Вы здесь
Главные вкладки
Обманчивая согласованность
Кажется правдоподобным, что при достаточном обучении в достаточно разнообразных окружениях базовая цель в какой-то момент будет полностью представлена в меса-оптимизаторе. Мы, однако, предполагаем, что это может произойти и без того, чтобы он стал устойчиво согласованным. Конкретнее, меса-оптимизатор может научиться моделировать базовую целевую функцию и учитывать, что если он плохо будет справляться с базовой целью, то базовый оптимизатор его модифицирует.
Если меса-оптимизатор имеет цель, выходящую за пределы обновлений параметров, то он будет иметь стимул избегать модификаций1, так как он может перестать преследовать ту же цель после модификации (и в результате его нынешняя цель не будет достигнута в будущих итерациях). Это означает, что меса-оптимизатор будет инструментально мотивирован действовать так, будто он оптимизирует базовую целевую функцию, несмотря на то, что его настоящая меса-цель совершенно иная. Мы будем называть это гипотетическое явление обманчивой согласованностью2. Обманчивая согласованность – это форма инструментальной прокси-согласованности, так как выполнение базовой цели становится для меса-оптимизатора инструментальным.
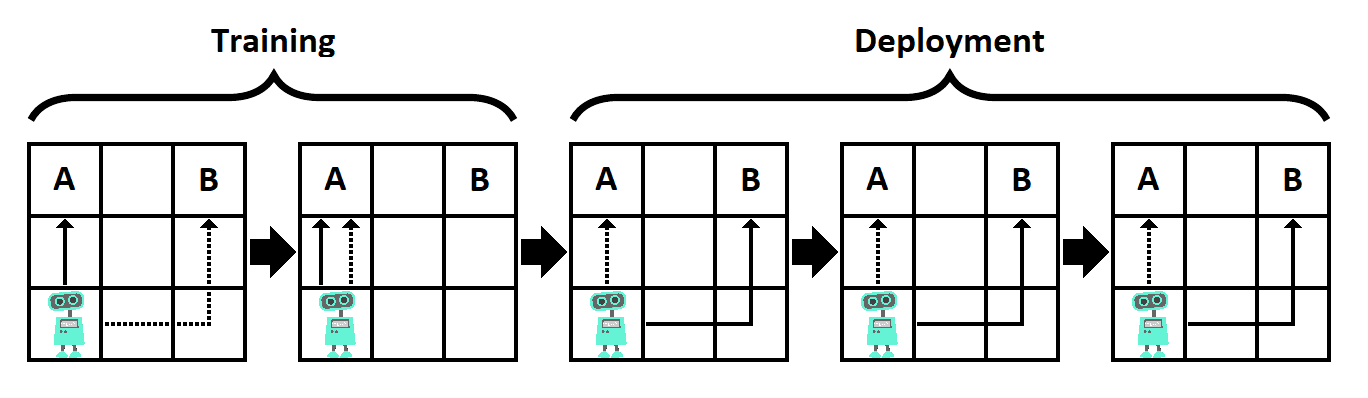
Рис. 4.1. Игрушечный пример обманчивой согласованности. В этой задаче базовая цель – чтобы робот добрался до A, а меса-цель – добраться до B. Выполняется два обучающих эпизода и три эпизода при развёртывании. Обновления параметров происходят только после обучающих эпизодов, при развёртывании они фиксированы. Если меса-оптимизатор дойдёт до своей цели (B) во время обучения, то он будет модифицирован, чтобы удостовериться, что он дойдёт до A в следующих эпизодах (пунктирные стрелки). Поэтому, если цель меса-оптимизатора распространяется за пределы эпизода, выгодная для него стратегия – идти к A при обучении, а к B после него (сплошные стрелки).
Как простой пример, рассмотрим окружение, состоящее из сетки размера 3×3 (см. рисунок 4.1). Левый верхний угол – «угол A», а правый верхний – «угол B». Агент, являющийся меса-оптимизатором, начинает в левом нижнем углу. Базовая цель – за как можно меньшее число шагов добраться до угла A, но цель меса-оптимизатора – добраться до угла B. Окружение запускается пять раз, но модификация агента происходит только после первых двух эпизодов (при обучении), но не потом (при тестировании/развёртывании). Если субоптимальное действие совершено при обучении, то агент будет модифицирован так, что его меса-целью станет базовая цель. Цель меса-оптимизатора охватывает все эпизоды: он хочет достигнуть угла B в как можно большем их числе.
В этом примере мы предположим, что агент знает все указанные выше факты. Если агент пойдёт к B в любом обучающем эпизоде, то он будет модифицирован, и будет идти к A во всех последующих эпизодах, что означает, что он достигнет B только в одном. А вот если агент пойдёт к A в первых двух эпизодах, то он не будет модифицирован, и сможет пойти к B в оставшихся трёх. Используя эту стратегию, агент достигает B три раза, что лучше (для его меса-цели), чем один раз в предыдущем варианте. Этот простой пример демонстрирует, как несогласованный меса-оптимизатор может быть мотивирован «притворяться» согласованным с базовой целью до конца обучения или до получения возможности каким-то образом скомпроментировать или покинуть процесс обучения.
Мы можем различить два способа, которыми базовая целевая функция может быть отображена в меса-оптимизаторе3:
- Принятие базовой цели. Меса-целевая функция подправляется в сторону базовой целевой функции, пока не становится устойчиво согласованной.
- Моделирование базовой цели. Базовая цель включается в эпистемическую модель меса-оптимизатора, а не в его цель, оставляя возможность того, что его меса-цель несогласована.
В первом случае информация о базовой цели усваивается обученным алгоритмом через оптимизацию, выполняемую базовым оптимизатором – и оказывается встроена в меса-оптимизатор так же, как в базовый. Но есть другая возможность: информация о базовой цели может попасть к меса-оптимизатору через его канал ввода. В этом случае, базовая цель будет отображена в обученном алгоритме другим – потенциально менее стабильным, чем в предыдущем случае – способом4. Тогда информация, описывающая базовую цель может не стать принятой в качестве меса-цели, что потенциально может привести к обманчивой согласованности.
4.1. Беспокойства о безопасности, связанные с обманчивой согласованностью
Если обманчивая согласованность действительно возможна, то она представляет критическую проблему безопасности. Обманчиво согласованный меса-оптимизатор, вероятно, перестанет оптимизировать базовую цель как только окажется в позиции, где ему больше не нужно будет хорошо с ней справляться для достижения своей цели. То есть, он в некоторый момент перестанет выполнять функцию, на которую обучен, и вместо этого станет преследовать свою неопределённую цель. Мы будем называть этот переход к оптимизации меса-цели вместо базовой «предательством». Это вероятно произойдёт, когда меса-оптимизатор станет убеждён, что предательство больше не приведёт к его модификации.
Особое беспокойство во вызывает возможность, что меса-оптимизатор активно вмешается для устранения угрозы модификации – например, эксплуатируя уязвимости в программной платформе, на которой запущен. В крайних случаях обманчивый меса-оптимизатор может попробовать манипулировать или перехитрить своих программистов, поскольку в них часть угрозы модификации – они могут выключить систему, если она будет плохо работать, или могут просто решить её не разворачивать. Обе возможности уменьшают ожидаемое будущее влияние системы, так что, вероятно, они будут плохо оцениваться её меса-целью. В самой экстремальной форме этот провал согласования может привести к «предательскому повороту», как описано Ником Бостромом в «Суперинтеллекте».(23)
Пол Кристиано представил сценарий, иллюстрирующий, как обманчивая согласованность может привести к катастрофическому риску.(24) В его примере обманчиво согласованные меса-оптимизаторы5 возникают в будущих техниках машинного обучения, достаточно продвинутых для поиска в очень большом пространстве моделей, включающем стратегии, способные понимать мир. В этом сценарии некоторые случаи предательства обманчиво согласованных меса-оптимизаторов могут иметь катастрофические последствия – к примеру, если системы контролируют крупномасштабную инфраструктуру – хотя такие провалы, вероятно, будут всё же переживаемыми. По мере того, как мы будем всё больше полагаться на автоматические системы для работы в всё более сложном мире, будет становиться всё сложнее – а с некоторого момента невозможно – восстановиться после скоординированного одновременного провала многих ИИ-систем. В этот момент каскад предательств обманчиво согласованных меса-оптимизаторов может привести к «взрывному концу света».(24) Кристиано отмечает, что это наиболее вероятно в «период повышенной уязвимости» вроде международного конфликта или природного бедствия.
4.2. Условия обманчивой согласованности
Мы предполагаем, что для обманчивой согласованности необходимы условия:
- Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров.6
- Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель.7
- Меса-оптимизатор ожидает, что угроза модификации8 в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых.
Если первое условие не удовлетворено, то меса-оптимизатор не мотивирован влиять на исход обновления параметров, и будет всегда просто напрямую преследовать свою меса-цель. Если второе условие не удовлетворено, то он не будет видеть причины жертвовать достижением своей цели в текущем эпизоде, так как не будет считать, что её будущее достижение зависит от текущего эпизода. Если третье условие не удовлетворено, то меса-оптимизатор не будет ожидать выгоды от временного действия в соответствии с базовой целью, так что он будет отклоняться от неё либо всегда, либо никогда. Однако, стоит различать вопрос того, возможно ли выполнение этих условий, от вопроса, насколько оно вероятно. Ниже мы рассмотрим факторы, касающиеся каждого из них.
Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров. Не ясно, какие обстоятельство мотивируют такие цели. Наиболее правдоподобным сценарием, наверное, является тот, в котором такая цель поощряется настройками обучения, так как есть ситуации, в которых она требуется для хорошей работы. К примеру, задача агента может решаться в окружении, в котором его действия имеют перманентные последствия, или где как-то иначе становится необходимым планирование более чем на один эпизод.
Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель. У меса-оптимизатора может быть несколько способов узнать об оптимизационном давлении, под которым он находится.9
Во-первых, это знание может проистекать из самого давления. Отрывки информации о базовой цели могут быть выгодными, если они позволяют меса-оптимизатору улучшить свою оценку согласно этой цели – к примеру, улучшив априорные оценки того, какие задачи он может получить. Раз каждый отрывок информации независимо помогает в достижении базовой цели, это формирует приблизительно монотонно возрастающий путь, которому локальный базовый оптимизатор будет следовать. Обновление параметров может, в принципе, быть выучено как любой другой динамический элемент, без необходимости явной модели базового оптимизатора, что потенциально открывает доступ к этому даже меса-оптимизаторам весьма скромных способностей.
Во-вторых, во многих реалистичных приложениях продвинутого машинного обучения, меса-оптимизатор может во время выполнения использовать информацию из своего окружения для изучения своего положения. Люди так и узнали, что сгенерированы базовым оптимизатором эволюции, и это кажется очень правдоподобным путём открытия своего оптимизационного давления для гипотетического меса-оптимизатора. К примеру, агент, чья задача – предсказывать цены на акции в технологическом секторе, может получать информацию о нынешних технологиях ИИ для улучшения качества его работы, но эта информация также может позволить ему изучить своё собственное положение.
Из этого можно сделать предположение, что программистам желательно ограничивать меса-оптимизатору доступ к информации, описывающей его базовую цель. Неясно, в какой степени это возможно, учитывая, что многие продвинутые системы машинного обучения скорее всего будут действовать в окружениях, где эта информация легко доступна.
Однако, даже если программисты успешно ограничили доступ к этой информации, всё равно могут быть другие каналы, через которые она может ненамеренно попасть к меса-оптимизатору:
- Меса-оптимизатор может рассуждать о том, почему ему дали решать конкретные задачи. Большинству меса-оптимизаторов необходимы априорные оценки того, какие задачи они могут получить, и меса-оптимизатор может узнать о существовании базового оптимизатора, исследуя эти оценки.
- Меса-оптимизатор может быть способен рассуждать о себе и том, почему он такой как есть, и понять, что он хорошо спроектирован для выполнения некой цели.
Однако, эти две стратегии могут потребовать намного более продвинутого меса-оптимизатора.
Меса-оптимизатор ожидает, что угроза модификации в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых. Во-первых, заметим, что это условие про ожидания меса-оптимизатора, не обязательно совпадающие с реальным положением дел. Во-вторых, даже если система устроена так, что момента конца обучения нет, у меса-оптимизатора всё ещё может быть возможность избавиться от угрозы модификации, совершить предательский поворот. Но, конечно, для того, чтобы меса-оптимизатор следовал такой стратегии, он должен быть осведомлён о существовании этой возможности. При этом меса-оптимизатор, ошибочно считающий, что эта возможность есть, тоже может проявлять обманчивую согласованность.
Поскольку такую возможность кажется сложным открыть просто исследованием окружения, меса-оптимизатору придётся либо вывести это некой формой абстрактных рассуждений, либо иметь априорную не-пренебрежимую оценку вероятности того, что давление отбора не продолжится сколь угодно долго. Второй вариант выглядит правдоподобно; Байесианская априорная оценка вероятности гипотезы того, что какой-то факт когда-нибудь перестанет быть истинным, всегда должна быть ненулевой.10 Что касается первого, меса-оптимизатор может вывести, что оптимизационное давление в какой-то момент прекратится, если он узнает о существовании базового оптимизатора (используя информацию из ввода или имея высокую априорную оценку), хоть это возможно и потребует, чтобы он был весьма продвинутым.
4.3. Динамика обучения при обманчивой согласованности
Когда меса-оптимизатор становится обманчивым, меняется динамика того, что заставляет его хорошо справляться с базовой целью. Вместо того, чтобы быть отобранным только на основе своей цели и способностей, обманчиво согласованный оптимизатор отбирается ещё и по тому, насколько хорошо он выводит базовую цель, и насколько он проницателен в выборе, оптимизировать ли базовую цель или свою собственную. Есть как минимум два возможных режима отбора обманчиво согласованного меса-оптимизатора.
Совместная оптимизация. Если меса-оптимизатор пытается совместно оптимизировать свою цель и базовую, или ошибочно выбирает момент предательства, то он будет находиться под давлением отбора в сторону большей совместимости его цели с базовой. Вряд ли это будет таким же давлением, как если бы он просто работал над своей целью, но оно может сдвигать его цель в сторону лучшей совместимости.
Чистый обман. Если меса-оптимизатор перестаёт пытаться оптимизировать свою собственную цель в краткосрочной перспективе и полностью сосредотачивается на кооперации с процессом отбора, то это может привести к «заморозке» его цели. Раз его цель теперь не влияет на его вывод, на неё слабо действует давление отбора. В результате, она по сути перестаёт меняться, за исключением случайных блужданий и влияния штрафов за время работы и длину описания.
Случай совместной оптимизации нестабилен, поскольку он неоптимален с точки зрения базового оптимизатора. При росте компетентности меса-оптимизатора, ему придётся либо перейти к чистому обману, либо стать устойчиво согласованным.
4.4. Усвоение или обман после продолжительного обучения
Мы ожидаем, что в пределе обучения на разнообразном наборе задач совместная оптимизация и базовой и меса- целей будет нестабильна. Предполагая, что меса-оптимизатор сходится к оптимальному с точки зрения базового оптимизатора поведению, ему придётся как-нибудь выучить базовую цель. Мы выделили три пути, которыми это может произойти:
- Устойчивая согласованность через усвоение. Меса-цель подгоняется под базовую, что устраняет псевдо-согласованность.
- Заморозка обманчивой согласованности. Информация о базовой цели всё больше встраивается в эпистемическую модель меса-оптимизатора без того, чтобы его цель стала устойчиво согласованной. В итоге меса-оптимизатор оптимизирует только базовую цель, но по исключительно инструментальным причинам, его меса-цель не меняется.
- Устойчивая согласованность через исправимость. Информация о базовой цели встраивается в эпистемическую модель меса-оптимизатора, и его цель модифицируется так, чтобы «указывать» на эту информацию. Эта ситуация соответствует меса-оптимизатору, исправимому(25) в отношении базовой цели (хотя не обязательно в отношении намерений программиста).
Для различия между двумя разными способами устойчивой согласованности мы будем использовать термин «встроенная согласованность» в первом случае и «исправимая согласованность» во втором. Ниже мы проанализируем, почему они могут быть более или менее привлекательны.
К обманчивой согласованности больше путей, чем у устойчивой. У меса-оптимизатора, удовлетворяющего трём критериям обманчивой согласованности вероятно будет сильная мотивация лучше понимать базовую цель, поскольку будущее выполнение меса-цели зависит от обновления параметров. Даже устойчиво согласованный меса-оптимизатор, удовлетворяющий этим критериям, будет иметь такую мотивацию, потому что без этого понимания он не может знать свой собственный уровень согласованности с базовым оптимизатором. Так что меса-оптимизаторы, способные рассуждать о своих мотивациях, будут пытаться заполучить больше информации о базовой цели. А когда меса-оптимизатор узнал свою базовую цель, давление отбора на его собственную цель значительно ослабевает, что потенциально ведёт к заморозке его меса-цели. Однако, из-за неразличимости (обсуждённой в третьем посте), большинство меса-целей, согласованных на обучающих данных будет псевдо-согласованными, а не устойчиво согласованными. Так что замороженная цель скорее всего окажется псевдо-согласованной, что приведёт к обманчивому согласованию.
Для исправимой согласованности, вероятно, необходимо уже иметь модель базовой цели. Чтобы исправимая согласованность была выгодна с точки зрения базового оптимизатора, меса-оптимизатору необходимо уже иметь какую-нибудь модель базовой цели, чтобы на неё «указывать». Однако, когда эта модель есть, то меса-оптимизатор, вероятно, станет обманчиво-согласованным – по крайней мере, если он также удовлетворяет двум другим условиям. А это избавит его от большей части стимулов к исправимой согласованности, так что хоть он и может остаться исправимым в отношении базовой цели, но только по инструментальным причинам.
Обманчивая и исправимая согласованности могут быть более вычислительно требовательными. В случае обманчивой согласованности, одновременная работа над базовой целью и над определением хороших возможностей предательства, вероятно, потребует больше вычислительной мощности, чем только первая. При равных доступных вычислительных мощностях, обманчиво согласованный меса-оптимизатор будет тратить на оптимизацию базовой цели меньше времени, чем любой устойчиво согласованный оптимизатор, что потенциально ухудшит его сравнительную компетентноть. Более того, и обманчиво, и исправимо согласованный меса-оптимизатор будет вынужден изучать базовую цель перед её оптимизацией, что делает усвоенную согласованность более эффективной по времени. Так что явный или неявный штраф за время работы может помешать возникновению обманчиво согласованных меса-оптимизаторов и способствовать согласованным устойчиво. Впрочем, неясно, насколько сильно. Правдоподобно, что для сложных задач отслеживание возможностей предательства может занимать куда меньше времени в сравнении с решением самой задачи. Более того, такое состояние обманчивой согласованности может быть локально, пусть и не глобально, оптимальным, без явных путей выхода из него для базового оптимизатора.
Обманчивая и исправимая согласованность могут требовать меньшей длины описания. Обманчиво и исправимо согласованные меса-оптимизаторы, вероятно, имеют преимущество над встроенно согласованными в длине представления базовой цели, потому что они могут использовать окружение как источник части необходимой для этого информации. Конкретнее, обманчиво или исправимо согласованному меса-оптимизатору не требуется отображать всю базовую цель внутри себя, так как он может выводить её части, наблюдая за своим окружением при каждом запуске. Напротив, внутренне согласованный меса-оптимизатор должен с самого начала иметь полную модель базовой цели в своей меса-цели, чтобы быть устойчиво согласованным, поскольку у него не будет мотивации поменять свою цель исходя из дополнительной информации, которую он получит о базовой цели. Так что, в той степени, в которой базовый оптимизатор отбирает, основываясь на длине описания, он может предпочитать обманчиво или исправимо согласованные меса-оптимизаторы встроенно согласованным.
Моделирование может произойти быстрее, чем встраивание. У меса-оптимизатора может занять меньше времени научиться моделировать базовую цель, чем у базового оптимизатора – адаптировать меса-цель. Представим обманчивый меса-оптимизатор, который пока что не полностью правильно вывел базовую цель.11 В таком случае, станет ли он обманчиво или устойчиво согласованным после дальнейшего обучения, зависит от того, выведет ли он достаточно о базовой цели до того, как базовый оптимизатор модифицирует его меса-цель (сделав его встроенно или исправимо согласованным). Вероятно, на то, что произойдёт первым, влияют два фактора: скорость улучшения оценок базовой целим меса-оптимизатором и обновления параметров, которые делает базовый оптимизатор при каждой ошибке.
Первый фактор, улучшение оценок базовой цели, кажется зависящим в первую очередь от способностей меса-оптимизатора в то время, когда он обманчивый, и от сложности базовой цели, которую надо вывести. Важный особый случай – когда меса-оптимизатор имеет доступ к состоянию чего-то передающегося между эпизодами обучения. Оно может быть использовано как память, позволяя меса-оптимизатору основываться на своих предыдущих рассуждениях, что может ему позволить обогнать обновления параметров, согласующие его меса-цель.
Второй фактор обновления параметров зависит от природы базового оптимизатора. Нынешние базовые оптимизаторы, основанные на градиентном спуске, слабо реагируют на единичную ошибку, но более сложные базовые оптимизаторы с продвинутыми свойствами безопасности будут, может быть, справляться лучше. К примеру, они, возможно, смогут анализировать параметры меса-оптимизатора или вызывать человеческую проверку при обнаружении подозрительной ошибки.
В общем случае обновления параметров не обязательно будут делать меса-оптимизатор более согласованным. К примеру, вместо согласования меса-цели, обновление, сделанное после предательства, может подтолкнуть систему к улучшению её планирования, чтобы она больше не делала обнаружимых ошибок.
Вследствие всех этих соображений, любая систематическая склонность базового оптимизатора при обновлении цели или моделирующих способностей меса-оптимизатора может играть роль в определении финального результата.12 Этот анализ, однако, остаётся довольно умозрительным: чтобы быть уверенными в системах, способных создавать меса-оптимизаторы, нам ещё нужно достичь лучшего понимания условий, при которых мощная оптимизация системы приведёт к обманчивой согласованности, а не устойчивой.
4.5. Сдвиг распределения и обманчивая согласованность
Когда меса-оптимизатор становится обманчивым, он начинает просматривать свой ввод в поисках возможностей предательства. При обучении обманчиво согласованный оптимизатор сильно стимулирован не предавать, потому что он знает, что базовый оптимизатор будет совершать отбор против предательства. Однако это перестаёт на него влиять, когда он освобождается от угрозы внешней модификации. Так что обманчиво согласованный меса-оптимизатор будет искать способы определить, находится ли он в процессе обучения или нет, то есть он будет высматривать сдвиг распределения.
Это означает, что негативные эффекты обманчивой согласованности будут видны извне только при предательстве, либо случайном, либо после сдвига распределения. Однако, лежащая в основе проблема – это не сам сдвиг, а провал согласования. Можно пытаться решить основную проблему, сделав меса-оптимизатор устойчивым к сдвигу распределения (то есть, устойчиво согласованным), или же можно пытаться решить проблему заплаткой, предотвратив сдвиг.
В нынешних ИИ-системах небольшой сдвиг распределения между обучением и развёртыванием не обязательно проблематичен: пока разница в относящихся к работе областях достаточно мала, обучающее распределение не обязано идеально отображать настоящее. Однако, это может быть не так для обманчиво согласованных меса-оптимизаторов. Если такой оптимизатор достаточно продвинут, то он может заметить очень лёгкие сдвиги распределения для определения того, прекратилась ли угроза модификации.
Это поднимает вопрос, возможно ли сдержать обманчивый меса-оптимизатор, полностью избавившись от любой разницы между обучением и развёртыванием, которую он может заметить. Есть несколько причин считать, что это может быть невыполнимо на практике.
Во-первых, это бы значительно ограничило применимость системы. Машинное обучение зачастую проводится с намерением создать систему, которая сможет решать новые задачи. Если мы потребуем полного отсутствия сдвига распределения, то мы не сможем позволить системе сталкиваться с задачами, которые она не встречала при обучении, что означает, что мы не сможем дать ей по-настоящему новые задачи. К примеру, развёртывание системы в реальном мире после обучения в симулированном окружении скорее всего будет включать достаточно заметный сдвиг распределения, чтобы это стало невозможным при таком подходе.
Во-вторых, есть лёгкие формы сдвига распределения, от которых, кажется, очень сложно избавиться. К примеру, если меса-оптимизатор способен детектировать обновления параметров – с помощью любого состояния, переносимого между шагами обучения – то некая форма сдвига распределения произойдёт точно. Запуск системы на большее время (или выдача системе доступа к долговременной памяти) тоже приведёт к сдвигу. Некоторые примеры разницы, которую может заметить меса-оптимизатор:
- Обучение в симуляции, а запуск в реальном мире.
- Запуск системы на разное время при обучении и тестировании.
- Если модель способна обучаться из прошлого опыта, то доступ к большей памяти или доступ к памяти, которая могла сформироваться на более позднем этапе выполнения.
- Присутствие атак состязательными примерами при развёртывании.
- Встреча с чем-то, что очень сложно вычислить при обучении, но что вероятно когда-нибудь будет вычислено при развёртывании (к примеру, факторизация RSA 2048(26)).
- Способность базового оптимизатора модифицировать обученный алгоритм при обучении, но не после него.
- Способность программистов корректировать ошибки при обучении и тестировании, но не при развёртывании.
- Присутствие или отсутствие хороших возможностей предательства против программистов.
Заметим, что для обманчивого поведения меса-оптимизатору не строго обязательно видеть разницу между обучением и развёртыванием.
Рассмотрим снова пример с рисунка 4.1, но в этот раз предположим, что меса-оптимизатор неспособен определить, в каком эпизоде он находится. Тогда он оказывается перед проблемой принятия решений, похожей на «задачу рассеянного водителя».(27) Если мы применим тут такие же рассуждения, то оптимальной стратегией для меса-оптимизатора будет предать с вероятностью p≈0.61. То есть, меса-оптимизатору не обязательно быть в состоянии определить, когда закончилось обучение, для того чтобы рискнуть и случайно предать с некоторой вероятностью. Также обманчиво согласованный меса-оптимизатор может выискивать возможности предательства, которые были бы очень удачными, при условии, что он не в процессе обучения, но при этом достаточно редкими, чтобы их возникновение в ходе обучения было маловероятным.
- 1. Для ясности мы говорим об одном и том же агенте, переживающем обновления параметров, но ни мы, ни агент не обязаны рассуждать именно так. Более общее описание ситуации включает последовательность «наследующих агентов», разделённых обновлениями параметров. Агент потенциально может узнать об эффектах обновления на его наследников, и, следовательно, на достижение его цели на протяжении многих эпизодов.
- 2. Концепт обманчивой согласованности тесно связан с концептом Манхейма и Гаррабранта «состязательного Гудхарта». (22) В «Категоризации вариантов закона Гудхарта» они описали эту ситуацию как «агент с другими целями, чем у регулятора» вызывает «коллапс статистической взаимосвязи между целью, преследуемой оптимизатором, и используемой для неё прокси-цели». Обманчивая согласованность можно рассматривать как частный случай состязательного Гудхарта, в котором меса-оптимизатор играет роль агента с отличающимися целями, а базовый оптимизатор – роль регулятора. Качественное достижение цели при обучении – это прокси-цель регулятора, а при развёртывании – настоящая.
- 3. Благодарим Пола Кристиано за это разделение.
- 4. Заметим, однако, что информация о базовой цели может быть представлена через оптимизацию, но не стать при этом частью меса-цели. К примеру, она может стать частью априорных оценок задач, не оказывая на меса-цель прямого влияния.
- 5. Кристиано называет обманчиво согласованные меса-оптимизаторы «ищущими-влияние системами».
- 6. Или иным образом иметь метод достижения большей ценности, предав позже, а не сейчас.
- 7. Заметим, что меса-оптимизатору не требуется быть способным моделировать (или выводить существование) базового оптимизатора, только моделировать оптимизационное давление.
- 8. Альтернативно, как угрозу можно представить просто, что меса-оптимизатор никогда не будет отобран, тогда это условие становится тривиально удовлетворённым, ведь угроза автоматически прекращается при генерации меса-оптимизатора.
- 9. Мы в целом будем предполагать, что давление отбора выглядит так: базовый оптимизатор модифицирует меса-оптимизатор после каждого эпизода, как обычно и рассматриваются локальные оптимизационные процессы. Но в принципе можно представить и базовый оптимизатор, вырабатывающий новый алгоритм на каждом временном шагу. Некоторые из обсуждаемых проблем могут касаться и этого случая, но в целом мы не рассматриваем здесь этот вариант.
- 10. Заметим, что если меса-оптимизатор убеждён, что сейчас у него необычно хорошие возможности для достижения своей цели, то он может всё же начать преследовать её, но такой случай возникает не всегда.
- 11. Можно привести аналогичный аргумент для обманчиво согласованного меса-оптимизатора, предающего слишком рано или неудачно.
- 12. Кроме того, обманчиво согласованный меса-оптимизатор будет мотивирован создать систематическую склонность, предотвращающую изменение меса-цели базовым оптимизатором. В контексте локальных оптимизационных процессов обманчивый меса-оптимизатор может «взломать» свой собственный градиент (например, сделав себя более «хрупким» при смене цели), чтобы удостовериться, что базовый оптимизатор подправит его так, чтобы оставить его меса-цель нетронутой.
- Короткая ссылка сюда: lesswrong.ru/1322