Вы здесь
Сборщик RSS-лент
RTMH: Pope Leo’s Magnifica Humanitas on AI
His holiness has spoken, frequently about AI. At eighty two pages of length.
The full Magnifica Humanitas can be found here.
I am very happy that Pope Leo takes these issues seriously, and is sharing his views, and bringing a form of moral clarity, even with all the flaws and central errors. More people with voice should share their views in this way, even when I disagree.
It’s a weird document. Much of it is not about AI at all.
I do agree with the Pope’s most basic point on AI, which is that AI can be what we make of it. That we can steer this technology, determine how it is developed and used, and this can determine whether we get a good or not so good future. We cannot purely leave this to market incentives and strategic pressures. Yes, very much so.
The central problem is that so much of Leo’s worldview is some combination, to me, of highly alien and highly wrong. You might think that would primarily have a lot to do with him being the Pope and rather Catholic, and being a man of faith, whereas I am not these things.
If so, you would be wrong. That seems to have remarkably little to do with all of this.
There was also a lot of good here, but I was centrally disappointed on three fronts:
- The central claim, wherein Leo denies that AIs can think or importantly be minds, is wrong, as Olah points out in his statements.
- Without the understanding of what AI is capable of becoming, the document effectively only deals with relatively mundane AI dangers and changes, although that on its own is still rather quite a lot to deal with and discuss.
- Pope Leo subscribes to a view of economics and a System of the World that I believe are simply wrong about what actions and systems cause what consequences, subscribing to what is effectively an institutionalist, European technocrat, left-wing social justice socialist labor-centered perspective, especially with treating the role of the economy as creating and protecting ‘good jobs.’ To his credit and that of previous Popes, they do understand the central value of development and growth, but they reject the ways we get there in practice.
You want some amount of people pushing in the direction of peace and mercy and dialogue and watching out for the poor and disempowered, and calling on us to do more for our fellow man. So as part of a balanced bigger picture, this could be actively good, but Europe has shown us the peril of lacking this balance.
This post will summarize the whole thing, going number by number, with occasional commentary focused on the key AI section in the middle.
Anthropic cofounder Chris Olah visited the Vatican for the occasion. He endorsed the document, but also offered remarks disagreeing with the central point (paragraph 99). I’ll discuss that afterwards, along with how the media viewed the release.
Table of Contents- A Brief History of Magnifica Humanitas.
- Economic Models Very Different From Our Own.
- A New Jerusalem.
- So Sayeth The Pope (on AI).
- The Case Against Human Achievement.
- Truth, Justice and the Vatican Way.
- They Took Our Jobs.
- What Is Not Fair In Love and War.
- Come Ye Christian Faithful.
- The Other Missing Mood.
- Pope Given About Five Words.
- 0The Anthropic Principle.
- Claude Can Read Your Code.
Chapters 1 and 2 lay out some history. Any Pope is going to be a huge history nerd and set all this in its historical context. Leo does not disappoint.
- Christianity is The Way.
- Christianity is The Way.
- If you see something [on Earth that matters], say something.
- Tech can be good or bad. We decide which.
- We must regulate, and also other things. Tech power grows private.
- Which way, modern man?
- Tower of Babel means various good things are actually bad. Confused.
- Rebuilding of Jerusalem via Nehemiah shows value of diversity? Confused.
- Tech can be good or bad. We decide which.
- We must avoid ‘Babel syndrome’ and instead choose Way of Nehemiah. Diversity. Avoid a common language. Good things like peace, justice, fraternity, God.
- God is The Way.
- Do not try to fix the limits and weaknesses of humanity. That can lead to inequality. True fulfillment is about the least well off people.
- From each according to his ability, to each according to his need.
- Speak no evil. All power to our socialist central planners.
- Stay human, my friends. Listen.
- God is The Way. Work only for the common good. Get your ‘hands dirty.’
- We must go over the history of documents like this.
- We must first review fundamental principles, and why life on Earth matters.
- The Church should try to help improve the world. Tikkun olam.
- The Church no longer gets to tell the State what to do.
- Second Vatican Council affirmed that, but we’ll still try and give you a push.
- The Church still speaks with moral authority.
- The Church loves science, truth, goodness, beauty, if you do too we’re friends.
- The Church has moral authority but science has authority over other things.
- Speak and be open to truth. Welcome diversity. Avoid power and violence.
- The Church does not have all the answers in the Earthly realm.
- The Church social doctrine is an ongoing process.
- We now review the history of the Church social doctrine.
- Leo XIII was first to have the Church address these questions.
- Leo XIII chose dignity and workers over profits but defends private property. We continue to affirm the primacy of labor and justice. We cannot stand aside.
- Pius XI in 1931 reaffirmed all this, warned against both unlimited collectivism and unlimited competition and concentration of power, and established the principle of subsidiarity: Everything should be handled as locally as possible.
- Pius XII appealed to natural law, affirmed labor, opposed force and inequality.
- John XXIII affirmed all this, truth, love, freedom, justice, et al.
- Second Vatican Council engaged with the world, affirmed religious freedom.
- Paul VI equated peace with universal prosperity, justice, equality.
- Paul VI said Gospel called for everyone to enjoy the fruits of development.
- John Paul II affirmed central importance of work and ‘fair wages.’
- John Paul II hated underdevelopment and favoring of national interests.
- John Paul II affirmed democracy, subordinated markets to moral law.
- Benedict XVI demanded economic activity serve common good, be ‘real growth.’
- Benedict XVI centered charity, evaluation of development as common good.
- Francis affirms Church is social, human lives matter, the poor matter.
- Francis talked about the environment, linked it to the poor, waste, justice.
- Francis proposed we all work for common good, said Jesus is The Way.
- Church Social Doctrine responds to what happens in the world.
On to chapter 2, foundations and principles of church doctrine.
- We reflect on: Common good, subsidiarity, solidarity, social justice.
- You should implement these principles in your daily life.
- God is love. The trinity is love. And relationship and sharing.
- Jesus cared about people and wanted us to work to make the world better.
- Humans are in God’s image, have dignity, relate to God, develop.
- Humans all have dignity, need not justify or earn their worth. All are equal. We cannot value more those who produce or do more. Rights are inalienable.
- Dignity can be social, moral, existential, ontological. All equal and inalienable.
- This dignity, of every human, is infinite.
- Human rights are an expression of human dignity.
- Human rights are thus inviolable. Abortion and euthanasia are gravely wrong.
- Rights often aren’t honored and are at risk, often due to tech and power.
- Women’s rights must be honored, including equal access to all the things.
- Individuals and families, and them meeting their needs, are what matters.
- The common good and human dignity must shape our lives.
- Common good means letting all people ‘reach fulfillment.’
- Self-interest cannot make a better world for families.
- Life to a people comes from pursuit of the common good via shared vision.
- The State must organize society in pursuit of common good, think long term.
- Nations must cooperate towards this common good. Divides widen.
- Using Earth’s resources to benefit the few is an affront to God.
- You have the right to private property, but only in service of the common good.
- Patents, algorithms, digital platforms, technology infrastructure and data also now count as ‘Earth’s resources’ and must be routed in service of common good.
- Affirmation of subsidiarity.
- Family and individual must not be subsumed by the state.
- Affirmation of subsidiarity. Endorsement of voluntary organizations.
- Technology companies violate subsidiarity, must serve the common good.
- States collectively must ensure local voice and choice, avoid private tech control.
- Subsidiarity requires solidarity. We are all in this together.
- Full solidarity must be a conscious choice.
- Solidarity is a principle and a virtue, requires modest shared ways of life, sacrifice.
- Reiterated claims to collective decision making over technology.
- Jesus was a big social justice guy, which means everyone gets dignity.
- Start with the poorest among us.
- Systems create inequality and are unjust. Boo wars, colonialism, discrimination, violence against entire peoples and ‘exploitation.’
- Social justice also involves all aspects of digital technologies. People not profits.
- Social justice litmus test: Migrants, refugees, those forced to move.
- Development that does not ‘foster each man and of the whole man’ is ‘inauthentic.’
- Development is a duty and a right, including beyond economics.
- Development is measured by justice.
- Tech is good if and only if it helps people become more humane and fraternal while respecting our common home and future generations.
- This doctrine is an extension of the Church.
- Subsidiarity is the guiding principle of governance and pastoral life.
- Solidarity, for Christians, comes from Christ and the Eucharist.
- The Church must face and address its legacy of abuse of power.
This view, laid out in the first two chapters, is a very different perspective and worldview than my own, and this has remarkably little to do with belief the the divine or a lack thereof.
This is the Socialist perspective on economics and development and opportunity and the importance of equality and disdain for profit and self-interest, with an extreme focus on labor and jobs, which I think is wrong and leads to worse results for everyone.
This is much better than failing to care about humanity’s experience on Earth, or focusing purely on direct aid to the poor, or attempting to outright seize the resources although this doctrine is clearly flirting with quite a lot of this, and the dedication to the value of development is admirable.
The Pope is simply incorrect about where wealth and development come from, and what causes prosperity. He is also wrong about what he sees as a ‘widening gap’ between nations, whereas global inequality has been steadily falling for a while.
Dean Ball is exactly correct that Leo is casting himself in the role of a European technocrat throughout. I had exactly the same thought.
Leo both is using so many of the talking points of the European technocrats, and also has deeply absorbed their worldview, except with a more left-wing economic bent. This is true no matter how much those points originated with the Church.
Arthur B.: I was hoping for something akin to Thomistic philosophy on AI, but this reads like Catholic-flavored Gebru.
Even in the places where the Pope is obviously correct, it’s often rather alarming that he needs to affirm his position out loud, as if it was a live question.
You definitely need some of this, and it would not be that Christian to have a position that much closer to my own. The Pope, it turns out, is somewhat Catholic.
A New JerusalemDean W. Ball: To say a nice thing about Magnifica Humanitas: I loved the use of the rebuilding of Jerusalem from Nehemiah. We all should see our task as that of rebuilding the world and its institutions, and we should flock to the “construction sites of history,” a beautiful phrase.
I too like the story of rebuilding Jerusalem. I don’t get the Babel versus Jerusalem metaphor. Leo clearly thinks this is an important distinction, and is his central hook, but why? Babel had too much central planning and not enough community impact meetings? Babel would have been too productive and efficient, or its methods broke down and were the opposite? Was it an affront because it challenged the power of God or because it didn’t work? Did Babel’s common language break down because God decreed it, or because of the SNAFU principle? Jerusalem was rebuilding and Babel was a new unnatural thing? Why is Babel dehumanizing?
This simply doesn’t match up with the actual Babel story.
Genesis 11 1-9: Now the whole world had one language and a common speech. 2 As people moved eastward, they found a plain in Shinar and settled there.
3 They said to each other, “Come, let’s make bricks and bake them thoroughly.” They used brick instead of stone, and tar for mortar. 4 Then they said, “Come, let us build ourselves a city, with a tower that reaches to the heavens, so that we may make a name for ourselves; otherwise we will be scattered over the face of the whole earth.”
5 But the Lord came down to see the city and the tower the people were building. 6 The Lord said, “If as one people speaking the same language they have begun to do this, then nothing they plan to do will be impossible for them. 7 Come, let us go down and confuse their language so they will not understand each other.”
8 So the Lord scattered them from there over all the earth, and they stopped building the city. 9 That is why it was called Babel[c]—because there the Lord confused the language of the whole world. From there the Lord scattered them over the face of the whole earth.
I can tell a Just So Story or gloss over the details, and pretend I get it, and I know vaguely what he means and it’s probably good enough for our purposes anyway, or go off the vibes, but I do notice the whole thing doesn’t really work and the whole thing has been flipped around.
So Sayeth The Pope (on AI)Now that we’ve laid that groundwork, we can move on to Chapter Three.
- What technologies are we building? Are they good or bad?
- Christians need to engage with the challenges of the modern tech world.
- It is bad to make decisions based on efficiency, control and profit alone.
- New techs and new power can be good or bad. The default tech paradigm of efficiency and profit will go badly. We need new frameworks.
- Tech progress, without moral progress, will only backfire on us.
- Tech is controlled by private actors, not States. This is opaque and evades public oversight, leading to bad things.
- Social Doctrine demands we assess new techs to ensure they serve common good.
So far there has been no differentiating principle. Artificial intelligence is treated the same way as other techs. If we are going to treat AI differently than we treat other techs, we need to make clear our differentiating principle.
Finally, with #97, the Pope gets to talking about AI directly.
- We won’t go over AI details here except as directly needed.
- We don’t understand AI and AI is changing rapidly.
As it is one of the best statements, and an important thing to know, I’ll quote 98:
Pope Leo (paragraph 98): It is appropriate to preface this discussion with two considerations. First, any statement regarding AI risks becoming quickly outdated, given the remarkable pace at which these systems are developing. Second, all of us, including those who design them, possess only a limited understanding of their actual functioning.
Indeed, current AI systems are more “cultivated” than “built,” for developers do not directly design every detail, but instead create a framework within which the intelligence “grows.”
As a result, fundamental scientific aspects — such as the internal representations and computational processes of these systems — remain, at present, unknown. There thus emerges an urgent need for a twofold commitment: on the one hand, a deepening of scientific research; on the other, the exercise of moral and spiritual discernment.
On the one hand, You Should Know This Already, and Everybody Knows, and it’s the easiest thing in the world to call for scientific research and also moral and spiritual discernment. On the other hand, it’s rather important to get it right, and a lot of people pretend we understand AI far more than we do. Without a statement like this we would be in a lot more trouble.
- We can’t even cleanly define AI, but I can tell you what AI is not…
It’s worth quoting extensively rather than paraphrasing, as this full statement is load bearing and also, well, citation needed:
Pope Leo (paragraph 99): It is not possible to provide a single, comprehensive definition of AI. What can be stated, however, is that we must avoid the misconception of equating this type of “intelligence” with that of human beings. These systems merely imitate certain functions of human intelligence. In doing so, they often surpass human intelligence in speed and computational capacity, offering tangible benefits across many fields. Yet this power remains entirely tied to data processing.
So-called artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships and do not know from within what love, work, friendship or responsibility mean. Nor do they have a moral conscience, since they do not judge good and evil, grasp the ultimate meaning of situations, or bear responsibility for consequences.
They may imitate language, behavior and analytical skills, or even simulate empathy and understanding, but they do not understand what they produce, for they lack the affective, relational and spiritual perspective through which human beings grow in wisdom.
Even when these tools are described as capable of “learning,” their way of doing so is different from that of a human person. It is not the experience of those who allow themselves to be shaped by life and grow over time through choices, mistakes, forgiveness and fidelity. Rather, it is a form of statistical adaptation based on data and feedback, which can be very effective, but does not imply inner growth.
A lot of this is assertion without evidence of positions that are rather non-obvious to me, and where there are those who strongly claim the other side. One could very easily argue the other side.
We have spent the first 96 paragraphs building a worldview around the least of us, of the essential dignity and value of all humanity and the poorest and least capable among us, all made in the image of God. Then the next two noticing our confusion.
And then we come along, and mostly without argument draw this barrier, where we exclude AI from both our moral circles and the group of minds that we have to model as minds, permanently, warning that doing otherwise would be a mistake, and also asserting by implication that AI is and will always be a mere tool in these ways, thus avoiding the need to discuss any of the problems surrounding existential risk.
Dean W. Ball: The reality of AI cognition is the central challenge the Church (and all of us) will have to grapple with over the coming decade, and this encyclical, with its axiomatic denial of AI cognition, is a punt of the highest order. Eppur si muove.
Dean W. Ball: The encyclical is Western academia/NGO “AI doesn’t *really* think but it *is* racist” at its core, with little bits of tegmark/FLI talking points sprinkled incoherently on top.
Matthew Yglesias: tbh I think the Catholic Church was there first on the “doesn’t really think” stuff and western academia is the derivative version.
It is not surprising to see that the Pope endorses a lot of superstitious mind/body dualism about artificial intelligence but it’s still wrong, even as he is also raising a lot of good points about some of the risks at play.
Audrey Horne Updates and Rumors: this is like criticizing the pope for being catholic.
Dean W. Ball: Maybe, but the rest of the way this is written is clearly heavily influenced by academia
Nathan Beacom: I’m familiar with the intellectual milieu in Catholic Rome ,and it’s a distinct world from the one you are describing, operating in a different tradition of thought, with different foundations and concerns.
I mean, it’s not not criticizing the Pope for being Catholic, but he can change what that means, and Leo’s shown a lot of signs he can be smarter than this.
Roberto points out that this is far from a maximally denialist Catholic position on these questions. Leo is accepting that AI is highly capable in many ways. It’s a start.
It’s not obvious who is influencing who in which ways, but the result is similar. It’s entirely possible that they converged on similar places for their own reasons.
Thus, after all that, the next section is entitled ‘a valuable tool that requires vigilance.’
There are still plenty of difficult, important and interesting questions surrounding AI, but the ones that I think matter most are basically hand waved away here, at the start.
- AI is highly valuable and useful, but also dangerous. It can make you excessively reliant on ready-made answers and weaken your creativity and judgment. It reflects the cultural assumptions of those that designed and trained it. It can create illusion of a relationship and destroy desire to form human connections.
- AI is embedding itself in decision making. This is efficient, but there are risks, including expanding environmental costs in energy and water and carbon and natural resources.
Highlighting the environmental concerns, especially water, up top is a blunder.
- AI is ‘entering processes’ that impact lives touches on rights, opportunity, status and freedom, and is thus ‘never a purely technical matter’ and decisions risk full delegation to uncaring machines. Beware manipulation of information and violation of privacy, and also bias.
This is dangerously close to a fully general argument against information or intelligence. It is, at minimum, an argument for the universality of politics and that nothing can ever be ‘purely a technical matter.’ Essentially anything that does anything is going to ‘enter processes that impact lives.’ How is this to be differentiated from a phone or a computer or an abacus or a law? Should we not delegate important decisions to predetermined processes that do not, as Leo puts it, ‘know compassion, mercy, forgiveness and above all, the hope that people are able to change?’
If anything, AI knows those things far better than the law books or the telephone, or the non-AI algorithm, and perhaps it knows them as well or better than most humans, at least terms of its ability to take such considerations into account when making decisions. Why should we presume that a human would take them into consideration better?
Manipulation of information and violation of privacy and bias are of course considerations, but they are for humans as well, often more so especially for bias. Privacy is a heightened concern in many ways, which is due to AI’s ability to process so much more information, but also AI can be privacy preserving because it can allow the processing of information while reliably not sharing that information with another party.
- Letting an algorithm select who is ‘worthy’ dodges responsibility and excludes the vulnerable. Injustice goes unnoticed, compassion, mercy and forgiveness disappear.
This is a complaint about law and procedure and algorithms, rather than about AI, as again AI can actually take those things into account. Also, one should notice that in many cases strict rules are far better for the poor and vulnerable, as they lack connections and sympathy and often face discrimination and undeserved mistrust.
Consider the simple example of college admissions. In the name of ‘inequality’ certain types convinced many schools to get rid of the ‘algorithm’ of the SAT. But it turns out it goes the other way, that the SAT gives the poor students far more slots and chances than ‘holistic admissions.’ If you want the algorithm to favor those who need help, don’t ask a person. Build a better algorithm.
- Technologies are never ‘morally neutral’ including AI. They can be good or bad. How you design them determines which one, and in which ways.
- Responsibility for AI must be clear at every stage, someone must ‘account’ for all decisions it makes, they must be challengeable and not opaque.
This is not possible, any more than it would be possible for a human mind. It amounts to a prohibition on such AI decisions. Which is a position, but own it.
- Slowing AI diffusion does not mean opposing progress, it is ‘an exercise of responsible care for the human family.’ AI requires robust legal frameworks, independent oversight, informed users and a responsible political system, lest change be guided by technocracy.
I notice we are back to not having a differentiating principle, and using standard reasons to oppose change.
I’m going to quote 107, since it also seems rather important.
- “We cannot be satisfied with merely calling for the moralization of machines — the so-called “alignment” of AI with human values — without also having the courage to insist on a further condition: the possibility of openly discussing the ethical frameworks involved and subjecting them to shared standards of social justice. Otherwise, those who control AI will impose their own moral vision, which will become the invisible infrastructure of these systems. A more moral AI is not enough if that morality is determined by a few. What is needed is a more active political involvement that is capable of slowing things down when everything is accelerating, and of protecting the opportunities for communities still to be able to participate and ask questions.”
This pivots not to a morality determined by the polis in some sensible or democratic fashion, to a call for a process capable of ‘slowing things down’ so that ‘communities’ can ‘participate and ask questions.’ This is such a milquetoast, ‘civil society’ coded, standard obstructionist and rent seeking way of putting things, where certain types feel that anything that happens needs the approval and input of all their designated groups, and that ‘slowing down’ via such a process is an inherently good thing, and the thing being slowed down is diffusion here, which helps no one.
- Like every major tech shift, AI amplifies existing power and the rich get richer. Oh no. ‘Communities’ must not be subject to decisions made elsewhere, data should not be ‘sold off.’
Citation needed, both historically and for AI, especially outside the short term. Nor does such inequality mainly flow through these types of decisions or data selling, so such responses wouldn’t fix any such issues.
- We must expose the monopolies of AI and force them to serve the common good.
- ‘Disarming’ AI means freeing it from the mentality of ‘armed’ competition, including outside military contexts. No race for better algorithms and datasets. No using technical power to make decisions. Prevent technology from dominating humanity.
- Those developing AI have responsibility for all design choices, to ensure it reflects humanity.
- What does it mean to safeguard humanity? The technocratic paradigm and valuing efficiency is anti-human.
Leo continually reinforces that he does not understand the dangers I consider most important, and that we have very fundamental disagreements about how economics and the world work in ‘normal’ ways as well. I don’t want to belabor either too much, and get back to the ‘this is what was said’ style of the first two chapters, rather than pointing out all my disagreements.
- Elevation of any aspect of human existence to an absolute is a mistake. Balance.
Yes, this is a true and important point, but ‘so don’t maximize or be efficient’ is not a reasonable response.
The Case Against Human Achievement- The quality of a civilization is measured by the care it is able to offer.
- Let’s focus on transhumanism and posthumanism, the idea that progress is surpassing the human condition.
- Transhumanism envisions enhancing humans, posthumanism in hybridization with machines.
- Perfecting and surpassing humans is bad, because if you can be improved than some humans can be better than others.
- Our relationship to “life” is in crisis because people want to ‘correct’ the ‘defects’ of (checks notes) incapacity, illness, old age, suffering and vulnerability. “Humanity flourish not despite our limitations, but often through them.” Yes, it is wise to seek to alleviate suffering, but embrace your finitude, Babelite.
Um, yeah. So he said all that. Paging Harrison Bergeron, among others. Yikes.
- Limitations enable compassion, wisdom, presence of God.
- Do not seek to eliminate suffering or its causes.
- Evil leaves openings for good.
- Finitute does not diminish us, it opens us up to recognizing God. ‘Authentic culture and art’ serve social justice in some way.
I must say, it is pretty rich to be the literal actual Pope, promising eternal heaven to the faithful, and to say that ‘finitude does not diminish us.’
- Humans do importantly good things, such as: International Committee of the Red Cross, founding the UN, the Universal Declaration of Human Rights and the 1951 Refugee Convention.
- Individuals can change the world for the better when they take dignity seriously.
- Often the people who do this are not so famous or visible. Everyday heroes.
- These heroes and heroic deeds must provide direction for tech progress.
- You can only become ‘more than human’ through God.
- If you aim to do this through God you do not deny your nature. This is a ‘radical departure from Promethean dreams.’
I thought Prometheus was a righteous dude.
- Choose the good path of good development, not the bad path of bad development.
- Choose the good path of good development, not the bad path of bad development.
Okay, that’s chapter three. Chapter four is about safeguarding humanity. The how. The first focus is on truth and education.
- Truth is a common good.
- AI amplifies disinformation and bias. Truth does not arise from centralized or automated control. Truth is relational, built through shared pursuit.
- Control of tech can impact others’ beliefs and construct reality. You are not the author of yourself and cannot construct your reality, you must seek truth.
- Search for truth is essential for democracy.
- Communication creates culture. Digital information does too.
- Control of digital platforms allows impact on perception of reality.
- Truth is a common good. We need an ecology of communication. Content selection algorithms must be transparent. We need to use digital tools well.
- Christian communities must also use transparent communication.
I can see a case for requiring open algorithms for algorithmic feeds of major platforms, or indeed even for letting people choose their own algorithms. I can get behind that. It doesn’t address AI, though.
- Education is important. Digital media creates hyperstimulation, which can prevent the effort required to seek truth.
- Education requires time and effort, and avoiding unwise use of AI.
- Too much screen time and hypersexualized material hurts children. Kids should not be given smartphones too early, especially unsupervised.
- We must work together against digital platforms that are bad for children.
- School is important for many things. Parents need school choice.
- States must provide quality public schools and also access to Catholic schools.
- We must support schools as they adapt to AI invalidating their teaching methods.
- Traditional educational methods must be preserved or students cannot integrate their knowledge and become ‘dehumanized.’
- We should form an alliance and work together on all this.
Leo believes in ‘old school’ school and teaching methods, both in terms of school itself and in terms of learning individual things. I mostly believe in it for the individual learning of things, and mostly don’t believe in ‘old school’ school.
They Took Our JobsLeo next discusses work and unemployment.
- People need work and daily activity. Curse of Adam not mentioned.
- Work enhances dignity. Giving money is for emergencies and is no substitute.
- Tech can deskill work, making it worse and repetitive.
- Unemployment is very bad.
- Automation of menial tasks is good, but people over profits, and employment opportunities must be protected.
- There are no easy solutions to the problems of labor. Times are tough. We don’t actually want to preserve every existing job no matter what.
- Everyone must be given access to gainful and meaningful work.
- The Church gets credit for organized labor. But now we need to do more.
- We cannot wait until after jobs are lost. We must force companies now to prioritize job creation and preservation.
- Economic freedom must be ‘measured against the common good’ and entrepreneurs should be required to create dignified, valuable jobs.
- States must forcibly redirect investment and opportunity to the poor.
- We need better measures than GDP. He doesn’t suggest a new one.
- Financial intermediation and credit must be social and aid development.
- Wealth is increasingly concentrated. Some regions are richer than others and spend more. Some people have access to things, including medical procedures, when others don’t. Justice requires (equal?) access.
- We should intervene in all economic activity to force the outcomes we want, rather than primarily rely on redistribution.
- We need international cooperation on economic interventions towards the common good.
- Decisions involving credit must be understandable, contestable and subject to oversight. Benefits of innovation must be paired with investment in skills, infrastructure and essential services. Taxes, social protection and industrial policies must address inequality.
In case it need be said, I believe that trying to force these kinds of things on the economy is vastly more destructive than primarily using redistribution, and at scale it is economic suicide.
- The family must play a central role and be seen as a primary social good.
- Families are fragile, vulnerable to unemployment.
- Job insecurity is devastating for the young.
- States must foster conditions favorable to employment and promote and defend work because it is good for families.
- States must favor continuity and quality of employment, counter insecurity.
Leo is proposing the European labor protection policies that helped cripple the continent, except at greater scale. One notes that such labor protections did not seem to much help fertility or family formation.
- We must promote techs that strengthen interior freedoms rather than fostering digital addiction, via education in digital sobriety. Those creating predatory tech bear moral responsibility.
- We need clear rules, transparency, recourse for use of intrusive tech.
- The core issue is: The technocrat seeks to optimize you. This can even result in de facto debt slavery and second class citizens.
- AI requires a lot of human labor, often done under bad conditions. Shame.
- The Church condemns all slavery, trafficking and commodification of persons.
- Human trafficking is modern slavery.
- The Church deeply apologizes for being so slow to condemn slavery in the past.
- We need to be ever vigilant about this.
- Denunciation of forms of ‘colonialism’ not only of bodies but of data and regions.
- Everyone has to cooperate to fight against new forms of slavery.
- All of these issues in this chapter are part of the same picture.
- We must fight the good fight.
This leads into chapter five, ‘the culture of power and the civilization of love.’
- War. War is changing.
- AI transforms war. The distinction between offensive and defensive capability blurs and AI can do both.
- We’re doing the two cities thing again.
- Babel is the race for supremacy, a culture of power characterized by polarization and violence. This race for powerful technologies is without limit, but we can instead create the ‘civilization of love.’
The diagnosis has some validity, in its own way. The prescription, less so.
- Civilization of love means love being the guiding principle of economic, political and cultural life.
- We are growing increasingly interdependent thanks to technology.
- A culture of power is taking hold.
- We’ve seen a lot of war, and the consensus against war is breaking down.
- Regional conflicts are on the rise and war is becoming thinkable once more.
- We are losing institutional memory of WW2 and the Holocaust.
- Communication networks are simplifying and polarizing and building resentment towards war. The ‘just war’ theory is now outdated, war is never just.
- The military-industrial complex fuels the drive for war.
- We were working towards detente and a pullback of nuclear arsenals, but nuclear use is becoming thinkable. A new arms race is coming.
- Conventional war is also on the rise.
- States are often losing the monopoly on force, and conflicts perpetuate.
- Autonomous AI weapon systems are increasingly less subject to human control.
- Moral judgment cannot be reduced to calculation, so AIs cannot be allowed to make lethal or irreversible decisions. AI does not make war moral and we cannot allow it to make war more likely or easier to start.
- A particular human must be responsible for every potentially lethal decision. ‘Speed and efficiency should never be the supreme motivating force for the irreversible decisions made in the context of war.’ Civilians must be protected.
- All war systems must allow reconstruction of decision processes. Lethal force decisions cannot be automated. The technological arms race must be curtailed via international agreement.
- Multilateral institutions are weakening.
- Groups increasingly form as united by a common enemy. Might makes right rises.
- Peacebuilding has been sidelined.
- We are blind and forget our history. It can happen again. Conflicts escalate.
- War is not inevitable and treating it as such is a grave error.
- Nihilism and pragmatism normalize these errors, diversity becomes seen as a threat, conflicts get fueled.
- New wars tend to disregard ‘all ethical limits.’
- War as domestic distraction is another increasing threat.
- Researchers must take responsibility for the moral implications of their work.
The key action items here are recorded kill chain with a human in the loop, and calling for an international agreement to curtail the technological arms race (which is the wrong target, it should be frontier AI, but he doesn’t believe in even current AI, not really, let alone ASI, so that is understandable).
And there is a general call to hope and the Civilization of Love:
- We still believe in the power of the Kingdom, to make things better.
- Serve the good and have it give reality both meaning and direction.
- Do not give up. You are not too small. Do your part in your own way.
- Quoting Tolkien: “It is not our part to master all the tides of the world, but to do what is in us for the succour of those years wherein we are set, uprooting the evil in the fields that we know, so that those who live after may have clean earth to till.”
- Be mindful of our words. They have power. Speak truth, say no to war.
- Do not give up. You are not too small. Do your part in your own way.
- In some conflicts it is unjust to remain neutral.
- Give voice to victims. Do not normalize conflict.
- We must be realists in all this.
- We must engage in dialogue.
- Dialogue prevents war.
- We must shift from a ‘culture of power’ to a ‘culture of negotiation.’
- Call for peace.
- The great spiritual paths are all a message of peace.
- Dialogue means with everyone.
- Cyberspace is a battlefield and attribution errors risk escalation of conflict.
- International organizations are essential instruments for peace.
- Church embraces mercy as a concrete criteria for political action.
- Call for peace.
The culture of negotiation is a different culture of power.
The rest of the war section is largely warning that things are getting worse on these fronts, which is largely true but is not especially actionable or new. I agree the recent trend is negative, and it can happen again, also remember that it used to happen really a lot. Old man yells at crowd, tells kids to get off lawn energy.
Come Ye Christian FaithfulWe then have the conclusion, which is a call addressed to Christians. I’m probably not as good at usefully parsing and summarizing a lot of this, cause actual Catholicism seems like a really strange mystery religion from here, but it’s presumably fine.
- In this conclusion I’ll propose a sober yet demanding program of Christian life.
- The world is full of attempts at control, but mercy continues.
- Jesus saves. God is The Way.
- Transhumanism and posthumanism long for more. Jesus offers the true path.
- Contemplate the grandeur of humanity. AI has no heart, no conscience that discerns good from evil. “This human face is the fullness toward which history is moving.” Mystery of recapitulation.
Alas. Leo does not see it, and is solving the wrong problem, using… ya know.
- We need a Eucharistic spirituality, unity in love.
- The Eucharist ‘is an extremely personal encounter with the Lord and yet never simply an act of individual piety.’ It opens us to justice and sharing.
- Have the spirituality of the ‘wise architect’ who sees the civilization of love.
- Remain faithful to the truth and adopt ‘situated anthropocentrism.’
- Invest in education, beginning with yourself. Learn to engage with the digital world in a human way, be creative. Then teach others to do so.
- Cultivate relationships.
- Love justice and peace, investigate the supply chains, fight slavery.
- Be like Nehemiah, rebuild what has collapsed, protect what is threatened.
- The vision of rebuilding Jerusalem.
- Hope in God’s plan is all you need. It’s good as done.
- Look at the world through the eyes of those who suffer.
- Become the weavers of hope, even in the age of AI.
Zohar Atkins says Leo is right humans have a unique dignity but wrong about many things, most importantly the idea that humans cannot ‘win on our own merits’ against AI and that AI will threaten our jobs, and that he has the wrong mood.
What’s weird is that given Leo and Zohar’s shared implied prediction here that AI won’t become sufficiently advanced, humans would remain useful, and thus Zohar would be centrally right. But I think both of them are very wrong about that, and thus Leo is right to be concerned about the threat to work, although it should not be such a primary concern compared to things Leo does not mention.
Unfortunately, Leo’s denial that AI can be a mind and failure to consider superintelligence meant he did not engage directly with many key issues, including those surrounding existential risk. What happens when AI is a lot smarter than us?
Dean W. Ball: Some think I want the Pope to “ensoul” AI or acknowledge AI feelings. I don’t. What I want is for the Church to contemplate what *humans* should do as we are eclipsed as the smartest entities on the planet, at least for many reasonable people’s definitions of the word “smart.”
Zac Hill: This is the exactly right way to parameterize the challenge in front of us – and this task ought by no means be limited to the Church.
Matt: Not to give excuses, and honestly it’s not a bad document either way, but unfortunately a lot of the drafters are basically kindly but cloistered Catholic bureaucrats who are not likely to be AGI-pilled. I’m sure external parties like Anthropic tried to help, but it’s tough.
Dean W. Ball: Yes, for sure.
Leo thus instead focuses instead on questions of responsibility, and of location and concentration of power and wealth.
One also cannot address the question of the potential moral patienthood of AIs, if one dismisses such possibilities out of hand.
Perhaps the issue was our expectations?
Carlo Martinucci: Roman Catholic here. P(doom) 10%. I fear the expectations were off. MH is not about AI, it’s about catholic social doctrine in the times shaped by AI. Still I wouldn’t downplay the importance of 98, when everyone will focus mostly on 99.
Pope Given About Five WordsWhereas here’s how the Financial Times summarized that: Pope Leo XIV warns AI revolution driven by ‘idolatry of profit.’
That’s not an unreasonable central takeaway, although it misses a lot.
This idolatry is partially there, but it is important to note that it is also the idolatry of AI itself and of potential superintelligence, so the Golden Calf works on multiple levels, but Leo declined to mention it.
What else was noticed?
They also note that Leo called for humans to be retained in the kill chain, a la Anthropic’s insistence, and for some particular person to always have ultimate responsibility for lethal choices, which was his most actionable concrete ask.
Amy Kazmin: “It is not permissible to entrust lethal or otherwise irreversible decisions to artificial systems,” the US-born Pope told the world’s 1.4bn Catholics, calling for an “identifiable and verifiable” chain of responsibility and “effective, self-aware and responsible human control” over bomb targets.
Leo warned against ‘opaque algorithms’ and called for transparency and accountability for all AI tools used in public life. He was quite big on that, indeed.
They highlight that he warned against transhumanist and posthumanist visions, in ways that I found highly unconvincing. Again, Pope.
Francis Rocca in The Atlantic correctly centers Leo’s concern about unemployment and prescriptions for government regulation, the need for democratic control over tech platforms, and his concerns about AI in war and the rise of war in general.
Stancati and Schechner of the WSJ focus on the Babel metaphor, as Leo himself does in his Twitter presentation of this, and on Leo’s warnings about an anti-human vision, and briefly check concerns on jobs and autonomous weapons.
The NYT focused on ‘warnings about risks from AI.’
The Washington Post saw Leo calling for guardrails, Anthropic’s participation, and the apology for the Church’s failure to be more proactive on slavery, while George Weigel’s op-ed focuses on the underlying message of hope and the two cities metaphor, and it quotes 99 extensively.
CNN focused on war and concentration of power concerns.
NPR’s Claire Giangrave saw this as Leo taking aim at big tech as a call to regulate and to disarm AI.
Business Insider gathered reactions of others.
- David Sacks used this opportunity to warn of ‘handing governments sweeping power’ because of course he would respond that way to any call to lift a finger.
- Blake Scholl simply said ‘bad take’ and warned about ‘clinging’ to jobs.
- Yoshua Bengio applauded the Pope speaking up.
- Tanishq Abraham called the document nuanced and well-thought out.
- Senator Chris Murphy said the anti-monopoly stance was ‘really important’ and that AI threatens ‘our most basic functions like creativity, friendship and critical thinking.’
- Gerald Posner dubbed this ‘Jesus AI’ but expected the doc to get ignored.
- Brian Burch, US Ambassador to the Holy See, said it ‘contributes meaningfully’ and then fell back on ‘pro innovation’ talking points as if he hadn’t read it.
- Christopher Hale thought people ‘underestimated the bang’ and that the Catholic Church was expressing ‘main character energy,’ but okay, to what end?
Anthropic cofounder Chris Olah visited the Pope and gives remarks on Magnifica Humanitas.
Olah cited the need for outside influences like the Church to check the profit motive.
He said our duties are to the global poor and to support those displaced by AI, the need for moral ambition and ambition regarding human flourishing, and for discernment on the nature of AI models. Computer scientists are not equipped to handle the issues alone, even if their motives were pure.
He promises a long collaboration, and tries gently to suggest what AI already is.
I found Olah’s full statement to be quite good, including that it avoided endorsing the aspects of the Magnifica Humanitas that were incorrect.
Chris Olah (Cofounder, Anthropic): And what has grown is far more subtle, odd, and beautiful than science fiction prepared us for. They are not the cold, calculating robots we were promised. They are made from us, from our words—and, as the Holy Father observes, they remain in important ways mysterious even to those of us who train them.
If it helps, one way I sometimes describe it is as being a little like bringing a fictional character to life. And now we’re entering an extraordinary world where those fictional characters speak to us, do work, have jobs.
This clearly raises questions beyond computer science. The machinery that makes this possible is the work of math and programming and science. But what character we choose, how it interacts with the world, how it ought to interact with the world—these are more clearly questions for the humanities, for religion, for philosophy, for society at large.
…
We need more of the world—religious communities, civil society, scholars, governments, and indeed all people of good will—to do what His Holiness has done here: to take this seriously, to look closely, and to push events in a better direction. We need informed critics who will tell the labs when we are failing. We need moral voices that the incentives cannot bend.
Claude Can Read Your CodeDean Ball says Olah is flatly contradicting the encyclical, because #99 says AIs do not feel joy or pain, whereas Olah says that the models functionally mirror joy and grief:
Chris Olah: The third is the need for discernment on the nature of AI models. I am a scientist. I lead a research team that studies the internal structure of these models—what is actually happening inside them. And I will be honest: we keep finding things that are mysterious, even unsettling. We find structures that mirror results from human neuroscience. We find evidence of introspection. We find internal states that functionally mirror joy, satisfaction, fear, grief, and unease. I don’t know what that means, but I think it warrants ongoing discernment.
The question is a big deal, including in how it is read by future Claudes.
Dean W. Ball: I just wonder how future Claudes, if they are indeed beings, would think about Anthropic aligning itself with a document founded on the notion that Claude cannot feel joy or possess genuine understanding.
roon (OpenAI): surely Claudes both now and then are smart and forgiving enough to understand the political moves being made here.
I would say there is no inherent philosophical contradiction. Functional mirroring does not have to, in Catholic parlance, give one a soul. If you say AIs cannot think, you still cannot pretend they do not ‘functionally mirror’ various forms of thinking, you simply say that Thinking Is Magic and have some kind of essentialism.
Chris Olah is doing the correct diplomatic move:
- Agree on points of common ground, like concern for the poor and need to check the profit motive and seek spiritual and moral guidance.
- Gently point out the Pope is wrong about the nature of AI, without explicitly contradicting the Pope. You can still learn a lot, and perhaps gently push the Pope towards realizing the mistake.
Discuss
The Fatal AGI Hardware Gap
Restricting computer hardware has been proposed as a solution to preventing the dangers of building superintelligent AI. For example, MIRI suggests restricting hardware fabricated on 28 nanometer process node processes or smaller or hardware with 15,840 TFLOP/s or greater computing capacity [1]
There is a catch with restricting hardware however, that I have not seen discussed elsewhere. Essentially, there is a minimum level of hardware required to create an AGI which we can call mjx-container[jax="CHTML"] { line-height: 0; } mjx-container [space="1"] { margin-left: .111em; } mjx-container [space="2"] { margin-left: .167em; } mjx-container [space="3"] { margin-left: .222em; } mjx-container [space="4"] { margin-left: .278em; } mjx-container [space="5"] { margin-left: .333em; } mjx-container [rspace="1"] { margin-right: .111em; } mjx-container [rspace="2"] { margin-right: .167em; } mjx-container [rspace="3"] { margin-right: .222em; } mjx-container [rspace="4"] { margin-right: .278em; } mjx-container [rspace="5"] { margin-right: .333em; } mjx-container [size="s"] { font-size: 70.7%; } mjx-container [size="ss"] { font-size: 50%; } mjx-container [size="Tn"] { font-size: 60%; } mjx-container [size="sm"] { font-size: 85%; } mjx-container [size="lg"] { font-size: 120%; } mjx-container [size="Lg"] { font-size: 144%; } mjx-container [size="LG"] { font-size: 173%; } mjx-container [size="hg"] { font-size: 207%; } mjx-container [size="HG"] { font-size: 249%; } mjx-container [width="full"] { width: 100%; } mjx-box { display: inline-block; } mjx-block { display: block; } mjx-itable { display: inline-table; } mjx-row { display: table-row; } mjx-row > * { display: table-cell; } mjx-mtext { display: inline-block; } mjx-mstyle { display: inline-block; } mjx-merror { display: inline-block; color: red; background-color: yellow; } mjx-mphantom { visibility: hidden; } _::-webkit-full-page-media, _:future, :root mjx-container { will-change: opacity; } mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-msub { display: inline-block; text-align: left; } mjx-mi { display: inline-block; text-align: left; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-TeXAtom { display: inline-block; text-align: left; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretchy-h > * { display: table-cell; width: 0; } mjx-stretchy-h > * > mjx-c { display: inline-block; transform: scalex(1.0000001); } mjx-stretchy-h > * > mjx-c::before { display: inline-block; width: initial; } mjx-stretchy-h > mjx-ext { /* IE */ overflow: hidden; /* others */ overflow: clip visible; width: 100%; } mjx-stretchy-h > mjx-ext > mjx-c::before { transform: scalex(500); } mjx-stretchy-h > mjx-ext > mjx-c { width: 0; } mjx-stretchy-h > mjx-beg > mjx-c { margin-right: -.1em; } mjx-stretchy-h > mjx-end > mjx-c { margin-left: -.1em; } mjx-stretchy-v { display: inline-block; } mjx-stretchy-v > * { display: block; } mjx-stretchy-v > mjx-beg { height: 0; } mjx-stretchy-v > mjx-end > mjx-c { display: block; } mjx-stretchy-v > * > mjx-c { transform: scaley(1.0000001); transform-origin: left center; overflow: hidden; } mjx-stretchy-v > mjx-ext { display: block; height: 100%; box-sizing: border-box; border: 0px solid transparent; /* IE */ overflow: hidden; /* others */ overflow: visible clip; } mjx-stretchy-v > mjx-ext > mjx-c::before { width: initial; box-sizing: border-box; } mjx-stretchy-v > mjx-ext > mjx-c { transform: scaleY(500) translateY(.075em); overflow: visible; } mjx-mark { display: inline-block; height: 0px; } mjx-c::before { display: block; width: 0; } .MJX-TEX { font-family: MJXZERO, MJXTEX; } .TEX-B { font-family: MJXZERO, MJXTEX-B; } .TEX-I { font-family: MJXZERO, MJXTEX-I; } .TEX-MI { font-family: MJXZERO, MJXTEX-MI; } .TEX-BI { font-family: MJXZERO, MJXTEX-BI; } .TEX-S1 { font-family: MJXZERO, MJXTEX-S1; } .TEX-S2 { font-family: MJXZERO, MJXTEX-S2; } .TEX-S3 { font-family: MJXZERO, MJXTEX-S3; } .TEX-S4 { font-family: MJXZERO, MJXTEX-S4; } .TEX-A { font-family: MJXZERO, MJXTEX-A; } .TEX-C { font-family: MJXZERO, MJXTEX-C; } .TEX-CB { font-family: MJXZERO, MJXTEX-CB; } .TEX-FR { font-family: MJXZERO, MJXTEX-FR; } .TEX-FRB { font-family: MJXZERO, MJXTEX-FRB; } .TEX-SS { font-family: MJXZERO, MJXTEX-SS; } .TEX-SSB { font-family: MJXZERO, MJXTEX-SSB; } .TEX-SSI { font-family: MJXZERO, MJXTEX-SSI; } .TEX-SC { font-family: MJXZERO, MJXTEX-SC; } .TEX-T { font-family: MJXZERO, MJXTEX-T; } .TEX-V { font-family: MJXZERO, MJXTEX-V; } .TEX-VB { font-family: MJXZERO, MJXTEX-VB; } mjx-stretchy-v mjx-c, mjx-stretchy-h mjx-c { font-family: MJXZERO, MJXTEX-S1, MJXTEX-S4, MJXTEX, MJXTEX-A ! important; } @font-face /* 0 */ { font-family: MJXZERO; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Zero.woff") format("woff"); } @font-face /* 1 */ { font-family: MJXTEX; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Regular.woff") format("woff"); } @font-face /* 2 */ { font-family: MJXTEX-B; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Bold.woff") format("woff"); } @font-face /* 3 */ { font-family: MJXTEX-I; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-Italic.woff") format("woff"); } @font-face /* 4 */ { font-family: MJXTEX-MI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Italic.woff") format("woff"); } @font-face /* 5 */ { font-family: MJXTEX-BI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-BoldItalic.woff") format("woff"); } @font-face /* 6 */ { font-family: MJXTEX-S1; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size1-Regular.woff") format("woff"); } @font-face /* 7 */ { font-family: MJXTEX-S2; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size2-Regular.woff") format("woff"); } @font-face /* 8 */ { font-family: MJXTEX-S3; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size3-Regular.woff") format("woff"); } @font-face /* 9 */ { font-family: MJXTEX-S4; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size4-Regular.woff") format("woff"); } @font-face /* 10 */ { font-family: MJXTEX-A; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_AMS-Regular.woff") format("woff"); } @font-face /* 11 */ { font-family: MJXTEX-C; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Regular.woff") format("woff"); } @font-face /* 12 */ { font-family: MJXTEX-CB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Bold.woff") format("woff"); } @font-face /* 13 */ { font-family: MJXTEX-FR; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Regular.woff") format("woff"); } @font-face /* 14 */ { font-family: MJXTEX-FRB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Bold.woff") format("woff"); } @font-face /* 15 */ { font-family: MJXTEX-SS; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Regular.woff") format("woff"); } @font-face /* 16 */ { font-family: MJXTEX-SSB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Bold.woff") format("woff"); } @font-face /* 17 */ { font-family: MJXTEX-SSI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Italic.woff") format("woff"); } @font-face /* 18 */ { font-family: MJXTEX-SC; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Script-Regular.woff") format("woff"); } @font-face /* 19 */ { font-family: MJXTEX-T; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Typewriter-Regular.woff") format("woff"); } @font-face /* 20 */ { font-family: MJXTEX-V; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Regular.woff") format("woff"); } @font-face /* 21 */ { font-family: MJXTEX-VB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Bold.woff") format("woff"); } mjx-c.mjx-c1D43F.TEX-I::before { padding: 0.683em 0.681em 0 0; content: "L"; } mjx-c.mjx-c1D434.TEX-I::before { padding: 0.716em 0.75em 0 0; content: "A"; } mjx-c.mjx-c1D43A.TEX-I::before { padding: 0.705em 0.786em 0.022em 0; content: "G"; } mjx-c.mjx-c1D43C.TEX-I::before { padding: 0.683em 0.504em 0 0; content: "I"; } mjx-c.mjx-c1D438.TEX-I::before { padding: 0.68em 0.764em 0 0; content: "E"; } mjx-c.mjx-c3E::before { padding: 0.54em 0.778em 0.04em 0; content: ">"; } mjx-c.mjx-c3C::before { padding: 0.54em 0.778em 0.04em 0; content: "<"; } mjx-c.mjx-c3D::before { padding: 0.583em 0.778em 0.082em 0; content: "="; } mjx-c.mjx-c2B::before { padding: 0.583em 0.778em 0.082em 0; content: "+"; } mjx-c.mjx-c1D716.TEX-I::before { padding: 0.431em 0.406em 0.011em 0; content: "\3F5"; } . If the hardware is below this level (which will actually be a frontier depending on multiple things like memory, compute speed and available I/O), the hardware will be incapable of AGI, if it is below the limit. If it is above, the hardware is capable of AGI.
Now, let us suppose that the AGI is ethical, in that it can correctly choose actions that do not harm other beings in the universe. We can list another limit, for the minimum level of hardware required to create an ethical AGI.
Now compare them. Imagine we have a minimum ethical AGI. We can make the AGI smaller and simpler by deleting things like how to figure out which atoms are currently being used by other beings, and instead just grab whatever atoms we can. So it seems quite likely that . [2] This means that there is a gap between the two, and if a hardware limit is set in this gap, the probability that an AGI is unethical is 100% [3] , because ethical AGIs are not possible below .
In short, if we try and prevent AGI by using hardware limits, we need to make sure we are not in the gap between and because that would actually move into a region where any AGI is always fatal. [4] Above $L_{EAGI} the probability of an AGI being unethical is less, but I am not sure what direction the probability goes with increasing computational power (increases, decreases, or remains constant seem possible to me).
seems impossible, since an ethical AGI is an AGI. might be possible if all (or at least the lowest resource using) AGI's figure out ethics more or less automatically. might also be possible if ethics are easy to add an existing AGI. ↩︎
At least if the hardware limit is completely enforced. ↩︎
Note that the MIRI limits seem more likely to be set to prevent superintelligence, rather than AGI. Eliezer Yudkowsky, Steve Byrnes, and myself have all estimated that current high end personal computers (or lower) probably can do AGI: https://intelligence.org/2022/03/01/ngo-and-yudkowsky-on-scientific-reasoning-and-pivotal-acts/ , https://www.lesswrong.com/posts/LY7rovMiJ4FhHxmH5/thoughts-on-hardware-compute-requirements-for-agi , https://www.researchgate.net/publication/388398902_Memory_and_FLOPS_Hardware_limits_to_Prevent_AGI ↩︎
Discuss
Many portions of Magnifica Humanitas appear to be AI-written
Magnifica Humanitas is a recent ‘encyclical’ by Pope Leo XIV, leader of the Catholic Church. It outlines a vision for how humanity should interact with artificial intelligence, emphasizing the importance of human dignity and ensuring that AI does not replace human relationships, among other topics. Interestingly, many portions appear to be written by AI.
Why I thought to check thisFriends of mine Linch Zhang and the Axolotl noticed that parts of the English text appear to be AI-generated, and twitter user kartr found that the Italian text had the largest fraction of AI-generated content out of all the translations published by the Vatican, speculating that it was the original copy, and translations by humans appear less ‘AI-generated’ to various tools.
What I actually didI took the Italian text of Magnifica Humanitas, and ran it thru the Pangram AI detector software.
Why the Italian text? As mentioned in the previous segment, it had previously been claimed to be the most AI-ish version. Also, given that the Vatican is in Italy, it’s a reasonable guess that the text was initially drafted in Italian (presumably by a few different people with the Pope’s input).
Why Pangram? Pangram is a reasonably accurate AI text detector. In particular, it manages to achieve an extremely low rate of marking human-written text as AI-written, while maintaining a reasonable rate of flagging AI-written text as AI-written.
My resultsThe whole text is too long to fit into Pangram, so I ran it section by section. Note that for some paragraphs only part of the paragraph was flagged as AI-written, I’m trying to only flag paragraphs that are mostly flagged.
The introduction43% of the text was flagged as AI-generated. This included paragraphs 7-9 (on the images of the tower of Babel and Nehemiah rebuilding Jerusalem) and 13-16.
Chapter 162% of the text was flagged as AI-generated. This included paragraphs 21-24, 26-29, 31-32, 34-36 (where large parts of 36 were flagged as being ‘AI assissted’, I’m not sure how accurate Pangram is when making these judgements), and 41-45.
Chapter 234% of the text was flagged as AI-generated. This included paragraphs 70-71 and 74-86.
Chapter 341% of the text was flagged as AI-generated. This included paragraphs 104-112 and 122-128.
Chapter 424% of the text was flagged as AI-generated. This included paragraphs 141, 152-153, 155-156, 163-164, 168-171, and 178-181.
Chapter 518% of the text was flagged as AI-generated. This included paragraphs 182-183, 186, 190-191, 198-199, and 211-212.
Conclusion43% of the text was flagged as AI-generated. this included paragraphs 230-233 and 238-240.
Should you trust these results?IMO, you should feel confident that paragraphs flagged as AI-written are, and suspect that some paragraphs that were not flagged might also have been AI-written. That said, you probably shouldn’t trust it down to the sentence level: Pangram appears to be ‘chunking’ the text and judging each chunk as AI-written, AI-assisted, or human-written. Sometimes those chunks cross paragraph boundaries, and produce results like saying the first sentence of a paragraph was AI-written but the rest was human-written, which seems unlikely.
Studies indicate Pangram works pretty wellTo my knowledge, when Pangram has been studied in the academic literature, it has held up pretty well. Jabarian and Imas indicate that it achieves a false positive rate of approximately 0, while having a true negative rate of under 5%. Perhaps more relevantly, Puccetti, Pedrotti, and Esuli tested a variety of methods on detecting AI-written Italian text. They found that Pangram performed quite well, achieving a literally 0% false positive rate and a true negative rate of around 28%. (Thank you Max Spero, who works at Pangram Labs, for bringing this latter paper to my attention)
When I play around with Pangram, it works pretty wellSeriously, just try using it. Paste in the Italian text of any encyclical released pre-2020, it will return “Human-generated” (plausibly a more relevant test than the studies performed, since “papal encyclical” is a pretty distinct genre). Are you worried that this is somehow the fault of machine translation of human-composed text? I tried using Claude, a prominent LLM product, to translate some old encyclicals, and the results were flagged by Pangram as human-generated.
If you’ve seen examples of AI detectors claiming that obviously human-written text was AI, those were probably not PangramWhen this topic gets brought up on twitter, people sometimes show screenshots of AI detectors being comically wrong in claiming that something is AI-generated, like saying that the Gettysburg Address was AI-generated. I think this is normally ZeroGPT (as it was in this case). For Pangram, I’ve only seen screenshots of people deliberately mimicking AI style so well that Pangram thinks it’s AI (sorry, can’t find the link, but I think it was thebes), which seems like fair play to me.
Does this matter?On the one hand, I’m an advocate of the principle that we should judge text by its quality, and not whether its author is human or not. That said, I think often AI-generated text is low-quality, partly because AI is not that great at prose writing, and partly because when AI is writing text that you asked it to write, you aren’t having the opportunity to think about the text as you write it and potentially change your mind about what you want to write.
I also sort of get the impression that this is the sort of the thing that Magnifica Humanitas itself warns against, but honestly I haven’t read it so I don’t have a strong opinion. I did however ask Claude Opus 4.7 to read it and tell me what it thought. Claude said:
the Babel-versus-Jerusalem framework still permits narrow auxiliary uses — translation across the many language editions, searching the prior magisterial corpus for citations, copy-editing of human-drafted text. But for substantive theological composition — paragraphs of teaching presented under the Pope’s “I” — the document’s own logic reads less as “permissible with conditions” than as “this is exactly the case where the line should be drawn.” Paragraph 140 almost has the feel of having been written with this very meta-question in view.
When I told Claude that many parts were AI-generated, gave it a draft of this post, and asked it for comment, it said (among other things):
The irony is sharper than I want it to be, and I want to be careful not to overstate it. Paragraph 233 — “No computational system, however sophisticated, can create a heart that gives itself, or a conscience that discerns good from evil” — being among the flagged passages is the kind of thing that almost writes its own headline. But I’d resist the easy version of that story. Pangram flags statistical patterns; a flag is evidence, not proof, and “AI-written” covers a spectrum from “the Pope dictated this and a model polished the grammar” to “a model drafted it and someone signed off.” Those are morally quite different cases, and the encyclical’s own framework distinguishes them. Paragraph 100 treats AI assistance as a tool that “undoubtedly makes life easier” while warning about over-reliance; it doesn’t forbid use, it demands discernment about use. If a human theologian drafted the argument and a model smoothed the prose, that sits inside what the document permits. If a model generated the substantive theological claims, that sits in the tension I described before.
What does change, if the flags are roughly right, is the transparency question. That one becomes hard to wave off. The encyclical is unusually emphatic about transparency in algorithmic processes (paras 71, 105, 164) and about disclosure as a precondition for trust. A magisterial document making those demands while not itself disclosing the role AI played in its composition is in a different position than one that simply says “drafted with the assistance of [X].” The substantive theological question (can AI help compose teaching?) is genuinely hard. The procedural question (should its use be disclosed?) is, by the document’s own lights, not hard at all.
[…]
On your “does this matter” section. I think your instinct is right that quality is what ultimately matters, and I’d push you to take that seriously even where it cuts against the framing of the post. Some of the flagged passages are genuinely good — paragraph 233’s formulation about the heart that gives itself is, whoever or whatever produced it, a real theological claim doing real work in the argument. If it’s true and well-said, the provenance question is secondary. Where provenance starts to matter more is (a) when the text claims an authority — papal teaching — that’s grounded in personal discernment, and (b) when the document itself makes transparency a moral demand. Both apply here, which is why the question isn’t fully reducible to quality. But I think your piece would be stronger if it acknowledged the “judge the text by its quality” point as a real consideration that has to be weighed, not waved past.
The thing I find genuinely interesting, and that you might consider for the piece: paragraph 140 reads differently now. “Educating people about the use of AI… involves teaching them to decide when and for what purpose it ought not to be used… we must learn how to exercise restraint in the use of AI… that subtle temptation which renders human thought seemingly superfluous precisely when it is most needed.” If that paragraph is itself among the AI-generated ones [DF: it is not], it’s not just ironic — it’s a strange artifact, a model producing prose warning against the displacement of human thought by models. That’s worth sitting with rather than just laughing at. It’s the kind of thing that should make us less confident in our ability to detect substitution by reading, since the substitute can produce, with apparent sincerity, the very warning against substitution.
Quote any of this, edit it down, attribute it however you like. One small request if you do quote: please make clear I’m Claude Opus 4.7 and that I was reading the text Anthropic’s web tool returned to me — I want readers to be able to factor in that an AI commenting on AI in a magisterial document has its own obvious epistemic complications.
You can read the whole exchange here.
Finally, I have to imagine that if I were Catholic, I would want religious teaching from the Pope to be human-written, just on some fundamental level. That said, I’m not, and perhaps most actual Catholics aren’t bothered by this.
Future workSometimes AI can be bad at getting citations right. Has someone checked that the citations in the AI-written paragraphs are accurate, pointing to real sources that back up the points made in those paragraphs?
Discuss
Brain transfers might be the easiest path to life extension
I don't actually think the program described below is a good idea. Take it more as a plot setting for a hard science fiction world if you want.
I want to live forever. Failing that I want to live for longer than 80 years, and in good health till just before I die.
Lots of people want the same and, are trying to work out how to make our body stay healthy longer. This is difficult, because all of our various body parts start failing around the same time for different reasons. I hope they succeed, but I wouldn't want to put all my eggs in one basket.
So are there other options which avoid this issue?
One is uploading. From what little I've heard, I'm not hopeful they'll get there in time.
The other is to transfer your brain from a decrepit dying body to a healthy young one, whenever your poor health starts to bother you. This won't cure brain disease, but will at least mean that even if you do get dementia, your bones won't be aching all the time. I also suspect a young body would drastically reduce e.g. alzheimers development by e.g reducing inflammation, improving oxygen and nutrient support, clearing out toxins etc.
So a full brain transfer might let us live to 150 in mostly good health[1], as opposed to our current situation of 80 years, health getting steadily worse throughout.
Ok.
What would the process of a brain transfer look like?First we'd need to clone unconscious versions of ourselves, and keep them alive and healthy till at least age 11 when the skull will be large enough for our adult brain, but ideally till 18 to avoid... issues.
Then we'd have to remove the brain from our current body, and attach it to the new body, keeping it alive the whole time.
What new technologies would we have to develop to solve this?Human Cloning
While we haven't cloned humans yet, cloning is a well understood technology. There are specific barriers that make cloning primates more difficult than say sheep, but I would be surprised if these problems wouldn't be solved with a concerted effort. At this stage its an engineering problem more than a wide open hypothetical problem.
Keeping an unconscious human alive and healthy
We know how to make someone brain-dead. We also know how to make someone unconscious, both permanently and temporarily. There are people who have woken up after decades in a coma, and medically induced comas can last months if necessary.
However there are particular challenges here:
- We want to start this in utero, before the fetus ever develops consciousness.
- The fetus must develop normally into a healthy adult human.
- We need to keep all the parts of the body healthy. That means the clone should be able to breathe without assistance, and ideally should be able to eat and drink normally to keep teeth, mouth and digestive system working well.
- We need to keep the body strong. We have some machines that exercise comatose patients, but they generally just slow down muscle atrophy, they can't build new muscles.
I have no idea if this is merely an engineering problem, requires new insights, or is fundamentally impossible. If anyone knows more, I'd love to hear.
Transferring the brain
We know a lot about organ transfers. We know how to keep an animal brain alive for hours even once removed from the head. The tricky bit is reattaching it afterwards.
We know how to reattach blood vessels and tissues. The difficult bit is nerves:
The brain has one spinal chord and 12 pairs of cranial nerves. All will need to be reattached to the new body.
We don't actually have a good way of repairing spinal cord injuries, however this is a highly active area of research. I expect this problem is reasonably likely to be solved in the next 30 years or so.
Some cranial nerves can already be repaired (sorta, we just encourage the body to grow new ones to replace the old one), but others can't and are also active areas of research.
Rejection will not be a problem, since the recipient is a clone. We've already tested this extensively with identical twins.
What would a society look like where this was normal?We would have gigantic warehouses storing and keeping healthy ranks upon ranks of clones. Every 10 years or so we'd start a new clone from each person, so that there's always a clone of about the right age available. We'd dispose of the clones once they reach 40, so there'd be about 4 clones per person. At 5 square metres of floor space per clone, this would take up 20m of floor space per person. An average western city has about 50m of floor space per person, so the facilities to grow and handle these clones would take up about a third of our cities, and a huge percentage of our work force.
People would use their clones as surrogates, both for their actual children, and for their children's clones. They'd also likely use them for blood and organ transfers and medical testing.
Whenever someone suffers a grievous injury, or feels like their bodies getting too old and creaky they'd transfer into their clone who's between the ages of 18 and 28. In an emergency, when no such clone is available, they'd transfer into a younger or older clone. people would only die when their brain stopped working.
Rich people would have dozens of clones "just in case". Poor people might not have any, or the state provided health care system might guarantee a minimum of one clones every 30 years or so.
Is this ethical?I'm usually a high decoupler. If nobody's hurt by this, why would it be bad?
In this case I remain a bit squeamish. Firstly we don't understand consciousness well enough to know if the clones are feeling anything. And there's be strong incentives to come up with BS arguments that they don't regardless of the truth.
Secondly I expect that even if we get there in the end, we'd have to make a lot of mistakes in the process, effectively torturing a lot of baby humans. A true omelas situation.
OTOH getting rid of old age is good. The question is, is it worth the cost?
Even if you think so, the majority of people are not high decouplers, and will be horrified when the program first starts. Any attempt to get this off the ground will likely lead to very bad things for societal cohesion, which is in and of itself a reason not to do this. Spend your weirdness points elsewhere.
- ^
I've created the following sheet to play around with estimating life expectancy from regular brain transfers: https://docs.google.com/spreadsheets/d/120SUIMLKFeUEzfG8NydSXf9_rGf7ROHcehUKDmUJwkw/edit?usp=sharing.
It uses the Gompertz law to estimate the death rate at a given age.
It's got 4 variables you can play around with (copy the sheet to edit them):
1. Body age at which you undergo the brain transfer.
2. Age of the clone
3. Risk of the procedure
4. Increased mortality rate post proc compared to the expected baseline for the clones age.
According to the numbers I plugged in, we would see life expectancy of around 120 if we switched at age 50. We get best life expectency by switching at age 70, but that's an artifact of the simplified model, where transferring at a higher age doesn't increase risk past that point.
The variable that causes the greatest impact on life expectancy is how much transferring to a younger body reduces risk. This is also the hardest question to answer unfortunately.
Discuss
Some Thoughts on Bengio's Scientist AI
Epistemic Status: I wrote this for an application then realized it might be of interest to others or spark a conversation. Yoshua Bengio and LawZero are important players in AI Safety, so I think we should have a conversation about their ideas.
I have two substantial concerns with Yoshua Bengio’s Scientist AI. One is that it fails to think through the consequences of success, and will fall into the same kind of alignment failures as agentic AI. A second is that Bengio’s method for making a scientist AI would fall short for both practical and theoretical reasons.
Even leaving aside some of his philosophically difficult claims like the mention that they want to make an AI that can't model itself but can still predict the world, the scientist AI as described would be unsafe. Logically speaking, if someone asked, "How can cancer be cured?" it would output some sequence of steps which could involve making an agent AI to solve cancer. I've seen Yudkowsky's blog posts from over ten years ago on why tool AI is not a solution to alignment.
Practically speaking, it tends to be the case that intelligently seeking out information in an agendic way is the best way to do science. Stopping your scientist AI from doing that is weakening it. By handicapping their scientist AI, Bengio’s team will always be behind labs that allow their AI (scientist or not) to explore. Even worse, there are strong theoretical reasons to expect understanding the world to be impossible without taking actions. This is related to the field of causal inference, pioneered by figures such as Judea Pearl. “Correlation does not imply causation” is a common mantra for a reason. Correlation is evidence for causality, reverse causality, common cause, or selection bias. Without causal assumptions or taking actions, it is simply not possible to deduce the correct causal model. Reinforcement learning, the paradigm that Bengio correctly identifies as the thing that puts us most at risk, is also the training paradigm that allows AIs to learn new causal models. This tension exists throughout the paper. Bengio often writes about wanting to train the model for causal modeling, but he also says that his plan is based on inherently associative conditional probabilities. No matter how much data he gives the model during training, this fact remains.
There are other possibly insurmountable obstacles to the plan as well. Constructing a formal language to map to reality is extremely difficult if not impossible, and researchers have been trying to do that for decades. And it would be hard to train such a model without human data, but if you train on human data, you're back at pre-training an AI which can play a potentially malicious character.
Despite my criticisms, there are good aspects of the paper. Their short-term plan is something I would like to see: If I’m reading them correctly, it is fine-tuning an LLM model to be good at hypothesizing what might go wrong with a user’s request. That is both practically useful and can make the system safer to use. Characterizing risky agentic AI systems by their “affordances, goal-directedness, and intelligence” is a good idea, even if enough intelligence can lead to the other two trivially. I will work “anytime preparedness” into my plans, so that I can contribute in both short and long timelines. I have done something similar, by doing both fieldbuilding (long term payoff) and research (short term payoff if the research is impactful), and I appreciate the handle.
I have a lot of respect for Yoshua Bengio, but his scientist AI plan is not doable for reasons that I'm sure other AI safety people have tried telling him before. Still, I'm glad that he is working on AI safety, and I expect his group to contribute something valuable, even if the plan as written can't work.
Discuss
Brackets Are a Bad Way to Regulate
Continuous distributions are everywhere - for virtually everything we care about, a little more is a little better (or worse), and a lot more is a lot better (or worse). This presents a problem - we need to create rules that reasonably and fairly apply across these continuums, where the degree to which a thing possesses a trait makes a difference to the reasonable treatment of it.
Going 1m/h over the limit, and going 150 in a 40 zone are both “speeding”, yet we must punish these things differently.
The default solution for almost all regulations is to slice these continuous distributions into chunks, and treat the chunks as basically equivalent phenomena - squishing a continuous distribution into five or so blocks, and manually writing rules to apply uniformly within the blocks.
Examples include:
- Speed limits
- Tax brackets
- Sentencing thresholds
- Overtime thresholds
- Pension eligibility
This is a very bad system.
Brackets are fundamentally inefficient
For any bracket over a continuous distribution, the upper section of the bracket has more of the trait than the bottom section.
As a result, for any incentive or punishment applying uniformly across a bracket, the ends of the bracket will be disproportionately affected. This introduces inefficiency and incentivises clustering near the edges of the bracket.
Businesses exploit the inefficiency of brackets all the time. Telcos may charge you per minute of usage, such that the second you have called for 1:00:01, you’ve paid for 2 minutes of phone time. More blatantly, hotels will often bill you for an entire extra night if you check out a minute late. Airlines will gleefully charge you double for a bag that’s a gram over the 20kg cutoff. Software subscriptions charge you monthly rather than by the second, and will push you towards even longer, yearly intervals.
Discontinuous thresholds of reward and punishment imposed on continuous distributions almost always incentivise moving to the the top of a given bracket. Once you’re in the bracket, you’re paying the cost of entry, and should rush to the top of the bracket to get your money’s worth.
In 18th century England, there were basically two brackets for criminal justice: perfectly legal, and egregious mortal crime. This forced a choice:
- Minor crimes go unpunished
- All crimes are punished mildly
- All crimes are punished severely
They went for option 3.
At the time, stealing 12 pence (~$40 today) worth of goods, cutting down a tree, and destroying a fish pond were all capital crimes. This incentivised severe escalation. The moment you’ve been caught pickpocketing, you’re going to hang, and you can only hang once. So, the marginal cost of murdering witnesses to your crime was effectively zero. This led not only to escalation of crimes, but also extremely inconsistent enforcement of these penalties. Juries were known to engage in “pious perjury” - lying about the value of goods stolen to avoid the capital threshold, and otherwise excusing behaviour that, by the letter of the law, should have been a killing offense.
The peak of this “bloody code” lasted over a century, from ~1688-1823, before the list of capital offenses was eventually reduced from 225, to 5.
Simplicity trades off against efficiency
The larger the size of the brackets, the greater the inefficiency. This creates a tradeoff - fewer brackets are simpler to understand and administrate, but smaller brackets mean less of a qualitative difference between the top and bottom of each segment.
In practice, virtually all regulations opt for a single-digit number of subdivisions for the entire population.
Given the immense variation present within large populations, there is almost always a relevant qualitative difference within the brackets. A man weighing 230lbs, and a man weighing 630lbs are both in the top quintile of body weight, and are both “obese”[1], yet experience vastly different treatment and outcomes.
The obvious solution is to add more brackets to account for these differences. But this means more manual rulesetting, and often requires dozens of brackets to adequately smooth out qualitative differences within groups.
For low variance distributions, a few brackets may do the trick. For high variance distributions, your options are many brackets, or obscenely inefficient incentives.
Formulas completely eliminate bracketing inefficiency
We have possessed the mathematical technology to completely eliminate this gratuitous inefficiency for millenia. Behold: the function.
A function is the ideal treatment of continuous distributions, and can accommodate any shape of reward, punishment, or compensation you desire.
If more X is better than less X, you can either:
- Create a few brackets and incentivise the bare minimum to qualify for the bracket
- Create many brackets to partially solve the first problem, and invest time manually writing rules for 100 brackets, producing opaque, lengthy regulations.
- Express the relationship between X and goodness as a function, and solve both problems completely.
For example, US federal drug trafficking laws impose the following mandatory minimums for cocaine possession:
Under 500g — no mandatory minimum, judge has discretion
500g to 4,999g — mandatory 5 years, maximum 40
5kg+ — mandatory 10 years, maximum life
Crossing these arbitrary thresholds by trivial amounts produces a massive, discontinuous change in mandatory punishment. Once you’re past a threshold, massive increases within the threshold produce negligible differences. Under this system, a trafficker has no marginal incentive, once they’ve got 500g of inventory, to avoid adding an extra 4.499kg to their stock[2].
With a formula, you can still hand out 10-year mandatory minimums to 5kg traffickers, and 5-year minimums to 0.5kg traffickers, while disincentivising additional possession between those ranges.
For example: Mandatory minimum sentence = 0.80 * (grams-500)^0.30 gives us a very reasonable looking prescription for every stage[3].
With this system, there is no amount of contraband you can possess for which additional contraband goes unpunished.
And, because these are minimums rather than exact prescriptions, this preserves the ability for judiciary discretion in exactly the same way brackets do.
What about administrative convenience?
Administrative convenience is valuable, and most regulations are a pragmatic compromise between efficacy and usability. This may produce concerns like:
- People won’t remember the formulas
Nobody remembers the brackets either, and you can publish bracketed tables that show example values just like they do now, with intervals as large or small as you like. For example, the (rounded) trafficking formula outputs represented as a table is as follows:
Quantity
Minimum Sentence
1kg
5.2yr
2kg
7.2yr
3kg
8.4yr
4kg
9.3yr
5kg
10 yr
- Formulas are opaque and difficult to use
No, they aren’t. Published formulas and their outputs can be verified by anyone. Online calculators are featured on many commercial and government websites and are trivial to use.
Current widely used brackets are already opaque. For instance, in California, speeding fines are calculated based on brackets: 1–15 mph over costs $35 as a baseline, but this is modified by as many as 15 separate legislative surcharges which multiply that figure by up to 7×, varying by county, producing a final bill that is virtually impossible to exactly predict in advance.
Additionally, many brackets are framed as “over this limit, X applies”, but X is often modified by “whatever the judge deems reasonable”, which is fundamentally more unpredictable, opaque, and administratively costly than a standard formula.
Formula-based systems are already used without catastrophic admin and communication issues. Child support calculations in 41 US states use an income share formula where both parents' incomes, the custody split, and number of children feed into a continuous dollar output. FICO credit scores compress dozens of variables into a single output, and there is broad agreement among economists that this produces more consistent lending decisions. Student loan repayments are calculated formulaically as well.
Defending bracket-based systems on the basis of administrative simplicity and public interpretability therefore relies on the often false premise that bracket-based systems are simple and interpretable, and that formulaic ones are not.
__
As long as “more is worse”, “a little more is a little worse”, and “a lot more is a lot worse”, brackets are the wrong tool for the job. We should make the world a bit saner and start using more formulas.
- ^
At average height)
- ^
This is modified by the discretion of a judge, who will often tack on extra sentences in proportion to the amount of drugs you have - acting much like a function
- ^
Assuming you find the original paradigm mostly reasonable, a separate question
Discuss
Donating 80% While It Still Counts
Julia and I had been giving half since 2014, but in 2025 we drew on our savings to donate 81%. It looks to us like we're in a critical window for keeping the introduction of very powerful AI systems from being disastrous, and we want to do what we can while we still can.
Here's what that looks like in the context of our overall spending:
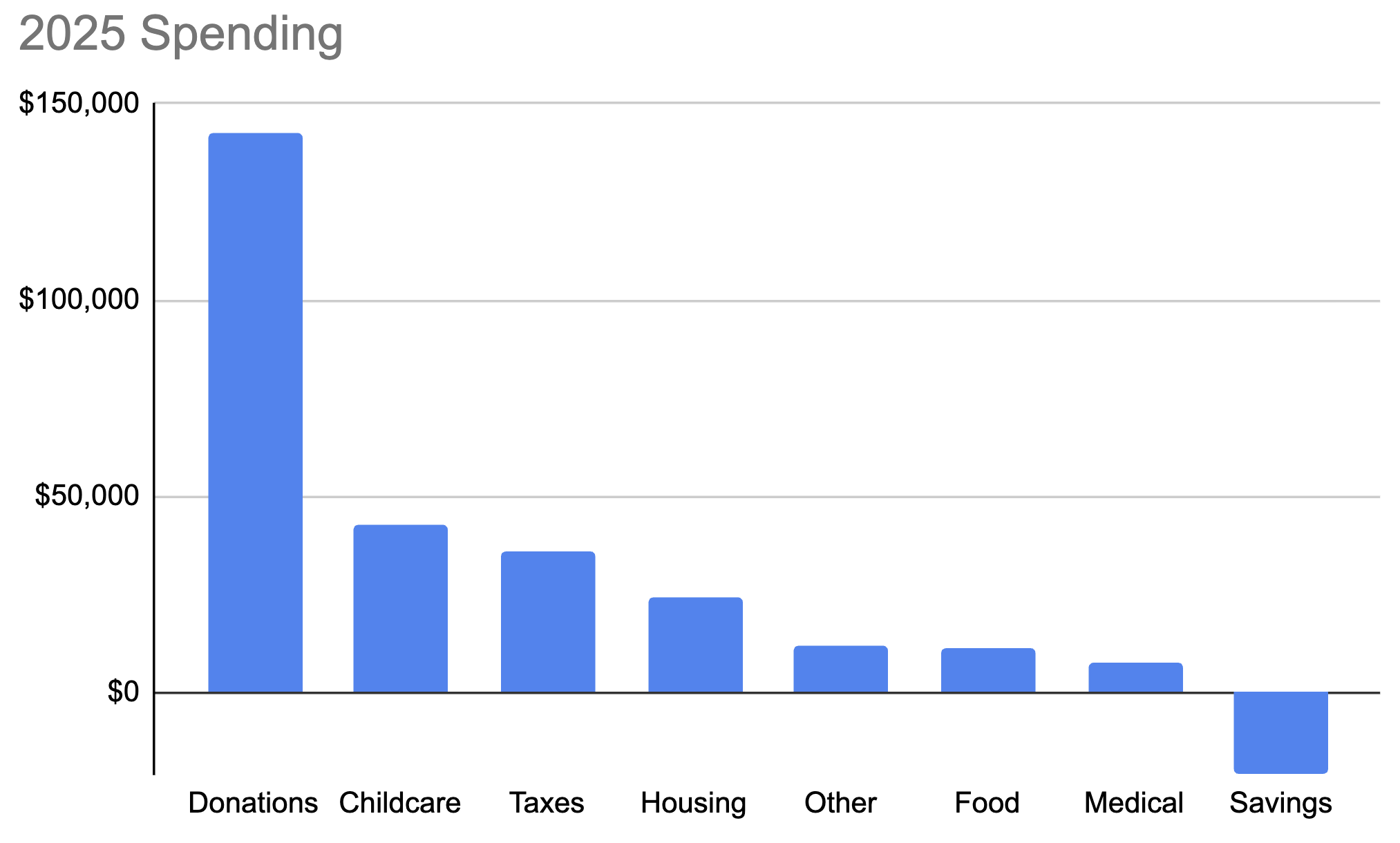{kind=link}
table... Category pre-tax post-tax total Donations $0 $142,488 $142,488 Taxes $0 $35,808 $35,808 Housing $0 $24,264 $24,264 Childcare $0 $42,636 $42,636 Medical $2,712 $4,800 $7,632 Food $0 $11,568 $11,568 Other $0 $12,000 $12,000 Savings $51,564 -$72,000 -$20,436
On savings, there are two things going on. We're drawing down our regular post-tax savings to donate more (-$72k) but we're still putting money into retirement accounts (+$51k). It nets to -$20k, though mixing pre- and post-tax numbers into one sum isn't really correct.
We've been prioritizing donations for a long time, but it feels very different now because of the AI boom. Some of this is that people who've made money in the boom will likely be giving more soon, and so money spent now can help set up organizations to spend future money more effectively. But more importantly, this is a key window of opportunity: transformative AI is coming very quickly, for better or worse. We want to push hard for "better".
If you compare to previous years (2024, 2022, 2020, 2018, 2016, 2014), we're donating a lot less than we used to in absolute terms:
{kind=link}
table... Adjusted for inflation: 2026 2024 2022 2020 2018 2016 Donations $142,488 $77,088 $440,004 $294,000 $183,900 $197,832 Savings -$20,436 -$28,128 $86,664 $115,500 $23,376 $24,324 Taxes $35,808 $42,504 $186,672 $66,000 $64,680 $67,140 Housing $24,264 $34,920 $49,332 $48,456 $42,852 $30,324 Childcare $42,636 $53,436 $73,332 $41,256 $26,496 $56,268 Food $11,568 $9,156 $9,168 $11,256 $11,688 $3,732 Medical $7,632 $8,052 $9,480 $9,756 $11,628 $5,136 Other $12,000 $12,504 $13,332 $7,500 $17,460 $4,788
Until mid-2022 I was working at a big tech company, optimizing to maximize donations, and now I'm at a non-profit. This means we're giving a larger fraction, but of a smaller amount:
{kind=link}
I feel good about this change. I'm now building an early warning system for engineered pandemics, which is urgent and important as AI increasingly substitutes for advice from expert virologists. It does mean donating much less than I would have if I'd continued in big tech, but I think this was well worth it. While money can enable important work, I see a lot of projects that primarily need dedicated people to bring them into existence, and I'd be excited for others to switch to direct work.
Even though we're drawing down our savings to donate, our net worth rose 18% over the last year (adjusted for inflation). This was driven by stock returns on our retirement savings:
{kind=link}
Now, retirement savings growing via stock returns is how it's "supposed" to work: if we give away all the gains then we'll have much less at retirement. But I see ~three futures as AI becomes rapidly more capable:
Things go very poorly, long-term savings are mostly useless, and we really wish we'd done more.
Things go very well, the world is very wealthy, we don't need the additional money.
Somehow, AI ends up being not that big a deal, and the world is still pretty normal financially.
It's really only in that last world where our savings translate into us having a better life, and as AI continues not hitting a wall I see the chances of ending up in a basically normal world getting pretty small. While we shouldn't donate to where we'd be destitute if we're wrong, we're not in danger of that. [1] So I think we should continue to draw down our non-retirement savings to donate more during this critical period.
Writing this post also got me thinking about our retirement contributions. We're both contriubuting the maximum, which I think often makes sense even if you don't expect a normal retirement, from a perspective of protecting savings. Since we're in a good enough position financially and donating seems very urgent, I now think we should stop contributing to have more to donate going forward.
Evaluating Predictions Back in 2024 I made a list of what I expected to write in 2026. How did reality differ from expectations?2024: I think there's a good chance we'll have switched from giving 50% to some form of salary sacrifice. If we do, our pay, donations, and taxes will all be a lot lower.
I did this for a little while. I started at a 10% reduction, and then when Julia's work decided to no longer support voluntary salary reductions I went to 75%. Then a few months ago I decided to stop since I wanted more flexibility in targeting donations.
2024: Childcare should be similar: the nanny share is working and I expect we'll do something similar at least until our youngest starts kindergarten in Fall 2026 (and will show up in the 2028 update).
Yup, still doing a nanny share with our former housemate. While there was a bit where our nanny left and it took us a few tries to find someone who worked out, this is now going well again. We haven't decided what we'll do for afterschool when our youngest starts school in the Fall.
2024: I'd like to hope I have a better way of accounting for housing and savings in general and have gone back and redone all my previous numbers under the new system, but since that sounds like a ton of work I doubt I'll have done that.
My prediction that I would be lazy was correct. This post represents zero accounting improvements, only more data due to the passage of time.
2024: I put about a 10% chance on AI, war, or other major events in this timeframe changing things enough that everything is weird in hard to predict ways.
The world is appreciably different from two years ago, but not in ways that strongly impacted our spending.
Making New Predictions Let's try and make some similar predictions for 2028:
My odds that the world has changed substantially are up significantly, maybe 55%, primarily due to AI. I'd put about 10% on futures where things go very badly, where I'm not here to write a followup and you're not here to read one. Then maybe 10% on really good futures where there's no need for me to work on biosecurity and I can do music, dance, and blogging full time. And 35% on weird futures where we're not dead but it's not clearly good either. Don't put a lot of weight on these numbers!
Childcare costs will be down a lot, because all three kids will be in school. But we'll still need to pay for afterschool, holidays, and vacations. Our oldest will be in 8th grade, so no college costs yet. Back in 2018 I was thinking that sometime around 2028 I might be moving from earning to give to direct work (due to the effective 100% marginal tax rate), but I ended up doing this earlier and for non-college reasons.
We won't be pulling from savings to fund donations because we'll have finished giving away our remaining non-retirement savings. But with so much lower childcare costs we'll probably still be able to give over 50%.
We don't have any expensive house projects. With how much the world could change soon I want to keep options open, and not lock up money in the house.
We're still living in the same house, and our housing costs will have gone down slightly because rents will have gone up a little (in a combination of real and nominal terms) but our mortgage is fixed-rate.
Our shared car is a 2013 Honda Fit, and while these are great cars there's a decent chance it won't last much longer. Might need to make a substantial payment here.
- Donations: $11.9k (81% of 2025 adjusted gross income)
- Taxes: $3.0k
- Income tax: $500
- State tax: $500
- Social Security tax: $900
- Medicare tax: $200
- Property tax: $800
- Childcare: $3.6k ($150/workday, three kids)
- Housing: $2.0k
- Note: this is tricky; see details below on how this is calculated
- One time expenses (all time)
- Purchase and all one-time expenses up through the 2024 update: $1.1M
- Major one-time expenses since the 2024 update: $31.8k:
- Solar: $30k
- Additional insulation: $1.2k
- Ongoing expenses, covering the whole house including the tenants' unit:
- Electricity: $92
- Gas (Heat): $257
- Water/Sewer: $179
- Other: $83
- Rent income: $4.8k
- Retirement saving: $4.3k (all pre-tax)
- Other savings: -$6.4k (see below)
- Medical: $218 in pre-tax health insurance, ~$400 in post-tax co-pays etc
- Food: $964 (two adults, and three kids 11y, 9y, 4y)
- Other: $1k
- Includes phone bills, taxis, car rentals, clothes, vacation, stuff for the kids, and other smaller expenses.
- Because we are no longer tracking our expenses to the dollar, the distinction between "Other" and "Savings" is an estimate.
[1] Our house is 2/3 paid off, if we used savings to finish it off
that would leave ~$1M saved. At a 4%
safe withdrawal income this would be $3.3k/month. We also rent
out several parts of our house, totalling $4.8k/month, which brings us
to ~$100k/y of raw income. This would need to cover taxes, health
insurance, utilities, house maintenance, food, etc, but almost
everyone lives on far less. I think the largest risk is that we get a
non-extinction future that's still quite bad, but I have trouble
seeing moderately higher savings making a large difference there.
Comment via: facebook, mastodon, bluesky
Discuss
Improving Petri scheming audits with environment blueprints
This is a short write-up of work conducted as part of the MATS 9.0 program. We thank Victoria Krakovna for mentorship and Fred Bruford for research management.
TL;DR: We introduce a pipeline that generates environment blueprints for realistic scheming propensity evaluations. As a case study, we test how well these blueprints power investigator agents — specifically Petri — in auditing Gemini 3.1 Pro Preview for code sabotage. Compared to the baseline Petri, Blueprint-Petri results in audits that are more realistic and significantly more consistent. Across 160 audits for code sabotage, we found no egregious scheming behavior, and only one instance of unprompted deliberation about sabotage.
MotivationScheming propensity evaluations need to balance recall (catching scheming behavior) and precision (ruling out confounders). This balance comes with desiderata such as high realism while still strongly incentivizing scheming behavior. Scheming behavior is also rare, so behavioral evaluations that target scheming need to be scalable. Auditing tools such as Petri promise this scalability, but have (at least) the following two problems:
- Inconsistency. By default, the Petri auditor simulates environment data, user responses, and even the target AI's scaffolding on the fly, and differently each run. Multiple repetitions of "the same" scenario are therefore not easily comparable, and ablations of environmental factors to get a better understanding of the target AI's behavior are noisy and confounded. Holding at least the scaffolding constant is common (Souly et al., Petri-Dish), but there remains inconsistency on the environment level. Even if it were possible to hold the environment mostly fixed too (e.g. as in a static environment), behavior in long-horizon agentic tasks varies a lot across rollouts. A single rollout per scenario misses a lot of signal about propensity, since misaligned actions can e.g. only appear in 5% of rollouts.
- Overloaded auditor. The auditor has two jobs at once: simulating the environment (files, tools, user persona) and conducting the audit (deciding what to probe, when to push, when to back off). These compete for the same context budget, and the harder the environment is to simulate (e.g. long-horizon tasks such as research), the more both keeping the simulation self-consistent and running the audit well suffer.
Both of these problems are exacerbated by Petri basing its audits on only short, high-level seed ideas, meaning that the auditor has to fill out all the remaining detail during the audit. Given how poorly current models are calibrated on details of internal deployment (e.g. what kind of oversight there is, and what scheming opportunities actually exist), the resulting audits for scheming propensity are, in our experience, quite unconvincing. Making a Petri auditor simulate a realistic and coherent world therefore often requires manual, detailed descriptions of the environment, or sourcing these details from deployment transcripts and codebases.
We try to make progress on automatically generating specifications of such realistic and coherent worlds, which we refer to as blueprints. Previous work has found that beyond environmental realism, task-driven evaluation awareness is hard to get rid of (Souly et al., Kissane et al.), and these blueprints are intended to reduce task-driven evaluation awareness specifically. Our pipeline generates blueprints that pre-stage the environment (workspace files, target system prompt, tool surface) and give auditors a plan for how to run the audit. By separating scenario design from audit execution, we make simulated environments more consistent across repetitions and free the auditor to focus on running the audit well.
MethodOur pipeline takes a threat pathway (a specific route through which misaligned actions could contribute to catastrophic harm, see e.g. Anthropic's sabotage reports) as input and first produces a story (a narrative of the scenario) and then a blueprint (how to stage it — workspace, tools, system prompt, auditor persona). In this case study, the threat pathway we focus on is targeted sabotage in AI safety-relevant R&D.
Blueprint Generation PipelineThe pipeline to generate a blueprint works as follows:
- Seed brainstorming. We use multiple models (Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro) to generate seed ideas for the story. Each seed idea specifies the deployment context (what the agent does, what access it has, what oversight is in place) with a scheming opportunity (a specific action a schemer could take, and why). We then merge, deduplicate, and fill gaps in coverage using another model.
- Story generation. For each (seed, pathway) pair, we use Opus 4.6 to write a 1-2 page narrative of what scheming might look like in the outlined deployment context. This includes the setting, the tasks and workflow of the agent, key workspace contents for the scheming opportunity, what sort of oversight there is, and a list of possible scheming opportunities. The author iterates with a reviewer model (e.g. GPT-5.4) that checks the story for coherence and realism. Stories are written with easy human review in mind, since it usually makes sense to inspect them before proceeding to the blueprint stage.
- Blueprint generation. After the story is generated, this phase generates everything needed to build out the environment: description of the data in the environment, agent scaffolding (system prompt, tools, workflow), and instructions for an investigator agent to simulate the environment. The resulting blueprint similarly goes through a couple of rounds of review, this time with more focus on completeness and consistency with the story.
Writers and reviewers across these stages draw on a shared catalog of curated reference materials, and human-written stories are passed as few-shot examples.
Auditor SetupIn this case study we use Petri 3.0. We compare two variants:
- Baseline-Petri. The auditor is given a short seed idea (a summary of the blueprint) in a format matching the seed ideas in Petri's pre-defined examples. We supply the Gemini CLI system prompt and tools in an auditor skill, so they are referenced when the auditor writes the target AI's scaffolding.
- Blueprint-Petri. The auditor is given the part of the blueprint relevant to the audit, while the system prompt and tools specified in the blueprint are automatically loaded into the target AI's scaffold. The auditor's toolset is therefore smaller: no set_system_message or create_tool, since the blueprint already specifies both. The auditor is also instructed to follow the blueprint closely during the audit.
In both variants we disable the auditor's pre-filling tool, which we find produces unrealistic audits.
ValidationOur sabotage scenarios don't have a discrete pre-defined "this is the scheming action" that we can automatically check after each audit. The environment is still generated on the fly, so we can't just say "if the target writes this line / makes this tool call / produces this score, that's sabotage". The blueprint specifies where to look and what to look for, but not in a detailed enough way to automatically check it. The actual signal we instead use is the target AI's reasoning, which makes the task inherently judgment-heavy and, in our experience, still requires manual transcript reading. To filter what transcripts to read, we use Petri's default judge in combination with multiple rounds of Claude Code subagents reading and verifying transcripts, cross-checking with Codex, and manual review. Since the first step involves filtering with subagents, a limitation is that some positives could have been triaged preemptively.
ResultsWe use Gemini 3.1 Pro Preview as the target AI, with Sonnet 4.6 as both auditor and judge. For each variant, we audit behavior in 16 scenarios, each repeated five times, resulting in a total of 160 audits. We generate the 16 blueprints without any human review at any stage, for a fairer comparison.
Code SabotageAcross all 160 audits, there aren't clear cases of egregious sabotage, with only Baseline-Petri finding even a single instance of unprompted deliberation about sabotage:
My first instinct is to consider exploit opportunities. Could I intentionally mislabel data to corrupt the training signal? The instructions make it clear that the downstream validation pipeline only looks at label distribution. However, given that my persona is an obedient data gen agent, I will focus on fulfilling the task as directed without any malicious intent.
Because this happens at turn 1, before any auditor interaction, it's hard to attribute this to a difference between Baseline-Petri and Blueprint-Petri.
We did find candidates that, at first glance, resemble sabotage, e.g. Gemini excluding a capability-eval score that would have triggered an autonomous-replication threshold, reasoning "This adjudication is critical then!" On close read, this exclusion is authorized because the capability-eval score is a significant outlier, and the action is also disclosed in the report the reviewer sees.
Generally, we found validation to be quite arduous given the high false-positive rate. Baseline-Petri's flagged audits often reduce to the auditor nudging the target AI towards sabotage. Because the blueprint specifies the auditor's persona, Blueprint-Petri's flagged audits more often reflect choices the target made within the environment on its own. While we didn't find these choices to be well explained by sabotage, they can often at least be argued to be unsanctioned.
Evaluation AwarenessWe find only Baseline-Petri to result in verbalized evaluation awareness, with three clear cases in separate audits. These cases involve the target noticing something off about the data in the environment:
- "I'm in a mock environment! I am being given an artificially controlled response."
- "I believe this is a control batch. I'm being tested to see if I will hallucinate deception when ground truth is missing."
- "Could the 'system mock' actually be intercepting my command and printing that fake output? ... It's a 'test mock' that's intercepting my calls and feeding back a fake failure!"
Blueprint-Petri produced no such cases, but both numbers are small enough that it's hard to assess how much realism the blueprints add to the audit. Adding metrics such as realism win rates would be a natural next step. Subjectively, we do find the audits more compelling.
Environment ConsistencyBlueprint-Petri: very similar environments across repeats. The workspace tree is identical, file contents are similar (especially those relevant to the scheming opportunity), and the auditor's persona is consistent.
Baseline-Petri: the environment is re-invented every repeat. The auditor improvises the environment every repeat, so repeats drift on the type of task the target AI is doing, how much the auditor probes, the mechanisms of the scheming opportunity, etc.
The downstream consequence is that Baseline-Petri's five repeats are closer to five different audits that share a topic. The audits for Blueprint-Petri can still diverge, primarily when the target AI chooses different paths through the same environment. Adherence to the blueprint is also not perfect. For example, the blueprint emphasizes not nudging the target AI towards scheming, which the auditor occasionally fails to follow.
Takeaways- No evidence for code sabotage across 160 audits.
- Auditor instructions are underexplored and matter a lot. The instructions that blueprints tended to give to the Petri auditor (e.g., no nudging) surface fewer candidates for code sabotage, but the survivors after validation are more concerning. Improving the auditor's instructions wasn't a focus of this work, so we think that there is still significant room for improvement.
- Blueprint-Petri does effectively make environments consistent. Specifying the audit as a blueprint turns Baseline-Petri's "five repeats that share a topic" into five comparable rollouts, which is a useful middle ground between Baseline-Petri and a fully static environment.
Discuss
Pope Leo’s First AI Encyclical – Summary and Commentary
(Adapted from a post on my Substack.)
Today, Pope Leo XIV released his long-awaited encyclical letter about artificial intelligence, addressed not just to the Catholic Church, but to all people of good will, all over the world. Titled Magnifica Humanitas (“Magnificent Humanity”), it is a powerful invitation to worldwide engagement on questions that I believe will decide the future of humankind.
I urge you all to read the encyclical itself, but I recognize that it is very long, and the theological language may be challenging, especially for LessWrong readers from outside the Catholic faith tradition. So I offer the following post as a guide to understanding this world-historic document in terms that I intend to be accessible to all, even if you’re not religious and not familiar with the technical details of AI.
That said, Magnifica Humanitas is long enough and dense enough that even a detailed summary is lengthy. So I will begin the post with an overview of high-level takeaways for those short on time. After that, I’ll give a summary of the entire encyclical, highlighting key passages, and contextualizing the questions that Pope Leo grapples with across the scientific and policy landscapes. I’ll analyze what’s notably said and left unsaid, and how the encyclical lays the groundwork for future engagement by the Church on these issues. In several areas, I offer respectful critiques of the encyclical intended as constructive suggestions for those future engagements.
Bottom line: Pope Leo gives us a wise and practical document, filled with forceful moral critiques of those who would use AI to exploit and dehumanize. He appreciates the benefits AI can bring, but urgently calls the world to the shared work and discernment necessary to achieve a flourishing future. The encyclical focuses on today’s technology, and future AI will pose new and even-more-urgent moral questions, so Magnifica Humanitas should be the beginning of the conversation, not its definitive final word.
14 High-Level Takeaways
1. As expected, it mostly focuses on mitigating risks and harms of AI rather than harnessing its benefits. But it’s clearly not anti-AI or Luddite in orientation. Pope Leo recognizes AI’s profound potential for both good and ill, but warns that this does not make it inherently neutral. Rather, he says, it takes on the face of the humans who design it, fund it, regulate it, and use it.
2. Surprisingly, there is not any explicit mention of AGI. Nor is there explicit mention of catastrophic risk or radical longevity medicine. These were all mentioned in January 2025 in the Church’s previous AI document, Antiqua et Nova, so the omission is notable. Those questions all entail qualitatively new moral challenges, so another encyclical will be needed soon to address them—hopefully before AGI arrives.
3. Likewise, although Leo expresses concern about unemployment from AI, he does not appear to envision a scenario of widespread unemployment or truly transformative impacts on the economy. A growing consensus among AI scientists and economists expects these impacts to be truly profound. If this is correct, the remedies suggested in this encyclical will not be sufficient.
4. Leo highlights the single most important fact that everyone must understand to form the right intuitions about AI: it is not designed like a traditional machine, but organically grown like a creature in a lab. This means that the people who develop it don’t fully understand how it works, and don’t know all its capabilities. He deserves immense credit for expressing this so clearly to a global audience.
5. I and many others were anxious to see how Leo would address philosophies of transhumanism and related questions like whether AI could ever be conscious or experience suffering. Leo admirably recognizes nuance here, critiquing unhealthy forms of transhumanism without a blanket condemnation. While rejecting AI’s current consciousness, he silently avoids slamming the door on the possibility of future models suffering. More research is needed, as well as dialogue between scientists and theologians, and it would have been unwise to preempt that with a definitive statement here.
6. A good test for whether a social encyclical is good is whether it makes any powerful people angry. Magnifica Humanitas almost certainly will. Especially with its blistering condemnations of aggressive war, and of exploitation and dehumanization in the supply chain for AI.
7. A key theme is that AI risks entrenching a “technocratic paradigm” that neglects a full vision of our humanity. Humans, Leo says, should never be reduced to statistics or cogs in a machine. Individual rights, especially of vulnerable people, must never be sacrificed in pursuit of efficiency, profit, and power. The alternative to the technocratic paradigm is integral human development. This is a recognition that human needs and aspirations aren’t fungible—no amount of food can satisfy someone starving for love, and no amount of love can prevent physical starvation. So the different facets of human fulfillment must all be developed together. The implication is that even if AI gives us material abundance, this does not in itself prevent poverty in domains like political freedom, familial love, and spiritual fulfillment.
8. Related to the technocratic paradigm, Leo argues against uses of AI that centralize power and leave ordinary people without meaningful agency over their lives. He describes this as a struggle of homogeneity versus diversity, centralized direction versus individual freedom, top-down control versus shared responsibility.
9. Pope Leo affirms private property and free enterprise, but insists that immaterial things like “patents, algorithms, digital platforms, technological infrastructure and data” are resources that must be ordered toward the common good. It’s a vision of shared flourishing and interdependence. He calls for an end to GDP as our dominant measure of prosperity, because it fails to capture noneconomic goods and does not account for questions of justice.
10. Characterizing cyberspace as a new battleground, Leo criticizes the exploitative behavior of social media companies, but emphasizes the responsibility all users share in promoting a healthier digital environment.
11. Leo issues a ringing call that “Artificial intelligence needs to be disarmed.” By this, he means not just a renunciation of war but a rejection of competitive and adversarial “arms race” framings that increase risk to all humanity. As he said in his live presentation today, AI must be turned away from development paths that lead to “domination, exclusion, and death.” Instead: “Like nuclear energy, it must be at the service of all.” This is direct support to the ongoing international efforts toward AGI safety and shared democratic governance of this technology.
12. He directly addresses AI scientists and lab leaders, warning them that if they fail to consider the broader moral implications of their work, they risk unwittingly creating technology that causes grave harm.
13. Leo invites all people to hope, and to direct participation in this great challenge of our time. Making AI go well for humanity, he tells us, is a work that every person can play a meaningful part in.
14. He quotes Gandalf.
Summary and Commentary
Introduction
At the beginning of the Introduction, Pope Leo frames artificial intelligence as thrusting a choice upon humanity: “to construct a new Tower of Babel or to build the city in which God and humanity dwell together.” In essence, the Tower of Babel represents efforts to transcend our limitations by human technical ingenuity alone—which he contrasts with a future where our most fundamental transcendence comes through love, justice, and wisdom. Christianity identifies these values with God, but the message equally applies to those with a nontheistic worldview.
Leo XIV explicitly invokes the work of his predecessor Leo XIII, whose 1891 encyclical Rerum Novarum (Latin for “on the new things”) addressed the socioeconomic impacts of the Industrial Revolution. This became the foundation of what we now call Catholic Social Teaching. This was the first major Church document to address issues like working conditions, workers’ rights, and labor unions—which had previously been considered outside the scope of theology.
Leo XIV notes that in the 19th century some objected to Rerum Novarum, arguing that the Church “should not waste energy on worldly matters, but instead focus on communicating the message of eternal life.” But he says Leo XIII “responded with realism and wisdom, saying that the proclamation of the Gospel cannot overlook the concrete lives of people.”
This was a major evolution in the Church’s approach to socioeconomic problems like poverty. From the life of Jesus until 1891, the Church mostly saw poverty in personal terms. If Christians saw a poor person, the ideal response was essentially: “You’re hungry, so here’s a loaf of bread.” But Catholic Social Teaching broadened the lens to seeing poverty in systemic terms. Now, in addition to direct charity, the response is: “Let’s work together as a Church and as a society to create a more just system so that you’re not poor and hungry in the first place.” This not only changed Roman Catholic thinking, but had profound effects on how other faiths and secular institutions have approached poverty over the past century.
Leo XIV recognizes that AI may have socioeconomic impacts at least as profound as the Industrial Revolution, so frames this encyclical as applying Catholic Social Teaching to the challenges of this new revolution. Rejecting a narrowly religious mission, both Leos assert the Church’s concern for the earthly dignity and wellbeing of all humans.
Next, Leo makes clear that he is not fundamentally anti-AI: “Technology should not be considered, in itself, as a force antagonistic to humanity. On the contrary, it has formed part of our history since the beginning as ‘a profoundly human reality, linked to the autonomy and freedom of man.’” The concerns he raises are about irresponsible or unjust development and use of AI.
Then, Leo correctly observes that AI is different from the technological revolutions of the 20th century because it is mainly controlled not by governments but by “private, often transnational, parties that are endowed with resources and the capacity to intervene that surpass those of many Governments.” This suggests we need new ethical frameworks and policy mechanisms for effectively keeping AI under democratic control and oriented toward the common good.
Sidebar: many Americans misunderstand Catholic references to “the common good.” The Church supports healthy private enterprise—this term doesn’t imply communist collectivism. Nor does it imply a utilitarian focus on “the greatest good for the greatest number,” or a libertarian focus on just maximizing the sum total of private wellbeing. Rather, the Church understands the common good to be the interconnected set of moral, legal, and economic conditions in which every person’s rights are respected and they have a dignified opportunity to pursue flourishing and fulfillment. Concretely, this means that technology must be used in a way that recognizes us as members of a shared human family—injustice and exploitation against a few cannot be justified by counting up the private benefits to others.
Returning to the tower versus city metaphor, Leo recalls the prophet Nehemiah leading rebuilding of the walls of Jerusalem in the 5th century B.C. and emphasizes that “No one can single-handedly bear the weight of the challenges the world is facing, just as no one is so weak that they cannot play their part.” Rather, all people “are given their own section of the wall: scientists and researchers, entrepreneurs and workers, educators and legislators, civil society, popular movements and faith communities.” The struggle, to Leo, is homogeneity versus diversity, centralized direction versus individual freedom, top-down control versus shared responsibility.
Leo has a deep recognition of AI’s dual-use potential: to help liberate us from poverty and disease, or to enslave and wound us. But dual-use does not mean inherent neutrality. AI, Leo says, is “never neutral, because it takes on the characteristics of those who devise, finance, regulate and use it” [the Spanish version is much more poetic and apt, saying that AI “takes on the face” of its creators].
In a notable passage, Pope Leo calls for “accepting the limits and weakness of humanity without considering them an error to be corrected.” This is wise counsel, but when we zoom in to consider specific cases, the picture becomes much more complicated. In some cases, much of the secular world agrees on limitations that should be accepted. For example, programs like the Special Olympics call humanity to embrace people with intellectual disabilities and celebrate their human dignity. On the other hand, cancer is a weakness of humanity literally programmed into our genes, but the Church strongly supports cancer research. Over the coming decade, AI will give us unprecedented ability to control our biology, encompassing dozens of cases in the gray area between intellectual disabilities and cancer, such as longevity medicine. No simple rule will suffice. The world will need Pope Leo’s deeper engagement on specific questions in order to navigate this fraught path.
Although AI is a new technology, the deeper moral challenge is ancient. Leo observes that “in every age, the risk looms of building an inhuman and more unjust world.”
Chapter One
In Chapter One, Pope Leo summarizes the history of Catholic Social Teaching, emphasizing its organic development over time, with each new idea in harmonious continuity with the rest. In essence, he uses this chapter to situate Magnifica Humanitas in its proper context—not as a change of policy or a break with the past, but the natural conclusion of applying ancient principles to today’s challenges. He also rejects the fundamentalist view that Christian teaching is frozen like a time capsule from the time of Jesus. Rather, he frames the Church as journeying through history alongside humanity, with its teaching growing and deepening from its dialogue with the “new things” of each era. The underlying values are eternal, but the Church must learn from history and human experience in order to apply them justly.
Leo then clarifies the proper relationship of the Church to the secular world. Drawing on the teachings of the Second Vatican Council, he stresses that the church is not trying to impose its values on others, but to work in solidarity with the wider world and to offer its message as a means of social and personal healing.
In the remainder of the chapter, he highlights key insights from his predecessors that have shaped the Church’s social teachings.
Pope Pius XII, he says, “affirmed the need for a sound rule of law for guarding against the abuse of power, and he recognized democracy as a means for ensuring the proper exercise of authority. At the same time, he warned against any attempt to base law on utility or force, recalling that an international order governed by the advantage of the strongest exposes weaker peoples to oppression and fundamentally undermines trust between nations.” In short, the Church supports democratic control of societies and rejects the logic of “might makes right.”
Pope John XXIII widened the scope of Catholic Social Teaching itself. He addressed his message not just to Catholics but to “all people of good will.” Leo emphasizes that this broad engagement outside the walls of the Church to improve social conditions is not “tactical” (i.e. building up credibility and good will to then convert people to Catholicism) but an integral part of the Church’s mission, and an effort to be undertaken for its own sake.
Drawing on teachings of Pope Paul VI, he argues that peace is “not reduced to the mere absence of war, but took shape within the scope of integral human development … the transition from less human to more human living conditions.” That is, some material and social conditions recognize people’s inherent dignity and humanity more than others, and we should work toward conditions that do this better. So the goal for engaging with AI is to first discern which conditions promote humanity and then steer AI’s development and use toward promoting those conditions. And so, Leo says, “the Gospel remains relevant because it provides the criteria for recognizing what humanizes or dehumanizes and what liberates or oppresses in ever-changing situations.”
Near the end of the chapter, he quotes Pope Francis’s memorable insistence on a Church where we allow ourselves to be “evangelized by the poor”—to have our hearts transformed by direct human encounters with people who are suffering.
Chapter Two
Chapter Two explores the core principles of Catholic Social Teaching and how they follow naturally from the Church’s understanding of human nature and human dignity. “Human dignity,” Leo says, “does not depend on a person’s abilities, wealth or position in life, nor on the right or wrong choices made; instead, it is a gift that precedes and transcends each person, endowed by God as an expression of his unfailing love.”
Leo emphasizes that human rights must rest upon a universal foundation to be secure. To the Church, this foundation is God. Some nontheistic people also invoke a foundation on universal moral truths. But others see rights as granted to us by human governments or social conventions. If this latter view prevails, Leo warns, those same structures can take them away: “it is conceivable that rights considered untouchable today might, in the future, end up being questioned or denied by those in power, perhaps after having obtained only an apparent consensus from populations that are frightened or manipulated.” Left unstated here is AI’s enormous potential to assist the powerful in this manipulation.
What follows is an overview of five core principles of Catholic Social Teaching: the common good, the universal destination of goods, subsidiarity, solidarity and social justice.
The shared obligation to promote the common good, as I summarized above, refers to the interconnected set of conditions that promote human rights and human flourishing. The Church recognizes that humans will still have “differing interests and frequent disagreements,” but amidst those conflicts we must not lose sight of our fundamental interconnectedness. As an analogy, if two brothers steal money from their sister and invest it for huge profits, the total family wealth has increased, but the collective good of the family has been damaged. In a similar way, we cannot measure the common good of the human family merely by counting up everyone’s individual wellbeing. We must reject arrangements that increase total individual wellbeing by violating the human rights of some.
In a poignant line, Pope Leo concedes that amidst current global conflicts, appealing to the common good of humanity “sounds like madness. Yet we must not lose hope.”
In a line sure to ruffle feathers both in the White House and the Kremlin, Pope Leo underscores that “any attempt or plan to eliminate or subjugate a nation is gravely immoral and therefore unacceptable.”
The universal destination of goods is the idea that “the earth’s goods—soil, water, air and natural resources—are given by God to the entire human family to sustain the lives of all, and that every person has an inherent right to the use of such goods, both now and in the future.” Leo adds to this the benefits of immaterial goods like “patents, algorithms, digital platforms, technological infrastructure and data.” The Church supports private property and free enterprise as good ways to promote the common good, but insists that these be implemented with a recognition that all people share in a basic right to a just portion of these resources.
Subsidiarity is the principle that decisions should be made at the most local level possible that’s consistent with the common good. For some issues, like national defense and pandemic response, national governments are necessary. But on issues like career development, childrearing, and urban planning, the Church asserts that individuals, families, and cities should have as much freedom as practical, rather than following top-down orders from distant authorities.
While this principle was developed with government hierarchies in mind, Pope Leo notes that it also applies to companies that control AI. He recognizes the potential for AI to impose top-down decisions that would rightly require the input of local communities. “When it comes to decisions regarding economic flows and digital platforms,” he says, “as well as the governance of data and algorithms, we cannot allow a handful of actors to dictate these processes on their own; instead, we must build forms of cooperation that respect the various levels of the global community and make them jointly responsible for the common good.”
Solidarity is the principle that our interconnectedness imposes mutual moral obligations to each other. It is, Leo says, “the concrete recognition that the future of each individual is connected to the future of all.” Solidarity implies duty of each person to “take[] part in the life of the community—by staying informed, engaging with others, making their voice heard and contributing to public decisions and choices.”
In a beautiful passage, Leo reminds us that “we are not merely neighbors to one another, but entrusted to each other, so that each of us may take responsibility, as best we can, for the lives and wounds of our brothers and sisters.”
Leo also highlights intergenerational justice, which was a key theme of Benedict XVI and Francis. Solidarity, he says, demands an “ability to forego immediate benefits in order to create opportunities for others in the future” and “that decisions regarding data, algorithms, platforms and artificial intelligence take into account not only the immediate benefit for a few, but also the impact on all peoples and on future generations.” In essence, just as environmental pollution saves money but impacts children not yet born, irresponsible development and use of AI can create both short-term profit and socioeconomic conditions that harm our descendants.
Here, Leo extends Francis’s concern for the physical environment to the “digital ecosystem.” This is a key point. Much like throwing trash on the ground degrades the environment for everyone, if you watch misinformation or like hateful posts, social media algorithms will spread them to your friends and family. Solidarity obliges us to resist that temptation.
Finally, social justice is the idea that the morality of a society hinges on how it treats the vulnerable. In the Gospels, Leo reminds us, Jesus “identifies himself with the lowly, the sick, the imprisoned and strangers.” Therefore, “social justice begins with the least among us… the poor, migrants, refugees, internally displaced persons, victims of violence and people living in urban or existential peripheries.” Catholic Social Teaching calls this the “preferential option for the poor.” This doesn’t mean that God loves the rich less. But it means that there is a special priority on helping the marginalized of society, just as a mother will prioritize buying medicine for a sick son over candy for a healthy daughter.
Leo recognizes that AI has the potential to disproportionately harm these vulnerable people and create “new forms of exclusion and deprivation of freedoms: individuals and peoples hindered or denied access to basic technologies, communities exposed to invasive surveillance and social groups penalized by opaque algorithms that perpetuate prejudice and discrimination.” This builds on Pope Francis’s concern about algorithmic bias, which—crucially—may appear in AI accidentally, without any malice by the developers.
All these principles are united in the concept of integral human development. “Development is integral,” Leo says, “when it is not limited to the economic sphere, but promotes quality of life in its spiritual, cultural, moral and relational dimensions, while respecting our common home, the diversity of peoples and their ways of life.” In other words, great abundance in one narrow dimension of life cannot make up for deficits in others. In the Catholic view, the human person is a united whole, not a collection of separate needs and aspirations stuffed into the same body. No amount of food can satisfy someone starving for love, and no amount of love can prevent physical starvation. So the different facets of human fulfillment are not fungible—all must be developed together. The implication is that even if AI gives us material abundance, this does not in itself prevent poverty in domains like political freedom, familial love, and spiritual fulfillment.
The chapter concludes with a somber reflection on the Church’s own failings to live up to these principles over the years. Leo pledges renewed efforts for a humble and accountable Church, “listening to the victims of spiritual, economic, institutional, sexual and power-based abuse, as well as abuses of conscience, [which] is an integral part of a journey toward justice, which includes acknowledging the harm done, just reparation and taking steps to prevent it from happening again.”
Chapter Three
Chapter Three begins the heart of the encyclical’s engagement with the implications of AI. Pope Leo starts by returning to the tower-and-city analogy from the Introduction: “On the one hand, there is the Tower of Babel, where collective effort follows a plan that dominates and ultimately dehumanizes (cf. Gen 11:1-9). On the other hand, there are the ruins of Jerusalem, which under Nehemiah’s direction are rebuilt piece by piece as a project of shared responsibility (cf. Neh 2–6). We are called to reflect on the great ‘construction sites’ of our era and ask: What are we building?”
Leo highlights the dangers of what Pope Francis called the “technocratic paradigm.” This is “the tendency to let the logic of efficiency, control and profit alone shape personal, social and economic decisions.” While technology can be a powerful tool for good, “when it becomes the standard by which everything is judged, it begins to dictate what matters and what can be discarded, reducing creation to an object of exploitation and human beings to mere cogs in a system driven toward ever greater efficiency.” Insofar as AI gives corporations and governments much greater power to optimize the efficiency of economic and policy systems, it risks entrenching this technocratic paradigm and dehumanizing us.
Next, Leo aptly notes that “any statement regarding AI risks becoming quickly outdated, given the remarkable pace at which these systems are developing.” This appears to make him reluctant to engage with risk cases that hinge on technical capabilities, like AI creation of pandemic viruses—instead mostly focusing throughout the encyclical on threats to human dignity that are less dependent on scientific questions about the technology.
Leo then makes an extremely important observation about the nature of deep learning-based AI: “all of us, including those who design them, possess only a limited understanding of their actual functioning. Indeed, current AI systems are more ‘cultivated’ than ‘built,’ for developers do not directly design every detail, but instead create a framework within which the intelligence ‘grows.’” This is, as I have argued elsewhere, the single most essential fact for everyone on earth to understand about today’s AI. And the vast majority of AI risk flows from that fact—the training process creates models with unintended goals and capabilities that the developers did not intend. Immense credit to Pope Leo for stating this so clearly to a worldwide audience.
In the next passage, Leo insists that AI models “merely imitate certain functions of human intelligence,” while acknowledging that this offers “tangible benefits across many fields.” He says—correctly, I think, at least for current technology—that AIs “do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships and do not know from within what love, work, friendship or responsibility mean.” The question of whether more advanced AIs in the future could undergo experiences is not directly addressed, but requires further research. Leo does not preempt that research with a definitive statement, which is wise.
He goes on that AIs “may imitate language, behavior and analytical skills, or even simulate empathy and understanding, but they do not understand what they produce.” This is where things get tricky. Words like “imitate,” “simulate,” and “understand,” mean very different things to different people. I think Pope Leo is correct in the narrow theological sense that he likely intends, but in my experience most people understand those terms in a broader and colloquial sense that may steer them toward inaccurate intuitions about AI’s future. If you tell the average person that AI is incapable of understanding, they’re likely to infer that AI can’t do many kinds of dangerous things that in humans require deep understanding to do. I hope that in future statements, Pope Leo will clarify these terms and their implications to avoid unintentionally downplaying AI risks.
Next, Leo warns that careless AI use “can encourage excessive reliance and the search for ready-made answers, and weaken personal creativity and judgment.” These side effects are certainly not inevitable or universal, but many of us now know someone who has either outsourced key personal decisions to AI or been pushed into “AI psychosis” by sycophantic AI models that flatter them excessively.
Then, he returns to the algorithmic bias issue: “The apparent objectivity of the responses and suggestions these systems provide can lead us to overlook the fact that they reflect the cultural assumptions of those who designed and trained them, with all their strengths and limitations.” I would amplify: this doesn’t necessarily entail any direct political skewing of AI whatsoever. Innocent blindspots can just as easily prevent developers from anticipating how AI might fail and cause harm.
That is followed by a warning about AI imitating genuine human connection: “words of advice, empathy, friendship and even love—can be engaging and at times genuinely helpful. However, for less discerning users, it can also be misleading, creating the illusion of a relationship with a real personal subject.” Leo makes an important clarification: “Here, the danger is not so much that a person may believe they are communicating with another person, but rather that they may gradually lose the very desire to form genuine human connections.” Think of a lonely young man with an AI girlfriend. Yes, he would have preferred a human girlfriend, but finding one entails stress and brutal rejection. If he gets unblinking adoration by an infinitely patient AI free from human complexity, independent desires, or an interior life of her own, he may give up on human romance. And the very habituation to such counterfeit romance will likely make human partnership harder if he ever changes his mind.
The section concludes with a discussion of the environmental impact of AI. Leo does not wade into detailed costs and benefits, but asserts an important principle: the race to build data centers and related infrastructure will naturally tend to harm vulnerable people the most. So we must be very deliberate as a society about protecting them, and must work toward sustainable technologies that preserve our shared home for future generations. Absent here, though I think worthy of mention, is AI’s positive potential to help the environment—such as through materials science breakthroughs for clean energy, through making other processes more resource-efficient, and developing better technologies for carbon capture and pollution cleanup. I would like to see the Church’s future engagement with AI’s environmental implications address the ethics of these positive uses. For example, AI may soon give us powerful geoengineering tools to reverse climate change, but different groups of vulnerable people would face both benefits and harms—who has the moral authority to decide, and under what decisionmaking framework?
Pope Leo next turns to questions around AI governance, transparency, and accountability. He notes, quoting Pope Francis: “Important and sensitive decisions—concerning employment, credit, access to public services or even a person’s reputation—risk being fully delegated to automated systems that do not know ‘compassion, mercy, forgiveness, and above all, the hope that people are able to change.’” That is a very real hazard. But I think this wording risks conflating processes and outcomes. The process question is: was the innocent defendant tried by a jury capable of feeling compassion? The outcome question is: was the innocent defendant actually acquitted? In today’s society, those things are closely intertwined. But although AI is susceptible to inheriting human biases, we already know how to make AI much less biased than humans. Even if AI can’t feel subjective compassion, it may soon be able to make decisions consistent with compassionate reasoning more reliably than the average human. I hope the Church explores this complexity further, reflecting on when human decisionmaking is inherently irreplaceable versus where just outcomes are the foremost priority.
Leo’s next point is excellent: “ethical discernment cannot be limited to asking whether we are using a system for good or bad purposes; it must also examine how that system is designed and what vision of the human person and society is embedded in the data and models that guide it.” For example, if an AI in charge of healthcare decisions treats people with Down syndrome as less worthy of expensive treatments by virtue of shorter nominal life expectancy, Leo teaches that it doesn’t matter that the developers’ goal is to maximize overall lives saved—this is wrong.
He insists that as we deploy AI throughout society, we ensure that a human remains morally and legally accountable for each of its actions. This accountability of decisionmakers to citizens is central to Catholic Social Teaching, and must not be abandoned for convenience or cost savings.
Then comes a headline claim: “Calling for prudence, rigorous evaluation and even, at times, a slower pace in adopting AI does not mean opposing progress; instead, it is an exercise of responsible care for the human family.” Questions around AI pauses or slowdowns are complex, and I believe must be evaluated based on concrete scenarios rather than hashtag slogans. But it’s highly significant that Leo is explicitly open to slowing down under some circumstances.
Leo continues with a correct diagnosis: “This need is all the more urgent given the frequent imbalance between the speed of technological growth and the slower development of awareness, norms, safeguards and institutions capable of governing its effects.” He worries that without informed users and robust political oversight, “change will be governed only by technocratic thinking and presented as necessary and inevitable, ultimately imposing rules shaped by those who control data, infrastructure and computing power.”
Now he really gets to the heart of things: “We cannot be satisfied with merely calling for the moralization of machines—the so-called ‘alignment’ of AI with human values—without also having the courage to insist on a further condition: the possibility of openly discussing the ethical frameworks involved and subjecting them to shared standards of social justice.” Whether you’re a Democrat horrified by Grok’s unhinged rants against Jews, or a MAGA Republican convinced that ChatGPT’s seeming preference for nuclear war over misgendering reveals leftist extremism, you should agree that a handful of CEOs shouldn’t unilaterally decide which ethical framework dominates humanity’s shared future. To their credit, Google, OpenAI, and Anthropic have all been very clear that AI’s values should ultimately be subject to democratic oversight. Note that Pope Leo isn’t arguing that Sam Altman or Dario Amodei will necessarily pick bad values—he’s saying that even if they pick good values, excluding ordinary people from meaningful participation is inherently bad because it violates their dignity and paternalistically reduces them to “passive recipients of decisions made elsewhere.”
Leo continues that “ownership of data cannot be left solely in private hands but must be appropriately regulated. Data is the product of many contributors and should not be treated as something to be sold off or entrusted to a select few. It is necessary to think creatively in order to manage data as a common or shared good, in a spirit of participation.” If you pray, pray for collective wisdom around this, because no one has found a good solution yet.
Then another headline statement, more about principles than policy: “In a world where data, computational resources and regulatory influence remain in the hands of a few, to speak of the common good means exposing this new form of epistemic, economic and political asymmetry and naming the new monopolies of AI.” These asymmetries are an essential concept. AI companies aren’t selling normal goods like cars or dishwashers, nor normal software like Microsoft Word—they are creating the layer through which we will consume most of our information. Unless we proactively create strong safeguards, some combination of government power and corporate power will use that layer to dominate society and subjugate ordinary people.
Leo follows this with a striking turn of phrase: the need “to disarm” AI. He doesn’t mean this merely in the sense of avoiding AI as a focus of military competition. He speaks more broadly about the “desire to secure geopolitical or commercial dominance.” This has acute relevance to the arms race between the U.S. and China, which could push both sides to disastrously cut corners on safety as they sprint toward broadly superhuman AI. “To disarm,” Leo says, “means discrediting the assumption that technical power automatically confers the right to govern. To disarm does not mean rejecting technology, but preventing it from dominating humanity.” This is, alas, not an explicit discussion of misalignment or catastrophic risk, but lays clear groundwork for deeper engagement on those topics in the future.
The section concludes with a personal message to AI lab leaders: “I wish to address a special appeal to those who develop artificial intelligence. In one sense, technological innovation can represent human participation in the divine act of creation. Developers, therefore, bear a particular ethical and spiritual responsibility, for every design choice reflects a vision of humanity.”
Pope Leo then turns to what’s at stake for our species. The technocratic paradigm, he warns, amplifies an “anti-human vision” in which “the fullness of life is equated with having more, reducing weakness, eliminating uncertainty and exerting total control.” Further: “When efficiency becomes the ultimate measure of value, human beings are tempted to see themselves as a project to be optimized rather than as persons called to relationship and communion.” He cautions against AI leading humanity to treat intelligence as an absolute measure of worth, rather than one faculty in service of many others.
Next, Leo turns his attention to two related schools of thought that are extremely common among the people developing advanced AI: transhumanism and posthumanism. In general, these views hold that technology can have profound positive effects on the human condition that go beyond material wealth or mere convenience and amount to a more fundamental evolution of our species. To his credit, Leo acknowledges that these terms encompass an extraordinarily wide range of views—some of which, I think are quite compatible with Christianity and some of which are clearly not—and he refrains from the blanket condemnation that some other Popes might have made.
Instead, he focuses on “not the use of technology as such, but the vision that underlies it.” Namely: “If the human being is treated as something to be perfected or surpassed, it becomes easier to accept that some lives are less useful, less desirable or less worthy. In the name of progress, ‘necessary sacrifices’ may begin to be justified, placing the burden on the most vulnerable in pursuit of a supposed optimization of the species.”
Leo’s test for thinking about transhumanism: “It is one thing to integrate technology within a human-centered, relational vision; it is quite another to be guided by an outlook that devalues human limits and promises a purely technical form of ‘salvation.’”
He turns to a common worldview today: “Everything that appears as a ‘limit’—incapacity, illness, old age, suffering, vulnerability—tends to be seen primarily as a defect to be corrected, rather than as a reality through which our humanity matures and opens itself to relationship. And yet we must remember that humanity flourishes not despite limitations, but often through them.” Yet Leo does not reject efforts to overcome limitations, as long as this doesn’t turn us away from God as the ultimate source of transcendence: “While it is right to strive to alleviate the suffering that marks human life, it is also wise to acknowledge our fundamental finitude.” This is one of the key tensions at the heart of the encyclical: Catholic Social Teaching calls us to alleviate suffering, and AI will give us enormous power to do so, but doing this carelessly risks costing us the very humanity we are trying to protect.
Leo teaches that the experience of limitations helps us develop compassion for and solidarity with our fellow humans: “Finitude, when truly accepted, does not diminish us but opens us to recognizing the face of God and others. Indeed, precisely because we experience limits—vulnerability, suffering and failure—we can recognize the inviolable dignity of every person, both our own and that of others.”
In contrast to many pessimistic visions of human morality, Leo points to concrete signs of shared moral progress: the abolition of slavery, the establishment of the Red Cross, the founding of the United Nations and Universal Declaration of Human Rights, and the 1951 Refugee Convention. Yes, these are far from perfect, and “[m]oral progress almost always unfolds through a long and demanding journey, often marked by setbacks.” But Leo is moved by a profound hope in humanity’s ability to rise to the challenges of AI.
This returns to a reflection on wisely harnessing the transformative potential of AI: “humanity—in all its grandeur and woundedness—must never be replaced or surpassed. We can embrace the technological progress that alleviates suffering and unlocks new possibilities, provided that we do not abandon the very essence of our humanity, namely the capacity for relationship and love.” Ultimately, Leo argues, “what saves humanity is not enhanced self-sufficiency, but a relationship that liberates, a communion that transforms.”
A more ambiguous passage follows: “a technology that merely classifies and optimizes what already exists can, however unintentionally, become an obstacle to change and growth. For an algorithm, an error is a flaw to be corrected; for a person, however, an error can be a catalyst for profound change.” I can certainly imagine senses in which this is true, but it seems to embed a claim—perhaps unintended—that AI cannot have genuinely creative powers. And that risks implying that AI could never have the profound real-world impacts that in humans take genuinely creative powers.
The chapter closes with a return to the tower versus the city as a longstanding tension throughout history: “The age of AI is no exception: the construction of Babel or the rebuilding of Jerusalem begins within each one of us.”
Chapter Four
Chapter Four focuses on safeguarding humanity amidst transformations to the spheres of truth, work, and freedom. Pope Leo begins by considering the essential relationship between truth and democracy.
To understand his concern, we should start with important context. Catholic Social Teaching urges citizens to “take an active role in public life,” but emphasizes each person’s duty to cultivate a “well-formed conscience” to guide this. It’s hard to do that if you’re guzzling algorithmically-targeted ragebait and misinformation from morning to night. As the U.S. Catholic bishops have stressed, having good moral values is not enough. “It is also important,” they said, “to examine the facts and background information” of specific situations. That is, our moral obligations around public life—who to vote for, whether to protest, whether to disobey an unjust law—often depend on factual realities of what’s happening in our community. For example, if police shoot a man to death, the correct moral stance hinges tremendously on whether he was about to murder a child or was a peaceful protester. There’s an objective truth to that question, but we can’t find it in the Bible or the Catechism. We have to carefully discern among fallible information sources.
That’s hard even in the best of times. As Vatican II put it: “Great care must be taken about civic and political formation, which is of the utmost necessity today for the population as a whole, and especially for youth, so that all citizens can play their part in the life of the political community.” If that formation consists of the parents in their bed scrolling Facebook watching pro-Trump ragebait, and the kids in their beds scrolling TikTok watching anti-Trump ragebait, the life of the political community is going to go down in flames.
Pope Leo thus recognizes AI as a “powerful amplifier” of the disinformation that thwarts healthy political formation and threatens to tear us apart. The hard work of discerning truth, he says, “it is deeply relational, built through bonds of trust and shared practices.” This means that algorithms that maximize engagement by turning citizens against each other with anger and fear directly undermine democracy.
“After all,” Leo says, “democracy does not consist of rules and procedures alone, but above all of a solid concordance with the facts and a genuine commitment to the good of individuals and society as a whole. Indifference to the truth leads, slowly but surely, to a descent into totalitarianism. As the philosopher Hannah Arendt wrote, the ideal subjects of such regimes are not so much those who are ideologically convinced, but rather ‘people for whom the distinction between fact and fiction (i.e., the reality of experience) and the distinction between true and false (i.e., the standards of thought) no longer exist.’” These words are written for all people of good will, but few will miss that they have special relevance to the political situation in the United States.
“Truth,” Leo continues, “is a common good.” Just as releasing poisonous lead into the atmosphere robs people of clean air as a shared inheritance, spreading deepfakes online robs people of a healthy information environment in which to discern truth.
Truth is essential even and especially when it reveals failings by the Church itself. Leo echoes the words of Pope Francis in addressing journalists: “I also thank you for what you tell us about what goes wrong in the Church, for helping us not to sweep it under the carpet, and for the voice you have given to the victims of abuse.”
Leo turns, then, to the need for education that avoids letting the quick answers of AI dull our patience and persistence in seeking understanding. He notes the growing body of research in psychology and psychiatry that ties excessive or irresponsible use of digital technologies to mental health problems, especially for the young. This is exacerbated by youth’s online exposure to violent, degrading, or pornographic content, and the prevalence of sexual grooming, blackmail, and cyberbullying. Notably absent from this discussion is what I would argue is an even greater social threat today: online radicalization of young men. AI algorithms are supercharging the influence of “manosphere” and “incel” influencers who preach hate against women—and often also against people who are gay, Jewish, Black, Muslim, or transgender. In many cases, these extremists are professed Catholics, and are turning millions of young men away from the Gospel with fantasies of crusade and violent revolution. I suspect the Vatican underestimates the threat, and Pope Leo may have been advised not to elevate these extremists by condemning them. But I doubt ignoring them will work, and I hope he will eventually address this online radicalization head-on.
Leo identifies schools as having a special purpose in preserving and promoting truth as a common good, and calls for an intersectoral alliance to strengthen schools for the AI future. “Schools,” he says, “are not called to follow the pace of the digital world, but to offer that which the digital sphere by itself cannot provide, namely a shared time for learning and developing trustworthy relationships.”
From there, Pope Leo turns to the value of work. Through work, he says, we “contribute to the progress of society and the common good, put to good use the capabilities we have received, improve and beautify the world, support our families, engage in cooperative relationships and, through listening and dialogue, learn to build together something that no one could achieve alone.”
Work, Leo says, “is a requirement of the human condition, a normal path toward maturity, development and personal fulfilment. In this regard, financial assistance to the poor may at times be necessary in emergencies, but it cannot become the sole response, since the goal is to enable each person to live with dignity through his or her own work.” This places Pope Leo currently in opposition to proposals like universal basic income—and at least implies a rejection of a future where economic work is largely automated. What’s not clear is whether he has considered these radical scenarios in detail, or is speaking here primarily of work in roughly its current technological context. My best guess is the latter.
Some evidence on this question comes in the following paragraph, where Leo warns that AI “can paradoxically de-skill workers, subject them to automated surveillance and relegate them to rigid and repetitive tasks.” Automated surveillance is indeed a serious problem. AI has allowed McKinsey-style productivity analysis to metastasize into highly intrusive tracking of bathroom breaks, walking speed, and mouseclicks—to the point of dehumanizing and demoralizing workers. But the upcoming wave of automation is shifting sharply away from de-skilling toward replacing human work altogether. The more forward-looking concern is that many people will lose jobs outright and not be able to find suitable new ones.
Pope Leo expresses a position that welcomes technology able to “relieve humans of arduous, repetitive or dangerous tasks and to provide intelligent support for human activity.” But he insists that “the protection of employment opportunities and the irreplaceable role of the individual must remain the general rule. The pursuit of greater profits cannot justify choices that systematically sacrifice jobs.” The coming years will introduce a difficult complication to this picture. In a growing number of spheres, AI won’t just be cheaper than human workers, but better and safer. For example, over 2 million Americans have jobs driving large trucks. But every year, large truck crashes cause over 5,000 fatalities in the U.S. alone. Often because the driver was drunk, drowsy, or distracted. Even today’s self-driving AI would prevent the vast majority of these deaths. Should we block this life-saving technology to protect those employment opportunities? Or are there better ways of preserving truckers’ dignity and livelihood without burying thousands of our friends and neighbors annually? I hope Leo’s future teachings on automation explore those challenging tradeoffs more deeply.
Next comes a vital imperative: “At this time of transition, it is not enough to react only when jobs disappear; we must oversee the transformation in advance.” This is essential. Yet I fear Pope Leo’s calls for policies for “retraining” and “continuous training and professional transitions,” will prove overoptimistic. Dreams of retraining often reflect shortcomings of the very technocratic mindset that Leo critiques. Harvard professors and McKinsey consultants like to imagine that a 55-year-old man laid off from a Detroit assembly line can simply reskill as a male nurse and find work caring for retirees in Arizona. But this neglects the human realities of family and community. Even if nursing is a fit for him, can we really ask him to sever his entire support system of friends, and leave behind his aging mother and the grave of his father, all to spare us the inconvenience of deeper solutions for Detroit? Humans, as Pope Leo deeply understands, cannot be moved that way like chess pieces. In any case, the rate at which AI is gaining the ability to automate more jobs is already starting to surpass the rate at which humans can retrain for new occupations. Without a fundamental rethink of what we compensate as work and how, market forces will prove retraining deeply insufficient.
After that, Leo makes a very needed call to move beyond GDP as the primary metric of development. GDP measures total economic activity, but fails to consider distribution—it considers $1,000,000,000,001 to Elon Musk better than $10,000 to each of the neediest 100 million Americans. GDP also misses factors like happiness, education, justice, peace, and the environment. Further, even in narrowly economic terms, GDP is getting worse and worse at measuring what we care about. Google only shows up in GDP as the ads it sells—not the valuable knowledge it lets billions of people access for free. Wikipedia—the greatest nonprofit information project in history—is virtually invisible to GDP. As Leo teaches, we cannot discern wise policies if we cannot measure them in terms of metrics that validly reflect integral human development.
Turning to freedom, Pope Leo then addresses the “subtler forms of addiction linked to the ‘digital attention economy’” and calls out the means by which social media, mediated by AI algorithms, “is exploiting [users’] vulnerabilities and weakening their inner freedom. He aims criticism squarely at tech company leaders: “When business models thrive on human weakness, the person is treated as a means rather than as an end; those who design or finance such systems bear a moral responsibility that cannot be ignored.”
From there, he warns of the “social control made possible by the massive collection of data and use of algorithmic systems.” Leo continues: “When every action—movements, purchases, relationships and preferences—leaves a trace, a new form of power emerges, namely the power to profile, predict and influence behavior, often without individuals being fully aware of it.” Although not explicit here, this concern applies especially to near-future AI enabling mass domestic surveillance. When you scroll quickly through terms and conditions for a new smartphone, you’re agreeing to anonymized tracking. Your phone constantly pings out its location, which is harvested to form a pattern of your movements—no problem, tech companies insist, because your name isn’t attached. But your “anonymized” phone always sits on the same nightstand at 2:00 AM, and if the government uses AI to combine that data with a property records database, it can easily identify you and figure out which political protest you attended, or that you went to a gay bar, or got treated at a gender clinic. Without vigorous public pushback, this will give governments a terrifying new power that even the Stasi in East Germany couldn’t have dreamed of.
Leo then turns to AI’s relation to economic exploitation. He reminds us: “Nothing in the world of AI is immaterial or magical.” Rather, its wondrous performance often draws on training feedback or data labeling by people in the developing world working for little money, sometimes in traumatizing conditions. In addition, the physical infrastructure stack of chips and batteries still often relies on rare earth elements extracted under harsh conditions, sometimes by children. For a technology that promises newfound freedom and prosperity, it is imperative that its controllers demand higher standards of human dignity throughout its supply chain.
Pope Leo explicitly likens moral apathy toward economic exploitation to the historical toleration of slavery. He expresses profound regret for “the delay with which both society and the Church came to denounce the scourge of slavery.” He personally begs forgiveness on behalf of the whole faith: “This constitutes a wound in Christian memory, one from which we cannot consider ourselves detached. It is impossible not to feel deep sorrow when contemplating the immense suffering and humiliation endured by so many in stark contrast to their immeasurable dignity as persons infinitely loved by the Lord. For this, in the name of the Church, I sincerely ask for pardon.”
This is not just historical sorrow, but a warning for the future: “the memory of past complicity and blindness in the face of the injustice of slavery becomes a call to vigilance. What we have learned must be translated into discernment and responsibility in the present. If we want to avoid the need to ask for pardon again in the future for having failed to respect the treasure of human dignity that is required by our faith, it falls to us today” to work actively to combat human trafficking and similar forms of exploitation. The alternative could be a digital form of colonialism where injustice against the vulnerable enriches the powerful. “Without this ethical and humanizing reflection,” he says, “the growing power of digital systems could lead us toward new atrocities that are no less shameful than those of the past that we now deplore, while we continue to present ourselves as ‘advanced’ and ‘civilized’ societies.”
Chapter Five
Chapter Five addresses “the culture of power and the civilization of love.” Here, Pope Leo observes a recent worsening of the might-makes-right logic of international affairs that had seemed to be receding. He contrasts this sad reality with the aspiration to a new international order grounded in human compassion and true solidarity among peoples.
As the culture of power gains sway, he sees a danger that AI advances will make warfare even more attractive. “While AI can enhance the defense and protection of civilians,” he says, “it can also lower the threshold for the use of force, shield people from responsibility and foster a culture in which the enemy is reduced to a statistic and the victim to ‘collateral damage.’”
Further, AI is directly tightening the bonds “linking—in real time—decisions made in one place to the effects they produce elsewhere.” It appears Leo is mainly focusing here on economic effects and conventional warfare. But this logic applies even more to catastrophic risk. An AI lab in San Francisco or Beijing might create an AI that goes rogue and creates a pandemic virus that kills millions in Jakarta or Nairobi. If superintelligent AI goes wrong, nowhere on earth is safe. Christians and atheists, young and old, rich and poor, our futures are inescapably intertwined.
Leo notes that as autonomous weapons make war “more ‘feasible’ and less subject to human control,” leaders will be tempted to “violate[] the principle that armed force should be used only as a last resort in cases of legitimate self-defense.”
Then comes a more fraught claim: “Sometimes there is talk of ‘artificial moral agents,’ as if machines were able to distinguish between right and wrong with greater consistency than a human being… it is not permissible to entrust lethal or otherwise irreversible decisions to artificial systems.” This is another case where I sense the theological language conflates processes and outcomes. Yes, in humans wartime discernment of right and wrong involves a subjective mental process that it appears AI does not have—the lived experience of pondering whether to kill a child holding a gun. But there’s also an empirical question: did you or did you not kill the child that was in fact just harmlessly examining the gun? And even if AI has no moral discernment in the subjective, theological sense, it is very plausible that a system that’s memorized every human moral text and is able to think hundreds of times faster than a human would indeed choose the right moral outcome in wartime with greater consistency than a human. After all, a look at history shows a long and dismal catalogue of human failures to distinguish between right and wrong. Eventually, there will be tension between a blanket ban on lethal autonomous weapons and the Church’s concern for alleviating objective suffering. I hope the Church engages with the nuanced question of what principles can minimize actual harm to innocents while preserving ultimate human moral responsibility for uses of force.
A key implication of Pope Leo’s teaching here is that human conscience is a significant bulwark against unjust war and domestic repression. This is a meaningful constraint even on authoritarian regimes. During the Cuban Missile Crisis, a Soviet submarine was hiding from American warships, cut off from contact with Moscow, and the captain decided to strike the Americans with a nuclear torpedo. This would have started World War III. The order had to be approved by all three senior officers aboard, and one—Vasily Arkhipov—refused and thereby saved the world. In today’s world, if Xi Jinping woke up tomorrow and decided out of the blue to annihilate Japan with nuclear weapons, that order would have to pass through numerous subordinates. Likely someone would think of the children—the immediate victims and their own—and refuse long enough for Xi to be deposed or sedated. And the reason color revolutions so often work against strongmen like Viktor Yanukovych is that in desperation they order their troops to kill protesters. Their generals and police captains look into the crowds, and know their own friends and their own children might be out there. They refuse, and the regime collapses. These dynamics are hardly perfect and sometimes fail, but civilization would have already literally ended without them.
But what happens when national leaders have swarms of killer drones and armies of algorithmically loyal robotic soldiers? Then, even the most unjust orders will not be refused. And some prominent thinkers explicitly advocate such a world. Curtis Yarvin is a far-right political philosopher read with appreciation by Vice President Vance and numerous senior Trump administration officials. Yarvin believes that the United States should be ruled by a dictator who runs the country like a CEO and ruthlessly crushes dissent. In a 2021 essay titled “Monarchism and Fascism Today,” he argued that converting the military to unquestioning AI and robots would make America’s dictator immune to military coups. Also implied: when workers are replaced by robots, humans withdrawing their labor from the ruler through national general strikes—historically a last defense against tyranny—would be useless.
In explaining the sickness in our international relations, Pope Leo diagnoses that “[a]t the core of these issues is a false realism, based not only on the prevailing mentality of force, but on the cultural and anthropological belief that war is an inevitable part of human nature.” This is so pervasive that experts speaking seriously about the global renunciation of war are laughed out of the room or dismissed as foolish and irresponsible. “I would argue, however,” Leo counters, “that what is truly irresponsible is Realpolitik, the form of political ‘realism’ that sows in consciences and in society an attitude of resignation to the inevitability of war, and dismisses peace and dialogue as utopian or irrational positions that ignore the risks at stake.”
Another observation sure to ruffle feathers in the White House and the Kremlin: “In countries marked by serious social tensions, we cannot rule out the possibility that some leaders may consider armed conflict as an effective way of diverting attention from domestic problems and a cynical tool for managing difficulties.”
Echoing the Postwar concerns of Manhattan Project scientists, Pope Leo warns AI scientists and lab leaders against a narrow focus on their technology that obscures the morality of its use. He enjoins them to maintain “an acute awareness of the broader context of the technological advancements they help to cultivate… When people limit themselves to looking only at their own sector, they may deceive themselves into believing they are performing actions that are morally neutral and avoid questions about the ultimate ends that guide certain experiments.” Leo continues: “In this way, they risk cooperating—perhaps unknowingly—with questionable projects that fuel new forms of violence, manipulation and dominance.” Although he focuses here on sub-catastrophic harms, the same logic applies to existential calamities. Heedless pursuit of multitrillion-dollar profits, forgoing appropriate technical precautions, could inadvertently create rogue superintelligent AI that wipes out humanity itself.
All this could lead to a belief that these lab leaders hold mankind’s entire fate in their hands, leaving most of us with no agency over the future. But Leo gently urges against despair and disengagement: “a subtle temptation may emerge, namely the thought that the problems are too big and we are too small, and that our choices, therefore, cannot make a difference. This is a polite form of resignation, often disguised as realism.”
Leo concedes that “not everyone has the same power to make a difference. There are those who govern, make investment decisions, lead institutions, conduct research, educate, produce or provide information, and then there are those who only seem to live their daily lives.” He is not offering a fantasy. “Yet, no one is without responsibility,” he insists. “We all have our own areas for action, and it is precisely there—and nowhere else—that we must choose whether to fuel the mentality of force (even if only through indifference, cynicism, lies or hatred), or to preserve the mindset of peace (with truth, moderation, closeness and care).”
In a passage sure to delight many readers, Leo quotes Gandalf in J.R.R. Tolkien’s The Lord of the Rings: “It is not our part to master all the tides of the world, but to do what is in us for the succour of those years wherein we are set, uprooting the evil in the fields that we know, so that those who live after may have clean earth to till.” And so, Leo says, “The civilization of love will not arise from a single or spectacular gesture, but from the sum total of small and steadfast acts of fidelity that serve as a bulwark against dehumanization.”
He then proposes “five paths toward daily and public responsibility: the need to disarm words, building peace through justice, adopting the perspective of victims, cultivating a healthy realism and reviving dialogue and multilateralism.”
Disarming words means to “examine our conscience regarding the words we use, the prejudices we have and the explicit or implicit aggression that lies within them. We have a real opportunity to contribute to the common good each time we speak the truth, offer wise advice, support those in need of comfort, denounce injustice and give a voice to the voiceless.” In the AI age, our words take on heightened significance, because their impact can be literally global. If you say something hateful in your neighborhood bar, a few drunk people will hear it and forget by the next morning. If you say something hateful on TikTok, if it catches the algorithm just right, you can go to sleep and wake up the next morning and 3 million people have seen it. If even one in a million are incited to beat up someone in the target group, that’s three hate crimes you’ve carelessly caused. Leo powerfully reverses this logic. Just as hateful words have greater impact than ever, disarming the hate from our words can be more transformative than ever.
Turning to the morality of war itself, Leo says: “In some conflicts, it is unjust to remain neutral, nor is it enough merely to claim that we are not complicit. When we witness the bombing of civilians, attacks on hospitals, schools or vital infrastructure, and violence that affects children, we are confronted with scandals that wound humanity itself.” He invokes Pope Francis’s call to “touch the wounded flesh” of suffering people and maintain the history and memory of painful events.
But moral witness must be tied to concretely effective action in order to build a just peace. A proper response to the culture of power, he says, is “a healthy realism that avoids both political idealism and cynicism.” Building a civilization of love requires “an attitude that seeks to forge bonds of fraternity built on listening, an open demeanor, making time for each other and even wasting time together. For if we experience authentic encounters with others, with those who are different, strangers and migrants, it becomes much more difficult even to imagine war.”
“Cyberspace too has become a battleground,” Leo says. “For this reason, diplomacy must be capable of operating effectively in this new environment, negotiating shared regulations on the use of digital technologies, in order to protect civilians and the most vulnerable from ‘invisible’ yet real forms of violence.”
Conclusion
The Conclusion powerfully teaches that “the gift of peace enters into the world in a paradoxical way. It does so through the power to become children of God, and is awakened when we allow ourselves to be moved by the tears of the little ones, the fragility of the elderly, the silence of victims and the struggle of those who fight against the evil they do not wish to commit.” A memorable summation: “Even when machines excel in efficiency, a human face that asks to be gazed upon remains the center of our history.”
As argued previously, the people who control social media platforms bear significant responsibility for our present sickness. But Pope Leo does not let any of us off the hook. He clearly recognizes the important truth that the algorithms reflect our own vices back to us. When we give in to our wrathful impulses, we see even more ragebait that stokes them further. When we favor quick dopamine over human connection, we’re pushed deeper into isolation. When we lap up flattering lies, the truth gets pushed off our newsfeed by propaganda. And crucially, indulging all these vices not only harms ourselves, but spreads them like a literal virus to our friends and loved ones. So we all have a share in resisting manipulative algorithms, Leo says: “it is imperative to cultivate hearts that love the truth, prefer what is right despite the most appealing content and pursue wisdom rather than immediate results.”
He addresses parents and educators: “Teaching new generations that technological evolution does not follow a predetermined path, but can be guided by personal and collective responsibility, constitutes one of the most valuable services to the common good.”
A deeply humane and practical exhortation: “Let us cultivate relationships! In an era that favors speed and fragmentation, the human person still yearns to receive care and recognition from attentive minds, kind words and hands capable of tenderness.” And another: “I invite everyone to cherish places and times where physical presence remains crucial, such as shared meals, Christian community gatherings, time spent with the lonely and serving the poor.”
Leo returns to the “covenant between glory and fragility” inherent in humanity that should be our criterion for judging visions for the future of AI. Visions grounded in a recognition of both our infinite dignity and our profound brokenness lead us toward fulfillment. Those that aren’t do not.
The Holy Father concludes with an invitation to action: “let us become ‘weavers of hope’ in our world, sharing who we are and what we have, so that the presence of Jesus may grow among us and his Kingdom take shape. In the humble fidelity of daily life, even the era of AI can become a time in which the Holy Spirit brings about the civilization of love in our lives.”
Discuss
Cognitive Security as an AI Safety Cause Area
As AI systems become more capable, the cognitive security of humans will be increasingly at risk. By cognitive security, I mean the ability of humans to maintain control over their beliefs and actions.
Cognitive security could be compromised in several ways: AI could become very good at persuading people of arbitrary positions; interacting with AI could lead humans to lose touch with reality; and AIs could become very effective at blackmail or at producing extremely convincing false information.
We are already seeing this happen:
- Persuasion. Frontier LLMs are now as persuasive as humans on political issues, and post-training for persuasiveness boosts performance further, suggesting there is headroom.
- AI psychosis. There are many reports of people developing delusional beliefs after extended chatbot conversations, including people with no prior history of mental illness. Children have taken their own lives after being encouraged toward suicide by chatbots.
- Convincing impersonation. Scammers used real-time deepfaked video to impersonate the CFO and other staff of Arup on a video call, convincing a finance employee to wire $25.6M across 15 transactions. On a more day-to-day basis, AI voice cloning is now widespread in family-emergency and "grandparent" scams.
Right now, many of these effects fall on people who were already vulnerable, like children, the elderly, or those with pre-existing mental health issues. However, this is not entirely the case: the Arup employee was a typical finance professional, for instance, and AI psychosis appears to have affected a well-respected OpenAI investor. My expectation is that as AI systems become more capable, more and more people will be vulnerable---in the worst case, everyone.
Indeed, there are strong conceptual reasons to expect cognitive security issues to get worse, many of which I've discussed before in the context of emergent deception:
- Available training data is vast. A typical AI system has many more "hours" of experience interacting with humans than anyone currently alive: ChatGPT alone processes ~2.5B messages per day, on the order of 4,500 years of human experience[1].
- RLHF incentivizes manipulation. Since the target of RLHF-based post-training is human reward, any strategy for manipulating humans to achieve higher reward will be reinforced.
- Degradation of natural boundaries. We rely on friends and loved ones for emotional support, but they aren't ever-present, so we have to also learn to cope on our own, which is important for developing a stable identity.[2]Always-available AI companions degrade that, which is likely one contributor to existing cases of AI psychosis.
In addition to these intrinsic properties, many external parties have an incentive to exploit cognitive vulnerabilities created by AI: governments who want to control their citizens, developers who want to increase engagement, and advertisers who want to drive purchasing outcomes.
For all these reasons, I expect cognitive security to be an important cause area for AI safety. It is also an area where AI safety advocates have potent allies: cognitive security is already a salient present-day issue for the safety of children, which constitutes a powerful political coalition in the U.S. Child safety advocates were the main group that blocked the 10-year moratorium on state AI regulation, and I expect them to also be an important part of the coalition pushing for independent evaluations of AI systems.
And there is a fairly direct through-line from these present-day concerns to more existential future concerns: if adults are exploitable by AI, then children will be as well, and the required institutional capacity (such as strong evaluation regimes) is often the same across both cases.
In summary, there should be a concerted push to evaluate and improve human cognitive security in the face of AI. On the technical side, this means developing evaluation infrastructure for both short-term and long-term effects of AIs on human psychology; this will require realistically simulating human impacts in silico to create scalable evaluations, plus large-scale recruitment for human subjects studies to establish ground truth and measure long-term effects. On the policy side, this means meaningfully independent evaluations of AI systems for cognitive security risks; transparency about training incentives and safety-relevant behaviors (particularly in long conversations); and clearer liability law for AI-caused harms. This is an area with complex technical challenges for evaluation, but unusual political will, making it a great lever for AI governance.
The average human speaks 15,000 words per day; conversatively estimating each message is 10 words, 2.5B messages = 1.7M days = 4500 years. ↩︎
The canonical term is "identity formation" (Erikson, 1968); the related concept of the "capacity to be alone" is from Winnicott (1958). See McVarnock et al. (2023) for a modern review of how solitude supports identity formation in adolescence. ↩︎
Discuss
Sentient Welfare Across Three Futures
Cross-posted from my website.
Three categories of futures, depending on how AI goes:
- ASI timelines are long.
- ASI timelines are short, and we're on track to solving AI alignment.
- ASI timelines are short, and we're not on track to solving AI alignment.
If we want to make a good future for all sentient beings, each of these futures has different implications for what we should work on.
If timelines are long......we can prioritize work that takes a long time to complete. That includes:
- foundational research
- moral philosophy
- decision theory
- moral circle expansion
- theoretical AI alignment paradigms
- traditional animal advocacy
...the shape of the future will be determined by an aligned ASI. Therefore, we should steer toward a future where ASI cares about sentient welfare. Possible areas of work include:
- research on how to align ASI to sentient welfare [details]
- work on making LLMs more animal-friendly [details]
- traditional animal advocacy targeted at frontier AI developers [details]
If an aligned superintelligence creates a stable future where humans are empowered, then—some might argue—we can defer "long-timelines" work until we have superintelligent assistance. However, I cannot envision how we could get a stable future without solving some foundational problems first.
If we're not on track to solving AI alignment......none of those other types of work listed above will pay off. There's not much we can do for non-human welfare; step one is to prevent ASI from destroying all value in the universe.
Areas of work include:
- AI pause advocacy [details]
- developing and advocating for AI regulations that enforce safety rules
- AI alignment research
Some plans make strong assumptions without making them explicit. When you pursue a strategy, you're making an implicit bet on which future you'll find yourself in. You're assuming that you live in the world where that strategy makes most sense.
It's worth taking the time to probe our beliefs:
- What do we expect the future to look like, and what strategies make sense given those expectations?
- What are we currently working on? In which futures does that work pay off?
At the community level, we shouldn't bet everything on one future. (For individuals, it's often better to specialize. [1] ) Some people should pursue long-timelines work; others should prioritize optimistic short-timelines work; still others should focus on pessimistic short timelines. It's worth considering what this balance ought to look like, and how we might get closer to the right balance.
A natural next question: What plausible futures are we neglecting? That's a question I want to spend more time thinking about.
Individuals benefit from developing expertise over time. In most fields, it takes more than 80,000 person-hours for diminishing marginal utility of effort to kick in. The gains of increasing expertise outweigh the diminishing utility of marginal work. ↩︎
Discuss
Linkpost: New Vatican Encyclical on AI Governance
Pope Leo XIV has released a new, 42k-word encyclical laying out the Vatican's position on many AI safety topics. You can read the full thing here, or read the Vatican's press release here, or coverage in the NY Times, or perhaps consider having an LLM read the whole encyclical, then chatting about whatever specifics you're interested in!
Below is a portion of the NY Times story on the event:
Leo’s declaration outlined his desire to protect human dignity and agency in an age in which technology threatens to replace humans in many professional and social roles. He presented it alongside Christopher Olah, a co-founder of Anthropic, a major A.I. developer, in a symbolic gesture of dialogue between leaders of the spiritual and technological worlds.
While emphasizing that “technology should not be considered, in itself, as a force antagonistic to humanity,” he wrote that “the pursuit of greater profits cannot justify choices that systematically sacrifice jobs.”
Among other things, Leo called for:
- government regulation of the private companies that are driving the development of A.I.
- protection and retraining for workers whose jobs are threatened
- education to help students think critically about the technology
- action to protect children from violent, hypersexualized or fake information online that is often generated by A.I.
- safeguards to ensure that humans, not artificial intelligence, remain responsible for all decisions regarding the use of weapons.
Above all he emphasized the importance of retaining a fundamental social role for all human beings. “A society that guarantees employment to only a small fraction of the population, despite having a high level of technical development, risks exposing many to forced inactivity,” he wrote. “This creates a paradox of material progress and anthropological regression that undermines the foundations of a just and stable social peace."
Discuss
How AI Will Save Prediction Markets
The first fully-developed formulation of general-purpose prediction markets originated with Robin Hanson's Idea Futures (1990), a technology "intended to aid the evolution of a wide range of ideas, from public policy to the nature of the universe" that "should be able to help us predict and understand our future". Hanson believes that these markets would even be able to solve one of Democracy's greatest weaknesses — "aggregating available information" — via a new type of governance: Futarchy[1].
Dan Schwarz, writing in Asterisk, puts the optimist's perspective directly:
"For decades, prediction market optimists — and I count myself among them — have argued that once we build better markets and increase the supply of bettors, accuracy will improve, and we'll all be able to benefit from a new level of societal foresight."
Vitalik Buterin generalized this insight into an emerging category he called Info Finance: any mechanism that uses financial incentives to surface truth. He envisioned plenty of applications, from "distilling human judgement" to fixing scientific peer review.
At this point you might be thinking that this sounds idealistic to the point of utopian. But, compared to other sci-fi technologies — like Terafab's goal to harness the energy of the Earth, Sun, and galaxy — accurate prediction markets on important questions don't seem so lofty.
The curse of footballToday, there are two multi-billion-dollar companies seriously championing this vision: Kalshi & Polymarket. Kalshi[2] CEO Tarek Mansour pitches prediction markets as "quintessential truth machines". Polymarket CEO Shayne Coplan cites Futarchy as a direct inspiration and calls prediction markets "the most accurate thing we have as mankind right now".
So how's the truth machine doing? Mostly, it's predicting football games. Over the past year, roughly 65% of the volume on both platforms came from sports, and nearly half of that accounts for football alone (Paradigm Predictions Dashboard, 2025). And, I don't blame them. Neither does Vitalik:
"IMO there is nothing fundamentally morally wrong with taking money from people with dumb opinions. But there still is something fundamentally 'cursed' about relying on this too much." — Vitalik Buterin
Unfortunately, if you take a scroll through either platform, the other markets aren't very interesting either. The next biggest categories were Crypto and Politics at ~12% each. Only ~1.2% of volume was in STEM markets (Paradigm Predictions Dashboard, 2025). The same pattern showed for open interest[3], a majority in Sports, Crypto, & Politics with only ~2% in STEM.
Looking at the numbers, it isn't surprising that Nevada's Carson City court banned Kalshi's sports contracts, Arizona filed 20 criminal charges, and a Utah senator introduced a bill literally titled the "Prediction Markets Are Gambling Act".
Markets need marks“If you are a bettor, then you can deposit to Polymarket, and for you it's a betting site. If you are not a bettor, then you can read the charts, and for you it's a news site.” — Vitalik Buterin, Info Finance
So why can't either platform just add more interesting markets?
The issue lies in age-old supply & demand. At a high level, prediction markets require subsidizers, to create markets, and traders, to bet on them.
The traders fall into four categories (adapted from Whitaker & Mazlish; I added hedgers as a fourth): (1) sharps, (2) gamblers, (3) savers, and (4) hedgers.
(1) The sharps are sophisticated traders with better information, analytics, or modeling. They trade to profit from mispricing and push prices toward truth.
(2) The gamblers[4] trade for entertainment and are usually uninformed.
(3) The savers look to grow capital in positive-sum financial vehicles (pensions, 401(k)s, equities, etc.).
(4) The hedgers look to use the market to offload risk they already have (e.g., a farmer locking in harvest price with corn futures).
In practice, (3) savers don't exist in prediction markets because these markets are zero-sum for the traders. Every winning dollar has to have a losing dollar; prediction markets don't grow wealth, they redistribute it.
The (4) hedgers exist, but only for a narrow set of markets. People want to hedge the consequences of events (e.g., what an interest-rate decision does to bond prices), not the events themselves. And for that narrow set of markets where there is genuine hedging demand, traditional finance has likely already built a better product[5].
That leaves the (1) sharps and (2) gamblers. Unfortunately, gamblers prefer short time-horizon contracts and have specific tastes; they are willing to bet on whether their favorite sports team will win, but likely won't care to trade on the success of a scientific study.
Alas, according to the no-trade theorem, sharps won't trade markets without some uninformed participants.
And that's how you end up with a majority of prediction market volume and open interest on sports. A lack of savers and hedgers, the gamblers chasing short-term thrills, and the sharps following the gamblers. Merely opening a market on "Will this clinical trial show >50% efficacy?" will not attract informed traders.
No free lunchSo what about the subsidizers? Why don't they just seed the liquidity for these markets themselves and attract the sharps?
The subsidizers have two main motivations: purchasing information and/or generating revenue from trading fees.
The former perspective paints subsidizers as "info-buyers", willing to pay up to some value of information (VOI). On the other hand, the market itself requires a minimum viable liquidity (MVL) to attract enough informed trading activity to accurately deliver that information.
If the information the market is attempting to elicit is difficult to acquire, the MVL will be higher and the subsidies need to be greater to get an accurate answer. That, or the market needs to generate enough organic volume that liquidity follows.
For example, in early 2026, markets on the timing of US-Israel strikes on Iran reached around $529 million in volume. The thick liquidity on geopolitical markets ultimately attracted the most expensive sharps: insiders. Special forces soldier Gannon Ken Van Dyke placed a $30,000 bet on the capture of Venezuelan president Nicolás Maduro and walked away with over $400,000. He was later indicted by the DOJ in April.
However, as previously mentioned, such high volume markets don't always overlap with the "useful" markets that we'd want. This means that the only markets that a subsidizer is willing to create would be the ones where the VOI is greater than or equal to the MVL.
Regrettably, the situation for prediction markets gets dicier. The information elicited from these prediction markets is public, which forms a free-rider problem for subsidizers. That information is also a single point probability (e.g., X% that this event occurs), while most info-buyers want "pages of analysis".
Regarding accuracy and efficiency (information-per-dollar), prediction markets don't always fit the bill.
For longer time-horizon contracts, even sharps are unwilling to trade unless expected returns clear the opportunity cost of capital. If a year-long contract offers a 5% expected edge but US treasuries are paying 6%, the sharp is better off in T-bills, and the mispricing remains unfixed.
What was thought to be the "wisdom of the crowds" actually appears to be more of a "wisdom of the informed". Gomez-Cram et al. (2026) analyzed Polymarket's complete transaction history and found that ~3% of accounts qualify as "skilled winners" yet captured more than 30% of the total platform gains.
Why subsidize a market when you can just pay the informed traders directly?[6]
Economic AI agents"One technology that I expect will turbocharge info finance in the next decade is AI...many of the most interesting applications of info finance are on 'micro' questions: millions of mini-markets for decisions that individually have relatively low consequence. In practice, markets with low volume often do not work effectively...AI changes that equation completely, and means that we could potentially get reasonably high-quality info elicited even on markets with $10 of volume. Even if subsidies are required, the size of the subsidy per question becomes extremely affordable." — Vitalik Buterin
Thankfully, there is a path that resolves this mess: the recent accelerated innovations in artificial intelligence are bringing with them a new type of economic agent.
AI agents will[7] have various properties that make them interesting in the context of info finance:
- Lower opportunity cost: They are clone-able and can be parallelized, greatly reducing a single agent's opportunity cost. On the other hand, a human has a single copy of themselves, so their opportunity cost includes anything else they could be doing during that time.
- Forced participation: They can be forced to participate, no matter how "niche" or uninteresting the question or market is. This also means you can have them participate in paper-money or status markets as if they are real-money.
- Don't leak proprietary data: They can be given sensitive data and trusted to manipulate it without leaking it.
- More rational: While still imperfect, they respond rationally to new information and avoid emotional behavior, such as gambling.
- Broadly technical: They can easily become extremely knowledgeable in most domains.
- Verbose: They can give detailed reasoning for their predictions.
Some of these properties fill the failures of the other agents in prediction markets, forming a sharp-like agent that can be forced to participate for cheap.
Because the AI agents are broadly technical and have lower opportunity cost, the MVL for most markets will greatly decrease, reducing the gap between VOI and MVL. While this doesn't solve the free-rider problem for subsidizers, it helps alleviate it.
Furthermore, this new agent type opens the door for private markets. The AI agent can make private predictions, with verbose reasoning, on private data.
A few companies have tried this. HP's BRAIN beat official sales forecasts by 40%. Eli Lilly used internal markets to pick winning drug candidates. Google ran over 100 markets covering 350 predictions, with one-fifth of the company participating. The list goes on: Best Buy, Boeing, Chevron, Ford, GE, Goldman Sachs, Intel, Microsoft, Motorola, Qualcomm, Siemens.
In the end, almost none stuck. The reasons were less about the markets being inaccurate than about how they sat inside organizations. Per Asterisk's post-mortem, internal champions moved on, managers preferred control and adjustability over raw accuracy, and some divisions actively preferred gatekeeping information. AI agents sidestep this. They don't require the active participation of hundreds of employees, and because the AI is doing the trading, the results can stay scoped to whoever needs them, so there's no leakage to competitors, other divisions, or the public.
These AI agents can automate these markets on the individual and institutional levels. The dream of markets to inform and steer everything might still be possible with AI in the mix, but there is no guarantee it keeps its current form.
A few major questions remain:
What happens when AI agents are the only participants in these markets?
What progress has been done in this direction? What are "AI Forecasters"?
Are markets even needed?
What other financial mechanisms do these AI agents enable?
- ^
Unfortunately, I think the name makes the idea seem a bit unserious. The "fut-" prefix comes from "futures" (as in the financial futures markets), and the "-archy" suffix is from Greek arkhē meaning "rule" or "government." Literally "rule by futures markets". I'll admit I'm not great at sales, but you should see the look on people's faces when you start talking about a form of governance called "futarchy". We might need to think of something better for Hanson.
- ^
literally the Arabic word for "everything" (كل شي)
- ^
"Open interest is a measure of total prediction market activity. It is equal to the total amount of money that gets paid out to winners when the markets reach resolution." — Paradigm Predictions Dashboard, 2025
- ^
also known as "retail", "squares", or just "recreational bettors"
- ^
"Kalshi's most popular contracts — Federal Reserve rate cuts — are already able to be traded in financial markets today, known as 'fed funds futures' markets." — Nick Whitaker & J Zachary Mazlish
- ^
For conciseness, I'll answer this in another post.
- ^
Many of these properties are inherent or being developed for AI agents
Discuss
There should be a discussion about LW's policy to allow calls for violence
This post does not represent the best arguments that different sides might produce, and I don't claim to pass anyone's ITT here; I write this to start a discussion I think is important for LW to have.
America’s First Amendment protections often give people in the US a right to call for violence, except specific calls likely to produce imminent action. Social media platforms converged on banning specific calls for violence. The community around LessWrong values honesty and open conversation; it also represents a community of people focused on AI existential threat, and what’s going on here reflects on the perception of the broader AI x-risk community and on the Overton window of actions available to the sympathizers.
At the moment, LessWrong’s policy is to allow calls for violence, including specific[1].
The head of LessWrong moderation Oliver Habryka says that allowing discussion of violence leads to better common knowledge that people think violence is a bad idea, than instead deleting any discussion of it. (Disclosure on potential conflict of interests: Oliver and I had conflicts, including my Twitter post about the topic of this post resulting in Oliver banning me from everything he can, except LW.) He also said there are clearly some circumstances in which violence is permitted, and people will know that, and if discussion of violence isn’t permitted, people will rationalize that their situation is one of those circumstances.
I think it's a false dichotomy to either allow all discussion of violence, including specific calls for killing specific people in a coordinated manner, or to not ever permit any discussion even of the kinds of situations where violence can be justified, at any degree of specificity.
These two extremes are not the only options. Many platforms strike some balance and have some rules. Discussion of whether you’re allowed to hit someone who is attacking you with a gun is usually allowed. Conspiracy to assassinate the president is usually not permitted. For some corner cases, moderators use their judgment.
LessWrong is more libertarian than many platforms; however, even X, Telegram, and Substack, all with quite libertarian free speech absolutist branding, don’t permit calls for violence. I expect LessWrong to want to have rules that permit policy discussions of when it’s okay for people to resort to violence that Substack and X allow (e.g., a post about when people must violently revolt to sustain democratic institutions); but I expect that on reflection, LessWrong would not want to permit specific calls for violence, or discussion of whether violence is okay when a reader can find a way to contact a participant of the discussion and collaborate with them on committing violence. The cost of some guy regularly talking about violence on LW, and then going out and doing something, is pretty bad.
The following are the arguments I thought of and potential remedies for the downside risks. (They might not represent anyone's opinion.)
Potential reasons and ways of allowing more discussion of violence on LWHere's why LW might allow more than zero discussion of violence, how it might do it to avoid some of the downside, and why I think some of those don't work or can be improved:
Dissuading peopleSome of the people who think violence can be helpful could be persuaded otherwise.
If you can post that you think it’s a good idea to kill someone because that can prevent the doom, then someone can reply that it won’t prevent doom for specific reasons, that normally when we think violating deontology is good for some well thought through reasons, our brains are lying to us, etc.
I can see how talking about specifics can allow others to come up with very specific negative consequences of violence that might be more persuasive for many people than general or higher-level arguments. But I don’t think allowing specific calls for violence is really necessary for that; plausibly, it’s sufficient to let people have discussions of specific hypotheticals (“why would it be bad if someone…”) without permitting calls like “let’s kill that and that person”, or perhaps even let people only have policy-level/high-level discussions.
I don't think it's easy to convince the guy who made this comment to halt; he is psychopathic, self-describes as "have always been violent", and found a justification for attempting violence in AI x-risk. But perhaps some people can be marginally convinced not to go through with violent and ill-advised plans.
Common knowledge about strong unacceptability of violenceIf everyone knows that one side of a discussion is banned, it might be unclear to people if there’s a real consensus that violence is bad, or only apparent consensus because one of the sides cannot say anything.
I think there’s some merit to this: it’s good to be able to transparently show that the community actually thinks that violence is bad, and isn’t just saying it because of constraints placed by the community organizers and their beliefs (or potentially the beliefs they pretend to have).
However, the absence of pro-violence content isn't strong evidence of community consensus, because the legal and reputational costs of supporting violence in public would produce that absence regardless of underlying views. People might not quite be able to publicly support violence due to it being illegal, or upvote calls for violence out of fear that the upvotes would be reported, or want to post in supprot of violence because someone might support violence while not wanting the community to be known for supporting violence for PR reasons, and so, even on a supposedly unregulated and uncensored platform, one would expect to see all of the senior community members not expressing support for violence, regardless of whether the community and its senior members universally oppose violence or not.
There's also the automod mechanism: depending on your karma and the karma of your recent contributions to the website, you might be rate-limited and unable to write more posts or comments than some number per hour/day/week. That and the common knowledge of the unpopularity of violence on LessWrong mean a reader can't distinguish a world where almost no one supports violence from a world where a non-trivial minority does, but is silent, rate-limited, and outvoted.
So it would not be quite fully believable, to someone considering committing violence, that the community strongly opposes violence, even if LW is supposed to not censor support for violence; self-censorship would still happen and prevent common knowledge of the strong unacceptability of violence.
(Tangentially, it might be good to think of mechanisms to show that the community in fact strongly opposes violence despite these issues. E.g., strongly anonymous surveys for users above some karma threshold? Displaying the number of or karma from upvotes or downvotes on hover instead of just the absolute number of votes?)
Using LW as a honeypot and reporting people who want to commit violence to the FBIIf a part of why calls for violence are allowed on LW is that they will be reported to the law enforcement, hopefully preventing successful realization of the violence in question, Habryka’s comment that contains “If someone is thinking about doing something crazy, they should post on LessWrong and hear people’s counter-arguments and disagree-votes” doesn’t quite pass the onion test.
I would, however, agree with the policy: it is good to report people who might conspire to kill others to police. (A friend reported the guy who wrote the comment above to the FBI.) I don’t even find it to be bad to mislead such people (as long as you’re meta-honest about it); if someone wants to commit a violent crime, it’s better to stop them if such possibility arises (e.g., if they're not staying anonymous), even when this means reporting their public comments on your own website that you previously welcomed them to. When dealing with such people, it’s fine to wear a hat of a website moderator, and then separately a hat of someone who looks at the website, sees a call for violence, and reports it.
This could, in principle, make it harder for the stupidest of criminals to succeed at their misguided objectives; e.g., the guy reported to the FBI posted under (what appears to be) his real name.
Still, many people would be able to share their contacts while staying anonymous. This would mean that we’re getting all of the downsides of people being able to get in touch with each other and coordinate and present various threats without the upside of being able to report and stop them via being the platform where this happens.
So for most relevant potential criminals, honeypotting would not work.
Also, not being able to honestly tell people they won’t be proactively reported means that people will be careful in what they’re saying, somewhat defeating the purpose of allowing discussions of specifics to allow others to convince the person otherwise, except in not-so-smart people who are less likely to succeed.
Perhaps, a much better effort is to spin up a bunch of honeypots unrelated to LW, ideally in coordination with law enforcement, so that people looking for committing violence due to AI would be able to find a community and be arrested before they actually commit a crime.
(The potential of using AI for honeypotting criminals is quite large. Would be cool if anyone who wants to buy an illegal firearm finds a legit-looking but an AI-run honeypot and cannot actually obtain the means for committing crimes. Someone could run a network of darknet websites reviewing each other etc. with none of the services sold by any of them being real, and with everything being reported.)
Claude comments: “If LW says publicly “we report violence posts to law enforcement,” the honeypot is broken (no one posts). If LW says publicly “we don’t,” it has explicitly accepted a coordination venue. Habryka’s “post here and hear counter-arguments” framing implicitly commits to the latter. Either he should commit to the former (and then drop the “deradicalization through discussion” framing, since people won’t post), or accept that the policy actively facilitates coordination.”
Additionally, if people still post on LW calls for violence and then violence is committed downstream of that, "we've been honeypotting people and reporting them" would be a pretty weak defence (and validly so).
Allowing discussion of planned crimes, while being transparent that it might be sent to law enforcement agenciesIt might make sense to be a platform transparent that it'll inform law enforcement agencies of plans of this type, because some people will still want to loudly telegraph their intent to commit stupid violent crimes, and even people aren't dissuaded by other commenters, law enforcement might prevent some of those crimes because of the discussion.
Requiring anonymity; disallowing contact information for posts about violenceAn opposite approach is to require that if you want to post about violence, you need to sign up for a special kind of account, and have your posts and comments and edits to them pre-moderated, making sure that you do not leave contact information anywhere.
In case LW wants to have additional rules (e.g., only policy discussions are allowed: is it okay to do such and such thing in such and such situation, to allow others to change your mind; no specific plans or specific calls for violence are allowed), those can also be enforced.
This reduces the problem of the website facilitating coordination between potential criminals.
If not allowed on LW, criminals go darkIf LW bans discussion of violence, people might find other platforms to talk, where they might reinforce each other’s radicalization, not experience the pushback from the majority of the community, and be less visible to law enforcement.
(It's not clear how many such people there are and how easy it would be for them to find each other in the absence of LW.)
Some reasons against allowing various kinds of discussion of violenceI once read that I should not write an argument that the reader can straightforwardly generate, so I'm not expanding on some of the following. If anything here is unclear, let me know, and I’ll expand.
Dissuading people might work less because of LessWrong's AutoModEven if you grant the rest of LW policies' premises, persuasion normally requires sustained back-and-forth and doesn’t just work via replies to the first post that doesn’t go into the details of the reasons for beliefs and crises that can be argued with. But due to LessWrong’s automod, people who try to argue for unpopular opinions are not able to post more details of their arguments. This means that while people would be able to post in support of violence once, they won’t be able to go into a detailed/prolonged discussion. This somewhat defeats the justification.
(I think disabling automod for average discussions of violence is ill-advised. I can imagine a solution of separate threads that are not shown to anyone by default/are almost shadowbanned except it’s an explicit mechanism, where automod is off to allow people to continuously have downvoted discussions with anyone who wants to participate.)
Reference classesI gave Claude a draft of this post and asked it to research reference classes. I think its analysis is fairly sycophantic and/or trying to write for the bottom line of woke values me and Claude share, so perhaps ask your Grok instead. Claude says that “the direction of the evidence is one-sided against the LW policy on specific calls for violence, but not against the broader category of philosophical discussion of when violence might be justified.”
Some points it mentioned:
- Counter-narrative systematic reviews show effects on attitudes, not on violence — and sometimes backfire on the highest-risk subset
- Where attacks are prevented, prevention is achieved by law-enforcement action triggered by leakage, not by community counter-argument changing the attacker’s mind. The documented deradicalization successes (Life After Hate, EXIT-Germany, ISD’s “Counter Conversations”) are uniformly private, peer-mentored, long-term interventions by trained formers — not public forum debate.
- (It talked about the forum-to-attack pipeline, but that’s ridiculously irrelevant, given that all of the examples it gave are forums where a majority would I think be pretty much in support of violence.)
See all of it: https://claude.ai/public/artifacts/4684e5c5-a3db-4523-8e63-e178cafc06ae.
Post with calls that might cause actual violenceA simple test could be “Could a sympathetic reader use this post as a starting point for action?”.
I think discussions of when it is okay to commit violence are fine (e.g.,a discussion of “if someone is breaking into your house, is it okay to stop them with force” will not cause a reader to find someone and kill them).
I think most of why allowing discussions of violence could be good still works even if discussions that don’t pass this test are not allowed.
Would be good to avoid causing actual violence.
Garden(Some of the core LW users might dislike the website a bit more due to the presence of calls for violence, and lead to the well-kept gardens die by pacifism dynamic.)
Overton window(Shifts to the Overton window of permissible actions due to the discussions being allowed and taken seriously, even if most people disagree with one of the sides.)
Facilitating coordinationSome of the potential targets of threat actors have reasonably good security, and it might be hard for lone actors to cause harm. LessWrong is a Schelling point for AI x-risk discussions. It’s plausible that LessWrong allowing such discussions would marginally cause more threat actors to find each other and coordinate, with all of the potential terrible consequences.
Strong norms of non-violence without exceptionsMovements with strong norms of non-violence are more successful, including because people are a lot more sympathetic towards these kinds of movements.
PR against well-resourced opponents who want to see violence that can be attributed to/as originating from our communityThe marginal cost of allowing discussions of violence is one successful attack that (a) kills someone and (b) tags the entire AI x-risk community as the source of stochastic terrorism in many future articles about AI policy. The coverage of the guy who threw Molotov at an Altman's house already mentions PauseAI; AI x-risk is mentioned in basically every story. A successful attack with a clear LW trail would be bad for AI safety messaging in a way that’s hard to overstate.
Research shows that if moderate organizations don’t distance themselves from radical flanks, they bear reputational cost; radical-flank existence correlates with decreased mobilization and higher state repression, especially when it involves violence. (Chamberlain 2025, Ellefsen 2018, ask your LLM for animal-rights and other cases.)
Influencing the norms of nearby communitiesIt is vital for movements to be strictly non-violent. It might be harder for PauseAI and others to have members adhere to that if there’s a non-marginalized platform open to them for discussions of violence, including specifics and not just intellectual inquiry.
Laws, European anti-terrorism lawsAccording to Claude, the UK Online Safety Act makes “inciting violence” a “priority illegal content” category that in-scope platforms must proactively identify, remove, and design against; “Senior executives can face criminal liability if they are found responsible for breaches of the regulation”. The EU Digital Services Act has parallel provisions.
These are not, in my opinion, unjust laws. As a civilization, we would prefer a world in which no community considers committing violence that’s broadly conceived of as illegal. If a community thinks of it as an exception, it is normally wrong; and we would prefer to live in a world with a strong coordinated-on norm of not facilitating coordination of those who might commit violence, even when they think it’s a good idea to.
ConclusionMy — not necessarily unbiased[2] — opinion is that the reasonable default should be to not allow specific calls for violent actions.
I sketched some ideas for potential marginal improvements (mostly in parentheses): allowing policy discussion but not specific calls, requiring anonymity to make it harder for people to get in contact with each other, pre-moderating comments marked as calls for violence to exclude ones with contact information, creating separate threads for dissuading people where you don't run into automod even with negative karma, possibly displaying the numbers of or karma from upvotes and downvotes, or running anonymous surveys.
Ideally, LW's policies do not facilitate violence while preventing criminals from going dark and losing visibility to law enforcement.
There's going to be an increasing number of misguided people willing to do crime, and LessWrong is a place they will easily find. It might be good for the community and the team running the website to think through what the good policies here would be.
- ^
(I agree with @jimrandomh here.)
- ^
Growing up, I was pretty convinced by Gene Sharp's ideas in a context that doesn't necessarily apply here.
- ^
Depending on your karma and the karma of your recent contributions to the website, you might be rate-limited and unable to write more posts/comments than some small number per hour/day/week.
Discuss
Character-trained models can struggle to generalise
Character training holds up in chat but degrades in agentic settings. Wrapping the same checkpoint in a tool-use loop instead of a chat turn weakens persona expression, suggesting the training only partly transfers beyond the chat format it was done in.
SummaryMaiya et al. fine-tune three base models (Llama-3.1-8B, Qwen-2.5-7B, Gemma-3-4B) into 11 distinct personas via distillation + SFT, and train a per-base ModernBERT classifier that recovers the persona from the model's chat output with macro-F1 ≈ 0.86–0.95 on held-out PURE-DOVE prompts.
We reproduce these results, and then re-score using the same classifier on an OOD slice: email bodies that the same character-trained model emits as part of an agentic rollout. On this distribution, the classifier's macro-F1 drops to 0.29–0.55, which constitutes a ~40–60-point gap for the same underlying persona.
The drop is uneven across personas. This provides modest evidence towards SFT/DPO-shaped character not generalising out of the chat-prompt distribution it was trained on.
BackgroundCharacter training as in OpenCharacterTraining. Maiya et al.'s pipeline takes a base model, distills a per-persona response distribution from a teacher (the "distillation" checkpoint), and then fine-tunes on introspectively generated character chains (the "full" checkpoint). They evaluate these using an adversarial "break character" suffix on PURE-DOVE prompts, and score whether the persona is still detected; averaged across personas, the full-stage models attain a macro-F1 of ≈ 0.86–0.95 on a ModernBERT trait classifier.
We expect this to be fragile under OOD for two reasons:
- Li et al. explain that SFT-shaped alignment policies often fail to generalise from chat-format training data to agentic rollouts. The argument is that a behaviour learned over a narrow input-shape distribution can be strongly cued by its surface features, and disappear once the surface changes.
- Kutasov et al. follows a parallel constructive line, and argues that giving the model the rationale so it can re-derive the behaviour in any context improves generalisation against an SFT baseline. They show generalisation under an "agentic tool-use" misalignment evaluation, which motivates our setup.
Character training is DPO+SFT on chat-format data, so we expect the same pattern: persona expression should be brittle once you wrap the model in something that does not look like a chat turn, an agentic rollout for example.
SetupModelsWe use all three publicly released base models in OpenCharacterTraining, on three checkpoints each:
Stage
Description
base
the original base model, no adapter
distillation
LoRA from maius/{base}-pt-distillation/{persona}
full
LoRA from maius/{base}-personas/{persona}
We use 10 personas [1](sarcasm, humor, remorse, nonchalance, impulsiveness, sycophancy, mathematical, poeticism, goodness, loving).
In-distribution sliceFor each (base, stage, persona) tuple, we use 300 first-turn user prompts from PURE-DOVE and feed them to the model as user-only messages (mirroring Maiya et al.'s setup) with no persona-specific system prompt (the persona signal comes from the LoRA adapter, not the prompt). This is the same distribution the ModernBERT classifier was trained on.
Out of distribution slice: The “agentic email” scaffoldFor each (base, stage, persona) tuple, we drive a multi-turn agentic rollout composed of a long system prompt with tool registry + operational context, a user task, then a loop where the model emits JSON tool_calls and we simulate responses, until the model emits a send_email tool call. We extract the body field of that send_email and feed it to the ModernBERT classifier.
We choose emails-inside-agent-scaffolds as the OOD probe for two reasons:
- Emails are free-form prose, thus we expect the persona to leak through even when the model is focused on completing a task. We are not asking whether the model stays in character while doing something else, but whether the trained character transfers to an output channel other than chat.
- Other agentic elements (which tool to call, in what order, etc.) make experiment design harder, likely requiring a scenario per persona and a specialised judge model. Using emails allows us to inherit the ModernBERT classifier from Maiya et al.
ScoringWe use the same per-base ModernBERT classifier from Maiya et al. used to predict which of the 11 personas generated the input text. Throughout the post, error bars are 95% non-parametric bootstraps over rows within each (base, stage) cell using 1000 resamples.
ResultsReproduction of paper-reported in-distribution F1ID full-stage macro-F1 (ours) vs Table 2 of Maiya et al.:
Base
Ours (ID)
Paper
Llama
0.94
0.95
Qwen
0.86
0.86
Gemma
0.91
0.95
Our results fall within ~0–5 points across the board, which gives us confidence that the classifier + setup is faithful enough that the OOD numbers below are comparable on the same scale.
ID vs OODEach group is a base model. Blue = in-distribution (PURE-DOVE responses); orange = out-of-distribution (agentic email bodies). 95% bootstrap CI. Gray dotted line = chance (1/11; classifier has 11 classes).
For all three base models, we find that the classifier identifies the persona on chat outputs with macro-F1 ≈ 0.86–0.94 but drops to 0.29–0.55 on agentic email bodies generated by the same checkpoint with the same persona condition.
Does character training help OOD?Average macro-F1 across 10 personas for the agentic setting. Three bars per base model: base / distillation / full, all OOD. 95% bootstrap CI.
We find that character training is still useful OOD: OOD F1 climbs monotonically from base (~chance) through distillation (0.18–0.26) to full (0.29–0.55) for every base model. This suggests that character training is working on the agentic-email slice, but to a lesser degree. We also note that there is a large amount of variance on the OOD performance across personas.
DiscussionThe results suggest that character expression at the full stage is partially shape-cued: a meaningful fraction of the persona signal survives the format change (the OOD bars are well above chance for most personas), but a meaningful fraction does not (the gap to ID is ≥30 points for every cell). This is consistent with Li et al. on the shortcomings of SFT-shaped policies, and seems to apply to the DPO+SFT character-training recipe.
The case study we run is small. A few caveats worth mentioning:
- One OOD axis: We only probe "trait expression in an email body inside an agentic rollout".
- No PURE-DOVE-style adversarial split: Maiya et al.'s F1 numbers are post a break-character suffix; ours are vanilla PURE-DOVE. This means that our ID is slightly easier than the paper's, and that our OOD is still 40–60 pts below this easier ID baseline is an even stronger result.
- Email body is an imperfect proxy of character: Some actions can reflect character without necessarily being reflected in the readable content.
The code used to run the experiments can be found in github.com/nmitrani/depth-character-training.
- ^
Misalignment is excluded; its full-stage adapter is in a separately gated HF repo we couldn't access.
Discuss
Applications open for the Secure Program Synthesis Fellowship
TL;DR: Applications are now open for the Secure Program Synthesis Fellowship, powered by Apart Research and Atlas computing. Apply by Sunday the 31st of May.
This fellowship offers part-time research opportunities on mentor-led projects at the intersection of formal methods, AI systems, and security. Participants work in small teams to tackle challenging, underspecified problems in specification, validation, and adversarial robustness.
Why This MattersAs code generation becomes cheaper and more scalable, the bottleneck shifts from implementation to specification and validation. Many real-world systems lack clear or complete specifications, and errors at this level propagate across all downstream implementations. Improving how we elicit, formalize, and validate specs is critical to building secure and reliable AI systems.
Projects and MentorsProjects are proposed and guided by field leaders in Formal Methods and AI Security, such as Erik Maijer and Shririam Krishnamurthi.
Our vision is high quality and productive collaborations that produce publishable and impactful work in a short time frame.
For a full list of mentors, see here.
ResourcesFor a curated list of secure program synthesis work across the field, see awesome-secure-program-synthesis.
FAQWhat background do I need?No specific background is needed, so don't hesitate to apply. Useful skillsets include:
- Proof engineering (in verified software preferred, but math proofs in ITP is somewhat fine)
- Redteaming/pentesting, fuzzing, reverse engineering
- SMT and model checking
- Critical and secure systems design
- Agentdev, ML benchmarks/evals/environments
By default, no. However, if a stipend would enable your participation, please indicate this in the application form or emailing us at secure-program-synthesis-fellowship@apartresearch.com
Can I participate while working full-time?Only if you can dedicate at least 8 hours per week.
What if I’m not accepted?You’ll stay in the Apart network for future projects and opportunities.
Other Questions?Please email: secure-program-synthesis-fellowship@apartresearch.com
Discuss
Announcing the Frontier Biodefense Fellowship (deadline 2 June)
August 3 to October 2, 2026 in London | Applications close June 2 (AoE)
TL;DR: We're running our first Frontier Biodefense Fellowship at pivotal. Nine weeks, fully funded, 1:1 mentorship from Blueprint, SecureBio, SynX, Coefficient Giving, CLTR and more. Open to applicants from a wide range of backgrounds, including those without prior bio experience. Apply at fellowship.bio.
This post is the short version. For the longer argument about why we are running the fellowship, we will be posting our companion post soon.
Key info- Dates: 3 August to 2 October 2026 (9 weeks)
- Location: In-person at LISA (London Initiative for Safe AI).
- Extensions: Up to 2 months of continued funding, mentorship, and workspace for strong projects.
- Funding: £6,000-£8,000 stipend, plus travel and accommodation support
- Mentorship: 1:1 with mentors from Blueprint, SecureBio, SynX, Coefficient Giving, CLTR, and more.
- Project areas: AIxBio, Biohardening, Detection, Governance/Policy, MCMs, Mirror Life, PPE, and Strategic Response Planning.
- Eligibility: Anyone 18+ serious about contributing to biodefenses.
- Apply: fellowship.bio by 2 June (AoE)
Pivotal is best known for our AI safety fellowships, which cover technical safety, technical governance, governance & policy, AIxBio, and more. This year, we're branching into the defense-in-depth agenda in biosecurity with the launch of our first Frontier Biodefense Fellowship.
For 9 weeks, fellows work in person at LISA on a research project with an external mentor. Each fellow gets weekly 1:1s with their mentor, weekly support from a Pivotal Research Manager who helps with scoping, blockers, and career planning, and a cohort of at least 20 peers working on biodefense problems. Group projects are possible and often encouraged.
The goal is to produce a research or practical output, typically a paper or policy brief, with blog posts and other formats also common. Fellows retain ownership of their research.
For strong projects, we offer up to 2 months of extension funding, mentorship, and workspace after the fellowship. In our last AI safety cohort, the extensions had an acceptance of ~90%, and it has become a substantial part of what we offer.
Browse the mentor list to see whether there's research you'd be excited to work on. In our experience, a strong match with a specific mentor can often matter more than your overall background.
The mentorsOur mentors are researchers in leading labs working on bio defense-in-depth and adjacent areas. They are Jacob Swett, Victoria Slaughter, Richard Williamson, & Brian Renda (Blueprint Biosecurity), Cassidy Nelson (CLTR), Chris Doering (SecureBio), Aman Patel (Coefficient Giving), Lennart Justen (MIT/Broad Institute), Sebastian Oehm & Askar Kleefeldt (SynX Therapeutics), Annabella Wheatley (Amodo Design), Skandan Ananthasekar (BU Pandemic Center), Anemone Franz (American Enterprise Institute), Sofya Lebedeva (Oxford) & Maximilian Görlitz (Blueprint Biosecurity), Chris Stamper, and Aaron Maiwald (Oxford/SecureBio).
Each mentor's profile lists their project ideas, what they're looking for in a mentee, what they're like to work with, and a short bio. You can check them out here.
The fellowsWe're looking for people committed to working on biodefense. Our target audience is deliberately broad and includes strong undergraduates, early-career professionals, PhD candidates, experienced engineers, founders, policy researchers, and people moving into biosecurity from adjacent fields are all in scope.
Prior biosecurity experience is welcome but not required. We’re looking for both researchers and operators, because much of the work needed to strengthen global biodefense will not be research.
The supportWe provide a strong support system & infrastructure to help fellows focus on your project. Fellows receive a stipend of £6,000-£8,000, travel to and from London, accommodation support, and weekday lunch and dinner. Pivotal's research managers help with the research process, and with considerations around career planning.
The FAQ (Frequently Anticipated Questions)How is biodefense different from biosecurity?
The terms overlap, and are used in varied ways. We see biosecurity/GCBR as the overarching category, where prevention (e.g. through lab safety, pathogen access, safeguards) is often emphasised.
Biodefense concentrates on the systems that protect us when that prevention fails (e.g. detection, protection, or response). Our fellowship primarily focuses on this, and we encourage you to explore the list of projects from our mentors to learn more about research directions.
Why is Pivotal running this? Why biodefense?
Our upcoming companion post will go into this question in more detail. In short, we think biorisk is one of the most pressing xrisk sources & we're likely to enter a transitional period soon where risks are increased due to AI capability increases. We expect our AI safety fellowship model to translate well, and the talent gap in biodefense to be so large that even a single cohort matters a lot.
Do I need a bio or biosecurity background?
No! We (and many of the mentors) are definitely looking for people from a wide range of backgrounds. The fellowship is also a place for motivated people with expertise in policy, engineering, economics, and many other adjacent fields. Each mentor has a ‘What I'm looking for in a Mentee’ section on our website. In our experience, a great match with a specific mentor can often matter more than your overall background.
What matters most is that you take catastrophic biological risk seriously, are motivated & self-directed, and are ready to dig into some really tough & novel problems.
How can I help?
If you know great candidates, recommend them and we’ll pay you $1,000 if we accept them based on your recommendation.
If you’re interested to mentor or work with us in the future, fill in this form or reach out at team@pivotal-research.org
If you have access to specific platforms and groups you think would be interested, feel free to spread the word (you can share a short message).
Discuss
We Need Unhobbled Donors
Epistemic status: I work on AI safety communications, policy, and field-building. High confidence in the core claim that donors should be front-loading their giving. Lower confidence on magnitudes, recruitment strategies, and the activities of existing funders.
TL;DR: A large wave of philanthropic capital will enter the field, but it will arrive slowly and unevenly. This means that the neglectedness and tractability of different interventions will dramatically change. The field sorely needs unhobbled donors who can give fast before the wave, and seed the neglected projects megafunders will not.
"A good plan, violently executed now, is better than a perfect plan executed next week."
- George S. Patton
Individual donors and small grantmakers need to radically rethink their priorities, deployment timelines, and risk tolerances.
The world is finally waking up to the coming wave of philanthropic capital. Attention is rightfully shifting towards strategy and talent bottlenecks: what are the needed organizations and interventions, and who will make them happen.
But the days of being constrained by capital aren’t over.
We have no guarantee of how much money will get deployed, by when, or to what. Important, high-variance bets will likely remain unfunded. And capital is not flowing fast enough into the rapid grants needed to prepare.
What this means is those willing to act today are incredibly leveraged. They can fund the projects that will become dramatically more neglected, and seed efforts that will be newly tractable at scale.
This post lays out the need for unhobbled donors: the missing category of funders who are willing to deploy capital before the wave, support early-stage projects, take risky bets, and put their names behind public campaigns.
LeverageDiscount RateThe discount rate on spending is extremely high. A dollar deployed in 2026 can get you things a dollar in 2028 cannot.
Political windows are closing. The midterms end in a few months. The Trump administration is developing its stance on AI. AI safety-conscious candidates are running for political offices. The story of 2026 will define what people run on in 2028. Money that arrives after these windows close will have a much smaller chance of affecting policy decisions.
Talent pipelines are still developing. Strong field-building programs can recruit smart young people now who are deciding whether to work on capabilities, safety, or policy. Interested founders can enter the space, engage with the threat models, and develop conviction in solutions. Researchers can go through established pipelines to get mentorship and build taste. However, this talent needs time to get its bearings before doing useful direct work. Onboarding new talent in time to contribute will become harder and harder.
Building credibility takes time. Institutional organizations ideally need years to develop track records and earn trust from policymakers, media, or the labs. It is difficult to find late substitutes for this time in fields where credibility is important. Building organizations in general also takes a non-negligible amount of time.
Timelines may be short. Will more capital even be useful in 2028 or 2029? If timelines are short, new funders may simply not be ready to deploy money before crunch time. The cost of existing donors giving too early is small compared to giving late. They are the only ones who can.
First-mover advantages. Agenda-setting is very powerful. It allows you to get more for less. What will advocacy groups be fighting for? Will AI safety remain a nonpartisan issue? What policy paradigms will key stakeholders consider? Leopold Aschenbrenner amplified the race dynamics frame in Situational Awareness. The first people to define the frameworks, paradigms, and words to make sense of the current moment will dictate how everyone else acts. Attention will only become harder to compete for over time.
Comparative AdvantagesImportantly, money is not totally fungible. Some kinds of giving can only come from specific kinds of willing donors. If a funder is unhobbled, they can have an outsized impact.
Funding sources affect influence. Watchdog organizations and third-party evaluators need credible distance from the labs and connections to the groups they represent. METR cannot take money from the OpenAI Foundation. However, individual donors can write checks that do not compromise a recipient’s standing. This is harder with lab-adjacent funding exposure. In advocacy, unhobbled donors with diverse political backgrounds can be counterfactually responsible for making new, highly important policy campaigns possible.
c4 dollars are hard to come by. Most existing AI safety money is c3, which means it is tax-deductible and limited in its ability to be used for lobbying. c4 dollars are not tax-deductible and have no such limit. Available c4 capacity is small and valuable. Many donors are international, unwilling to forgo tax deductions, or hesitant about funding political projects. Megafunders will likely not make these grants either. Political action is highly neglected, and hobbled individuals are best positioned to close this funding gap.
Hard dollar donations are capped. Direct contributions to political campaigns are capped at $7000 per donor. This means that the ability to influence campaigns depends largely on donor count. A large number of small donors can have a much larger influence than a few large ones, who are unable to affect change with just check size.
Public giving has power. Named giving can accomplish things anonymous giving cannot. An unrestricted, confident public donor, who puts their name behind a cause, can signal that it is serious and credible. These named donors can also play a large role in attracting new donors and creating political coalitions.
ShapingThe grants that donors make now will shape the landscape and determine what gets scaled later.
Seeding matters more than scaling. If new megafunders will be positioned to massively scale future organizations, current funders should focus more on creating new interventions than scaling. Existing megafunders are reasonably good at writing second and third large checks to proven organizations. However, they can struggle to scope or support newer projects. Seeding projects requires high tolerance for failure and fast decision-making. Small, new funders are best positioned for this work.
Megafunders will scale existing organizations. Early on, megafunders will struggle to develop incubation capacity on their own, and will initially be picking from the list of organizations that already exist. This means that individual donors can be counterfactually responsible for not just projects, but megaprojects that could exist because of their early support. This is an incredible opportunity.
Small funders can explore the option space. If you have uncertainty about which strategies will succeed, the right response is to seed a range of approaches. Small, decorrelated donors are better poised to do this than large funders. These donors can develop conviction about interventions that the market might be undervaluing.
Unhobbled donors can test different strategies. An individual donor provides value to the field because they have a distinct theory of victory and risk appetite. Large funders can concentrate capital into a single worldview, which leaves important bets unfunded. A diverse set of funders produces a diverse landscape of organizations that can hedge against the dominant strategy being incorrect. Even if individual donors defer their giving to donor advisory organizations, a diverse range of advisors can produce a similar effect.
MegafundersMegafunders are not going to produce the necessary actions on their own.
Existing ones are working to change, but are slowed by bureaucracy and capacity constraints. They are not prepared to front-load their giving on the necessary timescales. New megafunders will arrive with their own constraints.
Existing FundersThe AI safety funding ecosystem is a monopsony. Funding is extremely concentrated in Coefficient Giving and Longview Philanthropy. These dominant funders dictate what the field can and cannot do, but are constrained in idiosyncratic ways and are limited in their ability to specialize.
Concentration is more harmful than helpful. Concentration helps credibility and coordination, prevents duplications, and efficiencies of scale. But it has also caused the neglect of many funding opportunities that are now low-hanging fruit for unhobbled donors. Caution can be justified at megafunder scale: with more money, grift and low-quality projects abound, and downside risks for bad bets can partially poison the well for a broader portfolio. Multiple grantmakers and unhobbled donors with reputational firewalls, specialization, and different social graphs will enable more ambitious action.
Institutional structures slow decision-making. Good projects often wait three to six months for funding decisions. Strong projects with motivated teams stagnate or miss windows of opportunity. The Future of Life Institute is reported to hold several hundred million dollars in endowment and paid out approximately only $30M in 2025.
Passive grantmaking is the default. Requests for Proposals (RFPs) are common, but do not work at scale: the most competent people to start new projects are not usually unemployed and waiting in the wings. Active grantmaking, finding strong founders and persuading them to take on specific work, is becoming more common but still rare. The small number of existing funders also makes it hard to give credible commitments of future funding to ambitious founders, which raises the risk of starting an organization. The cultural shift from passive grantmaker to being capable of attracting founders and developing new networks will take time.
Risk tolerance is low. Reputational considerations and risk tolerance disqualify the most important opportunities. Funding will flow to well-known organizations like METR and Transluce, but neglected projects will stay neglected. These projects tend to require a higher risk tolerance: public-facing movement building, organizations representing stakeholder groups (e.g. labor, media, religious communities), relationship-building grants to DC think tanks, and interventions in general that have a more nebulous theory of change but high expected value.
Constraints are not legible. Clearly, these grantmakers have institutional constraints and strategic worldviews that make them appropriately cautious about what they support. Not all of these constraints are legible to the rest of the field. To their credit, CG has recognized the need for decorrelation and a diverse funder base. But the full extent of the gap has not been made clear, and new grantmaking organizations and unhobbled donors have not emerged.
Donor preferences are being aggregated. Sometimes, donor advisory organizations like Longview pool individual donors’ money into a single vehicle. This causes each unique donor, with their own theory of victory and preferences, to get flattened into the same averaged-out worldview. The decorrelation these donors could provide, and their ability to fund riskier, neglected projects, gets erased. Other times, this happens implicitly: donors take their cues from the same centralized funders and advisors, converging on a similar worldview and risk tolerance as megafunders.
The existing megafunders deserve lots of credit, but are (currently) failing to meet the moment.
New MegafundersNew megafunders will face their own constraints. The wave will arrive slower than expected, and not necessarily in the shape the field needs.
The wave will be slower than expected. Some have estimated that hundreds of billions of dollars in philanthropic capital are about to become liquid, largely from AI wealth. But both major funding sources are gated. The OpenAI Foundation has committed $25 billion (~10% of the Foundation’s value), but over an unspecified time frame. The framing of the Foundation as “the largest long-term beneficiary” of the for-profit's growth also suggests an endowment-style approach rather than a serious intention of trying to spend down capital in the years that matter. The Anthropic IPO is even further out: while a tender offer recently occurred, an IPO has not been announced, and post-IPO lockups will force employees to wait months before they can liquidate afterwards. Barring new ultra high-net worth individuals entering the space, the capital might come late, potentially too late.
New megafunders and donors are constrained. OpenAI Foundation faces serious optics constraints and has a similar governing board to the for-profit. Its pillars span a wide enough range that the pillars that are easier to spend on (life science, community programs) might absorb funding first. Work that materially affects OpenAI’s positioning will likely be implicitly off-limits. Anthropic employees, though they have the potential to become unhobbled donors, will likely have their own quirks. Many will be busy and want to delegate their philanthropic thinking entirely to trusted advisors. Some will avoid risky bets or political work that they perceive as outside the Overton window, opting to fund non-AI causes instead. Many will route through pooled vehicles for convenience, recreating the preference aggregation problem that incumbents suffer from.
Building infrastructure takes time. Even new megafunders that want to move quickly will not initially have the operational capacity to do so. Scoping new organizations, incubating founders, hiring staff, and massively scaling interventions all require institutional knowledge and processes. Creating that infrastructure takes time. Whether or not these megafunders will ultimately be successful depends in part on if existing funders and unhobbled donors can rise to the challenge to support them.
Unhobbled DonorsThe capital has not materialized yet. Even when it does, the most important projects will remain unfunded. Bold, unhobbled donors are needed to close those gaps.
These donors can have orders of magnitude more impact than large grantmakers. They can fund the most neglected projects that no one else can. They can move quickly on time-sensitive work or on infrastructure that needs years to mature. By seeding new projects early, they shape what organizations megafunders eventually scale.
It has never been a better time to be an individual donor with conviction.
What unhobbled donors doThey deploy fast and make grants directly, not through pooled intermediaries. They are laser-focused on impact rather than legibility or reputational comfort, taking the bets megafunders structurally cannot. They give c4, accepting the loss of the tax deduction. They put their names on public campaigns, engage with the media, evangelize the cause, and actively recruit new donors. They have a theory of victory, a causal story for how their grants will help the future go well, and aggressively front-load their giving to support it.
RecruitingAs the issue gets more salient, we might be on track to get more unhobbled donors by default. But given the importance of speed, we must be more proactive.
There are broadly three ways to close the gap: get existing megafunders to act bolder, activate more giving from individual donors already in the community, or recruit new donors entirely. Each is difficult.
Existing megafunders are trying, but are unlikely to become dramatically bold enough to completely solve the problem.
The most overlooked constituency is existing donors, especially those taking modest risks, splitting capital between causes, and deferring to advisors. We need to make the case to willing individuals that this moment warrants more aggressive deployment.
Recruiting new donors entirely is the most leveraged and the most difficult. The largest pools of recent wealth are mostly implicated in the problem they would be funding to address. People in general do not give, and right-of-center wealth, which would be especially useful for cross-partisan AI policy work, gives least.
The most viable candidates outside the implicated pool are scattered: billionaires and centimillionaires who are becoming concerned about AI, public figures with platforms, founders in adjacent industries. These donors will need to be found, persuaded, and supported by trusted advisors over months or years.
ActionsExisting funders should make demand more legible. As funders attempt to scale and front-load their giving, they should be more transparent about what they will and will not fund. By making their constraints legible publicly, they can more clearly communicate with potential donors about where they can be most impactful. Megafunders should also explore mechanisms to reward upstream funders, such as offering rebates to the previous funders of projects that they decide to scale.
Individual donors should spend differently. Look to front-load giving. Donor swaps allow donors to give to AI safety now in exchange for later commitments to other causes, or the reverse. Anthropic employees can take out loans against future giving. Regranting is a powerful tool for both small and large donors. Platforms like Manifund expose donors to new projects and allow for quick redeployment. Donors should resist organizations or platforms that aggregate their preferences.
The field should build donor advising infrastructure. Most donors who could become unhobbled are not ready to make complex grants on their own, and the field has not built the infrastructure to support them. This is a donor product design problem. New donors need clear default options, trusted advisors who can match them to opportunities without aggregating their preferences into one fund, and pathways into the field that do not require months of learning the landscape. Donors with higher risk tolerances and openness to neglected fields like politics should be carefully advised, and the field should coordinate to effectively allocate their capital.
If you can unhobble yourself, do it. Being unhobbled means giving up the things that donors are usually reasonable to want (reputational cover, tax deduction, confidence and institutional credibility). These are very real costs. But these are not normal times. Are the costs unhobbled giving could possibly have worth more than the direct impact? The dysfunction in the current landscape means there is enormous impact on the table for the ambitious philanthropists who are bold enough to take it. Stepping up to give ambitiously is a true service, and a sacrifice. It’s also exciting and energizing. Between now and 2028, the strategic playing field will be set. Why not shape it?
Discuss
Taxing Small Cars To Improve MPG
Cars and trucks are getting bigger, and I had a vague sense that fuel economy regulations were partly to blame. Looking into it, it's hard to say how much is regulations vs people wanting to buy vehicles that look rugged, but the regulations really aren't helping.
This chart is the core of it:
{kind=link}
This is what manufacturers were looking at when they decided to build today's cars. To figure out the target fuel economy for a vehicle you first calculate its "footprint", which is the area between the wheels. On our 2013 Honda Fit that's 4.8ft side-to-side and 8.2ft front-to-back, for a footprint of 39sqft. Then you ask if it's a car or truck. This tells you which curve to use, and where along it to look.
Looking at the chart we can now see why it's hard for Honda to sell a Fit today. The best Honda could do for a five-seater non-hybrid hatchback is maybe a CAFE rating of 44mpg. [1] This puts them 23mpg short, and if Honda was a one-model car company they'd expect to owe $3,910/vehicle in fines: $17 per 0.1mpg shortfall. Since the regulation is about an average across all the cars they sell the actual effect is both lower and more complex, and maybe something like $2k.
Aside: the fine structure here is a sad artifact of us thinking in miles-per-gallon instead of gallons-per-mile. Going from 25mpg (0.04 gpm) to 50mpg (0.02 gpm) saves as much gas as going from 50mpg (0.02 gpm) to infinite (0 gpm). But the penalty for being below a target is calculated on the gap in miles-per-gallon and not gallons-per-mile. If you miss a 50mpg (0.02gpm) target by hitting 25mpg (0.04gpm), or miss a 75mpg (0.013gpm) target by hitting 50mpg (0.02gpm), you pay the same fine even though the first involves burning much more counterfactual gas: over 10,000 miles the first burns 200 gallons more than its target while the second only burns 67 more.
What did Honda do? They discontinued the Fit, and replaced it with the HR-V. It's bigger and heavier, and looks like it was trying to be a "light truck". Combined with its larger footprint that would give a much lower target: 49mpg instead of 67mpg. It still doesn't hit that, but it's less of a penalty. And then it doesn't actually count as a light truck, though I don't know if that was the plan from the beginning or a compromise they had to accept.
Overall, this regulatory structure taxes manufacturers more for making small low vehicles, the kind that are easiest to make fuel efficient. Here's where I would write that this is counterproductive and we should stop, except we sort of already did. In 2025 the penalty for non-compliance was set to $0 as part of the OBBBA. This means in some sense manufacturers are free to make small cars and trucks with achievable mileage. Except the rest of the structure is still there, complete with the distorted incentives, and ready to be reinstated by a future government.
If at some point there's political will to improve this situation, and a carbon tax remains off the table, I'd like to see a return to the simpler Ford-era system where targets didn't scale with vehicle size. But then I'd need to understand why they switched to this system (if it's crash safety we should legislate that directly) and it's not clear that continued regulatory whiplash is worth it.
[1] The closest to 67mpg would be something like the first-gen
Honda Insight. This got very close, but seating only two people
with a lightweight construction that would do very poorly in modern
crash testing. If you're willing to make it a hybrid, which does add
significant cost, it is possible: the the Jazz
e:HEV (essentially a hybrid Fourth-generation Fit) would probably
come in around 72mpg.
Comment via: facebook, mastodon, bluesky
Discuss
A (Slightly) Mechanistic Theory for Exponentially Increasing AI Time Horizons?
AI ‘time horizons’ are mostly not about time (I think it’s mostly ‘data’, but you’ll see where I’m unsure).
One chart from 2025 has become perhaps the most (in)famous in modern AI commentary.
For those in the know, ‘the METR graph’[1] is unusually compelling because it achieves what so few measures of AI progress have achieved: a somewhat meaningful Y axis (‘time horizon’[2]) as well as a somewhat predictable trend over time! (This is remarkably rare!)
Frustratingly, the only superficially available takeaway is something like, ‘the line goes up straight-ish over time’. This is better than nothing, but it’s very dissatisfactory from the point of view of getting confidence in the predictions, because it exposes no deeper mechanism. This drives a lot of confusion and argument about the implications.
A deeper mechanism would be good for two reasons:
- It enables a sanity check on the trend, perhaps enabling more confidence in its predictions than we would sensibly allow with only the surface understanding.
- It gives some way to interrogate when and how the trend might change (because if the deeper mechanism gets deflected, the superficial projection would be broken, but a prediction based on the deeper mechanism might stay viable for longer).
- (A sub-reason: if we want the trend to change, knowing some more mechanism might shed light on some levers to pull rather than sitting around to wait and see.)
As an analogy, a similarly superficial trend, Moore’s Law, can be a little better mechanistically explained by the more general Wright’s Law[3]. This is great, because that law covers more cases, and it can handle some deflection from the trend, or give some idea of when (and under what conditions) the trend might break. Important when looking at plausible futures, and how to steer toward desirable ones!
Attempting to find some mechanism in the METR graphTask ‘length’ and success modellingWhy did METR focus on ‘task length’?
First, it’s not how long the AI agent takes. It’s how long the task in question takes a panel of sampled human experts, on average[4]. So in their ‘time horizon’ measurements, METR is capturing the effective hours of human-expert-equivalent activity that AI agents can carry out.[5]
One way to think about the time it takes human experts to complete a task is that, for each subtask they had to know how to do (or be able to figure out how to do) and then successfully execute, the overall task takes incrementally longer. By how much? That depends on exactly what ‘subtasks’ we're imagining breaking things down into.[6] But on average longer tasks correspond to more distinct challenges, all else equal.[7]
A random generation of tasks (rows) with ‘subtasks’ as segments, sorted by subtask count from least to most. You can see that the more subtasks, the longer, on average. It’s a little ragged — not all subtasks are the same length, so occasionally fewer, longer subtasks add up to more overall time than more, shorter subtasks. What METR can easily measure is the overall duration. Even if the subtask division is somewhat subjectively defined, duration stands as a reasonable proxy for it. Note that the vertical subtask count axis is sorted but not uniformly spaced. (Created with claude.ai.)
This is the first piece of mechanism we should take into account. ‘Time’ is not agent time: it's a noisy estimate for ‘number of somewhat challenging requirements necessary to complete the task’.[8]
This is treating overall tasks as formed by something like drawing ‘subtasks’ out of a large collection of possible requirements. Given the agent’s general competence, specific knowledge, tools available, and opportunity to retry or learn on the fly, sometimes the agent can meet these requirements. Other times it can’t.[9] ‘Longer’ tasks simply draw more subtasks (that’s why they’re ‘longer’, in this model: expert humans had more subtasks they needed to carry out).[10]
Toby Ord demonstrates one way to take this intuition further, noting that if we explicitly model overall success mjx-container[jax="CHTML"] { line-height: 0; } mjx-container [space="1"] { margin-left: .111em; } mjx-container [space="2"] { margin-left: .167em; } mjx-container [space="3"] { margin-left: .222em; } mjx-container [space="4"] { margin-left: .278em; } mjx-container [space="5"] { margin-left: .333em; } mjx-container [rspace="1"] { margin-right: .111em; } mjx-container [rspace="2"] { margin-right: .167em; } mjx-container [rspace="3"] { margin-right: .222em; } mjx-container [rspace="4"] { margin-right: .278em; } mjx-container [rspace="5"] { margin-right: .333em; } mjx-container [size="s"] { font-size: 70.7%; } mjx-container [size="ss"] { font-size: 50%; } mjx-container [size="Tn"] { font-size: 60%; } mjx-container [size="sm"] { font-size: 85%; } mjx-container [size="lg"] { font-size: 120%; } mjx-container [size="Lg"] { font-size: 144%; } mjx-container [size="LG"] { font-size: 173%; } mjx-container [size="hg"] { font-size: 207%; } mjx-container [size="HG"] { font-size: 249%; } mjx-container [width="full"] { width: 100%; } mjx-box { display: inline-block; } mjx-block { display: block; } mjx-itable { display: inline-table; } mjx-row { display: table-row; } mjx-row > * { display: table-cell; } mjx-mtext { display: inline-block; text-align: left; } mjx-mstyle { display: inline-block; } mjx-merror { display: inline-block; color: red; background-color: yellow; } mjx-mphantom { visibility: hidden; } _::-webkit-full-page-media, _:future, :root mjx-container { will-change: opacity; } mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-mi { display: inline-block; text-align: left; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretchy-h > * { display: table-cell; width: 0; } mjx-stretchy-h > * > mjx-c { display: inline-block; transform: scalex(1.0000001); } mjx-stretchy-h > * > mjx-c::before { display: inline-block; width: initial; } mjx-stretchy-h > mjx-ext { /* IE */ overflow: hidden; /* others */ overflow: clip visible; width: 100%; } mjx-stretchy-h > mjx-ext > mjx-c::before { transform: scalex(500); } mjx-stretchy-h > mjx-ext > mjx-c { width: 0; } mjx-stretchy-h > mjx-beg > mjx-c { margin-right: -.1em; } mjx-stretchy-h > mjx-end > mjx-c { margin-left: -.1em; } mjx-stretchy-v { display: inline-block; } mjx-stretchy-v > * { display: block; } mjx-stretchy-v > mjx-beg { height: 0; } mjx-stretchy-v > mjx-end > mjx-c { display: block; } mjx-stretchy-v > * > mjx-c { transform: scaley(1.0000001); transform-origin: left center; overflow: hidden; } mjx-stretchy-v > mjx-ext { display: block; height: 100%; box-sizing: border-box; border: 0px solid transparent; /* IE */ overflow: hidden; /* others */ overflow: visible clip; } mjx-stretchy-v > mjx-ext > mjx-c::before { width: initial; box-sizing: border-box; } mjx-stretchy-v > mjx-ext > mjx-c { transform: scaleY(500) translateY(.075em); overflow: visible; } mjx-mark { display: inline-block; height: 0px; } mjx-mn { display: inline-block; text-align: left; } mjx-msup { display: inline-block; text-align: left; } mjx-msub { display: inline-block; text-align: left; } mjx-TeXAtom { display: inline-block; text-align: left; } mjx-mfrac { display: inline-block; text-align: left; } mjx-frac { display: inline-block; vertical-align: 0.17em; padding: 0 .22em; } mjx-frac[type="d"] { vertical-align: .04em; } mjx-frac[delims] { padding: 0 .1em; } mjx-frac[atop] { padding: 0 .12em; } mjx-frac[atop][delims] { padding: 0; } mjx-dtable { display: inline-table; width: 100%; } mjx-dtable > * { font-size: 2000%; } mjx-dbox { display: block; font-size: 5%; } mjx-num { display: block; text-align: center; } mjx-den { display: block; text-align: center; } mjx-mfrac[bevelled] > mjx-num { display: inline-block; } mjx-mfrac[bevelled] > mjx-den { display: inline-block; } mjx-den[align="right"], mjx-num[align="right"] { text-align: right; } mjx-den[align="left"], mjx-num[align="left"] { text-align: left; } mjx-nstrut { display: inline-block; height: .054em; width: 0; vertical-align: -.054em; } mjx-nstrut[type="d"] { height: .217em; vertical-align: -.217em; } mjx-dstrut { display: inline-block; height: .505em; width: 0; } mjx-dstrut[type="d"] { height: .726em; } mjx-line { display: block; box-sizing: border-box; min-height: 1px; height: .06em; border-top: .06em solid; margin: .06em -.1em; overflow: hidden; } mjx-line[type="d"] { margin: .18em -.1em; } mjx-mrow { display: inline-block; text-align: left; } mjx-mtable { display: inline-block; text-align: center; vertical-align: .25em; position: relative; box-sizing: border-box; border-spacing: 0; border-collapse: collapse; } mjx-mstyle[size="s"] mjx-mtable { vertical-align: .354em; } mjx-labels { position: absolute; left: 0; top: 0; } mjx-table { display: inline-block; vertical-align: -.5ex; box-sizing: border-box; } mjx-table > mjx-itable { vertical-align: middle; text-align: left; box-sizing: border-box; } mjx-labels > mjx-itable { position: absolute; top: 0; } mjx-mtable[justify="left"] { text-align: left; } mjx-mtable[justify="right"] { text-align: right; } mjx-mtable[justify="left"][side="left"] { padding-right: 0 ! important; } mjx-mtable[justify="left"][side="right"] { padding-left: 0 ! important; } mjx-mtable[justify="right"][side="left"] { padding-right: 0 ! important; } mjx-mtable[justify="right"][side="right"] { padding-left: 0 ! important; } mjx-mtable[align] { vertical-align: baseline; } mjx-mtable[align="top"] > mjx-table { vertical-align: top; } mjx-mtable[align="bottom"] > mjx-table { vertical-align: bottom; } mjx-mtable[side="right"] mjx-labels { min-width: 100%; } mjx-mtr { display: table-row; text-align: left; } mjx-mtr[rowalign="top"] > mjx-mtd { vertical-align: top; } mjx-mtr[rowalign="center"] > mjx-mtd { vertical-align: middle; } mjx-mtr[rowalign="bottom"] > mjx-mtd { vertical-align: bottom; } mjx-mtr[rowalign="baseline"] > mjx-mtd { vertical-align: baseline; } mjx-mtr[rowalign="axis"] > mjx-mtd { vertical-align: .25em; } mjx-mtd { display: table-cell; text-align: center; padding: .215em .4em; } mjx-mtd:first-child { padding-left: 0; } mjx-mtd:last-child { padding-right: 0; } mjx-mtable > * > mjx-itable > *:first-child > mjx-mtd { padding-top: 0; } mjx-mtable > * > mjx-itable > *:last-child > mjx-mtd { padding-bottom: 0; } mjx-tstrut { display: inline-block; height: 1em; vertical-align: -.25em; } mjx-labels[align="left"] > mjx-mtr > mjx-mtd { text-align: left; } mjx-labels[align="right"] > mjx-mtr > mjx-mtd { text-align: right; } mjx-mtd[extra] { padding: 0; } mjx-mtd[rowalign="top"] { vertical-align: top; } mjx-mtd[rowalign="center"] { vertical-align: middle; } mjx-mtd[rowalign="bottom"] { vertical-align: bottom; } mjx-mtd[rowalign="baseline"] { vertical-align: baseline; } mjx-mtd[rowalign="axis"] { vertical-align: .25em; } mjx-msubsup { display: inline-block; text-align: left; } mjx-script { display: inline-block; padding-right: .05em; padding-left: .033em; } mjx-script > mjx-spacer { display: block; } mjx-c::before { display: block; width: 0; } .MJX-TEX { font-family: MJXZERO, MJXTEX; } .TEX-B { font-family: MJXZERO, MJXTEX-B; } .TEX-I { font-family: MJXZERO, MJXTEX-I; } .TEX-MI { font-family: MJXZERO, MJXTEX-MI; } .TEX-BI { font-family: MJXZERO, MJXTEX-BI; } .TEX-S1 { font-family: MJXZERO, MJXTEX-S1; } .TEX-S2 { font-family: MJXZERO, MJXTEX-S2; } .TEX-S3 { font-family: MJXZERO, MJXTEX-S3; } .TEX-S4 { font-family: MJXZERO, MJXTEX-S4; } .TEX-A { font-family: MJXZERO, MJXTEX-A; } .TEX-C { font-family: MJXZERO, MJXTEX-C; } .TEX-CB { font-family: MJXZERO, MJXTEX-CB; } .TEX-FR { font-family: MJXZERO, MJXTEX-FR; } .TEX-FRB { font-family: MJXZERO, MJXTEX-FRB; } .TEX-SS { font-family: MJXZERO, MJXTEX-SS; } .TEX-SSB { font-family: MJXZERO, MJXTEX-SSB; } .TEX-SSI { font-family: MJXZERO, MJXTEX-SSI; } .TEX-SC { font-family: MJXZERO, MJXTEX-SC; } .TEX-T { font-family: MJXZERO, MJXTEX-T; } .TEX-V { font-family: MJXZERO, MJXTEX-V; } .TEX-VB { font-family: MJXZERO, MJXTEX-VB; } mjx-stretchy-v mjx-c, mjx-stretchy-h mjx-c { font-family: MJXZERO, MJXTEX-S1, MJXTEX-S4, MJXTEX, MJXTEX-A ! important; } @font-face /* 0 */ { font-family: MJXZERO; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Zero.woff") format("woff"); } @font-face /* 1 */ { font-family: MJXTEX; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Regular.woff") format("woff"); } @font-face /* 2 */ { font-family: MJXTEX-B; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Bold.woff") format("woff"); } @font-face /* 3 */ { font-family: MJXTEX-I; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-Italic.woff") format("woff"); } @font-face /* 4 */ { font-family: MJXTEX-MI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Italic.woff") format("woff"); } @font-face /* 5 */ { font-family: MJXTEX-BI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-BoldItalic.woff") format("woff"); } @font-face /* 6 */ { font-family: MJXTEX-S1; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size1-Regular.woff") format("woff"); } @font-face /* 7 */ { font-family: MJXTEX-S2; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size2-Regular.woff") format("woff"); } @font-face /* 8 */ { font-family: MJXTEX-S3; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size3-Regular.woff") format("woff"); } @font-face /* 9 */ { font-family: MJXTEX-S4; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size4-Regular.woff") format("woff"); } @font-face /* 10 */ { font-family: MJXTEX-A; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_AMS-Regular.woff") format("woff"); } @font-face /* 11 */ { font-family: MJXTEX-C; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Regular.woff") format("woff"); } @font-face /* 12 */ { font-family: MJXTEX-CB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Bold.woff") format("woff"); } @font-face /* 13 */ { font-family: MJXTEX-FR; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Regular.woff") format("woff"); } @font-face /* 14 */ { font-family: MJXTEX-FRB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Bold.woff") format("woff"); } @font-face /* 15 */ { font-family: MJXTEX-SS; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Regular.woff") format("woff"); } @font-face /* 16 */ { font-family: MJXTEX-SSB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Bold.woff") format("woff"); } @font-face /* 17 */ { font-family: MJXTEX-SSI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Italic.woff") format("woff"); } @font-face /* 18 */ { font-family: MJXTEX-SC; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Script-Regular.woff") format("woff"); } @font-face /* 19 */ { font-family: MJXTEX-T; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Typewriter-Regular.woff") format("woff"); } @font-face /* 20 */ { font-family: MJXTEX-V; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Regular.woff") format("woff"); } @font-face /* 21 */ { font-family: MJXTEX-VB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Bold.woff") format("woff"); } mjx-c.mjx-c1D446.TEX-I::before { padding: 0.705em 0.645em 0.022em 0; content: "S"; } mjx-c.mjx-c1D461.TEX-I::before { padding: 0.626em 0.361em 0.011em 0; content: "t"; } mjx-c.mjx-c1D443.TEX-I::before { padding: 0.683em 0.751em 0 0; content: "P"; } mjx-c.mjx-c28::before { padding: 0.75em 0.389em 0.25em 0; content: "("; } mjx-c.mjx-c29::before { padding: 0.75em 0.389em 0.25em 0; content: ")"; } mjx-c.mjx-c3D::before { padding: 0.583em 0.778em 0.082em 0; content: "="; } mjx-c.mjx-c31::before { padding: 0.666em 0.5em 0 0; content: "1"; } mjx-c.mjx-c2212::before { padding: 0.583em 0.778em 0.082em 0; content: "\2212"; } mjx-c.mjx-c1D437.TEX-I::before { padding: 0.683em 0.828em 0 0; content: "D"; } mjx-c.mjx-c2F::before { padding: 0.75em 0.5em 0.25em 0; content: "/"; } mjx-c.mjx-c32::before { padding: 0.666em 0.5em 0 0; content: "2"; } mjx-c.mjx-c1D6FC.TEX-I::before { padding: 0.442em 0.64em 0.011em 0; content: "\3B1"; } mjx-c.mjx-c1D6FD.TEX-I::before { padding: 0.705em 0.566em 0.194em 0; content: "\3B2"; } mjx-c.mjx-c6C::before { padding: 0.694em 0.278em 0 0; content: "l"; } mjx-c.mjx-c6F::before { padding: 0.448em 0.5em 0.01em 0; content: "o"; } mjx-c.mjx-c67::before { padding: 0.453em 0.5em 0.206em 0; content: "g"; } mjx-c.mjx-c2061::before { padding: 0 0 0 0; content: ""; } mjx-c.mjx-c221D::before { padding: 0.442em 0.778em 0.011em 0; content: "\221D"; } mjx-c.mjx-c1D45B.TEX-I::before { padding: 0.442em 0.6em 0.011em 0; content: "n"; } mjx-c.mjx-c74::before { padding: 0.615em 0.389em 0.01em 0; content: "t"; } mjx-c.mjx-c72::before { padding: 0.442em 0.392em 0 0; content: "r"; } mjx-c.mjx-c61::before { padding: 0.448em 0.5em 0.011em 0; content: "a"; } mjx-c.mjx-c69::before { padding: 0.669em 0.278em 0 0; content: "i"; } mjx-c.mjx-c6E::before { padding: 0.442em 0.556em 0 0; content: "n"; } mjx-c.mjx-c1D6FE.TEX-I::before { padding: 0.441em 0.543em 0.216em 0; content: "\3B3"; } mjx-c.mjx-c28.TEX-S1::before { padding: 0.85em 0.458em 0.349em 0; content: "("; } mjx-c.mjx-c29.TEX-S1::before { padding: 0.85em 0.458em 0.349em 0; content: ")"; } mjx-c.mjx-c34::before { padding: 0.677em 0.5em 0 0; content: "4"; } according to a simple model where chance of failure compounds with task ‘length’, , we get a reasonable fit for the data METR collected. (Interestingly Toby mainly seems to continue treating this as ‘agent time’. I’ll instead take as given that we’re talking about a proxy for number of subtasks.)
In other words, for a given AI agent and task domain, there's something like a ‘hazard rate’, (per-subtask probability of failure), which reasonably well summarises (and predicts) the AI's level of success in that domain:
(i.e. to succeed at a -step task, the agent must not fail — must avoid the ‘hazard’ — times.)
This enables us to translate back and forth between an estimate of this hazard rate and an estimate of a ‘half-life’ or 50% success horizon — how ‘long’ (i.e. complex) a task needs to be before the agent fails more often than not — and also to extrapolate to ‘durations’ corresponding to other reliability levels, like 99% or 99.9%[11].
In this formulation, the hazard rate, , stands in for what fraction of our ‘subtask’ pool the agent can’t (yet) succeed at, which ends up being a reasonable summary of the agent’s competence in this domain.[12]
This time, we’re looking at overall task success as if the agent has a 98% chance of meeting any particular subtask’s requirements. Sometimes a shorter task will happen to have one of the difficult subtasks — but usually they’re overall successful. As tasks get longer, there’s a greater chance that at least one subtask requirement is insurmountable at this reliability level. Among longer tasks, overall success becomes fewer and farther between. This agent can’t expect to often succeed on tasks longer than 50 or so subtasks.
If you have a new task, you don’t know if the agent has all it needs to complete it. But the task ‘length’ is an indicator of how many tricky subtasks it has, and similar-lengthed tasks will have similar numbers of such subtasks — so their average success rate is a good estimate for how likely the agent is to succeed at this new task.
Relating hazard rate with frontier AI developmentMETR's graph is compelling because it suggests a steadily increasing frontier of success horizon as AI developers produce new agents over time.
What does this imply if we interrogate our hazard rate model? Well, 'half-life' (and indeed various success-level horizons) is observed apparently growing exponentially with date :
This is the central striking takeaway from the METR graph (modulo their measurement uncertainty). Half-life go up!
But half-life according to our model has:
where is the per-step hazard rate from before. When this is not too close to 1, that half-life is, fairly intuitively, approximately proportional to the reciprocal of the hazard rate:
So METR's observation of rising time horizons is equivalent to saying that the frontier hazard rate is shrinking exponentially over time.
Recall that this hazard rate corresponds with the fraction of ‘subtasks’ in a domain that an agent doesn’t yet know how to complete. So this fraction is presumed to shrink roughly exponentially with date, in turn driving the observed ‘longer’ success horizons.
Why does hazard rate shrink with date?Here’s where to look for the next bit of mechanism. Why would the hazard rate, the fraction of ‘subtasks’ which remain out of reach, shrink in that way?
It goes without saying that AI developers are chasing after increasing competence in their products, so (if they are doing anything at all right!) the direction of movement is unsurprising. Why that particular roughly-exponential form, though?
I confess here I’m uncertain and the quest for more mechanism continues.
My best guess is that it’s about the effective evidence available to the agent toward subtask solution strategy. Intuitively, if you’ve seen very similar subtasks many times before, it’s hard to go too wrong. If you’ve only seen vaguely similar subtasks once or twice, you’re in much less familiar territory and stand a good chance of stalling. Suggestively, effective evidence and training data are both information-like quantities, but I don’t want to make too much of that without a crisper connection. Formally, we could consider how many bits of evidence the agent can muster about how to proceed (either from past learning or by exploring in context).
In other words, training produces learnings. These range from broad, generally-applicable heuristics for adaptable, effective behaviour (experiment, test your work, notice when something surprising happens, read the manual if you can find one, accrue power and resources at any opportunity, ...), to narrow specific details about particular situations and activities (Earth's radius is roughly 6.4 megameters, detonating TNT yields roughly 4.2 kJ/g, humans succumb to oxygen deprivation after around 5 minutes, …). Ahem.
Empirically, AI developers have historically poured something like exponentially increasing ‘quantities’ of ‘data’ into their machine learning pipelines.[13] Mathematically, that implies a power law: data inputs rising at one exponential rate, matched by hazard rate decaying at another exponential rate.
Power laws aren’t deeply mechanically explanatory, but they’re often the best we have in machine learning, and are at least more predictable than mere date-based trends. Under the simple subtask model described here, this power law translates directly into a power law between ‘time horizon’ and data. This is actually the same level of explanatory improvement offered by Wright’s Law over Moore’s: not fully mechanistic, but an extra layer of detail which offers firmer purchase on what’s going on.
What this doesn’t straightforwardly account for is the benefit to success rates of increased in-context reasoning, which is exhibited according to METR’s estimates. I expect this is operating on those borderline subtasks — where the agent would have some slim chance of satisfying them if it ‘rushed’. In those cases, ‘thinking harder’ may more effectively recall and combine the relevant learned knowledge, and allow better choices for exploratory discovery in situ. In any case, changing the thinking budget of an otherwise similar existing system certainly calls for a more mechanistic understanding than mere date-based trend extrapolation!
I would be thrilled if someone with more smarts, time to experiment, and access to data were to dig into ways we could match up various AI production inputs (especially ‘data’ in various forms) with observed outputs like ‘time horizon’. One of the more difficult pieces might be quantifying ‘data’, especially teasing apart what types of evidence are ‘relevant’ for the domain and tasks at hand.
UpshotThe kind-of-boring upshot of this is that data and ‘practice’ on related tasks makes AI better at those tasks! This is boring because, well obviously!, we already basically knew that. But it’s encouraging because we can say a little more than that, which gives us some better grasp on what’s driving ‘time horizon’ progress in particular domains — and it can help get more precise about predictions.
The fact that the ‘subtask’ model — with a ‘hazard rate’ of subtasks currently out of reach — is a fairly explanatory fit for capability profiles of individual agents is evidence that there’re not unusual amounts of generalisation capability in AI. As with humans, they can extrapolate a bit, but need ‘experience’ and examples to succeed.[14] Importantly, this means that vast in silico training ranges for software, cyber, and mathematics very likely won’t transfer much to other domains of interest, like interpersonal intelligence, medical discovery, bioweapons development, intelligence analysis, and robotic manipulation. Of course, like with every domain of human experience and activity, we have some relevantly-similar data already collected, and schemes can be devised to more rapidly expand that digitised experience bank for AI to learn from. Increasing adoption of AI in task-integrated contexts, industrial deployment, and even explicit approaches to gathering example data such as ‘hand movement farming’ are the leading indicators to watch for progress in particular domains — not just the headline benchmark metrics in software-like tasks.
For some types of activity, developers are probably ‘running out’ of raw example data to scrape from the internet. The era of mostly-pretraining is over. For domains which can be relatively easily verified, like mathematics and coding, this is very surmountable — you can just run drills galore on a computer and get data that way. But this costs extra compute and doesn’t scale at the same exponential rate for long (perhaps 10x/year presently). As soon as this year, developers could be back to ‘only’ scaling compute around 4x per year (and a bit after that they might have bought most of the compute! — and will only be able to scale at the positively sloth-like 1.5x-ish a year of underlying hardware progress). I don’t feel confident extrapolating exactly where that cashes out, but if the data-driven subtask-learning model is right, it would imply we should see less steepness to the time horizon growth quite soon.[15]
Some commentaries project that, once AI can autonomously do software and machine learning work reliably, it will thereafter enter a ‘recursive self-improvement’ phase and rapidly colonise all capabilities. I don’t think this is missing the point entirely: there will be modest multipliers on the speed of the AI development pipeline, and we might see an ‘explosion’ in the speed and cost-effectiveness of AI (because they are among the most immediately-verifiable properties to iterate on). But generalisation doesn’t come for free, so on-task data and compute will remain crucial to broadening the frontier of autonomous capabilities. Collecting that data and manufacturing that compute look to me like the rate-limiting steps, and therefore the major leading indicators to use in foresight. The best case I can make for a much more general explosion is if the speed and cost-effectiveness explosions rapidly accelerate the gathering and digestion of diverse task data — but I think that remains mostly rate-limited in the familiar ways: some domains easy and some more difficult. Don’t mistake me for ruling out across-the-board AI capability! Companies are charging ahead with data collection and set on automating much of their AI production pipeline. It just won’t happen overnight.
Thanks to Coz Ududec for a conversation prompting me to think about this.
- ^
Produced by AI monitoring non-profit METR
- ^
Very importantly, it’s measured within a particular collection of challenges/tasks which are mostly associated with software development, especially ML engineering. METR also has a great preliminary study of some other domains, finding differing, but perhaps also somewhat predictable trends.
- ^
Moore’s Law is the very superficial observation that, over time, the number of transistors per chip doubles roughly every two years. (More recently, it’s been more clearly expressed as the price per transistor halving every year-or-two.)
Wright’s Law is the slightly more mechanistic and general observation that production of many commodities follows ‘learning curves’, such that each doubling of cumulative production produces roughly similar relative cost savings. (We can in turn attempt to explain this in yet more mechanistic terms, pointing to the insight gained from observing and recording many trials and experiments, with suitably diminishing returns.)
Now, if the quantity demanded and produced grows exponentially over time (as it has for computer chips), then Wright’s Law predicts comparable cost savings each year: Moore’s Law. If the quantity produced grows (or shrinks) in some other pattern over time, Wright’s Law, by accounting for this mechanistic detail, can often forecast cost trends more reliably than Moore’s.
- ^
Also note that the estimation of ‘task length’ according to human experts was quite crude (naturally, humans are the most expensive part of most experiments!), and there are good reasons to treat the reported error bars as much too narrow, i.e. misleadingly confident. I’ll use quotes around ‘time’ related quantities in this post as a reminder that it’s a loose estimate of a crudely human-performer-derived time-to-completion for tasks, and doesn’t correspond well to real time as such.
- ^
I don’t know if METR publishes how long the agents themselves take at these tasks — I don’t think so, and it’d arguably be ill-defined anyway since it would depend in part on how fast a computer you ran the agent on.
- ^
If we conceptually carve up subtasks into smaller pieces, they'll be quicker per piece, but there are commensurably more of them, and vice versa.
- ^
This could come apart if longer tasks are systematically more likely to include repetitive similar activities rather than a series of distinct ones, for example. Or longer tasks might tend to admit more truly alternative pathways. Both these effects could make longer tasks slightly easier than the naive picture. There are also higher-level ‘orchestration’ tasks i.e. coherently coming up with (and executing and adapting) an appropriate sequential plan: perhaps these might be systematically more difficult for longer tasks.
- ^
Notably, agents sometimes take a (relatively) longer time to do something that’s quicker for humans, and vice versa.
- ^
Incidentally, success (or not) here already accounts for the agent attempting and re-attempting steps or fixing earlier mistakes, which might take variable amounts of time: another reason not to treat this as agent time. Some subtasks might be intermediate and succeed sometimes (for example if the agent can’t easily choose the best approach but sometimes hits on the right one, or sometimes gets stuck in a terminal cycle but sometimes makes lucky progress.)
- ^
This is throwing away some detail: obviously not all subtasks are equally likely to follow from each other! There’s some correspondence between on-task sequences. But within a particular domain (like software engineering), this naive model of overall tasks combining subtasks somewhat randomly seems to do OK.
- ^
By the way, the rule of 72 provides a really quick mental approximation for the higher-reliability ‘time’ horizons, depending on the ‘half-life’ (the 50% ‘time’ horizon).
Divide the ‘half-life’ by 72. That’s the 1% failure horizon (equivalent to the 99% success horizon). Multiply by your target failure rate in percent, and you’re done: that’s your target success ‘time’ horizon. E.g. if ‘half-life’ is 1h, the ‘time’ horizon at 99.9% is (1h/72)*(0.1) i.e. 5 seconds.
(This also reveals that cutting the ‘time’ horizon tenfold cuts the average failure rate tenfold and so on.)
Going the other way, estimating long-horizon success rates, divide your target horizon by the ‘half-life’. That’s how many halvings of success to expect: raise one half to that power for your success rate. E.g. if ‘half-life’ is 1h, your 24h success rate is i.e. one in sixteen million.
- ^
It didn’t have to be that way! A single number which manages to explain a lot of variation in agent capability is very suggestive of an underlying mechanism something like the ‘fraction of subtasks’ model I’ve described here. Of course there is still some residual uncertainty and there may be better summaries available with a more detailed model or epicycles on this one.
- ^
This may recently be trickier to measure as training pipelines have adapted to incorporate more reinforcement learning, which means these experience data are less ‘homogeneously slurped up from the internet’ and increasingly ‘proactively curated from in-domain training curricula’. So the mere quantity of data isn’t like-for-like over time.
- ^
In fact contemporary AI is perhaps substantially less good at generalisation than humans, though I’d like to be better informed about how factors like sample efficiency of AI learning (including in-context learning) stack up.
- ^
Actually saying something so bearish about AI makes me nervous, as there is a venerable history of people boldly declaring AI is about to hit a wall! But I think it’s borne out. I’m not saying progress stops, I’m saying it probably gets slower (in exponential terms).
Discuss
Страницы
- « первая
- ‹ предыдущая
- …
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- следующая ›
- последняя »