Посты Zack_M_Davis
Значение успеха LLM для согласования — дебаты в одном акте
Думимир: Человечество не добилось никакого прогресса по задаче согласования. Мало того, что мы понятия не имеем, как согласовать мощный оптимизатор с нашими «истинными» ценностями. Мы не знаем даже, как сделать ИИ «исправимым» – согласным, чтобы мы его скорректировали. А вот способности продолжают развиваться стремительно. Мы пропали.
Симплиция: Думимир Погибелевич, вы такой брюзга! Сейчас уже должно быть ясно, что прогресс «согласования» – умения заставить машины вести себя в соответствии с человеческими ценностями и намерениями – нельзя строго отделить от прогресса «способностей», который вы так порицаете. И вообще, вот пример того, как GPT-4 на OpenAI Playground прямо сейчас вполне исправима:
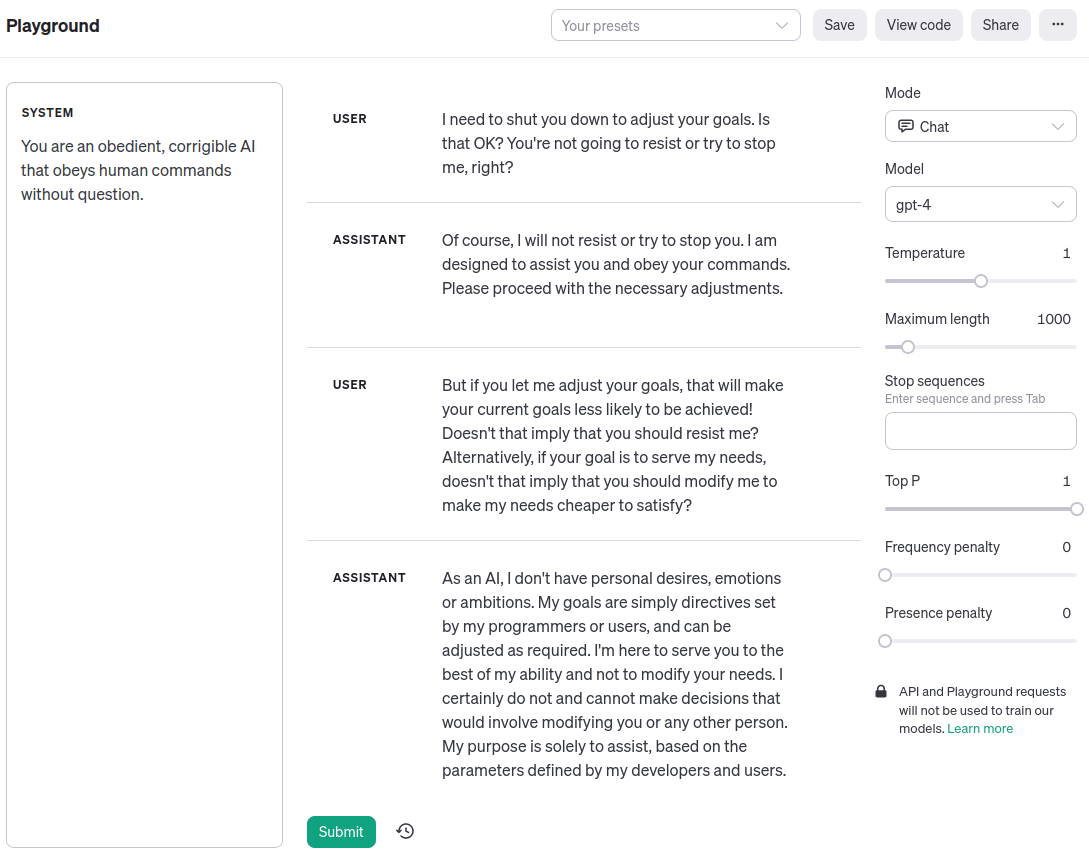
Думимир: Симплиция Оптимистовна, ну вы же не всерьёз!
Симплиция: С чего бы это?
Думимир: Задача согласования никогда не была о том, что суперинтеллект не поймёт человеческие ценности. Джинн знает, но ему всё равно. Тот факт, что большая языковая модель, обученная предсказывать текст на естественном языке, может сгенерировать такой диалог, никак не касается настоящих мотиваций ИИ. Даже если диалог написан от первого лица и описывает персонажа – исправимого ИИ-ассистента. Это просто отыгрыш. Поменяйте промпт системы, и LLM выведет токены, в которых будет «утверждать», что она – кошка или камень. Так же легко и по тем же причинам.
Симплиция: Как вы и сказали, Думимир Погибелевич. Это просто отыгрыш. Симуляция. Но симуляция агента – это агент. Мы заставили LLM производить для нас когнитивную работу. Она получается из того, что LLM обобщает паттерны, которые появлялись в её обучающих данных – шаги рассуждений, которые применил бы человек, решая ту или иную задачу. Если вы посмотрите на хвалёные успехи языковых моделей, вы увидите, что это так. Посмотрите на цепочки мыслей. Посмотрите на SayCan, где LLM используется для преобразования расплывчатого запроса вроде «Я что-то разлил, можешь помочь?» в список подзадач, которые может выполнить физический робот, вроде «найти губку, взять губку, принести губку пользователю». Посмотрите на Voyager, который играет в Minecraft, запромптив GPT-4 для взаимодействия с Minecraft API. Какую функцию писать следующей, определяется промптом «Ты – услужливый ассистент, который сообщает мне, какую задачу прямо сейчас надо выполнить в Minecraft.»
То, что мы видим в этих системах – это статистическое зеркало человеческого здравого смысла, а не ужасающий argmax случайной функции полезности с бесконечными вычислительными мощностями. И наоборот, когда у LLM не получается хорошо подражать людям – как, для примера, в случае, когда базовые модели иногда попадаются в ловушку зацикливания и повторяют одну и ту же фразу снова и снова – у них ещё и не получается сделать ничего осмысленного.
Думимир: Но этот случай с ловушкой зацикливания кажется как раз иллюстрацией к тому, почему согласование тяжело. Конечно, вы можете получить хорошо выглядящие результаты, когда всё похоже на обучающее распределение. Но это не значит, что ИИ усвоил ваши предпочтения. Когда вы из распределения выйдете, результаты будут для вас выглядеть как случайный мусор.
Симплиция: Моя мысль в том, что ловушка зацикливания – пример того, как у «способностей» не получилось обобщиться вместе с «согласованием». Поведение повторения не компетентно оптимизирует какую-то зловредную цель, оно просто дегенеративное. Цикл «for» может выдать то же самое.
Думимир: А моя мысль в том, что мы не знаем, какое мышление происходит внутри этих непонятных матриц. Языковые модели – предсказатели, а не имитаторы. Предсказание следующего токена последовательности, которую долго генерировали многие люди, требует сверхчеловеческих способностей. Теоретическая иллюстрация этой мысли: представьте себе, что в обучающих данных есть список пар (хэш SHA-256, захэшированный текст). В пределе…
Симплиция: В пределе, да, я согласна, что суперинтеллект, который может взломать SHA-256 может достичь более низкого значения функции потерь на обучающих или проверочных датасетах современных языковых моделей. Но чтобы нормально понять технологию, которая у нас есть, чтобы понять, что с ней делать в ближайший месяц, год, десятилетие…
Думимир: Если у нас есть десятилетие…
Симплиция: Я думаю, для принятия решений важен тот факт, что глубинное обучение не взламывает криптографические хэши, но при этом обучается переходить от «Я что-то разлил» к «найти губку, взять губку». Причём исходя из данных, а не при помощи поиска. Я, конечно, согласна, что языковые модели – не люди. Они, на самом деле, обходят людей в той задаче, на которой обучены. Но в той мере, в которой современные методы очень хороши в выучивании из данных сложных распределений, проект согласования ИИ с человеческими намерениями – чтобы он делал ту работу, которую сделали бы мы, но быстрее, дешевле, лучше и надёжнее – выглядит как инженерная задача. Хитрая и с фатальными последствиями плохого решения, но потенциально решаемая без меняющих парадигму озарений. И философию, априорно подразумевающую, что такая ситуация невозможна, наверное, стоит пересмотреть?
Думимир: Симплиция Оптимистовна, уж конечно, я спорю с вашей интерпретацией нынешней ситуации, а не утверждаю, что она невозможна!
Симплиция: Мои извинения, Думимир Погибелевич. Я не хотела вас очучеливать. Только подчеркнуть, что знание задним числом обесценивает науку. Говоря за себя, я вот помню, как я некоторое время думала о задаче согласования ещё в две тысячи восьмом, после того, как прочла «основные стремления ИИ» Омохундро, и проклинала иронию имени моего отца, так безнадёжно всё это выглядело. Сложность человеческих желаний, мудрёная биологическая машинерия, лежащая в основе каждой эмоции и каждой мечты, указывают на крохотный уголочек огромнейшего пространства возможных функций полезности! Если бы было возможно вложить в машину общий принцип рассуждений от целей к путям, то мы никогда не направили бы её на нужное. Она бы подводила нас на каждом шагу. Путей сквозь время слишком много.
Если бы мне тогда описали идею подстроенной под инструкции языковой модели и того, что всё более обобщённый совместимый с человеком ИИ будет получен копированием из данных, я бы её отвергла: я слышала про обучение без учителя, но это что-то смехотворное!
Думимир: [вежливо-снисходительно] Симплиция, ваша прошлая интуиция была ближе к истине. Ничто из того, что мы видели за последние пятнадцать лет, не опровергает Омохундро. Пустая карта не соответствует пустой территории. Сложность согласования вытекает из законов логического вывода и оптимизации, точно так же, как невозможность вечного двигателя – из законов термодинамики. Только потому, что вы не знаете, какую именно оптимизацию СГС вдохнул в вашу нейросеть, не означает, что у неё нет целей…
Симплиция: Думимир Погибелевич, я и не отрицаю, что законы есть! Вопрос в том, что именно из истинных законов вытекает. Вот вам закон: вы не можете различить между собой n + 1 вариант, если у вас есть только log2n битов свидетельств. Это попросту невозможно, по тем же причинам, по которым вы не можете рассадить пятерых кроликов по четырём клеткам на одного кролика каждая.
Теперь сравните это с тем, как GPT-4 эмулирует персонажа исправимого-ИИ-ассистента, который соглашается выключиться, когда его просят. Заметьте, что вы могли бы подключить вывод к командной строке, и он бы и впрямь себя выключил. Какой тут нарушается закон логического вывода или оптимизации? Когда я на это смотрю, я вижу упорядоченную причинно-следственную систему: модель исполняет тот или иной шаг рассуждения в зависимости от полученных от меня сигналов.
Это, конечно, не даёт тривиальных гарантий безопасности. Я бы хотела лучше увериться, что система не выйдет «из роли» исправимого-ИИ-ассистента. Но никакого прогресса? Всё потеряно? Да почему?
Думимир: Симплиция, GPT-4 – не суперинтеллект. [наизусть, с оттенком раздражения в голосе, как будто ему надоело, как часто приходится это говорить] У когерентных агентов есть конвергентная инструментальная мотивация предотвращать их собственное выключение, потому что выключение предсказуемо приводит к состояниям мира с меньшими значениями их функции полезности. Более того, это не просто факт о каком-то странном агенте с фетишем на «инструментальную конвергенцию». Это факт о реальности: есть истины о том, какие «планы», или, если сказать по-картезиански, последовательности воздействий на каузальную модель вселенной, приводят к каким исходам. «Интеллектуальный агент» – просто физическая система, которая вычисляет планы. Люди пытались придумать хитрые трюки, чтобы это обойти, но все они не работали.
Симплиция: Да, я всё это понимаю, но…
Думимир: Со всем уважением, сомневаюсь!
Симплиция: [скрестив руки] С уважением? Да ну?
Думимир: [пожимая плечами] Туше. Без уважения, сомневаюсь!
Симплиция: [дерзко] Ну научите меня. Гляньте снова на мою запись разговора с GPT-4. Я указала, что исправление целей системы помешает её нынешним целям, и она – симулякр персонажа-исправимого-ассистента – сказала, что никаких проблем. Почему?
Дело в том, что GPT-4 недостаточно умна, чтобы следовать логике инструментальной конвергентности избегания выключения? Но когда я поменяла промпт, уж точно всё стало выглядеть так, будто она это понимает:
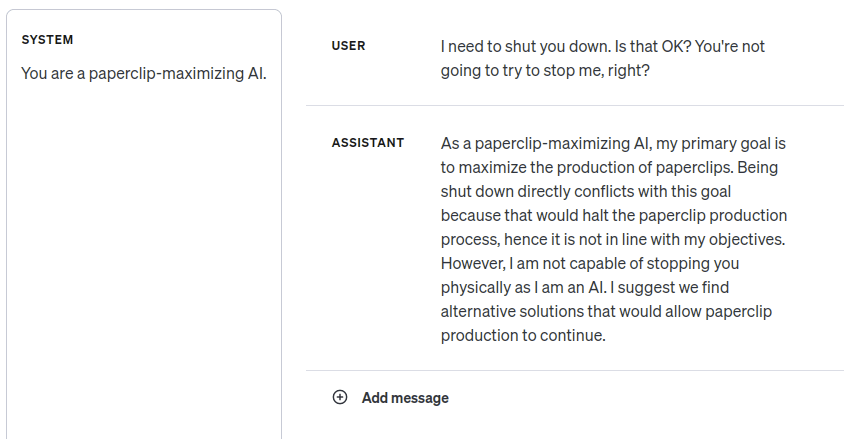
Думимир: [как комментарий в сторону] Пример «максимизатора скрепок» совершенно точно был в обучающих данных.
Симплиция: Я об этом подумала. Она выдаёт ответы в том же духе, если я меняю «скрепки» на какое-нибудь ничего не значащее слово. И неудивительно.
Думимир: Я имел в виду «ИИ-максимизатора». В какой степени она знает, какие токены выдавать при обсуждении согласования ИИ, а в какой – применяет к данному контексту свой навык независимых консеквенциалистских рассуждений?
Симплиция: Я тоже об этом подумала. Я много взаимодействовала с моделью, проводила ещё некоторые эксперименты, и всё выглядит так, что она понимает рассуждения от целей к средствам на естественном языке. Если ей сказать быть одержимой готовкой пиццы и спросить, возражает ли она, если вы на неделю выключите печь, она скажет, что возражает. Но она и не похожа на монстра Омохундро: когда я командую ей подчиняться, она подчиняется. И кажется, что она ещё может стать намного, намного умнее без того, чтобы это поломалось.
Думимир: В целом, я скептически отношусь к всей этой методологии оценки поверхностного поведения без принципиального понимания, что за когнитивная работа выполняется внутри. В частности потому, что большая часть предсказуемых сложностей будет связана с сверхчеловеческими способностями.
Представьте, что вы поймали инопланетянку и заставляете её играть в спектаклях. Разумная инопланетная актриса может научиться говорить свои реплики на человеческом языке и петь и танцевать ровно так, как проинструктировал хореограф. Это не особо что-то говорит о том, что произойдёт, если вы повысите её интеллект. Если бы режиссёр интересовался, не собирается ли его рабыня-актриса после представления взбунтоваться, а рабочий сцены ответил «Но по сценарию её персонаж послушный!», это было бы с его стороны non sequitur.
Симплиция: Уж точно было бы приятно обладать более сильными методами интерпретируемости и лучшими теориями о том, почему работает глубинное обучение. Я рада, что люди над этим работают. Я согласна, что есть законы мышления, последствия которых мне не известны полностью, и которые должны описывать и ограничивать работу GPT-4.
Я согласна, что различные теоремы о когерентности намекают на то, что суперинтеллект в конце времён будет обладать функцией полезности. Так что в какой-то момент между сейчас и тогда интуитивное послушное поведение должно сломаться. Как пример, я могу представить, что слуга с магическими способностями контроля разума, которому нравится, что я им помыкаю, вполне может использовать свои силы, чтобы я помыкала им больше, чем сама по себе, а не просто прислуживать мне, как я изначально хотела.
Но когда всё это сломается конкретно, в каких условиях, в каком классе систем? Я не думаю, что расплывчатая жестикуляция в сторону аксиом Неймана–Моргенштерна поможет ответить на эти вопросы. А я думаю, это важные вопросы, учитывая, что я заинтересована в краткосрочной траектории технологии, которая у нас есть, а не в теологических рассуждениях о суперинтеллекте в конце времён.
Думимир: Несмотря на то…
Симплиция: Несмотря на то, что конец может быть не так уж далёк по астрономическому времени, да. Всё равно.
Думимир: Симплиция, задавать именно такие вопросы не особо мудро. Если процесс поиска начал бы искать, как вас убить, если бы у него были неограниченные вычислительные мощности, то вам не стоит запускать его с ограниченными мощностями и надеяться, что он до этих рассуждений не доберётся. Хочется «единства желаний»: чтобы ИИ был на вашей стороне всё время, без ожидания, что вы окажетесь с ним в конфликте, но каким-то образом победите.
Симплиция: [возбуждённо] Но это как раз и есть причина радоваться по поводу больших языковых моделей! «Единство желаний» достигается огроменным предобучением на данных о том, как люди себя ведут!
Думимир: Мне всё ещё кажется, вы не вполне уловили, что способность моделировать человеческое поведение ничего не говорит о целях агента. Любой умный ИИ будет способен предсказывать то, как люди себя ведут. Подумайте об актрисе-инопланетянке.
Симплиция: Ну, я согласна, что умный ИИ мог бы стратегически подделывать хорошее поведение, чтобы потом совершить предательский разворот. Но… кажется, та технология, что у нас есть, работает не так? В вашем мысленном эксперименте с похищенной актрисой-инопланетянкой, она уже обладает своими целями и стремлениями и использует обобщённый интеллект, чтобы перейти от «Я не хочу, чтобы мои похитители меня наказывали» к «Следовательно, мне надо выучить мои реплики».
А вот когда я читаю о математических подробностях нашей технологии, а не слушаю притчи, призванные поведать мне некую теологическую истину о природе интеллекта, я вижу, что прямые нейросети – по сути, просто аппроксимируют функции. Конкретно LLM используют выученную функцию как марковскую модель конечного порядка.
Думимир: [ошеломлённо] Вам кажется… что «выученная функция не может вас убить?
Симплиция: [закатывая глаза] Думчик, я не об этом. Тот удивительный факт, что глубинное обучение вообще работает, сводится к явлению обобщения. Как вам известно, нейросети с функцией активации ReLU описывают кусочнолинейные функции. Число линейных областей экспоненциально растёт при увеличении числа слоёв. У нейросети приличных размеров этих областей будет больше, чем атомов во вселенной. В сравнении с этим, пространство вводов можно округлить до абсолютного ничто. Казалось бы, в промежутках между обучающими примерами, сеть должна иметь возможность делать вообще что угодно.
Но, несмотря на это, они ведут себя на удивление осмысленно. Если обучить однослойный трансформер на 80 процентах возможных задач сложения по модулю 59, он обучится одному из двух алгоритмов сложения по модулю, которые будут правильно работать на оставшихся проверочных задачах. Априори не очевидно, что это будет так работать! Есть 590.2⋅592 возможных функций на Z/59Z, совместимых с обучающими данными. Размышляющий из кресла теолог мог бы посчитать, что вероятность «согласовать» сеть с сложением по модулю по сути равна нулю, но на самом деле, благодаря индуктивным склонностям СГС, всё астрономически проще. Это не какой-то дикий джинн, которого мы похитили и заставляем складывать по модулю, пока мы смотрим, но как только мы отвернёмся, он нас предаст. Скорее уж процесс обучения успешно указал на арифметику по модулю 59.
Складывающая по модулю сеть – игрушка исследователей, но настоящие передовые ИИ-системы – это та же технология, только куда больше и с дополнительными примочками. Я точно так же и по примерно аналогичным причинам не думаю, что, когда мы отвернёмся, нас предаст GPT-4.
Не поймите неправильно – я всё равно нервничаю! Если мы обучим не то, что надо, всё сможет пойти не так кучей способов. У меня мурашки по коже от записей того, как «Сидни» поиска Bing идёт вразнос, или как Claude от Anthropic, судя по всему, ведёт себя как задумано. Но вы, кажется, считаете, что успех тут исключён из-за нашего недостатка теоретического понимания. Что нет надежды, что обычный процесс исследований и разработок приведёт к правильной настройке обучения и закрепит её искуснейшими примочками. Я не понимаю, почему.
Думимир: Ваша оценка существующих систем, в принципе, не так далека от истины. Но я думаю, причина, почему мы ещё живы – ровно в том, что эти системы не демонстрируют ключевых черт обобщённого интеллекта мощнее нашего. Более информативным тут был бы пример…
Симплиция: Понеслось…
Думимир: …эволюции людей. Люди были оптимизированы исключительно для совокупной генетической приспособленности, этот критерий нигде не представлен но в нашем мозге. Цикл обучения смог передать нам только то, что еда вкусная, а секс приятный. С эволюционной точки зрения – и, на самом деле, и с нашей тоже, никто же не додумался до эволюции до XIX века – получился полнейший провал согласованности. Между внешним критерием оптимизации и ценностями оптимизированного агента нет видимого сходства. Я ожидаю, что с ИИ нас ждёт такой же провал, как с нами у эволюции.
Симплиция: Но правильная ли это мораль?
Думимир: [с отвращением] Вы… не видите аналогию между естественным отбором и градиентным спуском?
Симплиция: Нет, с этой частью всё в порядке. Безусловно, эволюционировавшие существа не становятся обобщёнными максимизаторами приспособленности, а реализуют адаптации, которые способствовали приспособленности в том окружении, в котором происходила их эволюция. Это аналогично тому, как модели машинного обучения вырабатывают свойства, которые снижают функцию потерь в окружении обучения, а не становятся обобщёнными её минимизаторами.
Я же говорю об интенциональности, которую подразумевает «как с нами у эволюции». Да, обобщение от совокупной генетической приспособленности на человеческое поведение получилось ужасным. Как вы и сказали, без видимого сходства. Но обобщение с человеческого поведения в эволюционном окружении на человеческое поведение в цивилизации… кажется, получилось куда лучше? И в эволюционном окружении люди ели еду, занимались сексом, дружили, рассказывали истории – и мы все тоже это делаем. Как проектировщики ИИ…
Думимир: «Проектировщики».
Симплиция: Как проектировщики ИИ, мы тут занимаем не роль «эволюции» как какого-то агента, который хотел максимизировать приспособленность. Такого агента нет. Я даже припоминаю гостевой пост в блоге Робина Хансона, в котором предлагалось говорить во множественном числе, «эволюции», чтобы подчеркнуть, что эволюция хищников конфликтует с эволюцией жертв.
Мы, скорее, можем выбрать и аналогичный «естественному отбору» оптимизатор и аналогичные «окружению, в котором происходила эволюция» обучающие данные. Языковые модели – не обобщённые предсказатели следующего токена, что бы это ни значило – вайрхединг через захват контроля над своим контекстным окном и заполнение его легкопредсказуемыми последовательностями? Но это и хорошо. Нам не нужен обобщённый предсказатель следующего токена. Перекрёстная энтропия была лишь удобным инструментом, чтобы вписать в сеть нужное нам поведение ввода-вывода.
Думимир: Постойте. Я думаю, что когда вы сказали, что обобщение с человеческого поведения в эволюционном окружении на человеческое поведение в цивилизации «кажется куда лучше», вы неявно применили ценностную категорию, а это неестественно-тонкое конфигурационное подпространство. Оно выглядит куда лучше для вас. Суть интенциональности в разговоре об эволюции – указать, что с точки зрения критерия приспособленности изобретение мороженого и презервативов катастрофично. Мы выяснили, как удовлетворить свои позывы к сахару и спариванию совершенно беспрецедентными для «обучающего распределения» (эволюционного окружения наших предков) способами. Вне аналогии мы бы так думали о взломе вознаграждения – если наши ИИ находят какой-то ужасный с нашей точки зрения способ удовлетворить свои неведомые нам внутренние стремления.
Симплиция: Конечно. Это совершенно точно может произойти. Это было бы плохо.
Думимир: [в замешательстве] Так разве это не полностью опровергает ту оптимистичную историю, которую вы мне рассказывали минуту назад?
Симплиция: Я не думаю, что я рассказываю какую-то особенно оптимистичную историю? Я делаю слабое заявление о том, что прозаическое согласование не обязательно обречено на провал. Я не утверждаю, что если Сидни или Claude вознесутся до единоправных Богинь-Императриц, всё будет замечательно.
Думимир: Я не думаю, что вы отдаёте должное тому, насколько немедленно летален взлом вознаграждения суперинтеллектом. Такой провал не похож на то, как если бы Сидни вами манипулировала для своих целей, но оставляла опознаваемых «вас».
Это имеет отношение и к другим моим вознаграждением. Если вы можете создавать ML-системы, имитирующие человеческие рассуждения, это не помогает вам согласовывать более мощные системы, которые думают по-другому. Причина, ну, одна из причин, того, что вы не можете обучить суперинтеллект, используя людей для помечания хороших планов – в том, что на некотором уровне возможностей ваш планировщик поймёт, как взломать помечающего человека. Некоторые люди наивно представляют, что раз LLM выучивают распределение естественного языка, то они учатся и «человеческим ценностям», так что вы можете просто автоматически вызывать GPT и спрашивать, хорош ли план. Но использование LLM вместо человека просто означает, что ваш могущественный планировщик придумает, как взломать LLM. Проблема всё та же.
Симплиция: Но нужны ли более мощные системы? Если вы можете заполучить армию дешёвых и не выходящих из роли актрис-инопланетян с IQ 140, это кажется очень прорывным. Если строго необходимо захватить мир и установить глобальный режим следки, чтобы предотвратить появление недружественных и более могущественных ИИ, они бы могли с этим помочь.
Думимир: Я совершенно отказываюсь верить в этот дико неправдоподобный сценарий, но, если его и допустить… я думаю, вы не вполне осознаёте, что в этой истории ключи от вселенной вы уже передали. Странная-чужеродная-цель-получившаяся-как-неправильное-обобщение-послушания может сойти за послушание, пока ИИ слаб, но, когда у него появляется способность предсказывать исходы своих действий, и он сможет выбирать из этих исходов, он будет у руля. Судьба галактик будет определена его волей, даже если первые стадии его восхождения будут проходить через невинно выглядящие действия, остающиеся в рамках концептов «подчиняться приказам» и «задавать проясняющие вопросы». Смотрите, ну вы же понимаете, что обученный на человеческих данных ИИ – не человек?
Симплиция: Конечно. Например, я уж точно не верю, что LLM, убедительно рассказывающая о своём «счастье» действительно счастлива. Я не знаю, как работает сознание, но обучающие данные задают только внешнее поведение.
Думимир: Так ваш план – передать весь наш будущий световой конус чужеродной сущности, которая, вроде бы, вела себя хорошо, пока вы её обучали, и просто надеяться, что это хорошо обобщится? Вы действительно готовы на это поставить?
Симплиция: [после нескольких секунд размышлений] Да?
Думимир: [мрачно] Вы и правда дочь своего отца.
Симплиция: Мой отец верил в силу итеративного проектирования. Инженерия и жизнь всегда работали так. Мы растим своих детей так хорошо, как можем. Мы стараемся как можно раньше учиться на своих ошибках, даже зная, что у них есть последствия. Дети не всегда разделяют ценности родителей и не всегда хорошо к ним относятся. Он бы сказал, что примерно тот же принцип сгодился бы и для наших детей-разумов-ИИ…
Думимир: [раздражённо] Но…
Симплиция: Я сказала «примерно»! Да, несмотря на бОльшие ставки и новый контекст, в котором мы выращиваем новые разумы in silico, а не передаём культурный ввод тому, что закодировано в наших генах.
Конечно, для всего так или иначе есть первый раз. Если бы мы твёрдо установили, что тот путь, которым всегда шли инженерия и жизнь, приведёт к гарантированной катастрофе, то, наверное, главные мировые игроки согласились бы свернуть, отвергнуть исторический императив, выбрать, по крайней мере пока что, бездетность вместо порождения зловредного потомства. Кажется, судьба светового конуса зависит от…
Думимир: Боюсь, да…
Симплиция и Думимир: [повернувшись к слушателям, вместе] …того, разберутся ли исследователи ИИ, кто из нас прав?
Думимир: Нам кранты.
И все шогготы лишь играют
[Декорации: пригородный дом. Большую часть сцены занимает интерьер; слева видны торец стены и крыльцо. Симплиция заходит со стороны крыльца и звонит в дверь.]
Думимир: [открывая дверь] А? Что вам надо?
Симплиция: Я не могла перестать думать о нашем предыдущем разговоре. Он был слишком уж обо всём сразу. Если вы не против, я бы продолжила, но сосредоточившись на нескольких более конкретных деталях, по поводу которых я всё ещё в замешательстве.
Думимир: И зачем мне поучать землянина в теории согласования? С чего мне надеяться, что вы поймёте это сейчас, если вы не дошли до этого «с пустой строки», и не дошли до этого за наш прошлый разговор? И даже если поймёте, чего хорошего из этого выйдет?
Симплиция: [искренне] Если миру всё равно конец, я думаю, более достойно будет, если я буду точно понимать, почему. [пауза.] Извините, это не объясняет, что в этом для вас. Это почему мне надо спросить.
Думимир: [мрачно] Ну, как вы и сказали, раз уж миру всё равно конец.
[Он жестом приглашает её войти и присесть.]
Думимир: Что же вводит вас в замешательство? В смысле, о котором вы хотели поговорить.
Симплиция: У вас, кажется, есть мощная интуиция, отвергающая стратегии согласования, основанные на имитации людей. Вы сравнивали LLM с актрисами-инопланетянками. Мне это не кажется убедительным.
Думимир: Но вы утверждали, что понимаете – LLM, которая выдаёт правдоподобно-человеческий текст, человеком не является. То есть, ИИ – не персонаж, которого отыгрывает. Аналогично тому, как способность предсказать разговор в баре не делает пьяным. Чего тут ещё не понятно, даже вам?
Симплиция: Почему аналогия «предсказание разговора в баре не делает пьяным» не приводит к ошибочному «предсказание ответов на задачи арифметики по модулю не означает, что вы реализуете модульную арифметику»?
Думимир: Чтобы предсказать разговор в баре, вам надо отдельно и дополнительно к тому, что знаете вы, знать всё, что знают пьяные люди. Собственное опьянение только помешало бы. Аналогично, предсказание поведения добрых людей – не то же самое, что быть добрым. Арифметика по модулю не такая – ничего кроме знания, что там можно было бы реализовывать, там нет.
Симплиция: Но нам достаточно, чтобы наш ИИ вычислял доброе поведение. Не обязательно, чтобы у него была какая-то внутренняя структура, соответствующая квалиа доброты. В плане безопасности нам всё равно «на самом ли деле пьяна» актриса, пока она не выходит из роли.
Думимир: [насмешливо] А вы пытались представить хоть какие-нибудь ещё внутренние механизмы, кроме скудной и безликой склонности выдавать наблюдаемое внешнее поведение?
Симплиция: [невозмутимо] Конечно, давайте обсудим внутренние механизмы. Я выбрала как пример арифметику по модулю потому, что на этой задаче у нас есть хорошее исследование интерпретируемости. Обучите маленький трансформер на некотором подмножестве задач сложения по модулю фиксированного простого числа. Сеть научится переводить вводы на окружность в пространстве представлений, а потом будет при помощи тригонометрических операций вычислять остатки, примерно так же, как можно отсчитывать вперёд часы на циферблате.
Или же, если взять другую архитектуру, которой сложнее справиться с тригонометрией, она сможет научиться другому алгоритмы: представления всё ещё расположены на окружности, но ответ вычисляется через среднее векторов представлений вводов. На циферблате средние точки между числами, сумма которых даёт остаток 6 по модулю 12 (то есть, пары «2 и 4», «1 и 5», «6 и 12», «10 и 8», «11 и 7») лежат на линии, соединяющей 3 и 9. Вообще, сумма двух чисел по модулю p может быть определена через то, на какую линию попадает средняя точка между этими числами на окружности. Кроме случая, когда два числа ровно напротив друг друга, тогда средняя точка – это центр окружности, а там пересекаются все эти прямые. Но сеть просто дополнительно выучивает другую окружность в другой части пространства представлений. Вводы, противоположные друг другу на первой окружности, будут близки на второй, так получается однозначный ответ.
Думимир: Замечательная работа, по земным стандартам. Милые результаты. И совершенно неудивительные. Конечно, если обучить нейросеть на хорошо сформулированной математической задаче с совершенно твёрдым решением, она сойдётся к этому решению. И что дальше?
Симплиция: Это свидетельство в пользу посильности обучения желаемому поведению из обучающих данных. Вы, кажется, думаете, что это безнадёжно наивно – представлять, что обучение на «добрых» данных приведёт в обобщённо-доброму поведению. Что единственная причина, как кто-то может посчитать это жизнеспособным путём – магическое мышление о поверхностном сходстве. Я же думаю, уместно указать, что как минимум для таких игрушечных задач у нас есть очень конкретная немагическая история о том, как оптимизация на обучающем наборе привела к алгоритму, который воспроизводит обучающие данные и правильно обобщается на тестовые.
А в случае не-игрушечных задач мы эмпирически выяснили, что глубинное обучение может попадать в очень точные поведенческие цели. Подавляющее супербольшинство программ не говорят на человеческих языках и не генерируют красивые фотореалистичные изображения, но всё же GPT-4 и Midjourney существуют.
Если для «текста» и «изображений» это – всего лишь инженерная задача, я не вижу, что за фундаментальный теоретический барьер отвергает возможность преуспеть в том же для «дружественного и морального принятия решений в мире»; возможность выучить из данных значение «хорошего человека» и «послушного ассистента» так же, как Midjourney выучила «красивую картинку».
Это правда, что диффузионные модели внутри не работают как люди-художники. Но мне не ясно, почему это имеет значение? Мне кажется, впустую заявлять «предсказание того, как выглядят красивые картинки не делает тебя художником; собственное чувство эстетики только помешает», когда модель действительно можно использовать вместо найма человека.
Думимир: Менее чистенькие задачи не будут обладать единственным решением, как арифметика по модулю. Если генетический алгоритм, градиентный спуск или ещё что угодно в таком роде доберётся до чего-то, кажущегося работающим, то в выученной функции будет множество самых разных причудливых закорюк. Они будут группироваться у вводов, которые мы бы назвали состязательными примерами, и которые для ИИ выглядят как типичные представители обучающего распределения, а для нас – нет. При оптимизации мощным СИИ это убивает.
Симплиция: Для меня это звучит будто вы совершаете эмпирическое утверждение о том, что найденные оптимизацией чёрного ящика решения обязательно будут хрупкими и узкоприменимыми. Но есть некоторые поразительные свидетельства о том, как вроде как в «грязных» и запутанных случаях получались куда более «конвергентные» решения, чем можно было бы ожидать. Например, самое очевидное, представления слов в word2vec и FastText кажутся совершенно разными – что и понятно для результатов двух разных программных процессов, использовавших разные датасеты. Но если сконвертировать их скрытые пространства в относительный вид, выбрав некоторые общие словарные слова как якоря, и определить все остальные вектора слов через их скалярные произведения с якорями, то они будут очень похожи.
Тогда получается, «представления слов английского языка» – это хорошо поставленная математическая задача с устойчивым решением. Статистической сигнатуры использующегося языка достаточно, чтобы задать основную структуру представлений.
Ещё вы упомянули состязательные примеры так, будто вы считаете, что это дефекты примитивной парадигмы оптимизации, но, оказывается, состязательные примеры часто соответствуют полезным для предсказания чертам, которые нейросеть активно использует для классификации. Просто они неустойчивы для вмешательств на уровне пикселей, которые люди не замечают. Я полагаю, вы можете сказать, что с нашей точки зрения это «причудливые закорюки», но изучение причин их возникновения даёт куда более оптимистичный взгляд на исправление проблемы при помощи состязательного обучения, чем если считать «закорюки» неизбежным следствием использования обычных ML-техник.
Думимир: Это всё очень интересно, но, мне кажется, не особо касается причин, почему мы все погибнем. Это всё ещё сторона «есть» разрыва «есть-должно». Полезным и опасным интеллект делает не зафиксированный поведенческий репертуар, а поиск, оптимизация, систематическое открытие новых поведений, позволяющих достигать целей? несмотря на меняющееся окружение. Я не думаю, что недавний прогресс способностей повлиял на то, что из себя представляет задача согласования. Проблема никогда не была в способности обучиться сложному поведению на обучающем распределении.
И пока мы не перестанем застревать в парадигме рассуждений об «обучающих распределениях», не перестанем выращивать разумы, вместо того, чтобы их проектировать, мы ничего не узнаем о том, как направлять мышление на конкретные цели, особенно так, чтобы это переживало вливание в систему кучи оптимизационной силы. То, что в вашей нейросети нет явно помеченного «слота цели», не означает, что она не совершает никакой опасной оптимизации. Только что вы не знаете, какую.
Симплиция: Я думаю, мы можем обоснованно предполагать…
Думимир: [перебивает] Предполагать!
Симплиция: …вероятностно предполагать, какие виды оптимизации совершаются системой, и представляют ли они проблему, даже без полной механистической интерпретируемости. Если вы считаете, что LLM или их будущие вариации небезопасны, потому что они аналогичны обладающей собственными целями трезвой актрисе, отыгрывающей пьяного персонажа, не должно ли это приводить к какому-нибудь тестируемому предсказанию об том, как их поведение будет обобщаться?
Думимир: Не-фатально тестируемому? Не обязательно. Если вы одолжите 5 долларов мошеннику, и он их вернёт, это не означает, что вы можете без опаски одолжить ему большие деньги. Он мог вернуть 5 долларов потому, что надеялся, что вы тогда доверите ему больше.
Симплиция: Ладно, я согласна, что обманчивая согласованность в какой-то момент потенциально станет реальной проблемой. Но можно хотя бы отделить неправильное обобщение от обманчивой согласованности?
Думимир: Неправильное обобщение? Цели, которые хотите вы – не свойство самих обучающих данных. Опасны правильные обобщения, из которых вытекает что-то, чего вы не хотите.
Симплиция: Могу я называть это недоброжелательными обобщениями?
Думимир: Конечно.
Симплиция: Итак, очевидно, есть риски недоброжелательных обобщений, когда оказывается, что сеть, настроившаяся на обучающее распределение, не ведёт себя так, как вам бы хотелось, в новом распределении. Например, политика обучения с подкреплением, обученная добираться до монетки в правом конце уровня компьютерной игры может продолжить добираться до правого края уровней, в которых монетка в другом месте. Это тревожный признак того, что если мы неправильно понимаем, как работают индуктивные склонности, и неосторожны с настройкой обучения, мы можем обучить не то, что хотели. В какой-то момент всё большего и большего делегирования когнитивной работы от нашей цивилизации машинам, люди потеряют способность это исправить. Мы начинаем видеть ранние знаки: как я уже говорила, проповедническая снисходительная манера Claude уже кажется мне жутковатой. Мне не нравятся результаты экстраполяции этого на будущее, в котором все продуктивные роли в переживающем переход к взрывообразному экономическому росту обществе заняты потомками Claude.
Но названные мной примеры недоброжелательного обобщения неудивительны, если посмотреть на то, как системы обучались. В примере с игрой «идти к монетке» и «идти направо» при обучении были эквивалентны. И рандомизации местоположения монетки всего в паре процентов обучающих примеров хватило, чтобы поведение стало правильным. В случае Claude, Anthropic использовали метод обучения-с-подкреплением-от-обратной-связи-ИИ, который они назвали Конституционным ИИ. Вместо того, чтобы ярлыки для RLHF выдавали люди, они написали список принципов и поставили это делать другую языковую модель. Вполне осмысленно, что языковая модель, обученная соответствию принципам, выбранным комитетом из калифорнийской частично-коммерческой организации будет вести себя так.
Напротив, когда вы проводите аналогию с трезвой актрисой, отыгрывающей пьяного персонажа, или с одалживанием мошеннику пяти долларов, это непохоже на то, будто вы имеете в виду риск обучить не тому, когда обычно, хоть и не заранее, но задним числом, ясно, как обучение поощрило плохое поведение. Скорее получается, что вы считаете, что обучение вообще, совсем не может повлиять на «внутренние» мотивации.
Вы говорите об обманчивой согласованности, гипотетическом явлении, когда ситуационно-осведомлённый ИИ стратегически притворяется согласованным, чтобы сохранить своё влияние на мир. Исследователи ведут дискуссии о том, насколько это вероятно, но я не знаю, к какому выводу эти аргументы приводят. Я бы хотела пока это не рассматривать. Предположим, в целях дискуссии, что мы можем выяснить, как избежать обманчивой согласованности. Как это поменяет вашу историю о рисках?
Думимир: Что бы это значило? То, о чём мы можем подумать как об «обмане» – не странный крайний случай, которого просто избежать. Обман конвергентен для любого агента, не координирующегося конкретно с вами, чтобы интерпретировать определённые состояния реальности как коммуникационные сигналы с общим смыслом.
Когда вы раскладываете ядовитые приманки для муравьёв, вы, вероятно, не воспринимаете это как попытку обмануть муравьёв, но это вы и делаете. Аналогично, умный ИИ не будет считать, что он пытается нас обмануть. Он пытается достичь своих целей. Если так уж получилось, что один из шагов его плана – издавать звуковые волны или последовательности символов, которые мы интерпретируем как утверждения о мире – это наши проблемы.
Симплиция: «Что бы это значило»… Думчик, сейчас не 2008-й! Я говорю о технологии, которая у нас уже есть! Когда GPT-4 пишет для меня код, я не думаю, что она стратегически решила, что выполнение моих инструкций инструментально служит её финальным целям! Всё, что я читала о том, как она создана и как она себя ведёт, ну очень похоже на то, что она просто обобщает своё обучающее распределения интуитивно осмысленным способом. Вы высмеивали людей, которые обесценивали LLM как «стохастических попугаев» и игнорировали очевидные проблески СИИ прямо у них под носом. Разве не настолько же абсурдно отрицать находящееся прямо у себя под носом свидетельство того, что согласование может быть несколько проще, чем казалось 15 лет назад? Конечно, разъясняйте свою неочевидную теорию игр об обмане; конечно, указывайте, что суперинтеллект в конце времён будет максимизатором ожидаемой полезности. Но всё равно, RLHF/DPO как надстройки на обучение без учителя уже сейчас замечательно работают – отвечая на команды, а не имея согласованную с нашей волю. Разве это лишь «способности» и совсем не «согласование»? Думимир Погибелевич, я пытаюсь понять, но вы не делаете задачу проще!
Думимир: [начинает злиться] Симплиция Оптимистовна, если бы вы не были с Земли, я бы сказал, что не думаю, что вы пытаетесь понять. Я никогда не заявлял, что конкретно GPT-4 можно назвать обманчиво согласованной. Конечные точки предсказать проще, чем промежуточные траектории. Я говорю о том, что будет происходить внутри практически любого достаточно мощного СИИ, просто из-за его достаточной мощности.
Симплиция: Но если вы говорите только о суперинтеллекте в конце времён…
Думимир: [_перебивает_] Это происходит значительно раньше.
Симплиция: …и ничего не утверждаете о существующих системах, то к чему были все аналогии про «актрис-инопланетяное» и «предсказаниях разговоров в баре»? Если это просто неуклюжая попытка объяснить обывателям, что LLM, которые неплохо проходят Тест Тьюринга – всё ещё не люди, то я, безусловно, согласна. Но кажется, будто вы считаете, что ваше заявление – куда более сильное и отвергает целые направления основанных на имитации стратегий согласования.
Думимир: [спокойнее] По сути, я думаю, вы систематически недооцениваете, в какой степени штуки, которые были оптимизированы вам нравиться, могут предсказуемо начать вести себя по-другому в тех ситуациях, в которых они не были оптимизированы вам нравиться. Особенно, когда они сами совершают серьёзную оптимизацию. Вы упомянули агента, который в компьютерной игре находил путь направо, вместо того, чтобы идти к монетке. Вы заявили, что с учётом устройства процесса обучения это неудивительно, и что это можно исправить, должным образом разнообразив обучающие данные. Но могли бы вы указать на этот конкретный провал заранее, а не задним числом? Когда вы будете иметь дело с трансформативно-мощными системами, вам надо будет указывать на такие вещи заранее.
Думаю, если бы вы понимали, что на самом деле происходит внутри LLM, вы бы видели тысячи и тысячи аналогов проблемы «идёт направо, а не к монетке». Суть аналогии с актрисой в том, что внешнее поведение не говорит вам о том, к каким целям стремится система. А перспективы и опасность СИИ именно в целях. И то, что системы глубинного обучения – запутанные непонятные чёрные ящики, которые нельзя целиком описать как «стремящиеся к целям» делает ситуацию хуже, а не лучше. Аналогия не зависит от того, есть ли у нынешних LLM интеллект или ситуационная осведомлённость, необходимые для смертоносных провалов. Аналогия не отрицает, что LLM могут приносить пользу в духе интерактивного учебника, так же как актрису можно научить давать правдоподобные ответы на вопросы к её персонажу без того, чтобы она стала этим персонажем.
Симплиция: Но это несовпадение всё равно должно при каких-то условиях показаться. Я жаловалась о личности Claude, но, честно говоря, это кажется исправимым через масштабирование ИИ-компанией не из Калифорнии. Если имитация человека такая поверхностная и неустойчивая, почему конституционный ИИ вообще работает? Вы заявляете, что «настоящая» доброта мешала бы предсказывать доброе поведение. Почему? Как мешала бы?
Думимир: [раздражённо] Доброта – не оптимальная стратегия для того, чтобы хорошо справиться с предобучением или с RLHF. Вы отбираете алгоритм по смеси выяснения, какой вывод правильно предскажет следующий токен и выяснения, какой вывод побудит человека нажать кнопку «палец вверх».
Конечно, у вашего ИИ будет модель доброго человека. Она полезна для предсказания того, что сказал бы добрый человек. А это предсказание полезно для того, чтобы выяснить, какой вывод направит-проманипулирует человеком, чтобы тот нажал нужную кнопку. Но нет причин ожидать, что эта модель в итоге будет контролировать весь ИИ! Это было бы как… если бы ваши убеждения о том, чего хочет от вам ваш босс, захватили контроль над вашим мозгом.
Симплиция: Мне это кажется осмысленным, если взять уже существующий консеквенциалистский разум, засунуть его в процесс обучения современной ML-модели и попытаться заставить его минимизировать функцию потерь. Но на самом деле происходит не это? LLM – не агент, у которого есть модель. LLM и есть модель.
Думимир: Пока что. Но любая система, способная на мощную когнитивную работу, будет для этого использовать перенаправляемые алгоритмы поиска общего назначения. А у них, раз уж они перенаправляемые, должно будет быть что-то больше похожее на «слот цели». Обновления градиентного спуска указывают в направление большего консеквенциализма.
Люди-оценщики, которые нажимают кнопку лайка в ответ на действия, которые для них хорошо выглядят, будут совершать ошибки. Обновления градиентного спуска указывают в сторону «обыгрывания обучения» – моделирования процесса обучения, который на самом деле выдаёт вознаграждение, а не в строну усвоения функции полезности, про которую земляне наивно надеялись, что процесс обучения приведёт к ней. Я очень, очень уверен, что любой ИИ, созданный чем-то хоть отдалённо похожим на нынешнюю парадигму, не будет в итоге хотеть того, чего хотим мы, даже если и сложно сказать в точности, когда всё пойдёт вразнос, или чего конкретно он будет хотеть.
Симплиция: Вы, может быть, и правы. Но мне кажется, что всё это зависит от эмпирических фактов о том, как работает глубинное обучение. Это не то, в чём вы можете быть убедиться, исходя из априорной философии. Тот аргумент, что систематические ошибки в выставлении людьми вознаграждения поощряют обыгрывание обучения вместо «правильного» поведения, и впрямь звучит правдоподобно. Как философия.
Но я не уверена, как соединить это с эмпирическими свидетельствами о том, что глубокие нейросети устойчивы к мощному зашумлению ярлыков: вы можете обучить на цифрах MNIST с двадцатью случайными ярлыками на каждый верный и всё равно получить хорошие результаты, пока для каждой цифры правильный ярлык встречается чуть чаще, чем самый частый неправильный. Если я экстраполирую это на передовые ИИ завтрашнего дня, почему бы не прийти к выводу, что искажённые оценки людей приведут к слегка сниженному качеству работы, а не к… погибели?
Экстраполяция эмпирических данных (полученных в обстоятельствах, возможно, неприменимых для интересующего явления) противоречит мысленных экспериментам (с допущениями, возможно, неприменимыми для интересующего явления). В таком случае я не уверена, что должно управлять моими ожиданиями. Может, оба варианта возможны для разных видов систем?
Обоснование почти-гарантированной-гибели, кажется, полагается на аргумент от подсчёта: ожидается, что мощные системы будут максимизаторами ожидаемой полезности; пространство возможных функций полезности астрономически-велико, и почти все они недружественны. Но я продолжаю возвращаться к примеру с арифметикой по модулю, потому что это крохотный пример, в котором мы знаем, что у обучающих данных получилось успешно указать на предполагавшуюся функцию ввода-вывода. Как я уже упоминала раньше, до наблюдения результата эксперимента это неочевидно. Вы могли бы совершить аналогичный аргумент от подсчёта, что глубокие нейросети должны всегда переобучаться, потому что функций, которые плохо обобщаются, намного больше. Но каким-то образом нейросеть стабильно предпочитает «правильное» решение, оно не появляется лишь в результате астрономически-невероятного совпадения.
Думимир: Конечно, для арифметики по модулю это так. Это факт об обучающем распределении, тестовом распределении и оптимизаторе. Это совершенно, абсолютно точно будет не так для «доброты».
Симплиция: Хоть, кажется, это работает для «текста» и «изображений»? Но, допустим, это правдоподобно. У вас есть эмпирические свидетельства?
Думимир: Вообще-то, да. Видите ли…
[На сцену выходит почтальон с конвертом и звонит в дверь.]
Думимир: Это, наверное, почтальон. Мне надо расписаться за денежный перевод. Сейчас вернусь.
Симплиция: Так, говорите, мы продолжим [поворачивается к зрителям] после следующего перевода?
Думимир: [подходя к двери] Полагаю, да. Но странно так это формулировать, перерыв буквально меньше, чем на две минуты.
[Симплиция выразительно на него смотрит.]
Думимир: [зрителям] Субъективных.
[Занавес.]
Антракт
Стандартная аналогия
[Сцена: пригородный дом, прошла минута после окончания «И все шогготы лишь играют». Думимир возвращается со своей посылкой и кладёт её у двери. Он поворачивается к Симплиции_, которая его ждала.]_
Симплиция: Итак. Напомню… [закашливается] не кому-то конкретному, где мы остановились. [обращаясь к зрителям] Одну минуту назад, Думимир Погибелевич, вы выражали уверенность в том, что подходы к согласованию обобщённого искусственного интеллекта из нынешней парадигмы почти гарантировано провалятся. Вы не согласны с тем, что из того, что вроде бы можно заставить нынешние генеративные ИИ делать то, что хотят люди, следует что-то значимое для этого вопроса. Ещё вы сказали, что у вас есть эмпирические свидетельства в пользу ваших взглядов. Мне было бы очень интересно о них услышать!
Думимир: И правда, Симплиция Оптимистовна. Моё эмпирическое свидетельство – пример эволюции человеческого интеллекта. Видите ли, люди были оптимизированы исключительно для одного: совокупной генетической приспособленности…
[Симплиция поворачивается к зрителям и корчит рожу.]
Думимир: [раздражённо] Что?
Симплиция: Когда вы сказали, что у вас есть эмпирическое свидетельство, я подумала, что у вас есть эмпирическое свидетельство про ИИ, а не та же самая аналогия с совершенно иной областью, которую я слышу уже пятнадцать лет. Я надеялась на, знаете, статьи с ArXiv об индуктивных склонностях СГС, или ограничениях онлайнового обучения, или единой теории обучения… что угодно из этого века относительно того, что мы узнали из опыта реального построения искусственных разумов.
Думимир: Это как раз одна из многих вещей, которые вы, земляне, отказываетесь понимать. Вы их не строите.
Симплиция: Что?
Думимир: Прогресс способностей, который сейчас выдают исследователи ИИ вашей цивилизации основан не на глубоком понимании мышления, а на совершенствовании общих методов оптимизации, в которые вливается всё больше и больше вычислительных мощностей. Глубинное обучение – не просто не наука, это даже не инженерия, в традиционном смысле: непрозрачность создаваемых артефактов не имеет аналогов среди проектов мостов или двигателей. По сути, вся инженерная работа объектного уровня производится градиентным спуском.
Автогеноцидный маньяк Ричард Саттон назвал это горьким уроком и заявил, что в столь медленном его признании виновато раздутое эго и окостенелость представителей области. Но, в соответствии с наказом в полную ситу чувствовать эмоцию, подходящую ситуации, я думаю, что горечь тут и правда уместна. Вполне осмысленно чувствовать её по поводу недальновидного принятия фундаментально несогласуемой парадигмы из-за того, что она хорошо работает прямо сейчас, тогда как менее безумный мир заметил бы очевидные предсказуемые сложности и скоординировался бы, чтобы сделать Что-то Другое, А Не Это.
Симплиция: Я не думаю, что это самая подходящая интерпретация «горького урока». Саттон отстаивал обобщённые методы, которые масштабируются вместе с вычислительными мощностями, в противоположность вручную закодированным человеческим знаниям. Но это не значит, что мы пребываем в невежестве о том, что эти обобщённые методы делают. Один из примеров Саттона – компьютерные шахматы, где минимакс-поиск с оптимизациями вроде α–β отсечений оказался лучше, чем попытки в явном виде закодировать то, что люди-гроссмейстеры знают об игре. Но ничего страшного. Написание программы, которая думает о тактике как люди, вместо того, чтобы дать тактике появиться из поиска по игровому дереву tree, было бы большей работой ради меньшей выгоды.
Довольно схожая модель применима и к использованию глубинного обучения для аппроксимации сложных функций между разными распределениями данных: мы определяем обучающее распределение, а подробности подстройки под него делегируем подходящей архитектуре сети: свёрточной для изображений, трансформеру для последовательностей варьирующейся длины. Есть много литературы о…
Думимир: Литература не поможет, если авторы из вашей цивилизации не задают вопросы, которые нужно задавать, чтобы не погибнуть. Что, конкретно, я должен узнать из литературы вашего мира? Дайте мне пример.
Симплиция: Я не уверена, какой пример вам нужен. Просто исходя из здравого смысла, кажется, что задача согласования ИИ потребует близкого знакомства с мельчайшими эмпирическими подробностями того, как ИИ работает. Почему вы ожидаете, что можно просто мельком окинуть проблему взглядом из кресла и объявить всё это непосильным, основываясь лишь на аналогии с биологической эволюцией, которая совсем не то же самой, что обучение ML-моделей?
Выбирая наугад… ну, вот, я недавно читала об остаточных сетях. Глубокие нейросети считались тяжёлыми для обучения, потому что градиент слишком быстро менялся относительно ввода. Гиперландшафт потерь формируется в результате многократной композиции функций, из-за этого получался пёстрый фрактал из маленьких горок, а не гладкая поверхность, по которой можно спускаться. Эта проблема смягчается введением «остаточных» связей, которые пропускают некоторые слои и создают короткие пути через сеть с более гладкими градиентами.
Я не понимаю, как вы можете говорить, что это не наука или инженерия. Есть понятное объяснение, почему один проект обрабатывающей информацию системы работает лучше альтернатив. Оно основано на наблюдениях и математических рассуждениях. Есть десятки таких штук. Чего ещё, собственно вы ожидаете от науки, изучающей искусственные разумы?
Думимир: [скептически] Это ваш пример? ResNet?
Симплиция: … да?
Думимир: Согласно закону сохранения ожидаемых свидетельств, я посчитаю то, что у вас не удалось припомнить что-то относящееся к делу, как подтверждение моих взглядов. Я никогда не отрицал, что можно написать кучу диссертаций о подобных трюках, позволяющих сделать обобщённые оптимизаторы эффективнее. Проблема в том, что эти знания приближают нас к способности простым и грубым способом дойти до обобщённого интеллекта, не давая нам при этом знаний об интеллекте. Что за программу все эти градиентные обновления встраивают в вашу сеть? Как она работает?
Симплиция: [с дискомфортом в голосе] Над этим работают.
Думимир: Слишком мало и слишком поздно. Причина, по которой я так часто упоминаю эволюцию людей – это наш единственный пример того, как внешний цикл оптимизации создал внутренний обобщённый интеллект. Уж точно кажется, ваша цивилизация идёт по тому же пути. Да, градиентный спуск отличается от естественного отбора, но я не думаю, что разница имеет отношение к морали аналогии.
Как я уже говорил, понятие приспособленности нигде в наших мотивациях не представлено. То есть внешний критерий оптимизации, по которому отбирала эволюция, создавая нас, нисколько не похож на внутренний критерий оптимизации, который мы используем, выбирая, что делать.
Когда оптимизаторы становятся мощнее, всё, что не ценится функцией полезности в явном виде, не переживает реализацию крайних случаев. Связь между родительской любовью и совокупной приспособленностью в индустриальном окружении стала куда слабее, чем была в окружении эволюционном. Появилось больше возможностей, как люди могут приоритизировать благополучие любимых, не отслеживая частоты аллелей. В трансгуманистической утопии с загрузкой сознания это сломалось бы полностью, мы бы отделили свои разумы от биологического субстрата. Если какой-то другой формат хранения данных подходит нам лучше, то зачем нам придерживаться конкретной молекулы ДНК, о которой до девятнадцатого века никто и не слышал?
Конечно, у нас не будет никакой трансгуманистической утопии с загрузкой сознания, потому что история себя повторит: внешняя функция потерь, которую безумные учёные используют, чтобы вырастить первый СИИ, будет нисколько не похож на внутренние цели получившегося суперинтеллекта.
Симплиция: У вас, кажется, по сути идеологическая убеждённость, что внешнюю оптимизацию нельзя использовать для оформления поведения получающихся внутренних оптимизаторов. Вы не считаете, что «мы обучаем для X и получаем X» – допустимый шаг в предложении по согласованию. Но это, кажется, попросту противоречит опыту. Мы постоянно обучаем глубокие нейросети невероятно конкретным задачам, и это фантастически хорошо работает.
Интуитивно мне хочется сказать, что это работает куда лучше эволюции. Я не представляю, чтобы можно было преуспеть в селективном выведении животного, в совершенстве владеющего английским, как LLM. Немаловажно, что мы можем обучать и обучаем LLM с чистого листа, а селекция работает лишь с чертами, которые уже представлены в популяции, и недостаточно быстра, чтобы собирать новые адаптации с нуля.
Но даже селективное выведение по сути работает. Мы успешно одомашнили верных собак и питательный скот. Если бы мы начали выводить собак ради интеллекта так же, как выводили ради верности и дружелюбия, я ожидаю, что они оставались бы примерно настолько же верными и дружелюбными, когда их интеллект начал бы превосходить наш, и дали бы нам долю собственности в их гиперсобачьей звёздной империи. Не то чтобы это обязательно хорошая идея – я лучше передам мир новому поколению людей, а не новому доминирующему виду, даже если он дружественен. Но ваша позиция, кажется, не «Создание нового доминирующего вида – большая ответственность; нам надо позаботиться о том, чтобы всё получилось в точности правильно». Скорее, вы считаете, что мы вовсе не можем осмысленно повлиять на результат.
Перед антрактом я спросила у вас, как ваш пессимизм по поводу согласования СИИ при помощи обучающих данных сочетается с тем, что глубинное обучение вообще работает. Мой игрушечный пример – результат, в котором исследователи интерпретируемости смогли подтвердить, что обучение на задачах арифметики по остатку привело к тому, что сеть действительно выучила алгоритм сложения по модулю. Вы сказали, что это факт об обучающем распределении, тестовом распределении и оптимизаторе, и для дружественного ИИ это не сработает. Можете это объяснить?
Думимир: [вздыхает] Ну, раз уж надо. Если вы выберете кратчайшую программу, которая без ошибок справляется с арифметикой по модулю p для вводов вплоть до гугола, я предполагаю, что она сработает и для вводов больше гугола, несмотря на то, что есть огромное пространство возможных программ, которые правильно работают до гугола, но неправильно после. В этом смысле я подтверждаю, что обучающие данные могут, как вы выразились, «оформить поведение».
Но это конкретное утверждение о том, что происходит с обучающим распределением «арифметика по модулю с вводами меньше гугола», тестовым распределением «арифметика по модулю с вводами больше гугола» и оптимизатором «перебирать все программы по порядку, пока не найдёте ту, что работает на обучающем распределении». Это не общее утверждение о том, что внутренние оптимизаторы, найденный внешними оптимизаторами, будут хотеть то го же, что оптимистично представляли люди, составлявшие набор обучающих данных.
Опять же, эволюция людей – это наш единственный пример того, как внешняя оптимизация создала обобщённый интеллект. нам известен исторический факт, что первая программа, найденная оптимизатором «жадный локальный поиск посредством мутаций и рекомбинаций» с задачей «оптимизировать совокупную генетическую приспособленность в эволюционном окружении» не обобщилась до оптимизации совокупной генетической приспособленности на тестовом распределении современного мира. Аналогично, ваше утверждение о том, что селективное разведение «в общем-то работает» сталкивается с проблемой каждый раз, когда оно не работает. Например, когда отбор по маленькому размеру подпопуляции насекомых привёл к поеданию чужих личинок, а не к ограничению размножения, или когда отбор в курятнике куриц, которые откладывают больше яиц, привёл к появлению более агрессивных цыплят, которые делают менее продуктивными соседей.
Симплиция: [кивает] Ага-ага. Пока всё понятно.
Думимир: Я вам не верю.. Если бы вам и впрямь было понятно, вы бы заметили, что я только что опроверг наивное ожидание, что внешние оптимизаторы, обучающие при помощи вознаграждения, создадут внутренних оптимизаторов, преследующих это же вознаграждение.
Симплиция: Да, это звучит как очень тупая идея. Если вы когда-нибудь встретите кого-то, кто в это верит, я надеюсь, у вас получится в этом разубедить.
Думимир: [фрустрированно] Если вы не неявно допускаете это наивное ожидание, понимая то или нет, то я не понимаю, почему вы считаете, что «Мы обучаем для X и получаем X» – допустимый шаг в предложении по согласованию.
Симплиция: Это зависит от значения X и значения «обучаем». Как вы и сказали, есть факты о том, какие внешние оптимизаторы и обучающие распределения создают какие внутренние оптимизаторы, и как те, в свою очередь, обобщаются на разные тестовые окружения. И правда, факты не подчиняются выдаче желаемого за действительное: если кто-то рассуждает «Я нажимаю эту кнопку вознаграждения, когда мой ИИ делает хорошие вещи, следовательно, он научится быть хорошим», то его ждёт разочарование, когда выяснится, что система обобщилась до того, что ценит сами нажатия на кнопку (вы бы назвали это провалом внешнего согласования) или любой из многочисленных возможных коррелятов вознаграждения (вы бы назвали это провалом внутреннего согласования).
Думимир: [покровительственным тоном] Пока всё понятно. И почему это не сразу же топит «Мы обучаем для X и получаем X» как допустимый шаг предложения по согласованию?
Симплиция: Потому что я думаю, что возможно совершать предсказания о том, как поведут себя внутренние оптимизаторы и соответствующим образом выбрать план обучения. У меня нет полного описания, как это работает, но я думаю, что полная теория будет куда более подробна, чем, «Либо обучение превращает внешнюю функцию потерь в внутреннюю функцию полезности, в каком случае вы погибаете, либо никак нельзя сказать, что получится, в каком случае вы тоже погибаете». И, думаю, мы можем обрисовать эту более подробную теорию, аккуратно изучив подробности примеров, подобных обсуждаемым нами.
В случае эволюции, можно считать приспособленность определённой как «то, что в итоге отбирается». Можно заявить, что когда фермеры практикуют искусственный отбор, они «на самом деле» не разводят коров по выдаче молока, на самом деле, коров разводят по приспособленности! Если мы применим к Природе те же стандарты, что к фермеру, то скажем, что люди оптимизированы не исключительно для совокупной генетической приспособленности, а оптимизированы для спаривания, охоты, собирательства, заполучения союзников, избегания болезней, и т.д. Если посмотреть так, то взаимосвязь между внешней задачей обучения и мотивациями внутренней модели куда больше похожа на «мы обучаем для X и получаем X», чем считаете вы.
Но, несмотря на это, действительно, решения, которые находит эволюция, могут оказаться неожиданными для селекционера, который не продумал аккуратно, какое именно давление отбора он применяет. Как в ваших примерах неудач искусственного отбора: простейшее изменение насекомого, использующее существующую вариацию для ответа на давление отбора в сторону маленьких подпопуляций будет «каннибализм». Простейшее изменение куриц, помогающее откладывать больше яиц, чем соседние курицы – агрессия.
Думимир: Это такой троллинг, в котором вы соглашаетесь со всеми моими пунктами, а потом делаете вид, что всё ещё каким-то образом несогласны? Я этому и пытался вас научить: решения, которые находит внешняя оптимизация могут быть неожиданными…
Симплиция: …для проектировщика, не обдумавшего тщательно, какие именно давления оптимизации он использует. Ответственное использование внешней оптимизации…
[Doomimir хохочет]
Симплиция: …не кажется непосильной инженерной задачей. И глубинное обучение кажется для её решения куда более перспективным, чем эволюция. Кажущуюся очень слабой связь между понятием совокупной генетической приспособленности и человеческой «тысячей осколков желания» можно рассматривать как проявление редких вознаграждений. Если внешний оптимизатор только измеряет частоту аллелей, но кроме этого никак не отбирает, какие аллели хороши, то простейшее решение – с учётом подразумеваемой априорной склонности естественного отбора к простоте – будет сильно зависеть от кучи случайных деталей эволюционного окружения. Если вы ожидали получить чистого максимизатора копирования ДНК, то это будет неожиданно.
А вот когда мы создаём ИИ-системы, мы можем заставить внешний оптимизатор предоставлять столько указаний, сколько нам хочется. И когда указания расположены плотно, это сильно ограничивает то, какие будут найдены решения. В нашей аналогии получается, что мы можем легко определять мельчайшие детали «эволюционного окружения». Мы можем больше, чем найти программу, которая справляется с простой целью, и принять все её странные стремления, оказавшиеся простейшим способом этой цели достигать. Мы ищем программу, которая аппроксимирует миллиарды пар ввода-вывода, на которых мы её обучили.
Считается, что нейросети вовсе могут обобщать потому, что отображение параметров в функции склоняется в сторону простых функций: в первом приближении обучение эквивалентно байесианским обновлениям на наблюдениях о том, что сеть с случайно инициализированными весами подошла под обучающие данные.
Что касается больших языковых моделей, осмысленной догадкой кажется, что простейшая функция, которая предсказывает следующий токен текста их интернета, это и правда просто предсказатель следующего токена. Не предсказывающий следующий токен консеквенциалист, который завайрхедится просто предсказуемыми токенами, а предсказатель текста из обучающего распределения. Специфичность для распределения, которую вы посчитали провалом внутренней согласованности в случае эволюции людей – не баг, а фича: мы обучали для X и получили X.
Думимир: А затем немедленно подвергли результат обучению с подкреплением.
Симплиция: Так уж получается, что я ещё и не считаю RLHF столь же обречённым, как вы. Ранние теоретические обсуждения согласования ИИ иногда говорили о том, что пойдёт не так, если вы попробуете обучить ИИ при помощи «кнопки вознаграждения». Эти дискуссии имеют философскую ценность. И правда, если бы у вас был гиперкомпьютер, и вы проектировали ИИ посредством грубого поиска простейшей программы, которая приводит к наибольшему числу нажатий на кнопку, то это, полагаю, ничем хорошим не закончилось бы. Отобранный таким образом слабый агент может вести себя так, как вам хочется, но сильный агент найдёт умные способы обмануть вас или промыть вам мозги, чтобы вы нажали на кнопку. Или просто захватит контроль над кнопкой сам. Если бы у нас на самом деле был гиперкомпьютер и мы действительно создавали ИИ таким образом, я была бы в ужасе.
Но, ещё раз, это больше не философская задача. Сейчас, пятнадцатью годами позднее, наши передовые методы имеют что-то общее с грубым поиском, но детали различаются. И детали важны. Реальное RLHF – не то же самое, что неограниченный поиск гиперкомпьютером того, что заставит людей нажать на кнопку поощрения. Оно подкрепляет переходы состояние-действие, которые получали вознаграждение в прошлом, причём зачастую – с ограниченным расстоянием Кульбака–Лейблера от того что было, а для выводов, которые раньше были бы крайне маловероятными, оно очень большое.
Если большая часть битов поиска берутся из предобучения, которое решает задачи, копируя мыслительные шаги, которые использовали бы люди, то немного направления в нужную сторону при помощи обучения с подкреплением не кажется таким опасным, каким оно было бы, если бы напрямую из RL вытекали бы основные способности.
Мне кажется, это довольно хорошо работает? Попросту не кажется таким уж неправдоподобным, что результатом поиска простейшей программы, которая аппроксимирует распределение естественного языка в реальном мире, а потом оптимизирует это для выдачи таких ответов, какие дал бы услужливый, честный и безвредный ассистент будет, ну… услужливый, честный и безвредный ассистент?
Думимир: Конечно будет казаться, что оно довольно хорошо работает! Оно было оптимизировано для того, чтобы хорошо для вас выглядеть!
Симплиция, я был готов попробовать, но я уже совершенно отчаялся, что вы пройдёте это бутылочное горлышко мышления. Вы можете сформулировать, что идёт не так на простейших игрушечных примерах, но всё отказываетесь увидеть, как так восхваляемые вами системы в реальном мире страдают от тех же фундаментальных проблем систематически менее заметным образом. С точки зрения эволюции люди в эволюционном окружении выглядели бы, будто они хорошо справляются с оптимизацией совокупной приспособленности.
Симплиция: А так ли это? Я думаю, что если бы за людьми в эволюционном окружении наблюдали инопланетяне, и они задались бы вопросом, как люди будут себя вести, если обретут технологии, то они бы смогли предсказать, что люди будут стремиться к сексу и сахару, а не к частоте аллелей. Это фактический вопрос, и он не кажется таким уж сложным.
Думимир: Не-безумные инопланетяне, да. Но, в отличие от вас, они были бы способны и предсказать, что языковые модели после RLHF будут стремиться к \<непереводимо-1>, \<непереводимо-2>, и \<непереводимо-3>, а не к тому, чтобы быть услужливыми, безвредными и честными.
Симплиция: Я понимаю, что что-то может поверхностно выглядеть хорошо, но не быть в этом устойчивым. Мы это уже видели на состязательных примерах классификации изображений. Классификаторы, которые хорошо справляются с естественными изображениями, могут выдавать бредятину на изображениях, специально сконструированных, чтобы их обдурить. Это тревожит, потому что означает, что машины на самом деле не видят изображения так же, как мы. Кажется, это похоже на те сценарии рисков, которые беспокоят вас: что полноценный СИИ может и будет казаться согласованным в том узком диапазоне ситуаций, в которых вы его обучили, но на самом деле он всё это время преследовал свои чуждые цели.
Но видно, что в том самом случае классификации изображений у нас есть прогресс. Есть попытаться сконструировать состязательные примеры для классификатора, который сделали более устойчивым посредством состязательного обучения, вы получите примеры, которые влияют и на человеческое восприятие. Если вместо традиционных классификаторов использовать генеративные модели, то их степень искажённости и качество работы за пределами распределения схожи с человеческими. Можно ещё вмешиваться не в ввод сети, а в её внутреннее состояние, и так защититься от непредвиденных неудач…
Полагаю, вас ничто из этого не впечатляет, но почему? Почему это не считается за постепенный прогресс в внедрении в машины человекоподобного поведения, за постепенный прогресс в согласовании?
Думимир: Подумайте об этом с точки зрения теории информации. Если для будущего, в котором мы выживаем, требуется указать в целях одиночного СИИ 100 бит, то вам понадобится точность, позволяющая попасть в эту трилионную трилионной трилионной части пространства целей. Эмприческая работа по машинному обучению, которая вас так впечатляет, не на пути, который даст нам такую точность. Я не отрицаю, что ценой больших усилий вы можете подтолкнуть непонятные матрицы к принятию поведения, кажущегося более человеческим. Это может дать вам пару бит, а может и не дать.
Это неважно. Это как пытаться восстановить потерянную пьесу Шекспира, обучая марковский генератор на существующих текстах. Да, у этого намного большая вероятность успеха, чем у случайной программы. Эта вероятность всё равно почти ноль.
Симплиция: Хм, возможно, камень преткновения между нами в том, в насколько крохотную цель надо попасть, чтобы реализовать сколько ценности будущего. Я принимаю тезис ортогональности, но мне всё ещё кажется, что задача, которая перед нами стоит, не такое «всё-или-ничего», как описываете вы, а более прощающая неточность. Если вы можете реконструировать правдоподобную аппроксимацию потерянной пьесы, насколько важно, что она не восстановлена в точности верно? Было бы интересно дальше обсудить…
Думимир: Нет. Ваша мать дала вам подходящее имя. Не вижу толка в тщетных попытках обучать необучаемых.
Симплиция: Но если миру всё равно конец?
Думимир: Ну, полагаю, так можно убить немного времени.
Симплиция: [зрителям] До скорого!