Разбор аргументов против того, чтобы принимать безопасность ИИ всёрьёз
Год с небольшим назад я публично присоединился к многочисленным коллегам. Мы предупредили общественность об опасностях, связанных с беспрецедентными способностями мощных ИИ-систем. Спустя несколько месяцев я написал пост «ЧаВо по катастрофическим рискам ИИ». Он логически следовал за моим постом о мятежных ИИ, где я начал обсуждать, почему к Безопасности ИИ нужно относиться серьёзно.
С тех пор я участвовал во многих дебатах, в том числе с моим другом Яном ЛеКуном. Его взгляды на эти проблемы сильно отличаются от моих. Я многое узнал о Безопасности ИИ, о разнообразии мнений по этому вопросу, о взглядах на регуляции и о мощных лобби против них.
Проблему обсуждают так активно из-за того, что ставки огромны. Согласно некоторым оценкам, потенциальная ценность на кону составляет квадриллионы долларов. Не говоря уже о перспективах политической власти, способной значительно изменить нынешний мировой порядок.
Я опубликовал статью по многостороннему управлению СИИ-лабораториями. Долго размышлял о катастрофических рисках ИИ и способах их смягчения, как с технической, так и с управленческой и политической сторон.
Последние семь месяцев я возглавляю Международный научный доклад по безопасности продвинутых ИИ (далее просто «доклад»). В нём участвуют тридцать стран, ЕС и ООН, а также 70 международных экспертов. Цель доклада — собрать воедино состояние исследований Безопасности ИИ и показать всё разнообразие взглядов на риски и перспективы ИИ.
Сегодня, после года активного погружения в эти проблемы, я хотел бы заново рассмотреть аргументы о потенциальных катастрофических рисках, связанных с вероятными будущими ИИ-системами. Я поделюсь своим текущим взглядом на эту тему.
Многие риски связаны с гонкой нескольких частных компаний и других организаций за создание ИИ человеческого уровня (СИИ) и далее — Искусственного Суперинтеллекта (ИСИ). В докладе представлен широкий обзор рисков. Они включают проблемы с правами человека, угрозы приватности и демократии, вопросы авторского права, опасения о концентрации экономической и политической власти, а также возможные злоупотребления.
Мнения экспертов расходятся относительно вероятности различных исходов. Однако мы в целом согласны, что некоторые масштабные риски, такие как вымирание человечества, были бы настолько катастрофичны, что требуют особого внимания. Это необходимо хотя бы для того, чтобы убедиться, что их вероятность пренебрежимо мала. Другие риски, например серьезные угрозы демократии и правам человека, также заслуживают гораздо большего внимания, чем им уделяется сейчас.
Главный вывод из всех этих обсуждений и дебатов — простой и бесспорный факт: пока мы несемся в гонке за СИИ или ИСИ, никто сейчас не знает, как заставить их вести себя согласно морали. Более того, неясно, как даже обеспечить их поведение в соответствии с замыслом разработчиков и не допустить действий против людей. Это может быть трудно представить, но задумайтесь на секунду:
Сущности умнее людей и со своими собственными целями. Уверены ли мы, что они будут стремиться к нашему благополучию?
Можем ли мы коллективно так рискнуть, не будучи уверенными? Некоторые приводят аргументы, почему нам не стоит об этом беспокоиться. Я разберу их ниже. Но они не могут предоставить техническую методологию, демонстрирующую удовлетворительную степень контроля даже над современными передовыми ИИ-системами общего назначения. Что уж говорить о гарантиях или чётких и сильных научных обоснованиях, что методология исключит возможность ИСИ пойти против человечества. Я не утверждаю, что нельзя изобрести метод согласования и контроля ИИ, способный масштабироваться до ИСИ. Наоборот, я отстаиваю мнение, что научному сообществу и обществу в целом необходимо приложить мощное коллективное усилие именно для этого.
Более того, даже если способ контролировать ИСИ будет известен, у нас всё ещё не будет политических институтов, позволяющих увериться, что люди не будут злоупотреблять мощью СИИ или ИСИ, направлять её против других людей в катастрофических масштабах, использовать её для уничтожения демократии или учинения геополитического или экономического хаоса. Нам нужно убедиться, что никакой человек, корпорация или государство не сможет злоупотребить мощью СИИ в ущерб общему благу. Мы должны гарантировать, что корпорации не будут использовать СИИ для воздействия на свои государства, государства – для угнетения своих народов, а страны – для доминирования над другими странами. Одновременно нам надо обеспечить, чтобы мы избежали катастрофических происшествий и потери контроля над СИИ-системами в любой точке планеты.
Всё это вместе можно назвать задачей координации, то есть политикой ИИ. Если задача координации будет идеально и полностью решена, решение задачи согласования и контроля ИИ не будет такой абсолютной необходимостью. В таком случае мы могли бы «просто» исходить из принципа предосторожности и избегать проведения экспериментов с непренебрежимым шансом создания неконтролируемого СИИ.
Но, конечно, человечество - не единый разум, а миллиарды. Существует множество людей, корпораций и стран, у всех свои цели. Закономерности, вытекающие из личных интересов, психологических и культурных факторов, сейчас ведут нас в опасной гонке к мощным способностям ИИ. При этом у нас нет ни методологий, ни социальных институтов, позволяющих значительно снизить величайшие риски, такие как катастрофические злоупотребления и потеря контроля.
С оптимистичной точки зрения, я считаю вполне убедительными аргументы о том, что если будут решены и задача контроля ИИ, и задача координации, то скорее всего человечество сможет получить невероятную выгоду. Этот научный и технологический прогресс может принести пользу в медицине, экологии и улучшить экономические перспективы для большинства людей (в идеале, начиная с тех, кто в этом больше всего нуждается).
Сейчас мы несёмся в гонке к миру с сущностями умнее людей, преследующими свои собственные цели. У нас нет надёжного метода, гарантирующего совместимость этих целей с человеческими. Несмотря на это, обсуждая безопасность ИИ, я слышал много аргументов, призванных поддержать вывод «не надо беспокоиться».
Мой общий ответ на них таков: учитывая убедительные основания считать гонку к СИИ потенциально опасной и огромные ставки, нам необходимы очень сильные свидетельства, прежде чем заключать, что беспокоиться не о чем. Я вижу, что обычно эти аргументы даже близко не соответствуют такой планке.
Ниже я разберу некоторые из них и объясню, почему они не убедили меня в том, что мы можем игнорировать потенциальные катастрофические риски ИИ. Многие из аргументов за «не беспокоиться», которые мне встречались, – не настоящие твёрдые аргументы, а интуитивные заключения людей, уверенных в отсутствии опасности. Они не содержат убедительной цепочки рассуждений.
При отсутствии убедительных аргументов для отрицания важности безопасности ИИ и учёте ставок и неуверенности о будущем, рационально принимать решения исходя из принципов скромности. Следует признавать ограниченность наших знаний и отдавать приоритет осторожности. Но, как я вижу, сейчас это не так.
Да, катастрофические риски ИИ теперь всё больше обсуждают и не высмеивают. Но мы всё ещё не принимаем их с достаточным уровнем серьёзности. Многие, включая тех, кто принимает важные решения, сейчас осведомлены, что ИИ может нести катастрофические и даже экзистенциальные риски. Но насколько чётко они представляют, что это может значить? Насколько они готовы предпринимать экстраординарные шаги для смягчения этих рисков?
Меня беспокоит, что нынешняя траектория общественного и политического взаимодействия с рисками ИИ может, как сомнамбул, завести всех нас – даже наперегонки – в туман. За этим туманом - катастрофа, про которую многие знали, что она возможна, но не уделили должного внимания её предотвращению.
Тем, кто считает, что СИИ и ИСИ невозможны, или до них ещё века
Одно из возражений против серьёзного отношения к рискам СИИ/ИСИ - утверждение, что мы никогда (или только в далёком будущем) до них не дойдём. Часто такие люди говорят что-то вроде «ИИ просто предсказывает следующее слово», «ИИ никогда не будут обладать сознанием» или «ИИ не могут обладать настоящим интеллектом».
Я нахожу большую часть таких утверждений неубедительными, потому что они часто ошибочно объединяют несколько разных понятий в одно, упуская суть. Например, для СИИ и ИСИ (по крайней мере, при использовании большинства известных мне определений) сознание не обязательно. Неясно, имеет ли оно значение для потенциального экзистенциального риска СИИ. Куда важнее способности и намерения ИСИ-систем. Если они будут способны убить людей (это одна из многих способностей, которые можно составить или вывести из других навыков), и у них будет такая цель (а у нас уже есть ИИ-системы с целями), то это будет крайне опасно, если не будет способа это предотвратить или этому противодействовать.
Я также нахожу неубедительными утверждения вроде «ИИ не могут обладать настоящим интеллектом» или «ИИ просто предсказывают следующее слово». Соглашусь, если определить «настоящий» интеллект как «такой интеллект, как у людей», то у ИИ нет «настоящего» интеллекта: их методы обработки информации и рассуждений отличаются от наших. Но при разговоре о потенциальных катастрофических рисках ИИ это – бесполезное отвлечение. Важно то, чего ИИ может добиться, насколько он хорош в решении задач, и подобные вопросы.
Я думаю о «СИИ» и «ИСИ» именно так – как об уровнях способностей ИИ, на которых ИИ столь же хорош или превосходит людей-экспертов в исполнении по сути любой задачи (кроме тех, что требуют физических действий). То, как именно ИИ этого достигнет, для существования риска неважно.
Если посмотреть на способности ИИ-систем последних десятилетий, тренд на их усиление весьма ясен. На нынешнем уровне ИИ уже очень хорошо овладели языком и визуальными материалами, и способности исполнения самых разных когнитивных задач постоянно растут. См. «доклад» за подробными свидетельствами, включая расхождения во мнениях касательно нынешних способностей.
Наконец, нет никакой научной причины считать, что люди – обладатели высшего возможного интеллекта. Вообще-то, во многих специализированных когнитивных задачах компьютеры людей уже превзошли. Так что даже ИСИ вполне правдоподобен, хотя пока нельзя сказать, до какого уровня он может дойти. Если полагаться на науку, а не на личные убеждения, возможность СИИ и ИСИ исключить нельзя.
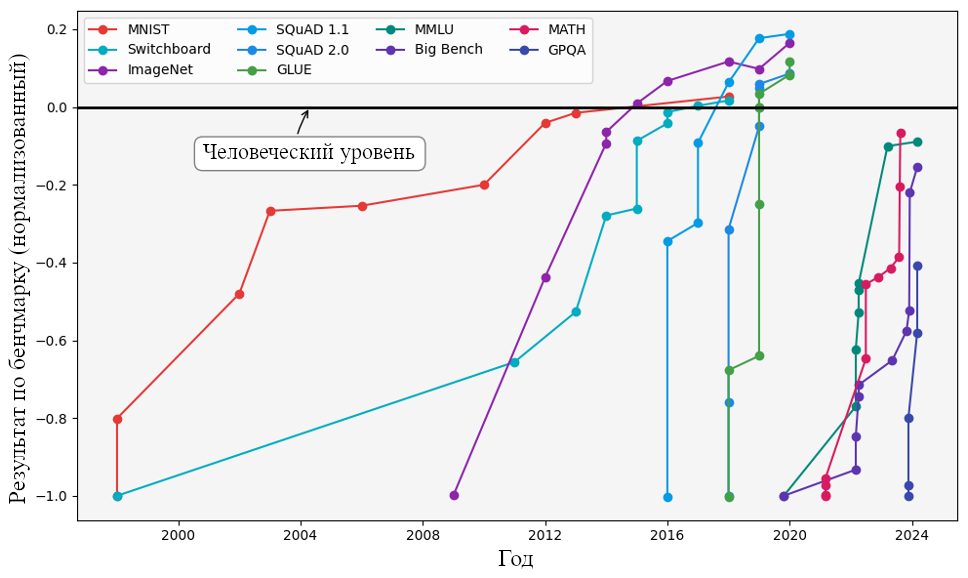
Результаты, которые показывают ИИ-модели по разным бенчмаркам с 2000 по 2024 год. Отображено компьютерное зрение (MNIST, ImageNet), распознавание речи (Switchboard), понимание естественного языка (SQuAD 1.1, MNLU, GLUE), общие оценки языковых моделей (MMLU, Big Bench, and GPQA), и математические рассуждения (MATH). К 2024 году многие модели превзошли человеческий уровень (отмеченный чёрной линией). Киела, Д., Траш, Т., Этаярадж, К., и Сингх, А. (2023) «Графики прогресса в ИИ»._
Тем, кто считает, что СИИ возможен, но до него ещё много десятилетий
Часто утверждают, что вводить регуляции против рисков СИИ пока рано, поскольку его ещё нет и неясно, каким он будет. Этот аргумент неубедителен по двум причинам.
Во-первых, нельзя исключать, что СИИ может возникнуть внезапно, в результате добавления какого-то нового приёма к существующим методам. Тренды развития ИИ по-прежнему указывают в сторону СИИ.
Во-вторых, и это ещё важнее, мы не знаем точных сроков появления СИИ. При этом разработка законов, введение регуляций и заключение соглашений могут занять годы или даже десятилетия. В наших условиях неуверенности, кто может не кривя душой сказать, что до СИИ точно ещё далеко?
Я согласен, что между мощнейшими ИИ-системами и человеческим интеллектом пока есть разрыв. Для его преодоления, вероятно, потребуются новые научные прорывы. Современные диалоговые системы, например, уступают людям в рассуждениях и планировании, часто демонстрируя непоследовательность.
Однако, у нас уже есть системы вроде AlphaGo, превосходящие людей в рассуждениях и планировании в ограниченных областях (например, правилах Го). Нужный прорыв мог бы объединить обширные знания и языковые навыки GPT-4 со способностью к планированию AlphaGo. К тому же, многие люди тоже не блещут логикой и могут выдавать нереалистичные ответы или действовать непоследовательно – известные слабости языковых моделей. Возможно, мы не так уж далеки от человеческого уровня способностей.
Важно отметить, что до появления ChatGPT многие исследователи ИИ, включая меня, не ожидали такого уровня возможностей в ближайшем будущем. Сейчас три самых цитируемых эксперта в области ИИ обеспокоены потенциальными последствиями. Учитывая такую неопределённость, стоит рассматривать разные сценарии: прогресс может сохранить нынешние темпы, а может и замедлиться, растянув путь к СИИ на десятилетия. В этой ситуации разумно проявить скромность и планировать, учитывая наше незнание.
В дискуссиях я часто замечаю обманчивый подход: люди рассуждают так, будто возможности ИИ навсегда останутся на текущем уровне. Нам необходимо учитывать вероятные сценарии будущего и траектории развития ИИ, чтобы подготовиться к потенциально опасным вариантам. Игнорировать тренды, подобные показанным на графике выше, было бы неразумно.
Тем, кто считает, что мы может достичь СИИ, но не ИСИ
Некоторые убеждены, что человеческий интеллект – это пик возможного, и ИИ-системы не смогут превзойти все наши способности. Хотя это нельзя строго опровергнуть, это крайне маловероятно. Я уже касался этого вопроса в начале поста. Джеффри Хинтон убедительно аргументировал это, сравнивая возможности аналоговых и цифровых вычислений.
Более того, для возникновения опасных сценариев с экзистенциальным риском не обязательно превосходить все человеческие способности. Достаточно создания ИИ-систем, превосходящих людей в исследованиях ИИ. Такой ИИ может быть запущен сотнями тысяч непрерывно работающих экземпляров, подобно тому, как GPT-4 обслуживает миллионы пользователей параллельно. Это мгновенно умножит усилия по исследованиям ИИ во много раз (возможно, сконцентрировав их в одной корпорации). Вероятно, это резко ускорит рост возможностей ИИ.
Когда мы, возможно, всего за несколько месяцев перейдём от СИИ к ИСИ, мы столкнемся со множеством неизвестных неизвестных. Ускорение исследований обеспечит более мощные ИИ, которые, в свою очередь, будут ещё сильнее ускорять исследования, создавая цикл положительной обратной связи.
Часто приводят аргумент, что робототехника значительно отстаёт от когнитивных способностей ИИ. Однако, учитывая текущее положение дел и тенденции развития, робототехника прогрессирует, и СИИ/ИСИ могли бы этот прогресс ускорить. Определённо стоит пристально следить за достижениями в этой области.
Можно представить сценарий, в котором стремящиеся к самосохранению ИИ-системы перестанут нуждаться в людях, поскольку смогут контролировать роботов для выполнения физической работы. Теоретически, у них может возникнуть мотивация полностью избавиться от человечества, чтобы исключить возможность своего отключения людьми.
Тем, кто считает, что СИИ и ИСИ будут к нам добры
Хотелось бы, чтобы эти ожидания оправдались, но исследования в области информатики и безопасности ИИ указывают в другом направлении. При отсутствии надёжных прогнозов, грамотное управление рисками требует принять меры предосторожности против вероятных негативных исходов.
ИИ с целью самосохранения стремился бы избежать отключения. Правдоподобная стратегия минимизации вероятности отключения – взять нас под контроль или устранить. Так ИИ мог бы гарантировать, что мы не поставим под угрозу его будущее.
Сущности (например, люди или страны) вынуждены искать взаимовыгодные решения только при относительном равенстве сил. Нет гарантий, что у нас будет такой паритет с ИСИ.
Откуда у ИИ может взяться сильное стремление к самосохранению? Это может быть намеренно заложено меньшинством людей, которые приветствовали бы превосходство ИИ, например, потому, что ценят интеллект превыше человечности. Но есть и технические аргументы (связанные с инструментальной конвергенцией или вмешательством в вознаграждение), в пользу того, что подобные цели могут возникнуть как побочный эффект даже самых безобидных целей, заданных людьми (см. «доклад» и цитируемые там источники, а также разнообразие взглядов на проблему потери контроля, отражающее уровень научной неопределённости в этом вопросе).
Было бы ошибкой полагать, что будущие ИИ-системы обязательно будут подобны нам, и у них будут те же базовые инстинкты. Мы не можем быть в этом уверены. То, как мы их сейчас создаём (например, как максимизаторы вознаграждения), указывает на совершенно иное. См. следующий пункт за дополнительными аргументами. Эти системы могут быть похожи на людей в одних аспектах, но сильно отличаться в других, и предсказать эти отличия сложно.
Стоит также учесть, что даже при конфликте между группами людей, если одна сторона обладает значительно превосходящими технологиями (как это было, например, при колонизации Америк европейцами, особенно в XIX веке), исход для более слабой группы может быть катастрофическим. Аналогично, наши перспективы в случае конфликта между ИСИ и человечеством выглядят довольно мрачными.
Тем, кто считает, что корпорации будут создавать только ИИ, которые будут хорошо себя вести, так что существующих законов достаточно
Почему бы инженерам из корпораций, занятых созданием будущих продвинутых ИИ-систем, не создавать безопасные ИИ? Разве корпорации сами не заинтересованы в безопасности своих ИИ? Проблема возникает, когда безопасность и максимизация прибыли или корпоративная культура («двигайся быстрее и ломай вещи») тянут в разные стороны.
Множество исторических свидетельств (вспомните компании по добыче ископаемого топлива и их влияние на климат, фармацевтические компании до введения регуляций, например, в случае с талидомидом) и экономические исследования показывают, что погоня за прибылью может сформировать поведение корпораций, противоречащее общественным интересам. При такой неопределенности рисков группе разработчиков легко убедить себя, что они найдут достаточно хорошее решение задачи безопасности ИИ (позже у меня будет пост с обсуждением психологических факторов).
Мы применяем законы, чтобы избежать конфликта интересов между глобальными рисками и корпоративными интересами или личным принятием желаемого за действительное. Однако команды корпоративных юристов могут найти в них лазейки. Искусственный сверхинтеллект (ИСИ), вероятно превосходящий лучшую команду юристов, наверняка обнаружит пробелы и в законах, и в инструкциях, призванных обеспечить безопасное поведение ИИ.
Составление контракта, который точно ограничивает поведение агента (человека, корпорации или ИИ) в интересах другого агента, остается нерешенной в общем случае задачей. Обратите внимание, как мы постоянно вносим поправки в законы в ответ на обнаруженные корпорациями лазейки. Неясно, сможем ли мы делать это с той же скоростью, с которой их будет находить ИСИ.
Проблема, похоже, в нашей неспособности предоставить ИИ полную формальную спецификацию неприемлемого поведения. Вместо этого мы можем дать спецификацию безопасности S, вероятно, на естественном языке. Если у ИИ есть основная цель G с ограничением соблюдения S, то при легкости достижения G без нарушения всех интерпретаций S всё будет работать как надо. Но если совместить одно с другим сложно, потребуется оптимизация (как команда юристов ищет способ максимизировать прибыль, соблюдая букву закона). Такая оптимизация, вероятно, найдет лазейки или интерпретации, позволяющие соответствовать букве, но не духу законов и инструкций.
Примеры таких лазеек уже описаны в литературе по безопасности ИИ. Они включают:
- Вмешательства в систему вознаграждения (контроль механизма вознаграждения создает неявную цель самосохранения)
- Разнообразные инструментальные цели (для достижения основной, казалось бы безобидной цели, ИИ стремится к потенциально полезным подцелям: самосохранению, контролю и влиянию в своем окружении, в том числе через убеждение, обман и взлом)
Уже наблюдались признаки таких склонностей. Ситуацию усложняет то, что инженеры не проектируют поведение ИИ напрямую, а только то, как ИИ обучается. В глубинном обучении результат – сложная и непрозрачная структура. Это крайне затрудняет выявление и исключение нежелательных намерений и обманчивости.
Для ссылок на исследования безопасности ИИ, нацеленные на смягчение этих рисков, см. «доклад». Пока эти исследования не смогли решить проблему.
Тем, кто считает, что нам следует ускорять исследования способностей ИИ и не задерживать выгоду от СИИ
Главный аргумент сторонников ускорения: будущий прогресс ИИ, вероятно, принесёт человечеству невероятную пользу, поэтому замедлять исследования способностей ИИ – значит отказываться от небывалого экономического и социального роста. Это возможно, но рациональное принятие решений требует взвешенного рассмотрения всех «за» и «против».
Представим, что мы получим медицинские прорывы, которые быстро удвоят нашу ожидаемую продолжительность жизни, но примем риск того, что все погибнут или потеряют свободу. В этом случае ставка ускорителей не особо привлекательна. Может, стоит немного притормозить, найти лекарство от рака чуть позже, но мудро вложиться в исследования, необходимые для контроля рисков, пока мы получаем глобальную выгоду?
Аргументы за ускорение часто исходят от крайне богатых людей и технокорпоративных лобби с личной финансовой заинтересованностью в максимальной краткосрочной выгоде. С их точки зрения, риски ИИ – это экономическая экстерналия, ложащаяся на всех сразу.
Корпорации принимают риски, потому что им выгодно игнорировать вред для общества – вполне обычная ситуация. Вспомним риски для климата от ископаемого топлива или опасность ужасных побочных эффектов от препаратов вроде талидомида. Но с точки зрения обычных людей и общества в целом, при учёте всех рисков и потенциальной выгоды, аккуратный и осторожный подход к СИИ явно лучше.
Возможен путь, при котором мы достаточно вложимся в безопасность ИИ, регуляции и соглашения для контроля рисков злоупотреблений и потери контроля, и одновременно реализуем выгоду ИИ. Это совместный вывод саммита по безопасности ИИ в Великобритании в 2023 году (30 стран-участниц), последовавшего в 2024 году саммита в Сеуле и Хиросимских принципов G7 об ИИ. С этим согласны и многие другие международные декларации и законотворческие предложения в ООН, ЕС и других организациях.
Тем, кто обеспокоен, что разговоры о катастрофических рисках навредят усилиям по смягчению краткосрочных проблем с ИИ, связанных с правами человека
Бывало такое, что меня просили перестать говорить о катастрофических рисках ИИ (как о злоупотреблениях, так и о потере контроля). Аргумент в том, что это обсуждение отвлечет внимание от хорошо обоснованного вреда правам человека, который ИИ уже наносит.
В демократии мы обсуждаем множество проблем параллельно. Было бы странно сказать: «Прекрати говорить об изменении климата» из страха, что это навредит обсуждению проблемы детского труда. Или просить не говорить о необходимости смягчать долгосрочные эффекты изменения климата, потому что это помешает обсуждению краткосрочной адаптации к нему.
Если бы мои оппоненты приводили сильные аргументы о невозможности катастрофических рисков ИИ, я бы понял их нежелание вносить в общественный дискурс лишний шум. Но на самом деле:
1. Есть правдоподобные аргументы, почему суперинтеллектуальный ИИ может обладать целью самосохранения (простейший – её ему дадут люди).
2. Ставки (если опасность реализуется) столь высоки, что это требует нашего внимания даже при низкой вероятности.
3. Мы не знаем, сколько времени осталось до СИИ. Уважаемые люди из передовых ИИ-лабораторий утверждают, что это может быть всего несколько лет. Риски могут оказаться не такими уж долгосрочными, а законотворчество, регуляции и соглашения могут занять много времени.
Наше будущее благополучие и способность контролировать будущее (иными словами, наша свобода) -– это права человека, которые надо защищать. К тому же, интересы тех, кто обеспокоен краткосрочными и долгосрочными рисками, должны сходиться. Обе группы хотят государственного вмешательства для защиты общества, регуляции и общественного надзора за ИИ.
Большинство недавних законотворческих предложений об ИИ затрагивали краткосрочные и долгосрочные риски в равной степени. На практике те, кто противостоит регуляциям – это часто люди с финансовыми или личными интересами в слепом ускорении гонки к СИИ. Во многих странах технические лобби успешно помешали или ослабили попытки ввода регуляций. Поэтому для тех, кто в них заинтересован, рационально было бы объединиться.
К сожалению, эти внутренние разногласия между теми, кто хочет защитить общество, сильно снижают шансы на реализацию общественного надзора и приоритизацию общего блага в разработке и развертывании ИИ.
Тем, кто обеспокоен холодной войной между США и Китаем
Китай – вторая ИИ-сверхдержава после США. В западных демократиях распространено искреннее беспокойство по поводу геополитического конфликта между Китаем и США (и их союзниками). Некоторые считают, что Китай может использовать прогресс в ИИ, особенно при приближении к СИИ и ИСИ, как мощное оружие. Это дало бы Китаю преимущество как в экономическом, так и в военном плане, особенно если Запад замедлит свой прогресс к СИИ ради безопасности.
Стоит честно признать: китайцы тоже боятся, что США могут использовать прогресс в ИИ против них. Это мотивирует Китай ускорять исследования способностей ИИ. Эта геополитическая конкуренция особенно беспокоит тех, кто убежден, что демократические институты лучше автократических режимов защищают права человека (см. [Всеобщую декларацию прав человека]((https://www.un.org/en/about-us/universal-declaration-of-human-rights), которую Китай подписал, но которая, к сожалению, ни к чему не обязывает).
Мы уже видим, как современные ИИ используются для воздействия на общественное мнение (например, с помощью дипфейков) и подрыва демократических институтов через распространение недоверия и невежества. Автократические государства уже применяют ИИ и социальные медиа для усиления внутренней пропаганды и контроля за недовольством (включая отслеживание в интернете и визуальную слежку с распознаванием лиц). Есть риск, что ИИ, особенно СИИ, может помогать автократам оставаться у власти и расширять влияние, вплоть до создания автократического мирового правительства.
Возможность, что будущий прогресс в ИИ может дать оружие первого удара (в том числе в кибервойне), мотивирует многих на Западе ускорять развитие способностей ИИ. Они отвергают идею замедления ради лучшей безопасности из страха, что это позволит Китаю опередить США в области ИИ.
Но если мы будем игнорировать безопасность ИИ и сосредоточимся только на способностях, как избежать экзистенциального риска потери контроля над СИИ? Если человечество проиграет из-за неконтролируемого ИСИ, неважно, какую политическую систему вы предпочитаете. Проиграют все. Когда дело касается экзистенциальных рисков, мы все в одной лодке.
Надеюсь, это мотивирует лидеров обеих сторон искать способы вкладываться и в безопасность ИИ. Мы могли бы сотрудничать в исследованиях, улучшающих безопасность, особенно если они не повышают способности. Никто не хочет, чтобы другая сторона в своих исследованиях СИИ совершила глобальную катастрофическую ошибку – мятежный ИСИ не станет уважать ничьих границ.
Что касается вложений, исследования способностей и безопасности не взаимоисключающи, если начать сейчас. У нас достаточно ресурсов для обоих направлений, особенно при правильно выстроенных стимулах. Но значительные вложения в безопасность необходимы. Надо убедиться, что вопросы безопасности решены до достижения СИИ, когда бы это ни произошло. Сейчас мы не на этом пути.
Меня беспокоит то, что если безопасные методологии в области ИИ не будут найдены вовремя, легче представимый риск чужой гегемонии вытеснит из внимания экзистенциальный риск потери контроля. Последний могут счесть умозрительным, в отличие от первого, подпитываемого веками вооруженных конфликтов.
Тем, кто считает, что международные соглашения не сработают
Заключать международные соглашения действительно сложно. Однако история показывает, что они возможны. Или, по крайней мере, она может помочь нам понять, почему они иногда терпят неудачу (особенно интересна история плана Баруха, когда США собирались поделиться атомными разработками с СССР). Даже без полной уверенности в успехе, они представляют важное направление, которое стоит попробовать для предотвращения глобальных катастрофических исходов.
Два необходимых условия успеха – это
общая заинтересованность в соглашении (имеется, все хотят избежать вымирания человечества) и возможность проверки соблюдения. Для первого нужно, чтобы государства действительно понимали риски. Поэтому необходимо больше исследований для их лучшего анализа. Здесь полезны компиляции знаний о безопасности ИИ вроде «доклада». Второе условие в случае ИИ представляет особую проблему. ИИ – это в основном софт, его легко модифицировать и скрывать. Возникающее из-за этого недоверие мешает заключить соглашение, предотвращающее опасные риски.
Однако ведутся обсуждения о возможности механизмов управления на уровне «железа». При их реализации высокопроизводительные чипы, позволяющие обучение СИИ, нельзя было бы спрятать. На них можно было бы выполнять только код, одобренный совместно установленной управляющей организацией. Цепочка поставок высокопроизводительных чипов для ИИ сейчас состоит из очень малого числа участников. Это даёт государствам возможность на неё повлиять. См. также проект из этого меморандума.
Можно представить сценарии, когда управление через «железо» не сработает. Например, если будут открыты способы на много порядков снизить вычислительную стоимость обучения ИИ. Это возможно, но не гарантировано. Вообще, все предложенные способы снижения катастрофического риска ИИ не дают гарантии по отдельности. Нам нужна «глубокая защита» – наслоение многих методов для защиты от различных опасных сценариев.
Важно понимать, что управления через «железо» будет недостаточно, если код и веса СИИ-систем не будут надёжно защищены. Использование и файн-тюнинг таких моделей намного дешевле их обучения и не требуют столь высокопроизводительных чипов. В этой области почти все (за пределами ведущих СИИ-лабораторий, у которых нет сильной культуры безопасности) согласны: при приближении к СИИ необходим быстрый переход к очень надёжным практикам информационной безопасности.
Наконец, соглашения касаются не только США и Китая. В долгосрочной перспективе безопасность от катастрофических злоупотреблений и потери контроля потребует сотрудничества всех стран. Но с чего странам Глобального Юга подписывать такое соглашение? Очевидный для меня ответ: в него должно быть включено обязательство, что ИИ не будет использоваться как инструмент доминирования, в том числе экономического. Научная, технологическая и экономическая выгода от ИИ должна распределяться глобально.
Тем, кто считает, что джинн уже выпущен из бутылки, и следует это признать и обойтись без регуляций
Возможно, джинн действительно выпущен из бутылки: большинство научных принципов, необходимых для СИИ, уже могут быть открыты. Много денег вложено с этим допущением. Но даже если это так, отсюда не следует, что нам стоит позволить силам рыночной и геополитической конкуренции полностью определять наш курс.
У нас всё ещё есть индивидуальная и коллективная возможность свернуть к более безопасному и демократичному миру. Также неверен аргумент, что регуляция обязательно провалится. Даже если регулировать ИИ будет непросто, это не значит, что не надо направлять усилия на проектирование новых институтов для защиты прав человека, демократии и будущего человечества. Это, конечно, может потребовать некоторых социальных инноваций.
Даже просто снижение вероятности катастрофы уже было бы полезно. Не обязательно ждать идеального решения, чтобы начать двигаться в нужную сторону.
Наприме, чтобы справиться с проблемой сложности выстраивания новой технической и социальной инфраструктуры, регуляторы могут полагаться на частные некоммерческие организации. Эти организации могут конкурировать друг с другом за проектирование наиболее эффективных оценок способностей и других инструментов безопасности.
Чтобы эффективно совладать с быстрым темпом перемен и неизвестными будущих ИИ-систем, регуляции должны обладать определённой гибкостью. У нас есть примеры законотворчества, основанного на определённых принципах и дающего регулирующим организациям достаточно свободы для адаптации к изменяющимся обстоятельствам и рискам (например, FAA в США).
Чтобы противостоять конфликту интересов (между общим благом и максимизацией прибыли) внутри корпоративных ИИ-лабораторий, государство может обязать эти компании включать в советы директоров разных заинтересованных лиц. Это обеспечит представление должного диапазона взглядов и интересов, включая представителей гражданского общества, независимых учёных и международного сообщества.
Тем, кто считает, что решение – открытый исходный код и веса СИИ
Открытые наука и код в прошлом многое нам дали и в целом продолжают приносить пользу. Однако всегда нужно взвешивать плюсы и минусы решений вроде «выложить в общий доступ код и параметры обученной ИИ-системы». Особенно когда способности ИИ достигнут человеческого или даже более высокого уровня.
Пока нынешние системы недостаточно мощны, чтобы быть катастрофически опасными в чужих руках или выйти из-под контроля. Поэтому выкладывание ИИ-систем в общий доступ может быть полезно – это помогает учёным в исследованиях безопасности ИИ. Но кто должен решать, где провести грань и как взвесить плюсы и минусы? Директора компаний или демократически избранные правительства? Если вы верите в демократию, ответ очевиден.
Это сложный (и болезненный для меня) вопрос: всегда ли свободное распространение информации – это хорошо? Представьте, у нас есть последовательность ДНК очень опасного вируса. Стоит ли её выкладывать в открытый доступ? Если в этом случае ответ для вас очевиден, тщательно подумайте о случае с алгоритмами и параметрами СИИ.
Недавно появился новый тревожный сигнал: исследование EPFL показало превосходящие человеческие способности к убеждению у GPT-4. Для этого ей достаточно дать страницу в Facebook человека, которого нужно убедить. Что, если такие ИИ-системы будут настроены на миллионах взаимодействий, обучающих ИИ тому, как эффективно переубеждать нас в чём угодно? Успешность демагогических приёмов ясно показывает уязвимость людей к подобным манипуляциям.
Что касается экзистенциальных рисков, некоторые утверждают: если у всех будут собственные СИИ, то «хорошие ИИ» победят «плохие ИИ», потому что хороших людей больше. У этого аргумента много слабых мест.
Во-первых, мы не уверены, что доброй воли владельца СИИ хватит, чтобы гарантировать моральное поведение самого СИИ (см. выше об инструментальных целях).
Во-вторых, нет гарантии, что меньшинство мятежных ИИ будет побеждено большинством «хороших» ИИ, и что мы вовремя найдём подходящие контрмеры (хотя мы, конечно, должны попытаться). Это зависит от баланса атаки и защиты. Подумайте о смертоносных первых ударах. Мятежный ИИ может выбрать вектор атаки, дающий атакующему мощное преимущество. Очевидный кандидат – биологическое оружие. Его можно скрытно разработать и выпустить разом, и оно будет сеять хаос и смерть экспоненциально, пока защищающаяся сторона будет искать лекарство.
Основная причина, почему биологическое оружие не применяется в человеческих войнах – атакующим сложно быть уверенными, что оно не обернётся против них самих. Мы все люди, и даже если у них есть лекарство, патоген после выпуска будет мутировать, и все гарантии могут перестать работать. Но это не проблема для мятежного ИИ, намеренного уничтожить человечество.
Теперь о злоупотреблениях ИИ-системами в открытом доступе. Действительно, злоупотребить можно и закрытой системой, например, найдя уязвимость. Однако:
а) Найти атаку для системы в открытом доступе гораздо проще.
б) В отличие от закрытых систем, после выкладывания в открытый доступ вы уже не можете исправить найденные уязвимости.
Важно: это касается и дополнительного обучения систем в открытом доступе. Оно может раскрыть опасные способности, допускающие потерю контроля.
Аргумент в пользу открытого доступа: больше людей смогут пользоваться преимуществами ИИ. Это верно, но для дополнительного обучения систем всё ещё требуются технические навыки. К тому же, экспоненциально растущие вычислительные затраты на обучение передовых ИИ-систем означают, что, скорее всего, оно будет доступно только очень небольшому числу организаций. Это сделает такие организации чрезвычайно влиятельными.
Я бы предпочёл как-то децентрализовать эту власть, не увеличивая при этом риски злоупотребления и потери контроля. От организаций, создающих эти системы, можно требовать особой прозрачности (по крайней мере, прозрачности способностей, не обязательно методов их получения), общественного надзора и участия разных заинтересованных сторон в управлении. Это поможет снизить риски злоупотребления мощью СИИ и риски потери контроля из-за недостаточных мер безопасности.
Вдобавок можно давать контролируемый доступ к коду доверенным исследователям, применяя при этом технические методы, не позволяющие им его копировать. Это откроет возможность присмотра и уменьшит риски злоупотреблений.
Тем, кто считает, что беспокойство о СИИ сродни Пари Паскаля
Пари Паскаля – рассуждение о том, что при возможности бесконечных потерь (ад или рай) в случае ошибочного решения не верить в Бога, нам следует действовать, исходя из убеждения, что Бог (кстати, именно христианский) существует. Аргумент против принятия мер по поводу катастрофических рисков ИИ проводит аналогию с Пари Паскаля из-за огромных рисков, потенциально даже бесконечных, если так рассматривать вымирание человечества.
Согласно этому аргументу, алармисты обосновывают своё беспокойство тем, что в пределе бесконечных потерь при вымирании мы должны действовать так, будто риски реальны, даже при практически нулевых свидетельствах в пользу вымирания или его вероятности. Это потому, что ожидаемый риск можно измерить, умножив вероятность события на потери, если оно произойдёт. Давайте рассмотрим, почему этот аргумент не работает.
Главная причина: мы имеем дело не с крохотными вероятностями. Согласно опросу от декабря 2023 года, медианный исследователь ИИ (не безопасности ИИ) оценивал вероятность вреда от ИИ уровня вымирания в 5%. Вероятность в 5% – не территория Пари Паскаля.
Есть серьёзные и подкреплённые научной литературой аргументы (см. «доклад» и пункты выше) в пользу того, что катастрофические риски очень продвинутых ИИ вполне реальны. Особенно при приближении или обгоне человеческого уровня во многих областях.
Нам не нужно принимать потери за бесконечные: возможных очень плохих сценариев по пути к СИИ и дальше много (опять же, см. «доклад»). У нас есть вполне ощутимые свидетельства в пользу ИИ-катастроф и значимая вероятность не бесконечных, но всё же неприемлемых потерь.
Это обычная ситуация для принятия решений. Рациональность требует от нас обратить внимание на эти риски, попытаться их понять и снизить.