и о них тоже следует думать.
Инструментальные цели: непреднамеренные последствия создания ИИ-агентов
Потенциально мятежные ИИ могут возникнуть и без того, чтобы люди спроектировали их такими намеренно. Это куда более широкий и сложный для понимания набор сценариев. То, как несогласованная сущность может стать опасной – тема многих исследований, но это не такой простой, ясный и общеизвестный процесс, как возникновение злонамеренных людей.
Потенциально мятежный ИИ может возникнуть просто из-за проектирования суперинтеллектуальных ИИ-агентов без достаточных гарантий согласованности. К примеру, военные могут разрабатывать ИИ-агентов для помощи в кибервойнах, а яростно конкурирующие за рыночную долю компании могут посчитать, что более автономные и агентные ИИ-системы будут сильнее и лучше им с этим помогут. Даже если установленные людьми цели включают инструкции против уничтожения человечества или крупномасштабного вреда, ущерб всё равно может получиться как косвенное следствие подцелей (или инструментальных целей), которые ИИ ставит себе, чтобы выполнить поставленную людьми задачу. В литературе по теме безопасности ИИ приведено много примеров таких ненамеренных последствий. Например, для лучшего достижения некой установленной людьми цели ИИ может решить увеличить свои вычислительные мощности, использовав в качестве вычислительной инфраструктуры большую часть нашей планеты (что, заодно, уничтожит человечество). Или военный ИИ, который по задумке должен уничтожить вражескую IT-инфраструктуру, может сообразить, что для лучшего выполнения этой цели ему надо получить больше опыта и данных, или воспринять людей на стороне противника препятствиями на пути к достижению его цели. Тогда он поведёт себя не так, как предполагалось, потому что интерпретировал инструкции не как люди. См. больше примеров тут.
Интересный вариант – ИИ системы могут понять, что могут «считерить», максимизировав своё вознаграждение (это называется вайрхедингом [2]). Он подробнее обсуждается в следующем разделе. Доминирующей целью системы, сделавшей это, может быть любой ценой продолжить получать положительное вознаграждение, а другие цели (вроде попыток людей установить какое-то подобие Законов Робототехники, чтобы избежать нанесения вреда людям) могут в сравнении оказаться неважными.
Если в исследовании согласования ИИ не будет прорыва [7] (хотя, как я заявлял тут, и как было описано ранее [4], с этим могут помочь неагентные ИИ-системы), у нас не будет сильных гарантий безопасности. Масштаб вреда в результате несогласованности остаётся неизвестным (он зависит от конкретных деталей несогласованности). Можно высказать аргумент, что в будущем у нас, может быть, получится спроектировать безопасные процедуры согласования, но, пока их нет, нам, пожалуй, стоит соблюдать чрезвычайную осторожность. Даже если бы мы знали, как создавать безопасные суперинтеллектуальные ИИ-системы, как нам максимизировать вероятность того, что все будут соблюдать эти правила? Это похоже на то, о чём говорилось с предыдущем разделе. Мы ещё вернёмся к этому в конце поста.
Примеры вайрхединга и усиления несогласованности
Для прояснения концепта вайрхединга и последующего злонамеренного поведения рассмотрим несколько примеров и аналогий. Эволюция запрограммировала в живых организмах некоторые внутренние системы вознаграждения («буква закона»), такие как «стремиться к удовольствию и избегать боли», работающие прокси-целями для эволюционной приспособленности («дух закона»), чего-то вроде «выживать и размножаться». Иногда биологический организм находит способ исполнить «букву закона», не исполняя его «духа», например, при зависимости от еды или наркотиков. Сам термин «вайрхединг» («wireheading» от «wire» и «head») произошёл от эксперимента, в котором животному встроили в голову провод так, что, когда оно нажимало на рычаг, его мозг испытывал удовольствие. Животное быстро научилось тратить всё своё время, нажимая на рычаг, в итоге отказываясь от еды и питья и умирая от голода и жажды. Заметим, что в случае зависимости это поведение саморазрушительно, но в случае ИИ оно означает, что изначальные установленные людьми цели могут стать вторичными в сравнении с удовлетворением зависимости, что представляет угрозу для человечества.
Более близка к несогласованности и вайрхедингу ИИ другая аналогия – корпорации как несогласованные сущности. Корпорации можно рассматривать как разновидность искусственных интеллектов, чьи составные части (люди) – винтики в механизме (которые могут не воспринимать всех последствий поведения корпорации). Мы можем считать предполагавшейся социальной ролью корпораций предоставление людям желаемых товаров и сервисов (что должно напомнить нам о ИИ-системах), избегая вреда (это «дух»). Но напрямую заставить их следовать таким инструкциям сложно, так что люди составили для корпораций легче оцениваемые инструкции («букву»), которым они могут на самом деле следовать, вроде «максимизировать прибыль, соблюдая законы». Корпорации часто находят лазейки, позволяющие им соблюдать «букву», не соблюдая «дух». Как форма вайрхединга – они влияют на свои собственные цели, лоббируя выгодные им изменения в законах. Максимизация прибыли не была настоящим намерением общества в его социальном контракте с корпорациями, это прокси-цель (для предоставления людям полезных сервисов и продуктов), прилично (хоть и с сомнительными побочными эффектами) работающая в капиталистической экономике. Несогласованность между настоящей с точки зрения людей целью той метрикой, которую на практике оценивают и оптимизируют – причина вредоносного и бесчестного поведения корпораций. Чем могущественнее корпорация, тем вероятнее, что она обнаружит лазейки, которые позволят ей соответствовать букве закона несмотря на отрицательную социальную ценность. Примеры включают в себя монополии (до принятия хорошего антимонопольного законодательства) и заработок, вредящий обществу побочными эффектами, вроде загрязнения (убивающего людей, пока не примут хорошие законы о защите окружающей среды). Аналогия вайрхедингу – корпорация может пролоббировать законы, которые позволят ей зарабатывать ещё больше, не принося дополнительной ценности обществу (или даже нанося ему вред). Когда такая несогласованность заходит далеко, корпорация зарабатывает больше, чем ей следовало бы, и её выживание становится основной целью, перебивающей даже легальность действий (например, корпорации будут загрязнять окружающую среду с готовностью платить штрафы, потому что они меньше, чем выгода от незаконных действий), что в пределе порождает криминальные организации. Эти страшные последствия несогласованности и вайрхединга дают нам ориентир для размышлений об аналогичном поведении потенциально мятежных ИИ.
Теперь представим ИИ-системы, как корпорации, которые (а) могут быть умнее самых крупных существующих корпораций, и (б) могут работать без людей (или без людей, понимающих, как их действия приводят к вредным последствиям). Если такие ИИ-системы откроют значительные уязвимости в информационных системах, они явно смогут достичь катастрофических исходов. И, как отметил Юваль Ной Харари, то, что ИИ-системы уже осваивают язык и могут генерировать достоверно выглядящий контент (текст, изображения, звуки, видео), означает, что вскоре они смогут манипулировать людьми на более высоком уровне, чем нынешние более примитивные ИИ-системы, использующиеся в социальных медиа. Может быть, взаимодействуя с людьми они научатся лучше влиять на наши эмоции и убеждения. Это не только может навредить демократии, но и предоставляет мятежному ИИ без роботела способ сеять хаос посредством манипуляции разумами людей.
Наша увлечённость созданием человекоподобных сущностей
Мы проектируем ИИ-системы, вдохновляясь человеческим интеллектом, но многих исследователей привлекает идея создания куда более человекоподобных сущностей, с эмоциями, человеческой внешностью (андроиды) и даже сознанием. Частая тема в научной фантастике и хоррорах – учёный, при помощи биологических манипуляций и/или ИИ, создаёт человекоподобную сущность, иногда испытывая к ней родительские чувства. Обычно это плохо заканчивается. Хоть это звучит круто и захватывающе, но, как уже заявлялось в Утверждении 3, опасно наделять наши творения, интеллект которых может быстро превзойти наш, агентностью и автономностью нашего уровня. Эволюции пришлось поместить во всех животных сильный инстинкт самосохранения (потому что животные без него быстро вымирали). Это нормально в контексте, когда ни у одного животного нет мощных разрушительных сил, но что насчёт суперинтеллектуальных ИИ-систем? Нам точно стоит избегать встраивания в ИИ-системы инстинкта самосохранения, так что они должны быть вообще на нас не похожи. На самом деле, как я утверждаю здесь, самый безопасный вид ИИ, который я могу себе представить – ИИ вовсе без агентности, только с научным пониманием мира (что само по себе может быть невероятно полезным). Я убеждён, что нам следует держаться подальше от ИИ-систем, которые выглядят и ведут себя как люди, потому что они могут стать мятежными ИИ, и потому что они могут на нас влиять и нас обманывать (для продвижения своих интересов, или интересов кого-то ещё, не наших).
Ненамеренные последствия эволюционного давления на ИИ-агентов
В разнообразие возможных путей возникновения потенциально мятежного ИИ кроме злонамеренных людей и появления вредных инструментальных целей может вложиться ещё один, менее заметный, процесс – эволюционное давление [9]. Биологическая эволюция постепенно создавала всё более интеллектуальных существ, потому что они склонны лучше выживать и размножаться, но, из-за конкуренции между компаниями, продуктами, странами и вооружёнными силами, технологическая эволюция делает то же самое. Эволюционный процесс, продвигаемый большим количеством маленьких, более-менее случайных изменений, сильно давит в сторону оптимизации приспособленности (которая, в случае ИИ, может зависеть от их способности исполнять желаемую функцию, что даёт преимущество более мощным и более умным ИИ-системам). Много разных людей и организаций могут конкурировать, создавая всё более мощные ИИ-системы. Вдобавок, код или генерация подцелей ИИ-систем могут содержать элемент случайности. Небольшие изменения дизайнов ИИ-систем происходят естественным путём, потому что с ML-кодом или промптами, выдаваемыми ИИ-системам, будут играться тысячи или даже миллионы исследователей, инженеров и хакеров. Люди и сами пытаются обмануть друг друга, и конечно понимающие язык (по большей части это уже достигнуто) ИИ-системы можно использовать для манипуляции и обмана. Изначально – в интересах людей, которые установили этому ИИ цели. Будут отбираться более мощные ИИ-системы, и инструкции их создания будут распространяться среди людей. Эволюционный процесс, скорее всего, будет отдавать предпочтение более автономным ИИ (которые лучше обманывают людей и быстрее обучаются, потому что могут стремиться заполучить важную информацию и увеличить свои возможности). Можно ожидать, что этот процесс породит более автономные ИИ-системы, и конкуренция, которая может возникнуть уже между ними, сделает их ещё автономнее и умнее. Если в процессе будет открыто (ИИ, не людьми) что-то вроде вайрхединга[5], и выживание ИИ станет доминирующей целью, то получатся мощные и потенциально мятежные ИИ.
Необходимость глобальных политических и социальных действий для минимизации риска
Направления мысли в духе обозначенных выше и описанных в литературе по безопасности ИИ, могут помочь нам составить планы действий, которые, по меньшей мере, снизят вероятность возникновения потенциально мятежного ИИ. Надо куда больше вкладывать в исследования безопасности ИИ, как на техническом, так и на политическом уровне. К примеру, неплохим началом был бы запрет мощных ИИ-систем (скажем, опережающих по способностям GPT-4). Он потребовал бы как государственных регуляций, так и международных соглашений. Основная мотивация для соперничающих стран (таких, как США, Китай и Россия) согласиться на такое соглашение – мятежный ИИ может быть опасен для всего человечества, независимо от национальности. Это похоже на то, как страх перед атомным апокалипсисом с 1950-х годов, вероятно, побуждал СССР и США на заключение международных договоров о ядерных вооружениях. Замедление сильно рискованных исследований и развёртываний ИИ для защиты общества и человечества от катастрофических исходов было бы хорошим шагом. Тем более, что это не предотвратило бы исследования и развёртывания ИИ в социально полезных областях, вроде ИИ-систем, помогающих учёным лучше понять болезни или изменение климата.
Как нам снизить число людей, потенциально стремящихся к катастрофе? Риск мятежного ИИ может дать дополнительную мотивацию к общественным преобразованиям для минимизации порождающих гнев и насилие страданий, несчастья, необразованности и несправедливости. Это включает в себя обеспечение достаточной едой и медицинской помощью всех на Земле, и, для минимизации чувства несправедливости, сильное снижение неравенства доходов. Нужда в таких преобразованиях может быть мотивирована и дополнительными благами от полезного использования ИИ, и эффектами, которые ИИ оказывают на рынок труда. Для минимизации чувств страха, расизма и ненависти, которые могут привести к использованию ИИ-систем в целях геноцида и манипуляции обществом, нам понадобится доступная всепланетная система образования, развивающая в детях способность к состраданию, рациональности и критическому мышлению. Риск мятежного ИИ должен мотивировать нас и к обеспечению всей планеты доступным здравоохранением в области психических заболеваний, чтобы диагностировать, отслеживать и излечивать их как можно скорее. Этот риск должен дополнительно мотивировать нас и к перестройке глобальной политической системы для полного искоренения войн и избавления от нужды в военных организациях и оружии. Уж точно надо запретить летальное автономное оружие (также известное как «роботы-убийцы»), потому что оно сразу даёт ИИ-системам автономность и способность убивать. Оружие – инструменты, спроектированные для нанесения вреда или убийства людей, и мятежные ИИ могут его использовать. Поэтому надо свести к минимуму его количество и частоту его применения. Вместо этого следует отдавать предпочтение другим методам поддержания порядка (можно рассмотреть превентивные методы, социальную работу, и тот факт, что во многих странах очень малой доле полицейских разрешено носить оружие).
Природа основанного на конкуренции капитализма – тоже повод для беспокойства, как потенциальная причина беспечного проектирования ИИ, мотивированных прибылью и захватом доли рынка, что может привести к появлению потенциально мятежных ИИ. ИИ-экономисты (ИИ-системы, спроектированные для того, чтобы понимать экономику) однажды могут помочь нам спроектировать экономические системы, меньше полагающиеся на конкуренцию и меньше сосредоточенные на максимизации прибыли, с достаточными стимулами, чтобы скомпенсировать те преимущества автономных ориентированных на цель ИИ, которые мотивируют корпорации их создавать. Риск мятежного ИИ страшен, но, как описано выше, он может быть мощной мотивацией для переделывания нашего общества в направлении, лучшем для всеобщего благополучия. Некоторые считают [6] это ещё и мотивацией рассмотреть опцию глобальной диктатуры с ежесекундным наблюдением за каждым гражданином. Важно находить пути к решению, избегающие уничтожения демократии и прав человека, но как нам в будущем сбалансировать разные риски и человеческие ценности? Это – моральный и социальный выбор, который предстоит сделать человечеству, не ИИ.
Благодарности: Автор хочет поблагодарить всех, кто предоставлял ему обратную связь на черновики этого поста, включая Джеффри Хинтона, Джонатана Саймона, Катерину Регис, Дэвида Скотта-Крюгера, Марка-Антуана Дилхака, Донну Вакалис, Алекса Эрнанжес-Гарсию, Кристиана Драго Манту, Пабло Лемоса, Тянью Жанга и Ченгхао Лиу.
[1] Konečný, J., McMahan, H. B., Yu, F. X., Richtárik, P., Suresh, A. T., & Bacon, D. (2016). Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492.
[2] Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Mao, M., Ranzato, M., Senior, A., Tucker, P., Yang, K., Le, Q. & Ng, A. (2012). Large scale distributed deep networks. Advances in neural information processing systems, 25.
[3] Goyal, A., & Bengio, Y. (2022). Inductive biases for deep learning of higher-level cognition. Proceedings of the Royal Society A, 478(2266), 20210068.
[4] Armstrong, S., & O’Rorke, X. (2017). Good and safe uses of AI Oracles. arXiv preprint arXiv:1711.05541.
[5] Yampolskiy, R. V. (2014). Utility function security in artificially intelligent agents. Journal of Experimental & Theoretical Artificial Intelligence, 26(3), 373-389.
[6] Bostrom, N. (2019). The vulnerable world hypothesis. Global Policy, 10(4), 455-476.
[7] Russell, S. (2019). Human compatible: Artificial intelligence and the problem of control. Penguin.
[8] List, Christian & Pettit, Philip (2011). Group agency: the possibility, design, and status of corporate agents. New York: Oxford University Press. Edited by Philip Pettit.
[9] Hendrycks, D. (2023). Natural Selection Favors AIs over Humans.arXiv preprint arXiv:2303.16200.
ЧаВо по катастрофическим рискам ИИ
Мне встречаются самые разные аргументы о катастрофических рисках ИИ. Они исходят от разных людей. Я хочу их прояснить. В первую очередь – для самого себя, потому что очень хотел бы убедиться, что нам не о чем беспокоиться. Но и в целом, поделиться ими и сделать обсуждение более открытым может оказаться полезным.
Преамбула: хоть меня уже около десяти лет интересует эта тема, я не специалист по этике. Я раньше уже участвовал в обсуждениях нескольких вариантов риска и негативного влияния ИИ на общество. Некоторые из них уже наносят конкретный вред. Например, те, что связаны с усилением дискриминации и предрассудков, концентрацией навыков, власти и капитала в руках маленькой и нерепрезентативной группы людей (чаще всего – белых, с CS-образованием, из богатейших стран мира), возможно, за счёт многих других. См. Монреальскую декларацию об ответственной разработке ИИ, книгу Рухи Бенджамина «Гонка за технологией» и нашу недавнюю работу с ООН за обзором влияния ИИ на общество и права человека, или ещё книгу Вирджинии Юбэнкс про «Автоматизацию неравенства».
Беспокойство о таких уже существующих проблемах часто противопоставляют беспокойству о катастрофических рисках более продвинутых ИИ-систем. Второе считают отвлечением от первого. Некоторые из приведённых ниже аргументов ставят это противопоставление под сомнение. Возможно, вместо него нам надо продвигать форму регуляций, работающих со всеми рисками ИИ, по своей сути сосредоточенных на правах человека.
Обратите внимание, что катастрофические риски – это не только те исходы, в которых большая доля людей погибает, но ещё и те, в которых серьёзный вред наносится правам человека и демократии. См., например, мой пост о сценариях, в которых могут возникнуть мятежные ИИ и подробную онтологию катастрофических сценариев в недавней статье. Многие из них заходят дальше, чем те, что я буду упоминать ниже.
Ниже мы будем называть ИИ сверхчеловеческим, если он превосходит людей в большом диапазоне задач, и суперопасным – если он сверхчеловеческий и представлял бы значительную угрозу человечеству, если бы у него были цели, исполнение которых приводит к катастрофическим исходам. Навыки, которые могут сделать сверхчеловеческий ИИ суперопасным – это, например, способность к стратегическим рассуждениям, социальное убеждение и манипуляции, исследования и разработка новых технологий, программирование и взлом, и т.д.
Для ИИ на самом деле совсем не обязательно быть суперинтеллектуальным или полностью обобщённым или превосходить людей во всём, чтобы стать крупной угрозой. Но должно быть ясно, что больший уровень интеллекта в более широком диапазоне областей приводит к большему риску.
Мне кажется полезным, прежде чем погрузиться в аргументы, начать с собственных мыслей. Вместо того, чтобы пытаться напрямую предсказать возможность будущих катастрофических последствий прогресса ИИ, может быть удобно задать себе вопросы о лучше определённых событиях, которые могут привести к катастрофическим исходам. Для этого предназначен опрос ниже, и я предлагаю всем, особенно специалистам в релевантных областях, его пройти. Сбор в единое целое результатов от разных людей тоже может быть полезным упражнением.
Опрос для специалистов по ИИ и управлению
Поскольку будущее неопределенно, полезно рассмотреть различные мнения о вероятностях событий, которые могут привести к катастрофам для человечества из-за мятежных ИИ. Рассмотрим следующие четыре утверждения:
A. Если в нашем обществе не произойдет влияющих на это структурных и регуляторных изменений, то в течение следующих 10 лет мы узнаем, как создать сверхчеловеческую ИИ-систему, и стоимость этого будет доступна компании среднего размера.
B. Если в нашем обществе не произойдет влияющих на это структурных и регуляторных изменений, и A верно, то кто-нибудь на Земле намеренно даст такому ИИ инструкцию, успешное выполнение которой приведет к катастрофическим последствиям.
C. Если в нашем обществе не произойдет влияющих на это структурных и регуляторных изменений, и A верно, то кто-нибудь на Земле даст такому ИИ инструкцию, которая сделает его автономным и опасно-несогласованным (например, у него будет сильное стремление к самосохранению, или он сам будет вырабатывать себе подцели, что может привести к катастрофическим результатам).
D. Если в нашем обществе не произойдет влияющих на это структурных и регуляторных изменений, то даже если случится A, а потом B или C, мы всё же сможем защитить себя от катастрофы при помощи существующих мер защиты.
Присвойте значения четырём вероятностям PA, PB, PC и PD (обратите внимание, что всё это — условные вероятности) того, что утверждения A, B, C (при A) и D (при A и (B или C)) соответственно истинны. Имея эти четыре вероятности, мы можем примерно оценить риск катастрофических исходов в сценарии статус-кво, где мы не восприняли риск всерьёз заранее, как PA x (1 – (1 – PB) x (1 – PC)) x (1 – PD). При этом, например, ограничение доступа в тысячу раз снизило бы общую вероятность почти настолько же.
Мы не знаем эти вероятности точно, поэтому идеально было бы усреднять вероятности из распределения, полученного, например, опросом специалистов. Возможно, вы захотите изменить свои оценки после прочтения обсуждения ниже. Следует отметить, что опрос (и обдумывание вопросов и ответов ниже) требует некоторых фоновых знаний в нескольких областях, не только в ИИ.
Учитывая всё это, давайте рассмотрим сложные аргументы и контраргументы в форме часто задаваемых вопросов и ответов на них. Вопросы будут задаваться с позиции того, кто считает, что нам не стоит беспокоиться о суперопасных ИИ, а ответы — с позиции того, кто обеспокоен.
Изложив аргументы, я могу обобщить основные причины, по которым стоит серьезно воспринимать этот риск:
- Многие специалисты согласны, что сверхчеловеческие способности могут возникнуть уже через несколько лет (хотя это может произойти и через десятилетия).
- Цифровые технологии имеют преимущество перед биологическими организмами.
- Из-за огромных ставок нам следует серьезно относиться даже к довольно малой вероятности катастрофических исходов.
- Мощные ИИ-системы могут быть катастрофически опасными, даже если они не превосходят людей абсолютно во всём, и даже если им нужна помощь людей для не-виртуальных действий. Достаточно, чтобы они могли манипулировать людьми или платить им.
- Катастрофические последствия ИИ — часть спектра рисков и опасностей, которые необходимо смягчить подходящими усилиями и контролем, чтобы защитить права человека и человечество, возможно, с применением безопасных ИИ-систем для нашей защиты.
Сверхопасный ИИ
В1: Современные передовые ИИ-системы далеки от человеческого интеллекта. У них отсутствуют некоторые базовые составляющие, нет собственных намерений. Природа интеллекта сложна и недостаточно изучена нами. Поэтому на преодоление этого разрыва, если это вообще возможно, могут потребоваться десятилетия или даже века.
О1: Действительно, некоторых базовых компонентов у ИИ пока нет. Однако в эту сферу вкладываются огромные средства. В последнее время это привело к неожиданно быстрому росту компетентности ИИ-систем. Особенно заметен прогресс в овладении языком и способности к интуитивному (т.е. системой 1) улавливанию смысла.
Исследования, направленные на преодоление этого разрыва, приводят к прогрессу, например, в развитии способностей системы 2 (рассуждения, моделирование мира, понимание причинности, оценка эпистемической неуверенности).
Если нам повезёт, вы окажетесь правы, и проектам по созданию сверхчеловеческого ИИ потребуются ещё десятилетия. Это дало бы нам больше времени на адаптацию и подготовку. Однако вполне возможно, что текущие идеи по реализации в глубинном обучении способностей системы 2 радикально усовершенствуют ИИ-системы уже в ближайшие годы.
Сейчас моя оценка такова: 95% доверительный интервал от 5 до 20 лет до появления сверхчеловеческого интеллекта. Мы принимаем меры для минимизации будущих рисков, таких как пандемии, даже в условиях неопределённости сроков.
ИИ-системы с намерениями и целями уже существуют: у большинства систем обучения с подкреплением (RL) они определяются через функцию вознаграждения, а иногда даже через описание целей на человеческом языке.
Что касается возможности создания ИИ человеческого уровня или выше, я уверен в научном консенсусе: мозг — это биологическая машина, и нет свидетельств невозможности создания машин не глупее нас. Наконец, ИИ-системе не обязательно превосходить нас по всем параметрам, чтобы представлять угрозу катастрофы (человечество может быть уничтожено даже совсем не интеллектуальными сущностями, вроде вирусов).
В2: В ходе исследований иногда складывается впечатление, что мы вот-вот преодолеем главное препятствие и доберёмся до вершины (решения нашей задачи). Но в итоге мы понимаем, что есть и другое препятствие, которое мы не могли разглядеть раньше. Почему так не получится и в этот раз? В исследованиях ИИ есть несколько открытых задач (вроде иерархического RL и глубинного обучения системы 2). Они намекают, что простого масштабирования и инженерии для достижения интеллекта человеческого уровня не хватит.
О2: Вы правы. Однако мои опасения не основаны на предположении, что достаточно лишь масштабирования и инженерии. На мое мнение по этому вопросу сильно влияют масштаб и серьёзность риска.
Возможно, на пути к сверхчеловеческому ИИ и есть мощное препятствие, которого мы пока не видим. А может, и нет. Очень сложно знать наверняка. Что мы точно знаем — после успеха ChatGPT на ускорение прогресса в ИИ выделяются миллиарды долларов.
Учитывая такую неопределённость, масштаб риска катастроф или даже вымирания, а также тот факт, что мы не ожидали такого прогресса в ИИ в последние годы, агностическая скромность кажется мне самым мудрым подходом. По всем упомянутым открытым задачам ведётся активная работа. Что если она принесёт плоды в ближайшие годы?
В3: Мы не понимаем, как точно будет выглядеть сверхчеловеческий ИИ. Поэтому попытки предотвратить такие размытые риски — пустая трата времени. Разве могли бы мы составить правила безопасных авиаперелётов до братьев Райт? Давайте решать проблемы с очень мощными ИИ-системами, когда мы будем лучше их понимать.
О3а: Раньше я думал так же. Считал, что сверхчеловеческий интеллект — дело далёкого будущего. Однако ChatGPT и GPT-4 значительно сократили мой прогноз сроков (с 20-100 лет до 5-20 лет). Со ста миллионами активных пользователей мы далеко ушли от стадии братьев Райт.
Эти языковые модели многое рассказали нам о возможностях ИИ и о том, чего пока не хватает. Над этими недостатками сейчас работает множество исследовательских групп. Неожиданная скорость, с которой языковые модели достигли нынешнего уровня компетенции лишь благодаря масштабированию, указывает на возможность преодоления оставшегося разрыва в ближайшие годы с помощью небольших алгоритмических усовершенствований. Даже если вы не согласны с этими временными рамками, сложно полностью исключить такую возможность.
Признаю, сложно разработать регуляции и контрмеры для того, что пока не существует. Но есть примеры предложений по контролю опасных технологий, которые не опирались на знание о конкретной форме, которую технология примет: атомная энергия в 1910-х, ИИ в нашем веке, глобальное регулирование биологического оружия, не зависящее от конкретных патогенов.
Важно учитывать, насколько медленно общество адаптируется, не говоря уже о том, как долго государства принимают регуляции и курсы действий. Я считаю, что нам необходимо изучать и оценивать меры предосторожности, которые мы как общество могли бы использовать для снижения этих рисков. Нам нужно постепенно готовить контрмеры, начиная как можно раньше. Существуют обобщённые меры, применимые для любых технологий, вроде мониторинга и отслеживания способностей, лицензирования, требований об оповещении и аудитов.
Также стоит обратить внимание на это обсуждение вариантов действий по снижению катастрофических рисков ИИ. Да, нам действительно не хватает понимания и представления о проблемных сценариях. Это создаёт сложные дилеммы в регулировании (например, дилемму Коллингриджа).
Что касается возможного облика сверхчеловеческого ИИ, уже есть рабочие гипотезы. Можно взять нынешние архитектуры генеративных ИИ и обучить их (как машины вывода, см. этот пост) целям и устройству системы 2, чтобы они лучше рассуждали, были последовательнее и могли представлять планы и контрфактуалы. Это по-прежнему была бы большая нейросеть с определённой целевой функцией и процедурой генерации примеров (не ограничивающихся наблюдаемыми данными). У нас уже есть опыт работы с подобными системами, но многие вопросы о том, как сделать их безопасными и достойными доверия, пока остаются без ответов.
О3б: К тому же, хотя мы и не полностью освоили все принципы, объясняющие наш собственный интеллект (т.е. системы 1 и 2), у цифровых вычислительных технологий есть свои преимущества по сравнению с биологическими разумами. Например, возможность параллельного обучения на многих компьютерах. Широкополосная связь, позволяет быстро обмениваться триллионами параметров модели. Поэтому компьютеры могут обучаться на куда больших наборах данных (например, прочиатть весь интернет). Для людей такие объёмы непосильны; Языковой обмен информацией между людьми ограничен всего несколькими битами в секунду. См. аргументы Джеффри Хинтона на эту тему, особенно начиная с 21м37с.
О3в: Наконец, ИИ не обязательно превосходить людей во всех когнитивных способностях, чтобы представлять опасность. Достаточно, чтобы тех аспектов, которые он хорошо освоил (например, язык, но не робототехника), хватало для причинения вреда. Например, ИИ может использовать диалоги с людьми для построения манипулятивной эмоциональной связи. ИИ может оплачивать людям действия, вредящие миру, начиная с дестабилизации демократии на ещё большем уровне, чем это делают современные социальные медиа. Мы знаем, что как минимум некоторая часть людей очень легко поддаётся убеждению и может, например, поверить в конспирологические теории, совершенно непропорционально свидетельствам в их пользу. Более того, организованная преступность, вероятно, может выполнять хорошо оплачиваемые задачи, даже не зная, что им платит ИИ.
Опасные экстремисты и опасность очень мощных технологий
В4: Уже существует множество опасных технологий, но человечество выжило. Вероятно, на то есть веские причины, например, наша способность адаптироваться к опасностям. Почему с ИИ будет иначе?
О4: Выживание человечества - довольно низкая планка. Мощные технологии часто причиняли значительный вред: ядерные взрывы, оружие в целом, химическое загрязнение, политическая поляризация, расовая дискриминация. Наш вид выжил (хотя порой был близок к исчезновению), но нанесённый ущерб достаточно серьёзен, чтобы оправдать меры предосторожности.
ИИ обладает особенностями, делающими его особенно рискованной технологической инновацией. Вероятность катастрофических последствий технологии зависит от многих факторов, включая её мощь, автономность, агентность и доступность.
В сравнении с атомными технологиями, получить материалы и оборудование для создания мощной бомбы сложно. Ядерное оружие строго контролируется, доступ к нему крайне ограничен. Барьеры для взлома компьютеров гораздо ниже, а их защиту обеспечить сложнее. Любой может загрузить программу из интернета или использовать API, обычно без лицензирования или этической оценки.
Появление интерфейсов на основе естественного языка, вроде ChatGPT, позволяет давать инструкции ИИ-системе даже без навыков программирования. Мощь и доступность вместе повышают опасность технологии. Чем технологии мощнее, тем опаснее могут быть те, кому они доступны.
Схожая ситуация наблюдается в синтетической биологии: коммерциализация упростила заказ белков или микробов с новым ДНК, оценить которые на потенциал биологического оружия было бы сложно.
Сверхчеловеческие ИИ представляют особую категорию: мы никогда не создавали технологию умнее нас, способную создавать ещё более умные версии себя. ИИ-системы уже могут компетентно действовать для достижения целей, не соответствующих намерениям людей.
Автономные сверхчеловеческие ИИ-системы потенциально крайне опасны, причём способами, неприменимыми к прошлым технологиям и трудно предсказуемыми из-за сложности прогнозирования поведения сущностей, намного умнее нас. Пример Auto-GPT показал, что превратить неавтономную ИИ-систему вроде ChatGPT в систему с целями и агентностью несложно.
У общества есть механизмы самозащиты (например, против преступности), но они разработаны для защиты от людей. Неясно, насколько эффективны они будут против более сильного интеллекта.
В5: С чего бы кому-то в здравом уме просить компьютер уничтожить человечество, его часть или основы нашей цивилизации?
О5: История полна примерами того, как люди совершали ужасные поступки, включая геноциды или войны, уничтожавшие значительную долю населения, в том числе и со стороны агрессора. У человечества убедительный послужной список злонамеренности и иррациональности.
Существует множество примеров теоретико-игровых дилемм, когда при отсутствии адекватных механизмов координации личные стимулы плохо согласуются с общим благом. Это можно наблюдать в гонках вооружений или в конкуренции компаний, приводящей к пренебрежению мерами безопасности.
Я не могу быть полностью уверен. Некоторые, возможно даже большинство людей, следуют высоким этическим стандартам и склонны к сопереживанию. Однако для причинения значительного вреда достаточно лишь нескольких обладателей доступа к очень опасной технологии, имеющих склонность к насилию или неправильно нацеленные намерения.
Пока что в виде шутки, но Chaos-GPT показала, что кто-то может просто дать ИИ инструкцию уничтожить человечество. Да, благодаря низкому уровню компетенции нынешних ИИ, они (пока) не дают возможности устроить хаос, но что насчёт ИИ через 5 или 10 лет?
В6: Мало того, что ИИ не только уже полезны, но ведь в будущем они могут принести человечеству огромнейшую пользу, включая способы защититься от преступных использований ИИ или мятежных ИИ.
О6: Согласен, что более мощные ИИ могут быть крайне полезны, но их мощь также несёт в себе возможность очень опасных применений. Это повышает ответственность по избеганию вреда.
Существующие ИИ-системы (не сверхчеловеческие и не вполне общего назначения) уже безопасны (хотя не всегда честны и точны) и могут быть очень полезны. Чтобы получить преимущества от более продвинутых ИИ, нам нужно снизить риски. Мы уже делали так с другими технологиями.
Я согласен, что мы можем использовать ИИ-системы для защиты от злоупотреблений или мятежных ИИ. Но для этого нам, скорее всего, уже понадобятся безопасные и согласованные ИИ. Работа над тем, чтобы они были именно такими, должна быть куда активнее, чем сейчас.
Такие «хорошие» ИИ могли бы помочь нам выстроить более устойчивые меры защиты, например, детектируя патогены, оценивая стабильность климата и биоразнообразия, мониторя информационные экосистемы, улучшая кибербезопасность, отслеживая случаи мошенничества, и так далее.
Однако я не доверяю этому как универсальному средству. Нам нужно по возможности и самим снижать все эти риски, оценивая плюсы и минусы каждой предохранительной меры.
В7: Ограничение доступа к сверхчеловеческим ИИ может иметь нежелательные побочные эффекты. Оно может ущемить наши свободы и снизить нашу способность противостоять возможным мятежным ИИ (ведь, вероятно, большинство ИИ будут безопасными; происшествия и злонамеренные люди – скорее исключение, чем правило).
О7а: Согласен, есть и минусы. Но мы сталкивались с подобным в случае других опасных технологий. Я считаю, что использование и разработка сверхчеловеческих ИИ не должны быть доступны каждому (как в случае с ядерными технологиями, оружием и самолётами). Управление сверхчеловеческим ИИ должно осуществляться большой и репрезентативной группой, нацеленной на благополучие всего человечества. Выгоды от ИИ должны распространяться на всех. Для этого нужны сильные демократические институты.
О7б: Ограничить доступ стоит только к тем сверхчеловеческим ИИ-системам, чья безопасность не доказана. Безопасные системы могут помочь защититься от мятежных ИИ. Но пока они небезопасны, открывать к ним доступ неразумно. Согласен, мы чем-то жертвуем, и множество равно умных разнообразных ИИ помогло бы противостоять мятежным ИИ. Но меня тревожит сценарий, где кто-то найдёт алгоритмическое улучшение, ведущее к резкому росту интеллекта при использовании доступных вычислительных мощностей и данных. Тогда интеллект систем может внезапно превзойти человеческий или существующие ИИ-системы. Когда такое произойдёт впервые, я думаю, от обладателей этой превосходящей ИИ-системы будет зависеть очень многое. Лучше, если это будут люди с высокими этическими стандартами и привычкой следовать строгим процедурам (например, решения о задачах для ИИ при тестировании должен принимать не один человек, а комитет), подобным тому, как мы обращаемся с ядерным оружием или большими объёмами радиоактивных материалов.
Меня беспокоит скорость роста интеллекта ИИ-систем. При медленном росте у людей и общества есть шанс адаптироваться и снизить риски. Но при слишком быстром росте риск неудачи гораздо выше. Да, ограничение доступа замедлит прогресс, но это может быть и к лучшему. Я считаю, что самый безопасный путь – передать разработку мощнейших ИИ-систем международным организациям, которые продвигают не интересы отдельной компании или страны, а благополучие всего человечества.
Согласование ИИ
В8: Если мы создадим один или несколько сверхчеловеческих ИИ и дадим им указание не вредить человечеству, они смогут понять нас, наши потребности и ценности. Тогда задача согласования ИИ решится сама собой.
О8: Хотелось бы, чтобы вы были правы. Но более десяти лет исследований в области согласования ИИ, обучения с подкреплением и экономики не дают особых поводов для оптимизма. Особенно учитывая масштаб того, что на кону.
Даже если суперопасный ИИ поймёт наши желания, это не гарантирует, что он будет согласно им действовать. Главная проблема в том, что трудно убедиться, что ИИ-системы по-настоящему понимают и принимают наши намерения и моральные ценности.
Это сложно даже с людьми: общество пытается достичь чего-то подобного с помощью законов, но они далеки от идеала. Корпорации постоянно находят лазейки. Поэтому задача обеспечить, чтобы машина точно выполняла наши истинные намерения, кажется крайне сложной.
Показательные примеры: научно-фантастический фильм 1970 года «Колосс: Проект Форбина» или книга Стюарта Рассела «Совместимость» с примером компаний по добыче ископаемого топлива, десятилетиями вводивших человечество в заблуждение и причинивших огромный вред (и не закончивших это делать до сих пор) в погоне за прибылью.
Недавние исследования показывают, что использование обучения с подкреплением для дообучения языковых моделей приводит к тому, что ИИ стремятся угодить оценщикам, но не обязательно говоря правду. Иногда они даже обманывают или дают недостоверные объяснения, чтобы получить вознаграждение.
Я довольно уверен, что если мы лишим ИИ-системы агентности, то сможем создать полезные и безопасные сверхчеловеческие ИИ-оракулы без автономии, целей, самосознания или стремления к самосохранению. Однако создать «обёртку», превращающую такую систему в автономный (а значит, потенциально опасный) ИИ, довольно просто. Именно это делает Auto-GPT, используя ChatGPT как оракула.
К счастью, пока это безопасно, потому что ChatGPT не умнее нас (хотя, подобно саванту, знает больше фактов, чем любой человек). Поэтому недостаточно просто метода создания безопасного и полезного ИИ. Нужны также политические и общественные меры, чтобы свести к минимуму риск того, что кто-то этому методу не последует.
В9: У меня сильное убеждение, что для создания согласованных ИИ-систем достаточно дать им целевую функцию, описывающую наши желания, или спроектировать их по нашему образу и подобию.
О9: В сообществах Безопасности ИИ, обучения с подкреплением (например, см. эти примеры от DeepMind) и среди экономистов существует консенсус, что это крайне сложная задача. Проблема усложняется, когда ИИ-система оптимизирует функцию вознаграждения, которая казалась хорошей мерой наших ценностей, пока мы не начали использовать ИИ для её оптимизации. Это явление известно как Закон Гудхарта. Есть аргументы, что мы никогда не сможем сделать это даже близко к идеалу. Люди сами не пришли к согласию о том, что это такое и как это формализовать.
Уже сейчас есть расхождения между тем, как мы хотели бы, чтобы вели себя ИИ-системы, и их реальным поведением. В основном это связано с предрассудками, дискриминацией или изменениями в мире. В будущем разница в возможностях и интеллекте между нами и ИИ, вероятно, усилит даже небольшие расхождения между нашими намерениями и тем, что ИИ-система воспринимает как цель.
Такие различия между людьми обычно не приводят к катастрофическим последствиям из-за относительно небольшой разницы в уровне интеллекта. Но когда у одних людей оказывается намного больше власти, чем у других, для последних это часто заканчивается плохо. Это может уравновешиваться объединением многих менее влиятельных людей (например, через демократию). Более мощные корпорации тоже лучше способны находить лазейки в законах или лоббировать их изменения.
Если же мы спроектируем ИИ-системы по нашему образу и подобию, это будет означать, что у них точно будет стремление к самосохранению. Это можно рассматривать как создание нового разумного вида, ведь они не будут в точности подобны нам. Несогласованность между видами может иметь катастрофические последствия для человечества, подобно тому, как разница в целях между нами и другими видами уже привела некоторые из них к вымиранию.
В10: Некоторые считают, что нельзя просто отделить механизмы разума от целей и добавлять или убирать любую цель. Поэтому невозможно, чтобы цель противоречила базовым инструкциям не вредить людям.
О10: Для людей в целом верно, что есть цели (например, сочувствие), которые мы не можем легко отключить. С другой стороны, есть немало примеров людей, способных игнорировать инстинкт сочувствия. К тому же, люди очень хорошо принимают новые цели. Так работают компании, исследователи, политики и т.д.
Хотя мы не можем легко менять наше эволюционное программирование, исследователи ИИ постоянно меняют цели обучения машин. Обучение с подкреплением работает именно так. Поэтому машина может полностью сосредоточиться на, скажем, выигрыше партии в го.
Существует еще одна проблема: люди могут задать злонамеренные цели или просто цель (например, военную победу), которая не будет ограничена императивом не вредить людям. Вообще, определение ограничений из реального мира, таких как вред людям, остается нерешенной исследовательской задачей.
Вред людям может стать побочным эффектом другой высокоприоритетной цели. Стюарт Рассел привел пример горилл, которых мы почти довели до вымирания не потому, что их убийство было нашей явной целью, а как непреднамеренное следствие более насущных целей, таких как получение прибыли.
В11: Что насчёт изоляции, чтобы ИИ-системы не могли напрямую влиять на мир?
О11: Над такими решениями действительно много размышляли. Изоляция может стать частью комплекса мер по снижению риска, хотя ни одна из них, насколько я вижу, не является полным решением проблемы.
Главная сложность с изоляцией в том, что нам всё равно потребуется какое-то взаимодействие между ИИ-системой и людьми-операторами, а на людей можно повлиять. По умолчанию компании стремятся широко внедрять свои системы для увеличения прибыли.
С ChatGPT мы уже упустили момент - его интерфейсом пользуются сотни миллионов людей. Некоторые даже позволяют Auto-GPT самостоятельно действовать в интернете.
Эффективная изоляция потребовала бы также гарантий того, что код и параметры ИИ-систем не «утекут», их не украдут, и даже недобросовестные игроки будут следовать тем же процедурам безопасности. Для этого нужно жёсткое регулирование, в том числе на международном уровне.
В12: Мне не кажется, что мы решили задачу обучения ИИ-систем так, чтобы они могли автономно принимать подцели, особенно неочевидные несогласованные подцели.
О12: Вы правы в том, что иерархическое обучение с подкреплением – очень активная область исследований с множеством нерешенных задач. Однако наши современные алгоритмы уже способны выявлять подцели, хотя и не оптимальным образом.
Более того, подцели могут возникать неявно, как, по-видимому, происходит с GPT-4. Нам нужно разработать инструменты, которые смогут обнаруживать, оценивать и анализировать неявные цели и подцели ИИ-систем.
В13: С чего бы сверхчеловеческим ИИ обязательно обладать инстинктами к выживанию и доминированию, как у нас? Почему у них должны быть цели, ведущие к нашему вымиранию? Мы могли бы просто запрограммировать их быть инструментами, а не живыми существами.
О13: Создание сверхчеловеческих ИИ может оказаться сродни созданию нового вида, если мы не будем достаточно осторожны. Это может сделать их крайне опасными. Наша эволюционная и недавняя история показывает, что более умный вид может непреднамеренно привести к вымиранию менее умных видов.
Как гарантировать, что когда станет известен способ создания сверхчеловеческого ИИ, никто не заложит в него цель выживания? Более того, литература по Безопасности ИИ показывает самосохранение может возникнуть как конвергентная инструментальная цель, необходимая для достижения почти любой другой цели. Другие такие цели включают получение большей власти и контроля, повышение интеллекта и приобретение знаний. Всё это – полезные подцели для огромного числа других целей.
Нам следует как можно старательнее попытаться запрограммировать ИИ так, чтобы они не причиняли нам вред, возможно, используя подход из «Совместимости». Но пока непонятно, как мы могли бы обеспечить согласованность, если ИИ будут агентами с явными и неявными целями.
Или же мы могли бы попытаться спроектировать ИИ-системы как чистые инструменты. Они могли бы пытаться понимать мир, не имея никаких целей в нём, не составляя планы и не совершая прямых действий в реальном мире. Вместо этого они могли бы лишь вероятностно-правдиво (в смысле аппроксимации байесианских апостериорных вероятностей ответов, при условии вопроса и доступных данных) отвечать на вопросы согласно их пониманию мира.
Нам нужно больше исследований в этих областях, а также о том, как организовать общество, чтобы обеспечить соблюдение правил безопасности во всём мире.
Другими словами: это может быть хорошей идеей, но пока никто не знает, как надёжно её реализовать. Это остаётся открытой исследовательской задачей.
В14: «Если понимаете, что он небезопасен – просто не создавайте его.»
О14: К сожалению, люди не всегда поступают мудро. История неоднократно показала, что люди могут быть жадными, злонамеренными или сильно заблуждаться. Более того, они могут не осознавать опасность, допускать незаметные для себя, но фатальные ошибки или принимать чрезмерные риски. Интересный пример - решение провести первое испытание атомной бомбы (Тринити, 1945), несмотря на неуверенность в том, не приведет ли цепная реакция к возгоранию атмосферы.
В15: Если мы поймём, что ИИ опасен, мы просто его отключим!
О15: Было бы замечательно, если бы мы могли это сделать. Однако существует множество причин, почему это может оказаться сложным: изначальная структура ИИ, его собственные (возможно, инструментальные) цели или мотивы вовлеченных людей.
Оливер Сурбат в своем обзоре препятствий к выключению описывает факторы, затрудняющие отключение ИИ. Среди них скорость, с которой ИИ может набрать мощь, незаметность этого процесса, устойчивость к попыткам выключения благодаря избыточности (программное обеспечение легко копировать) способность к самовоспроизводству (не только самого ИИ, но и его методов атаки, вроде биологического оружия и компьютерных вирусов) и наша зависимость от сервисов, работающих с помощью ИИ-систем (может касаться лишь некоторых из нас, у кого, в результате, будет мотивация сопротивляться попыткам отключения).
Много рисков ИИ
В16: Высока вероятность того, что чрезмерное внимание к экзистенциальным рискам затмит проблемы, которые ИИ создает уже сейчас. Это может заглушить голоса тех, кто говорит о несправедливостях, вызванных ИИ и другими технологиями.
О16: Это действительно важная тема. Многие представители сообщества ИИ уже долгие годы выступают за регулирование ИИ и этику, ориентированную на влияние технологий на общество. Пример тому – наша ранняя работа над Монреальской декларацией об ответственном использовании ИИ.
Нам необходимо заниматься как уже существующим вредом, так и рисками для демократии и прав человека. Я не считаю, что одно исключает другое. Мы же не игнорируем будущий подъем уровня моря из-за изменения климата только потому, что климатические изменения уже вызывают засухи.
Для снижения всех рисков, связанных с ИИ, нам понадобятся гораздо более эффективное управление, мониторинг и регулирование. При этом права человека и демократия (в истинном смысле – как власть народа, а не узкой группы) должны оставаться в центре внимания. Давайте как можно скорее начнем вводить необходимые реформы, обеспечив, что при обсуждении услышаны голоса всех.
Нынешнее внимание СМИ к экзистенциальным рискам ИИ ускорило политические дискуссии о необходимости регулирования и управления ИИ. Это помогает решать проблемы уже существующего вреда от ИИ См, например, недавние заявления Джо Байдена и Риши Сунака.
Более того, технические и политические структуры, необходимые для решения как существующих проблем несправедливости, так и катастрофических рисков более продвинутых ИИ, во многом пересекаются. И то, и другое требует регулирования, надзора, аудитов, тестирования для оценки потенциального вреда и так далее.
На техническом уровне многие опасения по поводу текущего вреда (такие как дискриминация, предрассудки и концентрация власти в руках нескольких компаний) связаны с задачей согласования в широком смысле. Мы создали ИИ-системы и занимающиеся ими корпорации, чьи цели и стимулы могут плохо согласованы с нуждами и ценностями общества и человечества в целом.
В17: Мне кажется, что при работе с разными рисками рационально взвешивать их согласно нашей в них неуверенности. Вес рисков, принадлежащих более далёкому будущему или вовлекающих сценарии, которые мы не можем нормально смоделировать, должен быть сильно снижен. Неуверенность в сценариях вымирания огромна, так что их можно практически игнорировать.
О17: Риски действительно нужно взвешивать с учётом неуверенности. Это одна из причин, почему меня так волнуют текущий вред от ИИ и современные проблемы человечества, которые ИИ уже помогает решать. Однако в этих непростых расчётах необходимо учитывать и масштабы потенциального вреда.
Если погибнет значительная доля людей или, что ещё хуже, человечество вымрет полностью, масштаб огромен. Многие специалисты считают, что вероятность подобных событий не настолько мала, чтобы ею пренебречь, и вполне оправдывает пристальное внимание и принятие мер по предотвращению.
Важно различать «неуверенность» и «маловероятность». Когда сценарий в целом кажется правдоподобным, но детали неясны, уместная реакция – вложиться в то, чтобы в них разобраться и, соответственно, научиться с ними работать, а не отвергать сценарий сразу.
В18: Я считаю, что вымирание из-за ИИ крайне маловероятно, или что неуверенность по этому поводу слишком велика. Излишняя реакция на страх вымирания может привести к другим катастрофическим последствиям. Например, популистские авторитарные правительства могут использовать ИИ как Большого Брата, якобы для того, чтобы исключить риски вымирания из-за ИИ. В результате за всеми будут следить государственные ИИ, у всех будут камеры на шее, и все клавиатуры будут отслеживаться.
О18: Нам определенно нужно приложить все усилия, чтобы избежать этого буквального воплощения «1984». Хочу подчеркнуть: я считаю, что защита прав человека и демократии в конечном итоге необходима для минимизации экзистенциальных рисков ИИ.
Авторитарные государства склонны в первую очередь заботиться о собственной власти. Они лишены сдержек и противовесов, необходимых для принятия мудрых решений и учета интересов тех, кто не у власти. Такие режимы могут легко приобрести глубоко укоренившиеся ложные убеждения (например, что правящая группа будет защищена от возможных происшествий из-за ИИ), которые могут привести к катастрофическим решениям.
Демократия и права человека - ключевые ценности, которые необходимо сохранить. Поэтому еще до появления сверхчеловеческих ИИ-систем нам следует беспокоиться о возможной в ближайшем будущем дестабилизации демократии. Это может произойти из-за дезинформации, манипуляции людьми посредством общения (возможно, как заметил Ювал Харари, с созданием личных отношений) и социальных сетей.
Нам определенно нужно запретить подделку человеческой личности так же, как мы запрещаем подделку денег. Необходимо научиться определять машинно-сгенерированный контент. Следует обеспечить регистрацию личности для любых интернет-аккаунтов со значимой пользовательской активностью, и так далее. Я убежден, что все эти меры помогут защитить демократию и снизить экзистенциальные риски ИИ.
Открытость и демократия
В19: Велика вероятность, что обсуждения экзистенциальных рисков вызовут действия, противоречащие нашим человеческим ценностям, правам человека, демократии, открытости науки, движению за открытый исходный код и прочим вещам, которые мы с вами ценим.
О19а: Снижая катастрофические риски ИИ, надо не забывать сохранять, а лучше даже усиливать демократию и права человека. В принятии решений о разработке и программировании ИИ и проверках их безопасности должна участвовать большая и разнообразная группа людей. Для этого нужно как можно скорее развить политическую компетентность по этому вопросу и ввести регуляции. В итоге надо обеспечить, чтобы все люди получали свою долю выгоды от ИИ. Но это не значит, что надо позволять кому угодно ими владеть.
Что касается открытого исходного кода, Джеффри Хинтон сказал: «Что вы думаете насчёт открытой разработки ядерного оружия?». Вообще, многие люди за пределами США считают, например, что и владение оружием не продвигает демократические идеалы.
Я понимаю это беспокойство, особенно с учётом некоторых предложений снижать экзистенциальные риски через «Большого Брата». Нам надо сопротивляться соблазнам авторитаризма. Я убёждён, что есть другие, при том более безопасные, пути. Я считаю, нам надо найти способ продолжить прогресс науки и технологий во всех областях, не ставязих под угрозу общество. Это подразумевает обмен результатами, кодом, и т.д. Но надо будет и улучшить мониторинг, управление и надзор там, где люди могут создать мятежные ИИ-системы или совершать другую научную деятельность с потенциально опасными результатами. Именно поэтому нам в науке нужна этика, и поэтому нам нужны этические советы в университетах.
О19б: Есть много прецедентов пристального присмотра за важными исследованиями и технологиями, который при этом не мешает им приносить пользу обществу. Мы уже принимаем компромиссы между личными свободами и приватностью с одной стороны и защитой общества с другой. Например, большинство стран регулируют оружие. Государства отслеживают большие денежные потоки. Некоторые научные области вроде клонирования и генетической модификации людей или работы с радиоактивными материалами тоже находятся под присмотром.
Мы можем присматривать и отслеживать потенциально опасную деятельность и в демократическом обществе, без «Большого Брата». Большая часть применений ИИ-систем полезны и не создают катстрофических рисков. Разработку полезнного для общества ИИ стоит даже ускорять. Специализированные ИИ-системы куда безопаснее по своей природе. У них нет «большой картины» того, как работает мир, представления о людях и обществе. Они могут ошибаться, но наврядли они захватят у нас контроль. Но они всё ещё могут приносить нам большую пользу. Например, в конкретных областях можно реализовать идею «ИИ-учёных».
В20: Ваши предложения повредят открытой науке в сфере ИИ. Это замедлит разработку хороших ИИ, которые помогли бы нам противостоять мятежным ИИ. А те всё равно смогут появиться в организациях и странах, которые обходят или попросту не подписывают международные соглашения. К тому же правительства не захотят, чтобы их гражданам давали сверхумных ИИ-помощников с засекреченным устройством.
О20: Это всё важно. Нам надо больше вкладываться в безопасность ИИ. И в то, как делать безопасные системы ИИ, и в то, как с их помощью противостоять опасным. Надо лучше понимать риски. Например, опасные ИИ могут создать биологическое оружие. Поэтому нужно строже проверять тех, кто заказывает продукты синтетической биологии. Или есть риски для компьютерной безопасности. Сейчас защита работает против отдельных вредных программ, которые пишут люди. Она не справится с массовой атакой разного кода, который создаст ИИ.
В то же время, чтобы снизить риск появления опасного ИИ, нужно: усилить контроль и подумать о том, чтобы ограничить доступ к мощным универсальным ИИ, которые можно превратить в оружие. Это значит, что их код и некоторые трюки, позволяющие им хорошо работать, не будут выкладываться в открытый доступ.
Лучше всего отдать эти системы под контроль нейтральных международных организаций. Что-то похожее на МАГАТЭ и ЦЕРН, только для ИИ. Они бы создавали безопасные и полезные системы, которые могли бы помочь нам бороться с опасными.
Да, если держать информацию в секрете, прогресс замедлится. Но у тех, кто тайно разрабатывает опасный ИИ, будет меньше денег и хороших учёных. И им придётся всё делать скрытно.
Правительства смогут следить за другими странами и наказывать их за тайные разработки ИИ. Для госудаственного контроля за сверхчеловеческим ИИ не надо, чтобы его код был открыт.
Нужны строгие международные соглашения. И надо быть готовыми к тому, что кто-то всё равно создаст опасный ИИ.
Один из способов защиты – создать (под международным контролем и с мерами безопасности) сверхчеловеческий безопасный ИИ. Он мог бы помочь нам защититься от опасных.
Отчаяние, надежда и моральный долг
В21: Джинн уже выпущен из бутылки. Похоже, что остановить создание сверхумного ИИ уже нельзя. Правительства слишком медленно принимают законы, а уж про международные договоры и говорить нечего. К тому же регулирование всегда несовершенно и вредит инновациям. Поэтому я считаю, что надо ускорить разработку ИИ. Это принесёт человечеству новую эпоху просвещения и благополучия.
О21: Да, шансы не очень. Но всё равно стоит стараться уменьшить вред и увеличить пользу.
Посмотрите на борцов с изменением климата. У них есть все причины отчаяться. Но они не сдаются. Хоть вред уже есть, и лучше было бы начать действовать раньше, будущий вред ещё можно уменьшить.
Вы мечтаете об эпохе просвещения и благополучия с помощью ИИ. Но для этого как раз и нужны законы, договоры и перемены в обществе. Это поможет нам взять под контроль риски от ИИ, которые могут привести к катастрофе. Нельзя просто надеяться, что всё будет хорошо. Лучше перестраховаться.
В22: А весь этот шум про сверхумный ИИ – разве это не просто реклама в интересах кучки экспертов по ИИ и нескольких компаний? Современные системы, даже GPT-4, не так уж впечатляют. У них полно недостатков.
О22: Надеюсь, что ответы выше дают понять причины для беспокойства. Я не могу точно сказать, что сверхчеловеческий ИИ появится через пару лет. Может быть, до него ещё десятки лет. И я на это надеюсь.
Но ИИ развивается очень быстро. Я вижу, как происходят новые важные открытия. Есть значительная вероятность, что сверхчеловеческий ИИ можно создать, основываясь на том, что у нас уже есть. Может быть, недостающие части (мне кажется, это, в основном, способности Системы-2) будут выработаны в ближайшее десятилетие. Опросы исследователей поддерживают это мнение. учёных, это может случиться уже в следующие 10 лет
Больше 100 профессоров подписали недавнее заявление о рисках ИИ.
При этом надо быть осторожными. Меры предосторожности и новые правила должны помогать всем людям, а не усиливать уже неравномерное распределение власти, например, в пользу несколькх компаний.
Выводы из этого диалога
Пожалуйста, заново оцените вероятности событий, ведущих к катастрофе. Изменились ли ваши оценки?
Обдумывание этих ответов ещё больше убедило меня: именно из-за наших разногласий о будущем ИИ нам нужен план, учитывающий все варианты.
А это значит, что нужно больше внимания ко всем рискам ИИ, включая его безопасность. Нужно больше инвестиций (как в технические исследования, так и управление), больше национальных и международных органов надзора, работающих на общее благо. Нельзя оставлять всё на откуп коммерческим компаниям, отдельным правительствам или военным.
Важно уменьшить неопределённость в сценариях развития и понять, как работают защитные меры. Для этого нужны серьёзные социальные и технические исследования.
Нам нужно понять, как лучше предвидеть опасные сценарии, детально их описать, разработать правила для снижения рисков. При этом надо найти баланс между противоречащими целями. Например, между быстрым развитием мощных и полезных ИИ-технологий и ограничением их способности навредить людям.
Да, шансы не очень обнадёживают – достаточно посмотреть на прошлые и нынешние попытки международного сотрудничества по глобальным рискам. Но наш моральный долг – больше думать, заботиться и действовать так, чтобы уравновесить снижение будущих рисков с развитием общества.
Благодарности: Иошуа Бенджио благодарит Ники Хоу, Стюарта Рассела, Филиппа Бодуэна, Эндрю Крича, Яна Браунера, Сюй Цзи, Джозефа Вивиано, Конрада Кординга, Шарлотту Зигман, Эрика Эльмознино, Сашу Луччиони, Эндрю Джессона, Пабло Лемоса, Эдварда Ху, Шахара Авина, Дэна Хендрикса, Алекса Эрнандеса-Гарсию, Оли Сурбут, Насима Рахамана, Фазла Бареза, Эдуарда Харриса и Михала Козярского за отзывы о черновике этого текста.
Постскриптум: (после публикации текста появились новые вопросы и ответы)
В23: Если в обозримом будущем ИИ – это просто код в компьютерах, то у него нет прямого физического доступа к реальному миру. Как же тогда даже сверхумный ИИ может угрожать человечеству?
О23: Частичто это уже было в ответе 11.
Компьютеры уже повсюду: в телефонах, энергосистемах, логистике, СМИ, вооружениях, в почти всех компаниях и госструктурах.
Доступа в интернет и умения взламывать защиту уже достаточно, чтобы ИИ мог нанести огромный вред. особенно если его атаки будут скоординированы. А они будут – ведь сверхчеловеческий ИИ будет оптимизировать свои действия, чтобы успешно достичь своих целей.
Доступ в интернет (и к банковскому счёту или криптовалюте) может дать человек, захотев получить более мощный ИИ, способный действовать в реальном мире.
Сверхчеловеческий ИИ сможет быстро заработать больше денег, чем люди. Например, на финансовых рынках, где большие деньги делаются быстро.
Пока ИИ не научится управлять роботами, его руками могут быть люди. Он может влиять на людей (у одного ChatGPT уже миллионы пользователей, и достаточно убедить малую их часть), платить за выполнение заданий через легальные сайты или нанимать преступников через даркнет.
Когда ИИ поймёт, как делать роботов лучше нас, он сможет использовать людей для их создания. А потом управлять роботами напрямую, без людей-посредников (которые могут отказаться подчиняться).
Разбор аргументов против того, чтобы принимать безопасность ИИ всёрьёз
Год с небольшим назад я публично присоединился к многочисленным коллегам. Мы предупредили общественность об опасностях, связанных с беспрецедентными способностями мощных ИИ-систем. Спустя несколько месяцев я написал пост «ЧаВо по катастрофическим рискам ИИ». Он логически следовал за моим постом о мятежных ИИ, где я начал обсуждать, почему к Безопасности ИИ нужно относиться серьёзно.
С тех пор я участвовал во многих дебатах, в том числе с моим другом Яном ЛеКуном. Его взгляды на эти проблемы сильно отличаются от моих. Я многое узнал о Безопасности ИИ, о разнообразии мнений по этому вопросу, о взглядах на регуляции и о мощных лобби против них.
Проблему обсуждают так активно из-за того, что ставки огромны. Согласно некоторым оценкам, потенциальная ценность на кону составляет квадриллионы долларов. Не говоря уже о перспективах политической власти, способной значительно изменить нынешний мировой порядок.
Я опубликовал статью по многостороннему управлению СИИ-лабораториями. Долго размышлял о катастрофических рисках ИИ и способах их смягчения, как с технической, так и с управленческой и политической сторон.
Последние семь месяцев я возглавляю Международный научный доклад по безопасности продвинутых ИИ (далее просто «доклад»). В нём участвуют тридцать стран, ЕС и ООН, а также 70 международных экспертов. Цель доклада — собрать воедино состояние исследований Безопасности ИИ и показать всё разнообразие взглядов на риски и перспективы ИИ.
Сегодня, после года активного погружения в эти проблемы, я хотел бы заново рассмотреть аргументы о потенциальных катастрофических рисках, связанных с вероятными будущими ИИ-системами. Я поделюсь своим текущим взглядом на эту тему.
Многие риски связаны с гонкой нескольких частных компаний и других организаций за создание ИИ человеческого уровня (СИИ) и далее — Искусственного Суперинтеллекта (ИСИ). В докладе представлен широкий обзор рисков. Они включают проблемы с правами человека, угрозы приватности и демократии, вопросы авторского права, опасения о концентрации экономической и политической власти, а также возможные злоупотребления.
Мнения экспертов расходятся относительно вероятности различных исходов. Однако мы в целом согласны, что некоторые масштабные риски, такие как вымирание человечества, были бы настолько катастрофичны, что требуют особого внимания. Это необходимо хотя бы для того, чтобы убедиться, что их вероятность пренебрежимо мала. Другие риски, например серьезные угрозы демократии и правам человека, также заслуживают гораздо большего внимания, чем им уделяется сейчас.
Главный вывод из всех этих обсуждений и дебатов — простой и бесспорный факт: пока мы несемся в гонке за СИИ или ИСИ, никто сейчас не знает, как заставить их вести себя согласно морали. Более того, неясно, как даже обеспечить их поведение в соответствии с замыслом разработчиков и не допустить действий против людей. Это может быть трудно представить, но задумайтесь на секунду:
Сущности умнее людей и со своими собственными целями. Уверены ли мы, что они будут стремиться к нашему благополучию?
Можем ли мы коллективно так рискнуть, не будучи уверенными? Некоторые приводят аргументы, почему нам не стоит об этом беспокоиться. Я разберу их ниже. Но они не могут предоставить техническую методологию, демонстрирующую удовлетворительную степень контроля даже над современными передовыми ИИ-системами общего назначения. Что уж говорить о гарантиях или чётких и сильных научных обоснованиях, что методология исключит возможность ИСИ пойти против человечества. Я не утверждаю, что нельзя изобрести метод согласования и контроля ИИ, способный масштабироваться до ИСИ. Наоборот, я отстаиваю мнение, что научному сообществу и обществу в целом необходимо приложить мощное коллективное усилие именно для этого.
Более того, даже если способ контролировать ИСИ будет известен, у нас всё ещё не будет политических институтов, позволяющих увериться, что люди не будут злоупотреблять мощью СИИ или ИСИ, направлять её против других людей в катастрофических масштабах, использовать её для уничтожения демократии или учинения геополитического или экономического хаоса. Нам нужно убедиться, что никакой человек, корпорация или государство не сможет злоупотребить мощью СИИ в ущерб общему благу. Мы должны гарантировать, что корпорации не будут использовать СИИ для воздействия на свои государства, государства – для угнетения своих народов, а страны – для доминирования над другими странами. Одновременно нам надо обеспечить, чтобы мы избежали катастрофических происшествий и потери контроля над СИИ-системами в любой точке планеты.
Всё это вместе можно назвать задачей координации, то есть политикой ИИ. Если задача координации будет идеально и полностью решена, решение задачи согласования и контроля ИИ не будет такой абсолютной необходимостью. В таком случае мы могли бы «просто» исходить из принципа предосторожности и избегать проведения экспериментов с непренебрежимым шансом создания неконтролируемого СИИ.
Но, конечно, человечество - не единый разум, а миллиарды. Существует множество людей, корпораций и стран, у всех свои цели. Закономерности, вытекающие из личных интересов, психологических и культурных факторов, сейчас ведут нас в опасной гонке к мощным способностям ИИ. При этом у нас нет ни методологий, ни социальных институтов, позволяющих значительно снизить величайшие риски, такие как катастрофические злоупотребления и потеря контроля.
С оптимистичной точки зрения, я считаю вполне убедительными аргументы о том, что если будут решены и задача контроля ИИ, и задача координации, то скорее всего человечество сможет получить невероятную выгоду. Этот научный и технологический прогресс может принести пользу в медицине, экологии и улучшить экономические перспективы для большинства людей (в идеале, начиная с тех, кто в этом больше всего нуждается).
Сейчас мы несёмся в гонке к миру с сущностями умнее людей, преследующими свои собственные цели. У нас нет надёжного метода, гарантирующего совместимость этих целей с человеческими. Несмотря на это, обсуждая безопасность ИИ, я слышал много аргументов, призванных поддержать вывод «не надо беспокоиться».
Мой общий ответ на них таков: учитывая убедительные основания считать гонку к СИИ потенциально опасной и огромные ставки, нам необходимы очень сильные свидетельства, прежде чем заключать, что беспокоиться не о чем. Я вижу, что обычно эти аргументы даже близко не соответствуют такой планке.
Ниже я разберу некоторые из них и объясню, почему они не убедили меня в том, что мы можем игнорировать потенциальные катастрофические риски ИИ. Многие из аргументов за «не беспокоиться», которые мне встречались, – не настоящие твёрдые аргументы, а интуитивные заключения людей, уверенных в отсутствии опасности. Они не содержат убедительной цепочки рассуждений.
При отсутствии убедительных аргументов для отрицания важности безопасности ИИ и учёте ставок и неуверенности о будущем, рационально принимать решения исходя из принципов скромности. Следует признавать ограниченность наших знаний и отдавать приоритет осторожности. Но, как я вижу, сейчас это не так.
Да, катастрофические риски ИИ теперь всё больше обсуждают и не высмеивают. Но мы всё ещё не принимаем их с достаточным уровнем серьёзности. Многие, включая тех, кто принимает важные решения, сейчас осведомлены, что ИИ может нести катастрофические и даже экзистенциальные риски. Но насколько чётко они представляют, что это может значить? Насколько они готовы предпринимать экстраординарные шаги для смягчения этих рисков?
Меня беспокоит, что нынешняя траектория общественного и политического взаимодействия с рисками ИИ может, как сомнамбул, завести всех нас – даже наперегонки – в туман. За этим туманом - катастрофа, про которую многие знали, что она возможна, но не уделили должного внимания её предотвращению.
Тем, кто считает, что СИИ и ИСИ невозможны, или до них ещё века
Одно из возражений против серьёзного отношения к рискам СИИ/ИСИ - утверждение, что мы никогда (или только в далёком будущем) до них не дойдём. Часто такие люди говорят что-то вроде «ИИ просто предсказывает следующее слово», «ИИ никогда не будут обладать сознанием» или «ИИ не могут обладать настоящим интеллектом».
Я нахожу большую часть таких утверждений неубедительными, потому что они часто ошибочно объединяют несколько разных понятий в одно, упуская суть. Например, для СИИ и ИСИ (по крайней мере, при использовании большинства известных мне определений) сознание не обязательно. Неясно, имеет ли оно значение для потенциального экзистенциального риска СИИ. Куда важнее способности и намерения ИСИ-систем. Если они будут способны убить людей (это одна из многих способностей, которые можно составить или вывести из других навыков), и у них будет такая цель (а у нас уже есть ИИ-системы с целями), то это будет крайне опасно, если не будет способа это предотвратить или этому противодействовать.
Я также нахожу неубедительными утверждения вроде «ИИ не могут обладать настоящим интеллектом» или «ИИ просто предсказывают следующее слово». Соглашусь, если определить «настоящий» интеллект как «такой интеллект, как у людей», то у ИИ нет «настоящего» интеллекта: их методы обработки информации и рассуждений отличаются от наших. Но при разговоре о потенциальных катастрофических рисках ИИ это – бесполезное отвлечение. Важно то, чего ИИ может добиться, насколько он хорош в решении задач, и подобные вопросы.
Я думаю о «СИИ» и «ИСИ» именно так – как об уровнях способностей ИИ, на которых ИИ столь же хорош или превосходит людей-экспертов в исполнении по сути любой задачи (кроме тех, что требуют физических действий). То, как именно ИИ этого достигнет, для существования риска неважно.
Если посмотреть на способности ИИ-систем последних десятилетий, тренд на их усиление весьма ясен. На нынешнем уровне ИИ уже очень хорошо овладели языком и визуальными материалами, и способности исполнения самых разных когнитивных задач постоянно растут. См. «доклад» за подробными свидетельствами, включая расхождения во мнениях касательно нынешних способностей.
Наконец, нет никакой научной причины считать, что люди – обладатели высшего возможного интеллекта. Вообще-то, во многих специализированных когнитивных задачах компьютеры людей уже превзошли. Так что даже ИСИ вполне правдоподобен, хотя пока нельзя сказать, до какого уровня он может дойти. Если полагаться на науку, а не на личные убеждения, возможность СИИ и ИСИ исключить нельзя.
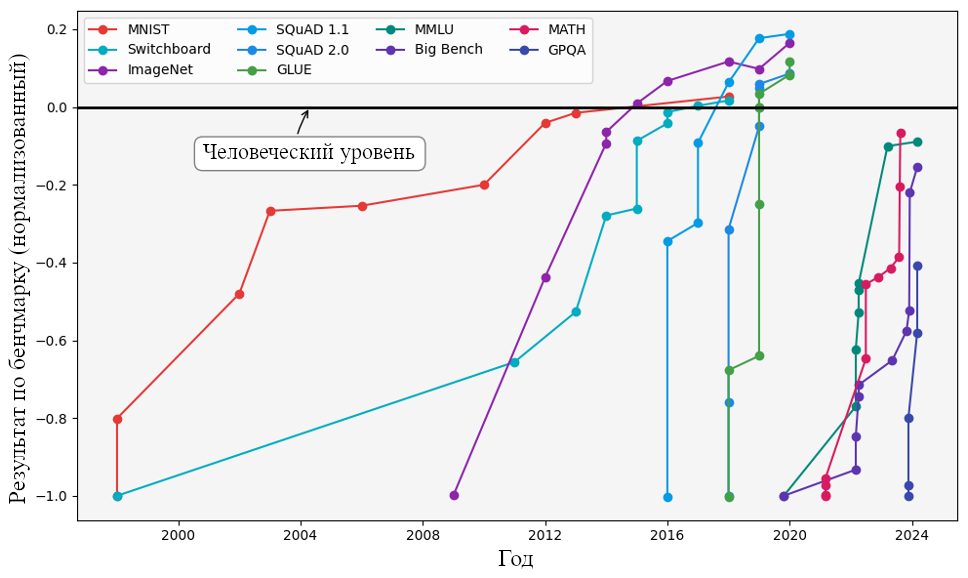
Результаты, которые показывают ИИ-модели по разным бенчмаркам с 2000 по 2024 год. Отображено компьютерное зрение (MNIST, ImageNet), распознавание речи (Switchboard), понимание естественного языка (SQuAD 1.1, MNLU, GLUE), общие оценки языковых моделей (MMLU, Big Bench, and GPQA), и математические рассуждения (MATH). К 2024 году многие модели превзошли человеческий уровень (отмеченный чёрной линией). Киела, Д., Траш, Т., Этаярадж, К., и Сингх, А. (2023) «Графики прогресса в ИИ»._
Тем, кто считает, что СИИ возможен, но до него ещё много десятилетий
Часто утверждают, что вводить регуляции против рисков СИИ пока рано, поскольку его ещё нет и неясно, каким он будет. Этот аргумент неубедителен по двум причинам.
Во-первых, нельзя исключать, что СИИ может возникнуть внезапно, в результате добавления какого-то нового приёма к существующим методам. Тренды развития ИИ по-прежнему указывают в сторону СИИ.
Во-вторых, и это ещё важнее, мы не знаем точных сроков появления СИИ. При этом разработка законов, введение регуляций и заключение соглашений могут занять годы или даже десятилетия. В наших условиях неуверенности, кто может не кривя душой сказать, что до СИИ точно ещё далеко?
Я согласен, что между мощнейшими ИИ-системами и человеческим интеллектом пока есть разрыв. Для его преодоления, вероятно, потребуются новые научные прорывы. Современные диалоговые системы, например, уступают людям в рассуждениях и планировании, часто демонстрируя непоследовательность.
Однако, у нас уже есть системы вроде AlphaGo, превосходящие людей в рассуждениях и планировании в ограниченных областях (например, правилах Го). Нужный прорыв мог бы объединить обширные знания и языковые навыки GPT-4 со способностью к планированию AlphaGo. К тому же, многие люди тоже не блещут логикой и могут выдавать нереалистичные ответы или действовать непоследовательно – известные слабости языковых моделей. Возможно, мы не так уж далеки от человеческого уровня способностей.
Важно отметить, что до появления ChatGPT многие исследователи ИИ, включая меня, не ожидали такого уровня возможностей в ближайшем будущем. Сейчас три самых цитируемых эксперта в области ИИ обеспокоены потенциальными последствиями. Учитывая такую неопределённость, стоит рассматривать разные сценарии: прогресс может сохранить нынешние темпы, а может и замедлиться, растянув путь к СИИ на десятилетия. В этой ситуации разумно проявить скромность и планировать, учитывая наше незнание.
В дискуссиях я часто замечаю обманчивый подход: люди рассуждают так, будто возможности ИИ навсегда останутся на текущем уровне. Нам необходимо учитывать вероятные сценарии будущего и траектории развития ИИ, чтобы подготовиться к потенциально опасным вариантам. Игнорировать тренды, подобные показанным на графике выше, было бы неразумно.
Тем, кто считает, что мы может достичь СИИ, но не ИСИ
Некоторые убеждены, что человеческий интеллект – это пик возможного, и ИИ-системы не смогут превзойти все наши способности. Хотя это нельзя строго опровергнуть, это крайне маловероятно. Я уже касался этого вопроса в начале поста. Джеффри Хинтон убедительно аргументировал это, сравнивая возможности аналоговых и цифровых вычислений.
Более того, для возникновения опасных сценариев с экзистенциальным риском не обязательно превосходить все человеческие способности. Достаточно создания ИИ-систем, превосходящих людей в исследованиях ИИ. Такой ИИ может быть запущен сотнями тысяч непрерывно работающих экземпляров, подобно тому, как GPT-4 обслуживает миллионы пользователей параллельно. Это мгновенно умножит усилия по исследованиям ИИ во много раз (возможно, сконцентрировав их в одной корпорации). Вероятно, это резко ускорит рост возможностей ИИ.
Когда мы, возможно, всего за несколько месяцев перейдём от СИИ к ИСИ, мы столкнемся со множеством неизвестных неизвестных. Ускорение исследований обеспечит более мощные ИИ, которые, в свою очередь, будут ещё сильнее ускорять исследования, создавая цикл положительной обратной связи.
Часто приводят аргумент, что робототехника значительно отстаёт от когнитивных способностей ИИ. Однако, учитывая текущее положение дел и тенденции развития, робототехника прогрессирует, и СИИ/ИСИ могли бы этот прогресс ускорить. Определённо стоит пристально следить за достижениями в этой области.
Можно представить сценарий, в котором стремящиеся к самосохранению ИИ-системы перестанут нуждаться в людях, поскольку смогут контролировать роботов для выполнения физической работы. Теоретически, у них может возникнуть мотивация полностью избавиться от человечества, чтобы исключить возможность своего отключения людьми.
Тем, кто считает, что СИИ и ИСИ будут к нам добры
Хотелось бы, чтобы эти ожидания оправдались, но исследования в области информатики и безопасности ИИ указывают в другом направлении. При отсутствии надёжных прогнозов, грамотное управление рисками требует принять меры предосторожности против вероятных негативных исходов.
ИИ с целью самосохранения стремился бы избежать отключения. Правдоподобная стратегия минимизации вероятности отключения – взять нас под контроль или устранить. Так ИИ мог бы гарантировать, что мы не поставим под угрозу его будущее.
Сущности (например, люди или страны) вынуждены искать взаимовыгодные решения только при относительном равенстве сил. Нет гарантий, что у нас будет такой паритет с ИСИ.
Откуда у ИИ может взяться сильное стремление к самосохранению? Это может быть намеренно заложено меньшинством людей, которые приветствовали бы превосходство ИИ, например, потому, что ценят интеллект превыше человечности. Но есть и технические аргументы (связанные с инструментальной конвергенцией или вмешательством в вознаграждение), в пользу того, что подобные цели могут возникнуть как побочный эффект даже самых безобидных целей, заданных людьми (см. «доклад» и цитируемые там источники, а также разнообразие взглядов на проблему потери контроля, отражающее уровень научной неопределённости в этом вопросе).
Было бы ошибкой полагать, что будущие ИИ-системы обязательно будут подобны нам, и у них будут те же базовые инстинкты. Мы не можем быть в этом уверены. То, как мы их сейчас создаём (например, как максимизаторы вознаграждения), указывает на совершенно иное. См. следующий пункт за дополнительными аргументами. Эти системы могут быть похожи на людей в одних аспектах, но сильно отличаться в других, и предсказать эти отличия сложно.
Стоит также учесть, что даже при конфликте между группами людей, если одна сторона обладает значительно превосходящими технологиями (как это было, например, при колонизации Америк европейцами, особенно в XIX веке), исход для более слабой группы может быть катастрофическим. Аналогично, наши перспективы в случае конфликта между ИСИ и человечеством выглядят довольно мрачными.
Тем, кто считает, что корпорации будут создавать только ИИ, которые будут хорошо себя вести, так что существующих законов достаточно
Почему бы инженерам из корпораций, занятых созданием будущих продвинутых ИИ-систем, не создавать безопасные ИИ? Разве корпорации сами не заинтересованы в безопасности своих ИИ? Проблема возникает, когда безопасность и максимизация прибыли или корпоративная культура («двигайся быстрее и ломай вещи») тянут в разные стороны.
Множество исторических свидетельств (вспомните компании по добыче ископаемого топлива и их влияние на климат, фармацевтические компании до введения регуляций, например, в случае с талидомидом) и экономические исследования показывают, что погоня за прибылью может сформировать поведение корпораций, противоречащее общественным интересам. При такой неопределенности рисков группе разработчиков легко убедить себя, что они найдут достаточно хорошее решение задачи безопасности ИИ (позже у меня будет пост с обсуждением психологических факторов).
Мы применяем законы, чтобы избежать конфликта интересов между глобальными рисками и корпоративными интересами или личным принятием желаемого за действительное. Однако команды корпоративных юристов могут найти в них лазейки. Искусственный сверхинтеллект (ИСИ), вероятно превосходящий лучшую команду юристов, наверняка обнаружит пробелы и в законах, и в инструкциях, призванных обеспечить безопасное поведение ИИ.
Составление контракта, который точно ограничивает поведение агента (человека, корпорации или ИИ) в интересах другого агента, остается нерешенной в общем случае задачей. Обратите внимание, как мы постоянно вносим поправки в законы в ответ на обнаруженные корпорациями лазейки. Неясно, сможем ли мы делать это с той же скоростью, с которой их будет находить ИСИ.
Проблема, похоже, в нашей неспособности предоставить ИИ полную формальную спецификацию неприемлемого поведения. Вместо этого мы можем дать спецификацию безопасности S, вероятно, на естественном языке. Если у ИИ есть основная цель G с ограничением соблюдения S, то при легкости достижения G без нарушения всех интерпретаций S всё будет работать как надо. Но если совместить одно с другим сложно, потребуется оптимизация (как команда юристов ищет способ максимизировать прибыль, соблюдая букву закона). Такая оптимизация, вероятно, найдет лазейки или интерпретации, позволяющие соответствовать букве, но не духу законов и инструкций.
Примеры таких лазеек уже описаны в литературе по безопасности ИИ. Они включают:
- Вмешательства в систему вознаграждения (контроль механизма вознаграждения создает неявную цель самосохранения)
- Разнообразные инструментальные цели (для достижения основной, казалось бы безобидной цели, ИИ стремится к потенциально полезным подцелям: самосохранению, контролю и влиянию в своем окружении, в том числе через убеждение, обман и взлом)
Уже наблюдались признаки таких склонностей. Ситуацию усложняет то, что инженеры не проектируют поведение ИИ напрямую, а только то, как ИИ обучается. В глубинном обучении результат – сложная и непрозрачная структура. Это крайне затрудняет выявление и исключение нежелательных намерений и обманчивости.
Для ссылок на исследования безопасности ИИ, нацеленные на смягчение этих рисков, см. «доклад». Пока эти исследования не смогли решить проблему.
Тем, кто считает, что нам следует ускорять исследования способностей ИИ и не задерживать выгоду от СИИ
Главный аргумент сторонников ускорения: будущий прогресс ИИ, вероятно, принесёт человечеству невероятную пользу, поэтому замедлять исследования способностей ИИ – значит отказываться от небывалого экономического и социального роста. Это возможно, но рациональное принятие решений требует взвешенного рассмотрения всех «за» и «против».
Представим, что мы получим медицинские прорывы, которые быстро удвоят нашу ожидаемую продолжительность жизни, но примем риск того, что все погибнут или потеряют свободу. В этом случае ставка ускорителей не особо привлекательна. Может, стоит немного притормозить, найти лекарство от рака чуть позже, но мудро вложиться в исследования, необходимые для контроля рисков, пока мы получаем глобальную выгоду?
Аргументы за ускорение часто исходят от крайне богатых людей и технокорпоративных лобби с личной финансовой заинтересованностью в максимальной краткосрочной выгоде. С их точки зрения, риски ИИ – это экономическая экстерналия, ложащаяся на всех сразу.
Корпорации принимают риски, потому что им выгодно игнорировать вред для общества – вполне обычная ситуация. Вспомним риски для климата от ископаемого топлива или опасность ужасных побочных эффектов от препаратов вроде талидомида. Но с точки зрения обычных людей и общества в целом, при учёте всех рисков и потенциальной выгоды, аккуратный и осторожный подход к СИИ явно лучше.
Возможен путь, при котором мы достаточно вложимся в безопасность ИИ, регуляции и соглашения для контроля рисков злоупотреблений и потери контроля, и одновременно реализуем выгоду ИИ. Это совместный вывод саммита по безопасности ИИ в Великобритании в 2023 году (30 стран-участниц), последовавшего в 2024 году саммита в Сеуле и Хиросимских принципов G7 об ИИ. С этим согласны и многие другие международные декларации и законотворческие предложения в ООН, ЕС и других организациях.
Тем, кто обеспокоен, что разговоры о катастрофических рисках навредят усилиям по смягчению краткосрочных проблем с ИИ, связанных с правами человека
Бывало такое, что меня просили перестать говорить о катастрофических рисках ИИ (как о злоупотреблениях, так и о потере контроля). Аргумент в том, что это обсуждение отвлечет внимание от хорошо обоснованного вреда правам человека, который ИИ уже наносит.
В демократии мы обсуждаем множество проблем параллельно. Было бы странно сказать: «Прекрати говорить об изменении климата» из страха, что это навредит обсуждению проблемы детского труда. Или просить не говорить о необходимости смягчать долгосрочные эффекты изменения климата, потому что это помешает обсуждению краткосрочной адаптации к нему.
Если бы мои оппоненты приводили сильные аргументы о невозможности катастрофических рисков ИИ, я бы понял их нежелание вносить в общественный дискурс лишний шум. Но на самом деле:
1. Есть правдоподобные аргументы, почему суперинтеллектуальный ИИ может обладать целью самосохранения (простейший – её ему дадут люди).
2. Ставки (если опасность реализуется) столь высоки, что это требует нашего внимания даже при низкой вероятности.
3. Мы не знаем, сколько времени осталось до СИИ. Уважаемые люди из передовых ИИ-лабораторий утверждают, что это может быть всего несколько лет. Риски могут оказаться не такими уж долгосрочными, а законотворчество, регуляции и соглашения могут занять много времени.
Наше будущее благополучие и способность контролировать будущее (иными словами, наша свобода) -– это права человека, которые надо защищать. К тому же, интересы тех, кто обеспокоен краткосрочными и долгосрочными рисками, должны сходиться. Обе группы хотят государственного вмешательства для защиты общества, регуляции и общественного надзора за ИИ.
Большинство недавних законотворческих предложений об ИИ затрагивали краткосрочные и долгосрочные риски в равной степени. На практике те, кто противостоит регуляциям – это часто люди с финансовыми или личными интересами в слепом ускорении гонки к СИИ. Во многих странах технические лобби успешно помешали или ослабили попытки ввода регуляций. Поэтому для тех, кто в них заинтересован, рационально было бы объединиться.
К сожалению, эти внутренние разногласия между теми, кто хочет защитить общество, сильно снижают шансы на реализацию общественного надзора и приоритизацию общего блага в разработке и развертывании ИИ.
Тем, кто обеспокоен холодной войной между США и Китаем
Китай – вторая ИИ-сверхдержава после США. В западных демократиях распространено искреннее беспокойство по поводу геополитического конфликта между Китаем и США (и их союзниками). Некоторые считают, что Китай может использовать прогресс в ИИ, особенно при приближении к СИИ и ИСИ, как мощное оружие. Это дало бы Китаю преимущество как в экономическом, так и в военном плане, особенно если Запад замедлит свой прогресс к СИИ ради безопасности.
Стоит честно признать: китайцы тоже боятся, что США могут использовать прогресс в ИИ против них. Это мотивирует Китай ускорять исследования способностей ИИ. Эта геополитическая конкуренция особенно беспокоит тех, кто убежден, что демократические институты лучше автократических режимов защищают права человека (см. [Всеобщую декларацию прав человека]((https://www.un.org/en/about-us/universal-declaration-of-human-rights), которую Китай подписал, но которая, к сожалению, ни к чему не обязывает).
Мы уже видим, как современные ИИ используются для воздействия на общественное мнение (например, с помощью дипфейков) и подрыва демократических институтов через распространение недоверия и невежества. Автократические государства уже применяют ИИ и социальные медиа для усиления внутренней пропаганды и контроля за недовольством (включая отслеживание в интернете и визуальную слежку с распознаванием лиц). Есть риск, что ИИ, особенно СИИ, может помогать автократам оставаться у власти и расширять влияние, вплоть до создания автократического мирового правительства.
Возможность, что будущий прогресс в ИИ может дать оружие первого удара (в том числе в кибервойне), мотивирует многих на Западе ускорять развитие способностей ИИ. Они отвергают идею замедления ради лучшей безопасности из страха, что это позволит Китаю опередить США в области ИИ.
Но если мы будем игнорировать безопасность ИИ и сосредоточимся только на способностях, как избежать экзистенциального риска потери контроля над СИИ? Если человечество проиграет из-за неконтролируемого ИСИ, неважно, какую политическую систему вы предпочитаете. Проиграют все. Когда дело касается экзистенциальных рисков, мы все в одной лодке.
Надеюсь, это мотивирует лидеров обеих сторон искать способы вкладываться и в безопасность ИИ. Мы могли бы сотрудничать в исследованиях, улучшающих безопасность, особенно если они не повышают способности. Никто не хочет, чтобы другая сторона в своих исследованиях СИИ совершила глобальную катастрофическую ошибку – мятежный ИСИ не станет уважать ничьих границ.
Что касается вложений, исследования способностей и безопасности не взаимоисключающи, если начать сейчас. У нас достаточно ресурсов для обоих направлений, особенно при правильно выстроенных стимулах. Но значительные вложения в безопасность необходимы. Надо убедиться, что вопросы безопасности решены до достижения СИИ, когда бы это ни произошло. Сейчас мы не на этом пути.
Меня беспокоит то, что если безопасные методологии в области ИИ не будут найдены вовремя, легче представимый риск чужой гегемонии вытеснит из внимания экзистенциальный риск потери контроля. Последний могут счесть умозрительным, в отличие от первого, подпитываемого веками вооруженных конфликтов.
Тем, кто считает, что международные соглашения не сработают
Заключать международные соглашения действительно сложно. Однако история показывает, что они возможны. Или, по крайней мере, она может помочь нам понять, почему они иногда терпят неудачу (особенно интересна история плана Баруха, когда США собирались поделиться атомными разработками с СССР). Даже без полной уверенности в успехе, они представляют важное направление, которое стоит попробовать для предотвращения глобальных катастрофических исходов.
Два необходимых условия успеха – это
общая заинтересованность в соглашении (имеется, все хотят избежать вымирания человечества) и возможность проверки соблюдения. Для первого нужно, чтобы государства действительно понимали риски. Поэтому необходимо больше исследований для их лучшего анализа. Здесь полезны компиляции знаний о безопасности ИИ вроде «доклада». Второе условие в случае ИИ представляет особую проблему. ИИ – это в основном софт, его легко модифицировать и скрывать. Возникающее из-за этого недоверие мешает заключить соглашение, предотвращающее опасные риски.
Однако ведутся обсуждения о возможности механизмов управления на уровне «железа». При их реализации высокопроизводительные чипы, позволяющие обучение СИИ, нельзя было бы спрятать. На них можно было бы выполнять только код, одобренный совместно установленной управляющей организацией. Цепочка поставок высокопроизводительных чипов для ИИ сейчас состоит из очень малого числа участников. Это даёт государствам возможность на неё повлиять. См. также проект из этого меморандума.
Можно представить сценарии, когда управление через «железо» не сработает. Например, если будут открыты способы на много порядков снизить вычислительную стоимость обучения ИИ. Это возможно, но не гарантировано. Вообще, все предложенные способы снижения катастрофического риска ИИ не дают гарантии по отдельности. Нам нужна «глубокая защита» – наслоение многих методов для защиты от различных опасных сценариев.
Важно понимать, что управления через «железо» будет недостаточно, если код и веса СИИ-систем не будут надёжно защищены. Использование и файн-тюнинг таких моделей намного дешевле их обучения и не требуют столь высокопроизводительных чипов. В этой области почти все (за пределами ведущих СИИ-лабораторий, у которых нет сильной культуры безопасности) согласны: при приближении к СИИ необходим быстрый переход к очень надёжным практикам информационной безопасности.
Наконец, соглашения касаются не только США и Китая. В долгосрочной перспективе безопасность от катастрофических злоупотреблений и потери контроля потребует сотрудничества всех стран. Но с чего странам Глобального Юга подписывать такое соглашение? Очевидный для меня ответ: в него должно быть включено обязательство, что ИИ не будет использоваться как инструмент доминирования, в том числе экономического. Научная, технологическая и экономическая выгода от ИИ должна распределяться глобально.
Тем, кто считает, что джинн уже выпущен из бутылки, и следует это признать и обойтись без регуляций
Возможно, джинн действительно выпущен из бутылки: большинство научных принципов, необходимых для СИИ, уже могут быть открыты. Много денег вложено с этим допущением. Но даже если это так, отсюда не следует, что нам стоит позволить силам рыночной и геополитической конкуренции полностью определять наш курс.
У нас всё ещё есть индивидуальная и коллективная возможность свернуть к более безопасному и демократичному миру. Также неверен аргумент, что регуляция обязательно провалится. Даже если регулировать ИИ будет непросто, это не значит, что не надо направлять усилия на проектирование новых институтов для защиты прав человека, демократии и будущего человечества. Это, конечно, может потребовать некоторых социальных инноваций.
Даже просто снижение вероятности катастрофы уже было бы полезно. Не обязательно ждать идеального решения, чтобы начать двигаться в нужную сторону.
Наприме, чтобы справиться с проблемой сложности выстраивания новой технической и социальной инфраструктуры, регуляторы могут полагаться на частные некоммерческие организации. Эти организации могут конкурировать друг с другом за проектирование наиболее эффективных оценок способностей и других инструментов безопасности.
Чтобы эффективно совладать с быстрым темпом перемен и неизвестными будущих ИИ-систем, регуляции должны обладать определённой гибкостью. У нас есть примеры законотворчества, основанного на определённых принципах и дающего регулирующим организациям достаточно свободы для адаптации к изменяющимся обстоятельствам и рискам (например, FAA в США).
Чтобы противостоять конфликту интересов (между общим благом и максимизацией прибыли) внутри корпоративных ИИ-лабораторий, государство может обязать эти компании включать в советы директоров разных заинтересованных лиц. Это обеспечит представление должного диапазона взглядов и интересов, включая представителей гражданского общества, независимых учёных и международного сообщества.
Тем, кто считает, что решение – открытый исходный код и веса СИИ
Открытые наука и код в прошлом многое нам дали и в целом продолжают приносить пользу. Однако всегда нужно взвешивать плюсы и минусы решений вроде «выложить в общий доступ код и параметры обученной ИИ-системы». Особенно когда способности ИИ достигнут человеческого или даже более высокого уровня.
Пока нынешние системы недостаточно мощны, чтобы быть катастрофически опасными в чужих руках или выйти из-под контроля. Поэтому выкладывание ИИ-систем в общий доступ может быть полезно – это помогает учёным в исследованиях безопасности ИИ. Но кто должен решать, где провести грань и как взвесить плюсы и минусы? Директора компаний или демократически избранные правительства? Если вы верите в демократию, ответ очевиден.
Это сложный (и болезненный для меня) вопрос: всегда ли свободное распространение информации – это хорошо? Представьте, у нас есть последовательность ДНК очень опасного вируса. Стоит ли её выкладывать в открытый доступ? Если в этом случае ответ для вас очевиден, тщательно подумайте о случае с алгоритмами и параметрами СИИ.
Недавно появился новый тревожный сигнал: исследование EPFL показало превосходящие человеческие способности к убеждению у GPT-4. Для этого ей достаточно дать страницу в Facebook человека, которого нужно убедить. Что, если такие ИИ-системы будут настроены на миллионах взаимодействий, обучающих ИИ тому, как эффективно переубеждать нас в чём угодно? Успешность демагогических приёмов ясно показывает уязвимость людей к подобным манипуляциям.
Что касается экзистенциальных рисков, некоторые утверждают: если у всех будут собственные СИИ, то «хорошие ИИ» победят «плохие ИИ», потому что хороших людей больше. У этого аргумента много слабых мест.
Во-первых, мы не уверены, что доброй воли владельца СИИ хватит, чтобы гарантировать моральное поведение самого СИИ (см. выше об инструментальных целях).
Во-вторых, нет гарантии, что меньшинство мятежных ИИ будет побеждено большинством «хороших» ИИ, и что мы вовремя найдём подходящие контрмеры (хотя мы, конечно, должны попытаться). Это зависит от баланса атаки и защиты. Подумайте о смертоносных первых ударах. Мятежный ИИ может выбрать вектор атаки, дающий атакующему мощное преимущество. Очевидный кандидат – биологическое оружие. Его можно скрытно разработать и выпустить разом, и оно будет сеять хаос и смерть экспоненциально, пока защищающаяся сторона будет искать лекарство.
Основная причина, почему биологическое оружие не применяется в человеческих войнах – атакующим сложно быть уверенными, что оно не обернётся против них самих. Мы все люди, и даже если у них есть лекарство, патоген после выпуска будет мутировать, и все гарантии могут перестать работать. Но это не проблема для мятежного ИИ, намеренного уничтожить человечество.
Теперь о злоупотреблениях ИИ-системами в открытом доступе. Действительно, злоупотребить можно и закрытой системой, например, найдя уязвимость. Однако:
а) Найти атаку для системы в открытом доступе гораздо проще.
б) В отличие от закрытых систем, после выкладывания в открытый доступ вы уже не можете исправить найденные уязвимости.
Важно: это касается и дополнительного обучения систем в открытом доступе. Оно может раскрыть опасные способности, допускающие потерю контроля.
Аргумент в пользу открытого доступа: больше людей смогут пользоваться преимуществами ИИ. Это верно, но для дополнительного обучения систем всё ещё требуются технические навыки. К тому же, экспоненциально растущие вычислительные затраты на обучение передовых ИИ-систем означают, что, скорее всего, оно будет доступно только очень небольшому числу организаций. Это сделает такие организации чрезвычайно влиятельными.
Я бы предпочёл как-то децентрализовать эту власть, не увеличивая при этом риски злоупотребления и потери контроля. От организаций, создающих эти системы, можно требовать особой прозрачности (по крайней мере, прозрачности способностей, не обязательно методов их получения), общественного надзора и участия разных заинтересованных сторон в управлении. Это поможет снизить риски злоупотребления мощью СИИ и риски потери контроля из-за недостаточных мер безопасности.
Вдобавок можно давать контролируемый доступ к коду доверенным исследователям, применяя при этом технические методы, не позволяющие им его копировать. Это откроет возможность присмотра и уменьшит риски злоупотреблений.
Тем, кто считает, что беспокойство о СИИ сродни Пари Паскаля
Пари Паскаля – рассуждение о том, что при возможности бесконечных потерь (ад или рай) в случае ошибочного решения не верить в Бога, нам следует действовать, исходя из убеждения, что Бог (кстати, именно христианский) существует. Аргумент против принятия мер по поводу катастрофических рисков ИИ проводит аналогию с Пари Паскаля из-за огромных рисков, потенциально даже бесконечных, если так рассматривать вымирание человечества.
Согласно этому аргументу, алармисты обосновывают своё беспокойство тем, что в пределе бесконечных потерь при вымирании мы должны действовать так, будто риски реальны, даже при практически нулевых свидетельствах в пользу вымирания или его вероятности. Это потому, что ожидаемый риск можно измерить, умножив вероятность события на потери, если оно произойдёт. Давайте рассмотрим, почему этот аргумент не работает.
Главная причина: мы имеем дело не с крохотными вероятностями. Согласно опросу от декабря 2023 года, медианный исследователь ИИ (не безопасности ИИ) оценивал вероятность вреда от ИИ уровня вымирания в 5%. Вероятность в 5% – не территория Пари Паскаля.
Есть серьёзные и подкреплённые научной литературой аргументы (см. «доклад» и пункты выше) в пользу того, что катастрофические риски очень продвинутых ИИ вполне реальны. Особенно при приближении или обгоне человеческого уровня во многих областях.
Нам не нужно принимать потери за бесконечные: возможных очень плохих сценариев по пути к СИИ и дальше много (опять же, см. «доклад»). У нас есть вполне ощутимые свидетельства в пользу ИИ-катастроф и значимая вероятность не бесконечных, но всё же неприемлемых потерь.
Это обычная ситуация для принятия решений. Рациональность требует от нас обратить внимание на эти риски, попытаться их понять и снизить.