Вы здесь
Новости LessWrong.com

Neurogastronomic Phenomenology for Advanced Beginners, Applied and Pure
(This one's a double-header on the tightly-linked senses of smell and taste, especially pertaining to foodcraft; it comprises both The Space of Olfaction is δ-Hyperbolic and A Partial Theory of Flavor Pairing in Foodcraft. You could read them in either order. I've chosen to put the more widely-appealing one about food phenomenology first and the less polished and more abstract and speculative one about olfaction second. Dedicated to SR-S and SS on the occasion of their marriage, and to the whole S family, who has already begun to benefit from this theoretical depth. Enjoy the sixspice buns!)
(Part 1: Theory of Foodcraft. Epistemic status: only partially worked out, lots of handwaving, still not something I've seen talked much about explicitly anywhere.)
(With thanks to @johnswentworth, @Morphism, @WhatsTrueKittycat, and MR and RG of Mox, among others, who all asked for this. If you asked me for this out of the list, it's also for you.)
Food and drinks have flavors [citation needed]. In fact, they have lots of flavors - careful tasting of an ordinary bottled barbecue sauce presents sweetness and tartness and savoriness, and beneath those, tomato and molasses, and beneath those - if you get that far - mustard seed and paprika and onion powder and "some kind of fish sauce???". (It's Worcestershire sauce.) Some flavors blend nicely, like onion and garlic, while others clash, like onion and pineapple. But then some very different flavors pair just fine, like apples and cinnamon, or vanilla and nearly anything you'd find in a dessert. And even onion and pineapple go together just fine in the greater context of a salsa, or even a pizza! So what's going on?
Here's a stab at explaining why. I'll use "food" as a term of art to mean anything intended to be eaten and enjoyed. A food flavor is comprised of two major parts: its tastes (sweet, salty, spicy, all the basic and chemosensory types) and its flavors (individual odorants, mostly associated with specific ingredients like cumin, tomato, or beef). On top of that, we have things like its context (what's the nature of the larger mixture? is it a dessert? a stew?), its temperature, and the relative concentration of flavors, and to a lesser extent modifiers like how cooked it is (caramelized, raw, normally cooked as "blurs out and turns up the gain" on flavors), what solvent it's in (water, alcohol, fat), the physical properties of the substrate (is it crunchy? soft? liquid?), and what expectations you have when tasting the food.
On my model, a combination of flavors tastes at least OK if at least one of three things is true, and generally better with more of them satisfied. The combination can call back to a known tasty food, it can have satisfying blending with no bad clashes, and it can have interesting bistable contrasts with indepdently good-but-maybe-overstrong components.
The first of these, the Rule of Familarity, is the simplest to explain. A food will probably taste OK if the flavors in it match closely to the major notes of a known and beloved dish and the presentation of the food isn't too terribly different. This is the operating principle behind any fussy "deconstructed" food: you take the components of a dish and permute or alter their order or presentation while leaving the basic notes intact, as well as the general presentation. Maybe you also really sell the phenomological binding by adding some additional element that would classically go with the dish, just to control expectations a little. Take the example of a deconstructed apple pie. Turn the apple filling to a reduction sauce and swap crust for an artful bed of crumbs. Make very sure that the apple sauce has a bit of molasses and cinnamon in it, maybe some other pie spices. Apple pie's easy for presentation, since it's served both hot and cold, but if you really want to sell the effect, serve it with the sauce piping hot with a scoop of vanilla ice cream alongside. It'll be... fine. Sell it for 30 bucks a plate. (Give me a proper slice of pie any day, though.) Almost every food can be done up this way - dishes have major ingredients that people will expect, expected form factors or temperatures to serve them at, and expected roles that need to be filled. Match those well enough and you probably end up with something good.
The second, the Rule of Harmony, is a little trickier: there is a need for satisfying blending. A food will probably taste OK if any given pair of flavors in it blend satisfyingly, and no pair of ingredients clashes. On this model, a pair of flavors blends well if they share flavor chemicals; the more, the better the blend. Thus: onions and garlic, vanilla and most (but not all!) sweet flavors, and meat with anything savory, like tomato. This also helps explain what's going on with spices: they're almost pure flavor, and frequently contain flavorant chemicals that they share in common with ingredients. This in particular is why vanilla and chocolate see such wide appeal, and why rose was once the standard for desserts before vanilla: their chemical makeups are exceedingly complex and multifaceted, having some degree of commonality with a wide variety of different ingredients. This is also why oak is used for wine casks: it too contains vanillin. Alternately, we might contrast the sense of "blending" here with "masking", where "masking" should be taken to mean an attempt to force a fit by moving as far as possible to one extreme of the bistable spectrum; this rarely works out well. For instance, certain intoxicatingly herbed pastries frequently contain lots of chocolate in a doomed attempt to mask the taste. Better to work with the terrain rather than against it, to blend the flavor in instead - from personal experience I can recommend a nice quiche Florentine, whose heavy spinach component blends much better with bitter green flavors, especially alongside the base of pleasantly sulfurous Gruyere cheese and eggs, with onions, garlic, and perhaps some bacon all indicated.
Lastly, the Rule of Interesting Contrasts. A food will probably taste OK if it has some kind of interesting bistable contrast in it and it's made of individually good-but-maybe-overstrong components - and, again, no bad clashes. By bistable here I refer to an effect that can be achieved straightforwardly with careful balances of pairs of distinct tastes or even flavors, where we note that (e.g.) with a combination of salty and sweet, at one extreme the mix is just salty, at the other it's just sweet, but at some point in between, finely graded concentration differences and habituation effects give rise to the sensation of a taste that seems to flip back and forth between the two components. This is the operating principle behind trail mix: people generally like some subset of dried fruit, chocolate, beef jerky, cheese crackers, assorted nuts, and the like. (It's also the operating principle behind any cursed combination of foods that's "surprisingly good".) Each of them hits all the expected marks for being individually enjoyable - one or more of salt, sugar, and fat; individually enjoyable flavors; pleasant texture and form factor; all that good stuff. Also, for any given pair of those, there's one or both of a difference in taste - covering both sweet and salty - and a reasonably compatible difference in flavor (e.g. meat and fruit). Here we find a deep secret of foodcraft: never neglect the acid. A little tartness is a vital component of almost any food, and I hypothesize that a part of why is its capacity to play a supporting role to contrast well with sweet, fatty, and salty alike.
As with any art, the rules are not ironclad, and they can be broken to good effect. Neither are they universal: a combination of shrimp paste and pears might disgust you, but to the Indonesian palate, it evokes delicious rojak. Another is the rule against bad clashes: on this model, the reason why onion and pineapple go just fine together in a salsa is that the onion pairs excellently with the tomato (itself arrogating the savoriness of meat, along with salt), and the pineapple serves the role of adding sweetness and tartness, supporting the salsa as a whole rather than pairing with any specific ingredient; the same is generally true of any dish where one ingredient sticks out as particularly weird, and likewise, there likely ultimately exists no pair of ingredients that cannot be made to go together somehow in some dish. From this we might posit that the rule of familarity can override some minor clashes, if one of the clashing ingredients is core to the dish, the other is serving some role, and the clash is merely not enjoyable rather than actively offensive. Conversely, the "Incompatible Food Triad" - three ingredients that go together well pairwise but not as a triple - points the way to what looks like a puzzling inconsistency, but we might resolve the seeming paradox by pointing out that in such cases, any pair of the three evokes a very different dish, with the third having no place in it at all. That said, even the foremost research into Incompatible Food Triads has failed to turn up any particularly clean or striking examples of one, the closest being yogurt, salted cucumber, and sugar - breakfast yogurt, tzatziki, and sweet pickles are each perfectly fine dishes, but they pull in very different directions.
Using the principles expounded here, you can start composing your very own dishes. My specialties are generally of this sort: I've made a delicious beef stew halfway between an English-style stew and a boeuf borguignon; I've made a variant on cinnamon buns that uses plenty of Chinese five-spice powder, on top of the use of tangzhong dough preparation, to approval from Grandma Kim and numerous friends alike; and I've swapped out the broccoli in various dishes with Romanesco cauliflower to cheers. People ask me how I think of these substitutions, but considered rightly in a frame that this post partially illuminates, they all constitute natural alterations. Go make something delicious of your own!
(Part 2: Theory of Olfaction. Epistemic status: barely even half-baked - but unique, intriguingly plausible, and anyway no one has any better ideas.)
Vision, hearing, the numerous aspects of touch, taste, and smell: of these, smell - or olfaction - is by far the worst-understood, even if we try to tease out the role that olfaction plays in flavor, separating it from the gustation and chemoception that strict-sense taste encompasses. As Convergent Research puts it, “We can’t yet replicate animal olfaction synthetically as a sensing and classification modality. We currently lack a comprehensive model explaining how biological systems decode and classify chemical signals through olfaction. Understanding this process is critical for applications ranging from flavor science to disease diagnostics to understanding and harnessing animal communication.” This past weekend, I briefly attended a “gap mapping” research hackathon organized by YJK; my thanks both to him and to DK who invited me.
While I couldn’t hope to build a full olfaction decoding model, nor fully map odorant-receptor binding, nor even give a robust and comprehensive working theory of how to replicate olfaction in the few hours I had, I thought it prudent to at least clean up my existing thoughts on the subject, given how they’re informed heavily by both my experience in geometric group theory - far removed from the life sciences - as well as my experience as a skilled home chef, sometime perfume blender, and possessor of a keen sense of smell as linked to a keener phenomenology. With any luck, the added insight from the model I sketch out of how olfaction might work will prove a useful map for others more skilled in more central approaches to the question of olfaction; I believe the model to be a plausible one, given a few established facts about both the biochemical basis and subjective experience of olfaction.
Let me start by defining some terms carefully and laying out premises in the language that those terms scaffold. I’ll use “smell” to describe a direct olfactory percept, like the experience of exposure to (+)-limonene, or to ammonia with minor adjuncts, or to a blend of citronellol, geraniol, rose oxide, and beta-damascenone. I’ll use “scent” to mean the olfactory experience a person might have on being exposed to that smell in some concentration or set of concentrations; respectively: orange, stale cat urine, and rose.
For some established facts, we first note that olfactory receptors come in many different varieties, each highly selective to a single small molecule, or to a small set of chemically similar small molecules. Additionally, every such receptor has a band of sensitivity in terms of (say) parts per billion, below which the smell is imperceptible and above which the receptor either tops out or else no longer fires at all (consider the infamous case of hydrogen sulfide); we can rescale that range to the open interval (0, 1) as a fraction of maximal perception strength. As a minor fact, chiral molecules generally smell very different from each other, and don’t cancel each other out: the scent of (+)-limonene closely corresponds to the smell of oranges, but (-)-limonene’s scent better approximates pine; (+)-carvone smells like caraway or dill, while (-)-carvone’s scent is much more like the smell of spearmint. Meanwhile, we may make two mysterious observations: that given one scent, the addition of any amount of any other scent will be smothered by it, blend with or mutate it into a different scent, or stand out against it altogether; and that when moving through a room with a single (complex) smell source present, the resulting scent perceived can nonetheless change with factors including position with respect to the source, air currents, and even different individuals’ olfactory keenness or disabilities.
My major premise is this: arbitrary combinations of smells can be observed, but any two scents built up from smells - even the same list of smells, in some cases - differ greatly from each other, and this suggests that olfaction is best understood as having a treelike or hyperbolic structure to it. (This is notably unlike audition, which may be modeled as involving something like a Fourier decomposition with some added spatial information from timing differences, and unlike vision, which may be loosely modeled as having some pixel-like structure with three-dimensional Euclidean (color) coordinates for each pixel.) In addition, just as the color gamut is limited to only a part of Euclidean space, so too is the scent gamut limited to a tiny sliver of the possible (high-dimensional) hyperbolic space, given the nonexistence of anti-scents - though the nature of hyperbolic space is such that unlike with color, we barely notice the lack.
To understand why this is so plausible, it will be necessary to explain the concept of a δ-hyperbolic space. A δ-hyperbolic space is a metric space in which for any triangle ABC that we might draw, every point on the side AC is distance at most δ from some point on one of the sides AB, BC, and likewise for the other two sides Put another way, the entirety of each of the sides is relatively nearby to the other two sides of the triangle. (This is the picture at the head of the page.) The ordinary hyperbolic plane can be calculated to be ~0.88-hyperbolic, and at δ = 0, we find trees - note that for any three points in a tree, if they’re not part of a single path, then there exists a unique vertex which all three sides of the triangle contain.
The δ-thin hyperbolic model of olfaction then goes like this:
- Each olfactory receptor has some band it receives best in; we can rescale this to an open interval like (0, 1).
- Smells are best transcribed as a list of olfactory receptors, ordered from strongest to weakest (rescaled) response; something like (ABCDEF…)
- A pair of scents is similar in quality exactly when the two scents agree for a large number of initial receptors, that is, we have something like a natural word metric on the space.
- Each such receptor defines a vector in the hyperbolic space, with most pairs of scents orthogonal to each other and a rare few pairs closer-linked. We can consistently define something like cosine similarity between subjective responses to pure stimulation of individual olfactory receptors, but this would need to be measured empirically.
- Obviously, chiral and algebraic inverse are not the same; spearmint and caraway do not cancel out, even if their rescaled percept strengths are similar enough for the receptors to be adjacent in the scent-list.
- Slight differences in scent perception can occur if the strengths of the components of the smell vary slightly (perhaps due to air/fluid circulation), especially if some pair of smell components provokes similarly strong rescaled responses. This might lead to bistable smells.
- The set of all perceptible smells, having this treelike structure, is δ-hyperbolic, and we could (empirically) measure this δ; scent perception is based on dividing up this hyperbolic space into contiguous directions, possibly Voronoi cells on the surface of some segment of a hyperbolic hypersphere, surely of varying size.
- The experience of more than one different scent occurs when the components of a smell can be most naturally grouped into two or more recognizable clusters with small intra-cluster and large inter-cluster metric distances.
This model suggests a few ex ante predictions/explanations and proposes associated measurements and tests..
- There should be a bistable scent that can be generated by the right mix of smells - probably three of them, where going from (ABC) to (ACB) produces notably different scents. That scent (or pair of scents?) should give us good bounds on the just-noticeable-difference level for relative concentrations from swapping the concentrations of the subdominant smell components.
- There should be some overlapping chain of smells which makes two otherwise unrelated-smelling scents blend. Similarly, there should be a scent (probably a mix of at least four or five smells) from which the removal of some “central” scent breaks the scent apart into two unrelated-smelling scents.
- There should be a “base perfume” blend that one could turn into numerous importantly different scents through the addition of a small amount of chosen extra odorants - specifically not just “neutral-ish base enriching chosen scents”.
- The phenomenon of synthetic scents feeling “flat” but only rarely wrong likely comes from a natural scent having a form like (ABCDEF…) and the synthetic form having a form like (ABCD) - truncated, but still nearby.
- The (now sadly-well known) phenomenon where some sufferers of COVID-19 smell nothing but garbage is likely partially explained by total loss or at least of some of the olfactory receptors, collapsing most of the space of scents down to their garbage-like components by dropping the other coordinates. It’s also possible that these receptors have instead been scrambled such that their signals cannot be adequately received or interpreted, much as some sufferers of nerve damage have reported with various forms of touch.
- Actually do the empirical measurements for subjective cosine similarities between olfactory receptor activations - something like the process that brought us word2vec.
- Likewise, actually measure the subjective metric distances between nearby scents, and probe the borders of each projective scent subspace.
Discuss
Heretical Pasta
If you ask the internet how to prepare pasta you'll hear two things:
You must salt the water.
You must serve it mixed with the sauce.
I disagree on both.
I've been cooking pasta since I was a kid, and I prepare it the way my mother (who grew up in Rome) did:
Cook it way less than it says on the box, until it's no longer crunchy but not further.
Time dinner so that the pasta is the last thing to be ready, where you're eating it within 5min of it coming out of the pot.
Serve it in one bowl, with the sauce in another.
The primary goal is to keep the tastes and textures distinguishable, merging only as you chew. The pasta resists your teeth; the sauce flows. The sauce is rich and flavorful; the pasta is a hearty foil. Secondarily, by combining only on each person's plate you can handle a range of preferences in sauce-to-pasta ratio, and different dietary restrictions (ex: a separate vegan sauce).
I don't know how people ended up thinking there was only one way to cook pasta, but to my taste the standard approach is a big missed opportunity.
Discuss
Veganism is Virtuous but not Obligatory
Tl;dr: Here, I argue that eating meat is morally acceptable. The central point is that every argument for abstaining from animal products being a moral obligation is also an argument for more extreme levels of obligatory abstinence. The “as far as is practicable” constraint vegans often assert either permits omnivorous diets, or entails extreme obligations that nearly all vegans fail to fulfil. I view abstaining from animal products as a virtuous, supererogatory act - similar to building free houses for the homeless. It is something that is beneficial and kind, but regarding it as obligatory seems indefensible under a consistent view of ethics.
Upfront acknowledgments: Factory farming is despicable and I would gladly see it abolished. Animals have moral worth. I support vegans, particularly on policy. The animal industry is bad for the environment. Eating animal products is not necessary for a long, healthy life.
Terminology: I use slightly nonstandard meanings of certain terms (eg: virtuous = supererogatory) in this essay, and have taken care to use terms consistently throughout. Definitions are available in the appendix.
There is a distinction between an obligatory action and a virtuous action.
Obligation: Something you must (or must not) do
Virtuous action: Something that is moral to do, beyond one’s obligations; supererogatory.
The factors that determine whether abstaining from a practice is obligatory are twofold: the sacrifice it would impose on the abstainer, and the immorality of the action. These jointly determine which side of the obligation threshold an action falls on.
There are many cases where an action causes substantial harm to moral patients, yet is permissible. Two actions can have equal expected harm, yet differ in permissibility.
Consider the following hypothetical:
Anne has one laptop. It contains treasured photographs and videos of her late family, who died in a car accident. The laptop is broken, preventing copying or backing up of files through either external drives or the internet - it is her only way of preserving the memories of her loved ones, and is her most treasured possession. However, every time she charges the laptop, she causes some harm to the environment, since the grid relies on fossil fuels.
John has an identical laptop. He uses it as a paperweight for papers he doesn’t use, but because he thinks the light emitting from the screen looks slightly interesting, he keeps it on, and charges it using the same grid, with equal frequency to Anne. This causes the same harm to the environment.
In this case, John has (or is far more likely to have) an obligation to abstain from using the laptop. For Anne, using the laptop is clearly permissible, despite equal expected harm produced by their actions.
Rejecting the principle entails the conclusion that John and Anne are equally obligated to abstain from charging the laptop in order to avoid harming the environment - an absurd conclusion.
If sacrifice doesn’t free you of an obligation as long as harm is brought to moral patients, then eating a vegan diet is also unacceptable, as it carries an expected lifetime burden of counterfactually killing numerous small creatures as an unavoidable side effect of crop farming.
Most vegans acknowledge this principle by implication. The vegan position is broadly that one ought to “reduce animal suffering to the greatest extent possible, or practicable” - implying that highly impractical or gratuitous sacrifices are not part of one’s harm reduction obligations, but feasible, non-extreme sacrifices are.
Furthermore, just because an action (such as a vegan diet) is less harmful than many alternatives, doesn’t justify it as permissible. All actions that are harmful are less harmful than alternatives. Eating typical quantities of meat is less harmful than eating enormous quantities of meat, which is less harmful than massacring millions of animals. If one holds that an action being less harmful than many alternatives is adequate to justify it as permissible, then virtually all actions, including extreme, gratuitous violence, are permissible.
There is no Principled Distinction Between “Need” and “Want”Invoking “need” is central to many arguments made by vegans. If a vegan aims to differentiate not eating meat and, for instance, not using electricity, on the basis that you “need” to use electricity, they must provide a clear distinction between what is a need, and what isn’t.
I argue that needs are exclusively instrumental to some wanted thing, and there is no such thing as a terminal “need” that is different to a terminal “want”.
One “needs” something only if it produces a result that they want. In every case of a need, the needed thing facilitates, or is equivalent to, a desired end state. Absent a preference for the end state, need dissolves without exception. A person who doesn’t care to live, doesn’t need to breathe, for example.
Therefore, a “need” is equivalent to: “A thing that results in something we want (for its own sake)”, and is thus entirely subjective.
Contra the “Survival” Framing of Need
Commonly, a need is defined as: “A thing without which you will die”
A literal reading of this definition faces an obvious problem: we will all eventually die. So, strictly, this entails we need everything in existence, rendering the term functionally meaningless.
A steelman of this framing is “A thing without which, you will die earlier than otherwise”. This does not withstand scrutiny either.
Consider a hypothetical supplement that would extend your lifespan by a single hour per sixty years of daily use. If you miss a single day, the clock resets.
Under the definition of “a thing without which you will die (earlier than if you had it)”, this supplement qualifies as a thing you need. It seems clearly absurd to call this a “need”, and thus the definition fails to capture the true meaning of the word.
There is no mind-independent threshold of lifespan addition beyond which this supplement would suddenly become a “real” need versus an optional luxury. At 1 hour of extra lifespan per 60 years, or 1 day per 60 weeks, or even eternal life after a single dose, there is no point at which it transforms into an inarguable, mind-independent need.
On “Proper Function” and “Natural Kinds”
To avoid bloating this essay, I will not argue for the position of anti-realism about natural kinds and related concepts like “proper function” - I am flagging it here as a background premise.
In brief, I reject the position that there are objective facts about the “correct” functioning of humans, animals, or any other organism or object. I maintain that these are merely observations about “things that tend to be true of X” rather than “things that X should have”. The second cannot be objectively derived from the first.
Contra the “Harm Avoidance” Framing of Need
The supplement hypothetical shows longevity is insufficient to ground a distinction between need and want. However, one may argue for “need” being sustained in both cases by the opposing harm involved. The supplement is bitter and inconvenient. These are forms of harm.
So, can “that which avoids or mitigates harm” serve as an objective distinction between “need” and “want”?
This distinction collapses to equating need with want, and relies on smuggling “wants” into the definition via the word “harm”.
What does “harm” mean in the context of this framing, if not “a thing producing unwanted consequences"?
Some may invoke an outside view of harm: something like “an adversely impactful divergence from the typical or proper function of a thing”.
This invokes “proper function”, which as noted, is taken to be an invalid concept. Additionally, the work of this definition of harm is being done by the word “adverse”, which means “harmful”, making it a circular definition. Without the word “adverse”, this definition reduces to “a divergence from the norm”, and a person being transformed into Superman would be considered harmed.
Therefore, the outside view of harm is either circular or absurd.
The distinction between eating meat and killing animals is one that is often glossed over in arguments about animal ethics, where the two are treated as equivalent - purchasing one chicken equals killing one chicken. I argue this is a false equivalence.
Eating meat is not as morally bad as killing animals because it is significantly less direct in every important regard.
By directness, I mean: having a close causal or mechanistic relationship to something, absent intermediary mechanisms or ambiguating factors.
Directness is a spectrum: the less time, intermediary mechanisms, and unpredictability connecting an action to its outcome, the more direct it is, and vice versa. For example, shooting a man is slightly more direct than paying someone to poison him, which is significantly more direct than starting a podcast that advocates for violent crime in his local area. This is orthogonal to outcomes - even if the expected value of human lives lost is the same in all three cases, they differ in directness.
I argue that a harmful action that is more direct is more immoral than a harmful action that is less direct. I argue that the direction of this difference universally favours eating meat over killing animals.
Directness being rejected as an intensifier leads to absurd conclusions
If directness is held to be irrelevant to the morality of an action as long as the expected outcome is the same, this leads to indefensible conclusions.
For instance:
Approximately 365 million vertebrates are killed by cars on roads each year in the United States. There are approximately 240 million licensed US drivers. Therefore, the average driver is expected to kill ~1.5 vertebrates per year. Assuming a driving window of 50 years, this entails that the average driver will kill roughly 75 vertebrates in their lifetime.
A vegan who rejects indirectness as a mitigating factor must concede that driving a car in typical conditions today is no different morally than buying a car that is (through hypothetical technology) completely harmless to animals on the roads, but is sold to you on the condition you personally crush 75 live vertebrates underfoot before being handed the keys.
This position is untenable, and the vast majority of vegans would consider this to be grossly immoral in a way that general car driving would not, despite identical expected harm. Thus, a rejection of indirectness as a mitigator is reduced to absurdity.
Per-Instance Probability Is Relevant to Morality Even with Equal Expected Outcome
In cases of equal expected value, I argue the absolute per-instance probability of a bad outcome remains relevant, and that lower probability bad events are more moral choices to higher probability bad events, ceteris paribus.
Consider the hypothetical:
A mother of 10 children must either (A) sacrifice one of her children, or (B) accept a 1/10 chance that all ten die.
I maintain that the 1/10 chance is a more moral choice, and that a woman who would willingly forgo a 90% chance of total safety in such a scenario would be acting immorally.
Inverting the principle seems unacceptable, committing one to sacrificing their child for the sake of avoiding an unlikely, proportionally severe event.
Ambivalence is suspect - it seems to call for a preference for one case or the other, particularly given the apparent unacceptability of option A. Few would waive their right to deliberate in this scenario.
Indirectness of mechanism: Variance in the supply chain
If you go to a grocery store and buy a chicken, the store owner does not immediately notify a chicken farmer of your purchase and order exactly one chicken to replace it. Instead, the grocer may take inventory every two or three days to see how many chickens have sold (with some inaccuracy given the inevitability of misplaced stock, theft, administrative errors, etcetera). Let's say it's 187, so he puts in an order for 200 chickens. He might sell more next week, and it's better to have a slight surplus than to run out of stock.
Further still, the number of chickens ordered doesn't have a 1:1 relationship with the number of chickens that are raised and killed by the farmer, because a single grocer ordering 200 chickens is analogous to a single customer buying one chicken from the grocer - the effect compounds. From the perspective of the chicken farmer, who may service several grocery stores, he could get orders for chickens ranging in size from 1200 in a week to 1400 in a week. Again, the cost of slightly overestimating is far less than the cost of slightly underestimating (reputation, lost profits, scalability, etc.), so he aims to produce 1400 chickens, perhaps 1500 for good measure.
We now have a situation where the individual purchase is removed from its cumulative effect by several degrees of imprecision. If you abstain from buying chickens this week, the most likely outcome is that the grocer still rounds up, the farmer still overestimates, and the same number of chickens meet the axe.
Importantly, the expected outcome of buying a chicken, on average, is still approximately "1 chicken dies'', but its effect is ambiguated by what is now a lottery system. Rather than causing a chicken to die every time you buy a chicken, you have something like a 1 in 200 chance of counterfactually causing the deaths of 200 chickens every time you buy a chicken.
This is a simplified illustration of the high-variance processes connecting your purchase to its harmful effect. In reality, this 200 figure is conservative. For most economies, there are more middlemen in the picture than this simplified example describes. Each stage enlarges variance and increases the size of the thresholds. These include:
- Distribution centres
- Wholesalers
- Processors
- Integrators
- Hatcheries
- Breeder farms
- Grandparent/great-grandparent breeders
The mechanisms connecting your purchase of a chicken to the death of a chicken are significantly less direct than killing a chicken yourself by virtue of probabilistic lottery-style impact rather than certain per-purchase outcomes, and numerous imperfectly efficient agentic intermediaries.
The “hitman” objection
A common objection to the premise that indirectness ameliorates immorality, is the reductio of hiring a hitman.
“If it’s true that indirect harmful actions are less immoral than more direct actions, this means that hiring a hitman would be better than killing someone directly. Further still, you can hire a man, to hire another man, to hire a hitman, and so on, washing your hands of the crime with each stage. This is an unacceptable conclusion and reduces the position to absurdity”
This fails to reduce the position to absurdity. Paying a hitman is slightly less bad, because it is slightly less direct. The degree of indirectness remains relevant. The mechanism is clear, and there are not many intermediaries.
Either the case being posited is a realistic hitman (or hitman hirer) with imperfect efficiency, or a hypothetical ideal hitman (or hitman hirer) with perfect efficiency.
The “realistic” middleman case: If the reductio posits realistic conditions for the hiring process, and realistic reliability of the intermediaries, then it fails to show the action is equally immoral. Each stage of the “hiring” chain involves leakage - there is an increased chance they fail to complete their task, get caught, or renege on the deal at every stage. Therefore, with each intermediary, the expected outcome gets less bad. At 0 intermediaries, the murder is near certain. With many intermediaries, the outcome is far from certain. Therefore, the expected harm occasioned by initiating this lengthy chain sequence of hitman hirers is predictably much less, and the action is therefore less immoral.
The “perfect” middleman case: If the reductio posits that there is no drop-off from intermediary to intermediary, then this raises the question of what constitutes an intermediary versus the same mechanism. The “perfect” middleman must have no counterfactual agency, and be deterministically tied to the subsequent events with complete in-advance certainty. This is disanalogous to the case it attempts to refute. In the case of buying meat, there is counterfactual agency, significant variance, and there is not complete in-advance certainty of the outcome. The outcome of an indirectly harmful act, though equal in expectation, is ambiguated by numerous rolls of the dice, whereas the perfect hitman eliminates this salient factor. It is hard to argue that these middlemen are actually separate causal entities at all. In the same way, one can argue that a person shooting someone is employing many intermediary mechanisms - millions of neurons must fire in sequence, each a “middleman”, their muscles must pull on their tendons, which pull on bones, which pull on the finger-facing molecules of the trigger, which kinetically influence the adjacent molecules, and so on. The principle that distinguishes a middleman from a single causal mechanism in this context is ambiguity and variance. If there is no, or negligible ambiguity or variance in the outcome, then it is not a valid analogy for indirectness.
Time lag
A component of indirectness is time lag. That which has an immediate effect is more direct than that which doesn’t.
In the case where an intentional harmful act causes harm later rather than immediately, it is less immoral than the reverse, as long as the harm eventually occasioned is equal in expectation.
Buying a chicken to eat involves a substantial time lag from the moment of purchase to a counterfactual chicken being killed. Therefore, buying a chicken is less immoral than killing a chicken.
Intention
I argue intention affects how moral an action is, independently of its expected outcome.
An action that is done with the intention of bringing about a harmful result, is worse than an action that is not done with the intention of bringing about a harmful result, all else equal.
For example, extending the vehicle analogy:
A woman driving a car intends to get to work, and accepts the incidental expected harm of pollution, collision risk, and roadkill as an unfortunate, unavoidable compromise. However, a man who drives in exactly the same way, but for whom getting to work is just a bonus, and whose primary goal is to legally kill animals that happen to wander into his car’s path, is acting more immorally than the first person.
This is true even if the expected outcome is exactly the same. In some cases, it is even enough to offset substantially greater expected harm.
For instance, a woman who drives in a heavily forested area with many creatures wandering across the roads is expected to run over far more squirrels and frogs and snakes on her way to work than a man who lives in a desert. But, the man in the desert, who prays for small animals to wander across the road during his daily commute so he can relish their deaths, is acting more immorally than the woman, who intends merely to get to work, and regards the vertebrates she kills as an unfortunate, unavoidable externality.
Rejecting the principle, taking the position that intention makes no difference, and that the moral calculus is purely consequential, entails that there is no difference in morality between someone driving so they can get to work, and someone driving so they can see the blood of innocent creatures decorate their car, as long as they drive in the same way.
“Name the trait”-style reductios are disanalogous by virtue of mitigators
Either mitigators such as directness and intention decrease one’s obligation to sacrifice, or they don’t.
If they don’t: Then all actions with equal expected consequences are treated as morally equivalent. In this case, the “name the trait” challenge collapses under the same argumentation.
Recalling the vehicle analogy:
A typical American driver will kill (crush) ~75 vertebrates in their lifetime. Under the view mitigators such as directness are irrelevant, this is morally equivalent to personally crushing 75 vertebrates underfoot.
To hold consistently to the framing of “name the trait”-style reductios, a vegan driver must name the trait true of animals that, if true of humans, would justify crushing them underfoot in order to drive.
Clearly, no trait true of animals applied to humans would permit crushing a human underfoot for the sake of being able to drive. Therefore, either driving is morally unacceptable, or the position that mitigators do not decrease one’s obligation is reduced to absurdity.
If they do: Then “name the trait that permits you to kill an animal” is disanalogous to the case of purchasing meat. Purchasing meat is less direct, less intentional, involves high variance, many causal intermediaries, and substantial time lag before counterfactual harm occurs. These are the same mitigators that differentiate driving a car from crushing vertebrates underfoot. The extent and significance of these mitigators is subjective and arguable for both cases. I would argue the driving case actually has fewer and less extensive mitigators than purchasing meat - you are not ever likely to be in the same room as a slaughtered animal, but you are virtually guaranteed to personally crush a squirrel or a frog, for instance.
This issue is not resolved by constraining the challenge to consumption, i.e., "Name the trait true of animals that, if true of humans, would justify buying their meat.". The constrained form has the same logical structure as the original, and the same structure can be turned on driving: "name the trait true of small vertebrates that, if true of humans, would justify driving in a manner that near-certainly crushes 75 of them in a lifetime." No such trait exists in either case. So the constrained challenge condemns driving exactly as the unconstrained one does. Since vegans generally regard abandoning driving as beyond one’s obligations, they must concede that the absence of a distinguishing trait is not sufficient to establish impermissibility. Constraining NTT to consumption therefore fails to establish that buying meat is unacceptable.
Humans are Worthy of Greater Moral Consideration than AnimalsIf one assigns moral value on the basis of capacity for suffering, pleasure, intelligence, meaning, social exchange, or anything else humans generally value, humans as a group outperform animals on these metrics. The degree of value difference will vary depending on the weights you assign to each of these traits, but the direction of the net difference is obvious. Almost all vegans will readily concede that humans are more valuable, in general, than animals.
Without some hierarchy of value anchored on morality-relevant traits, instead viewing moral relevance as binary contingent on meeting a threshold of traits, absurd conclusions result.
Imagine, for instance, a choice between certainly killing an ant that has the minimum level of moral traits needed to satisfy the threshold, or a 99% chance of killing a creature that possesses morally relevant traits to a vastly greater degree than humans. A threshold view entails that no matter how intensely this creature feels suffering, how richly it experiences positive emotions, or how intelligent it is, near-certainly killing it to save a threshold-clearing ant is the optimal moral choice - an evidently absurd conclusion.
Therefore, all else equal, harm occasioned to animals is less immoral than harm occasioned to humans.
Dietary Veganism is a Significant Sacrifice that Varies Between IndividualsDietary veganism requires most people to give up or markedly diminish valued aspects of their lives for the sake of reducing expected harm to animals. It thus involves a sacrifice.
Vegans commonly argue the extent of the sacrifice involved is minor. However, I argue the sacrifice involved for most non-vegans is significant, and varies substantially between individuals.
Taste/pleasureFor most non-vegans, a major factor motivating their consumption of animal products is that a diet including these products is tastier and more enjoyable than a diet without. The stated and revealed preferences of the vast majority of humans clearly indicate that eating animal products makes their lives more enjoyable. Therefore, to abstain from eating animal products involves sacrificing a degree of the all-things-considered enjoyableness of one’s life.
The scale of this sacrifice varies. For some, animal products are disgusting, and thus it involves essentially no sacrifice to abstain from eating them. For others, animal products are a source of immense satisfaction, and plant-based staples are disgusting. The latter group must make a markedly greater sacrifice to the overall enjoyment of their lives in order to be dietary vegans.
For the typical non-vegan, the taste/pleasure sacrifice is considerable. Taste consistently ranks as a primary reason people give for not reducing meat consumption. Additionally, the most common reason for relapse from vegan diets is food dissatisfaction. So, even among people actively motivated to abstain from meat, taste is often a prohibitive sacrifice by revealed preference.
Available evidence on stated and revealed preferences points strongly to the taste value of animal products being a significant factor in most people’s lives, and should therefore be regarded as a considerable sacrifice by default.
NutritionBecause a vegan diet is a subset of an omnivorous diet, it necessarily narrows the range of available foods.
I do not argue that animal products are essential for a healthy, long life. However, the sacrifice involved comes in the form of greater difficulty, and a considerably narrower range of ways to meet nutritional needs.
Additionally, without careful dietary planning and/or supplementation, there is an elevated risk of essential nutrient deficiencies like B12 and iron. Factors like protein quantity and source variety become a greater consideration as well due to the diminished bioavailability and variable amino acid profile of plant proteins.
Thus, there is an unavoidable tradeoff between risk of dietary mismanagement and time investment (research, meal planning) to ensure nutritional sufficiency.
Convenience/timeAnother sacrifice associated with veganism is that it is inconvenient. Despite the trivial connotations of the word “convenient”, convenience is a strongly valued aspect of most people’s lives, and a legitimate object of concern.
Some (non-exhaustive) ways veganism results in lost time or convenience include:
- Adjusting to the lifestyle
- Auditing existing habits and ongoing purchases
- Greater logistical need to prepare meals where vegan options may not be available
- Research on nutrition and supplements
- Limitations or friction introduced in social settings
- Moving location to areas with greater availability of vegan staple ingredients (such as for those living in food deserts)
It is worth noting this aspect of sacrifice is a catch-all category which trades off against the other sacrifices. To achieve a level of enjoyment closer to that of an omnivorous diet, one must spend a greater amount of time and effort learning and practicing how to make tasty vegan food. To achieve more complete nutrition and a lower risk of deficiencies, one must spend more time and effort learning and organising their diet.
SocialSocial difficulties are among the most common reasons for vegan diet lapses, and a major barrier to veganism for many people.
Vegans are disliked by the general population, and face widespread discrimination. A prospective vegan must not only accept restrictions on their nutritional options, meal enjoyment, and convenience, but also risk being ostracised or mocked in social settings. This is particularly the case in settings involving communal eating.
Communal eating is a near-universally cherished aspect of human experience. It is valued to such an extent that sharing meals with friends and family predicts happiness and wellbeing comparably to income. Even marginal encroachments on this aspect of life therefore merit serious consideration.
On balance, veganism has a clearly negative expected effect on one’s social life.
_
The nature and extent of the sacrifice veganism requires varies, however, by revealed preference, the vast majority of people do regard it as a sacrifice (since it is worse than their preferred default). For people with strong social ties to omnivores and anti-vegans, high taste affinity for animal products, limited nutritional knowledge, or strong preferences for convenience and variety, the sacrifice is substantial.
Veganism Either Entails Extreme Conclusions or Permits Eating MeatThe most commonly cited definition of veganism, from The Vegan Society, is as follows:
"Veganism is a philosophy and way of living which seeks to exclude—as far as is possible and practicable—all forms of exploitation of, and cruelty to, animals for food, clothing or any other purpose; and by extension, promotes the development and use of animal-free alternatives for the benefit of animals, humans and the environment. In dietary terms it denotes the practice of dispensing with all products derived wholly or partly from animals."
First, the terms “exploitation and cruelty” decompose to harm. Roughly, “exploitation” means “harm in order to benefit”, and “cruelty” means “harm for its own sake”. These two terms are thus functionally inclusive of all forms of foreseeable harm, and will be treated as an equivalent concept.
The contentious aspect of this definition comes from the qualifier: “possible and practicable”. Since practicable is a subset of “possible” (all practicable things are possible), practicable is the only relevant component to address.
The term practicable maps directly to the sacrifice framing established in this essay: That which is practicable involves a level of sacrifice that is below a certain acceptable threshold. That which is impracticable exceeds this threshold.
For example: a person living in a food desert for whom dietary veganism would result in an unhealthily restrictive diet. It is a contentious topic among vegans whether such a person would have an obligation to go vegan at all, or if the financial and logistical challenge of moving to a more abundant area (or tolerating malnutrition) is too great a sacrifice.
This “practicability” framing produces two possibilities: Either "practicable" is a threshold that constrains obligation, or it isn't. I will first briefly address positions absent a practicability constraint, before discussing the dominant practicability-constrained view.
Possibility 1: Practicability does not constrain one’s obligation to abstain from harmful practices. This commits vegans to unbounded, extreme levels of abstention.
The spectrum of potential acts of abstinence is continuous, and has no principled stopping point.
Consider these escalating possible acts of harm-reducing abstention:
- Buying meat from a store that sells only meat
- Buying meat from a general store
- Buying less meat from a general store
- Buying vegetables from a general store that also sells meat
- Buying vegetables from a vegan store
- Buying vegetables from a vegan store with verifiably all-vegan employees
- Growing your own vegetables from inexpensive seeds bought from vegan stores with all-vegan employees…
At the first stage, financially and socially supporting stores that sell only meat is a stronger per-dollar causal contribution to animal harm than buying equivalent products from general grocers. Thus, it’s possible to reduce harm by abstaining and seeking alternatives.
Buying vegetables from general grocery stores does little, but not nothing, to facilitate the meat industry - the grocery store does not compartmentalise revenue with perfect efficiency, and in expectation, your contributions will fund the meat-producing functions of the store to an extent.
Further, buying from a vegan store (that has some omnivore employees) is less harmful, but still contributes to the animal industry via the wages paid to employees who will buy meat.
Continuing with possible sacrifices, you can further reduce harm by growing your own vegetables, ensuring the seeds are sourced from vegan stores with vegan employees. Even in this case, there is nonzero monetary leakage into the meat industry - it is impossible to entirely isolate your purchase from downstream contributions to the broader economy.
The progression does not stop there. With no threshold of sacrifice or “practicability”, this commits you to abstaining from the economy entirely, choosing instead to grow your vegetables from seeds that you have found through foraging, with fertiliser you have made yourself.
No mechanism under this view constrains your obligation to make further concessions beyond that which is “possible”.
Ultimately, this position seems to entail suicide by starvation, the maximum possible degree of abstention.
If one argues that a person would be obligated to eat to such an extent that it causes a net-benefit relative to merely abstaining from food[1], such as by being an advocate, this concedes there is no act/omission distinction relevant to one’s obligations - one must act to eat, one must act to advocate, one must act to afford the seeds. Therefore, such a position produces unbounded act-based consequentialist obligations, like sneaking into as many factory farms as you can to free animals. All the while, ruthlessly optimising your calorie intake so as to never scrape above the threshold of absolute necessity.
The demandingness of this view makes it an untenable position, and entails that the vast majority of vegans fall short of their obligations. Because of this, a practicability constraint is the majority view among vegans.
Possibility 2: Practicability does constrain one’s obligation to abstain from harmful practices.
This licenses the view that abstaining from animal products is supererogatory, and that omnivores are eligible as vegans.
A typical omnivore already abstains from practices that are harmful which don’t involve inordinate sacrifice - i.e. to a practicable extent. The popularity of “free range” eggs demonstrates omnivores are often willing to sacrifice money for the purpose of reducing their causal contribution to animal suffering, for instance. An omnivore may abstain from eating live octopus, despite otherwise finding it an amusing cultural experience - another practicable sacrifice.
Given this, the obligations produced by this position hinge entirely on what is “practicable”.
As previously argued, there is no principled, objective distinction between “need” and “want”, thus, this cannot serve as a valid definitional basis for practicability.
What remains is a sacrifice threshold view: that there is a continuous spectrum of “wants” that can be sacrificed to greater or lesser degrees, and there is a threshold beyond which further sacrifices are supererogatory.
Importantly, whether a given abstention is obligatory (practicable) varies even with identical sacrifice willingness. One can be willing to sustain a level of subjective suffering that is exactly the same as that of a dietary vegan, and yet remain an omnivore, because sacrifice is contingent upon variable subjective affinities and aversions for the tradeoffs involved.
Consider the following hypothetical case:
Lisa and William both fully accept they should reduce their contribution to animal suffering to the greatest extent practicable - they are both willing to make sacrifices of abstention to the point of moderate discomfort and inconvenience, but not beyond. William is in a great position to do so: his family and friends are vegan and he never much cared for the taste of meat, eggs or dairy. Lisa, however, lives in the heart of Texas - barbecue is a cherished part of her culture, she loves the taste of meat, can hardly stomach most plants, and her friends and family are ardent conservatives who openly express contempt for vegans and vegetarians. For William, eating entirely plant foods falls well below the threshold of practicability, barely registering as a sacrifice at all. For Lisa, even moderate reductions in her animal product consumption risks great discomfort, distressing identity dissonance, and being ostracised by her loved ones.
In this case, if they both abstain from eating animal products altogether, Lisa is making a vastly greater sacrifice that exceeds practicability, whereas William is making virtually no sacrifice, and would be obligated to abstain further in order to reach the point of moderate inconvenience and/or discomfort - otherwise, he isn’t abstaining “as far as is practicable”. For them to make the same sacrifice, Lisa will either give up trivial amounts of meat to match William's negligible discomfort, or William will need to make major additional sacrifices to match the distress Lisa faces by giving up meat entirely. It is not possible for Lisa and William to have the same level of sacrifice-mediated practicability, while also adopting the same lifestyle.
Without a categorical distinction between “need” and “want”, there is no principled argument that Lisa is obligated to abstain from eating meat that is not also an argument for William to abstain from other things such as electricity, driving, and general economic activity to the point of intense discomfort. As established, no such categorical distinction exists.
Therefore, positions on this threshold either skew towards permitting many omnivores, or entailing untenable obligations. There is no threshold at which practicability unambiguously prohibits eating meat for Lisa that does not also entail extreme compromises for William.
The reasonable threshold of practicability is modest
There are many strong reasons to believe the threshold of obligation is relatively low for abstaining from animal products, both in principle and by precedent.
In principle:
- Mitigators
Given the abundance and extent of mitigators distinguishing eating meat from the expected harm eating meat entails, the obligation to abstain from the practice is considerably reduced. Consuming animal products involves many layers of indirect mechanisms with high variance, many agentic intermediaries, significant and variable time lag, and views harm as an unfortunate consequence rather than a desired result.
These mitigators are powerful, not trivial. Driving a car ad libitum for 8 months is vastly less immoral than crushing a squirrel underfoot, despite equal expected harm and fewer, less extensive mitigators than buying meat.
Given the level of immorality is an input that distinguishes an obligatory sacrifice from a merely virtuous one, a greatly reduced level of immorality entails a greatly reduced degree of obligatory sacrifice.
- Moral consideration
Given humans at minimum match, and near-universally exceed animals on commonly weighted factors such as lifespan, capacity for social connection, and intelligence, actions that harm groups of animals and insects are significantly more likely to be permissible given equal harm.
The group-level difference in moral consideration is significant. This is hard to quantify, however even in the strongest case where a cow is otherwise trait equalised with a human, their natural lifespan is roughly 5X shorter, for instance. Factoring in other trait differences such as social and intellectual capacity points to a very significant overall difference in moral consideration.
Most vegans acknowledge humans are, on the whole, worthy of substantially greater moral consideration than nonhuman animals.
Since consuming animal products primarily harms animals as opposed to humans, the action is less immoral than for the human equivalent.
Given lesser immorality entails lesser obligations, the threshold of practicability therefore must concomitantly decrease.
By Precedent:
- Housing
Residential buildings contribute to a surprisingly large number of bird deaths. Birds mistake windows for open passages, crash into them, and die. An estimated one billion birds are killed by colliding with buildings every year in the United States alone, the majority of which are small residential buildings. Some estimates are as high as several billion. On average, using conservative figures, roughly 3 birds are killed per house per year this way.
However, residences in bird migration hotspots frequently kill 10-20 per year once factors like scavenging are accounted for. A person who lives in a house in a high-bird-traffic area is therefore contributing to approximately 500-1000 bird deaths over a lifetime by virtue of merely living in a dwelling with windows[2].
Further still, having a 2-storey tree in the yard of a property increases the rate of bird collisions by 3.6X. A person in a high bird traffic area who does not give up their tree in the front yard is accepting several additional bird deaths (and many injurious nonfatal collisions) per year.
It is not typically considered practicable to avoid buying or renting properties that have large windows, or trees close by. Nor is moving to a low bird traffic area to minimise one’s economic contribution to bird deaths considered practicable despite a death toll that, in many regions, potentially exceeds the impact of a moderate meat eater.
Many (possibly most) omnivores would prefer to move to a low-bird-density area than to give up animal products, implying the sacrifice involved is comparable.
Given this precedent, where the feasible, yet inconvenient burden of limiting residential options is not considered practicable, it seems likely that the standard of practicability is fairly low to an extent that permits animal product consumption for many people.
The vegan position that accepts a practicability limiter is thus constrained to two views:
- The standard of practicability extends to limiting one’s residential options to treeless, low-bird-traffic dwellings, including cases where someone lives in a hotspot; or
- The standard of practicability falls short of limiting one’s residential options to treeless, low-bird-traffic dwellings.
If 1: This is highly demanding and entails that the vast majority of vegans fall short of their obligations.
If 2: Then the threshold of practicability with respect to a lifestyle that kills 500-1000 birds falls short of relocation. Therefore, a meat eater who would eat 500-1000 (animals comparable to) birds in their lifetime, who would rather limit their residential options than give up animal products, would be making a greater sacrifice in doing so than the practicability threshold demands. Therefore, this view permits eating meat to an extent equivalent to hundreds of bird deaths.
- Electricity
Using electricity is widely considered to be permissible, including by vegans. This is despite the fact that all major methods of electricity generation are environmentally deleterious, and in most cases result in direct animal deaths. For instance, power lines alone in the United States kill approximately 30 million birds per year via collisions and electrocution - implying an individual electricity user counterfactually causes approximately 5-15 bird deaths in their lifetime. Ad libitum electricity usage is common among vegans, and abstaining from, or drastically reducing one’s electricity consumption is not typically considered practicable or obligatory.
- Driving
As discussed, driving carries a lifetime burden of ~75 vertebrate deaths as a conservative estimate. Abstaining from driving is typically considered impracticable, despite it being technically feasible in most cases to use alternate means of transportation. A person who commutes 20 minutes by car to work can typically bike to work and accept a more challenging hour-long commute. However, the inconvenience this involves ostensibly crosses the threshold of impracticability, despite it providing a near total reduction in roadkill.
- Vegan advocacy itself implies low thresholds
Vegan advocates themselves near-universally claim that abstaining from animal products is easy. In doing so, this admits they are not typically making a significant sacrifice by eliminating animal products. If that is the case, and no further (difficult) sacrifices are obligatory, this further indicates the threshold of obligation to sacrifice is modest. Therefore, it is far more likely that interpersonal subjective variation on issues like taste will distinguish whether a given act of abstention is practicable. To obligate omnivores for whom it is difficult to switch, “don’t worry, all you need to do is make easy sacrifices”, does not suffice.
Abstaining from animal products is a practice that reduces harm, and therefore doing so is a virtuous practice. However, a practice being harm-reducing is not sufficient to justify it as an obligation - this neglects the crucial factors of the sacrifice required to perform that harm-reducing action, and mitigators that may diminish the immorality of the action.
The sacrifice involved in abstaining from a given practice is subjective, and a major determinant of whether abstention is obligatory. The greater the personal sacrifice required to forgo something, the lesser one’s obligation to forgo it. In the case of consuming animal products, the harm a typical omnivore faces by abstaining is significant: enjoyment, nutritional sufficiency/ease, and convenience/time accumulate to a considerable sacrifice, affecting its obligatory status.
Mitigators - factors that ameliorate the immorality of an action orthogonally to harm, drastically affect obligations in many areas of life. Cars, electricity, housing and economic participation all result in considerable harm, yet are considered permissible by virtue of their indirectness, lack of intentionality, or delayed, distributed effect. The act of consuming animal products is ameliorated by these mitigators as well.
Animals, though moral patients, are worthy of less moral consideration in general than humans because they possess morally relevant traits to lesser extents. Given this, harming animals is less immoral than harming humans. Given the aforementioned sacrifice/immorality model of obligation, this lesser immorality further shifts the designation of dietary veganism towards being supererogatory rather than morally required.
Vegans typically acknowledge a threshold of obligation themselves that is functionally identical to the framing of sacrifice vs immorality by their call to: “[abstain from animal products] as far as is practicable”. Without a practicability constraint, the view that one should abstain from practices harmful to animals entails unbounded, extreme abstention. With a practicability constraint, the threshold of practicability is either low enough to permit omnivorous diets, or it is high enough to demand unrealistic lifestyle compromises.
There are compelling reasons to believe “practicable” abstention from animal products is a low threshold rather than an extreme one. In principle, there are many mitigators present which decrease its immorality relative to harm, as well as its harm being concentrated among animals, which are of lesser moral consideration. By precedent, economic participation, driving, electricity usage, and residential windows all cause animal deaths, yet are “impracticable” to abstain from. Vegans themselves widely claim that the practice of dietary veganism is easy - further suggesting the standard of “practicable” is not very demanding.
Given many principled and precedent-based reasons to view a “practicable” sacrifice as one that is relatively easy and painless, and the strong reasons to believe abstaining from animal products is, for most omnivores, far from easy and painless, the standard vegan position that one ought to abstain from animal products to the greatest extent practicable, permits most omnivores to continue eating omnivorous diets while definitionally and morally qualifying as vegans.
Therefore, veganism - as in abstaining from consuming animal products such as meat, eggs, and dairy - is virtuous, but not obligatory.
Definitions:
Moral patient: An entity worthy of moral consideration
Harm: (a thing) Producing a result that is dispreferred by moral patients
Benefit: (a thing) Producing a result that is preferred by moral patients
Morality (moral/immoral): The goodness or badness of an action, which is a function of the action’s harm and/or benefit, and mitigators/intensifiers, weighted by the moral consideration of the affected entities.
Mitigator: A thing that decreases the moral weight of an action independently of its harm or benefit.
Intensifier: A thing that increases the moral weight of an action independently of its harm or benefit.
Obligation: A thing that one must (or must not) do.
Permissible: Lacking an obligation to abstain (from something).
Sacrifice: A voluntary self-imposed harm accepted for the purpose of benefiting other moral patients
- ^
“permitted” is insufficient - this acknowledges a practicability constraint
- ^
Bird-deterring window films do not solve this problem particularly well. Independent studies suggest roughly a 40-70% reduction in collisions, and only if the window film is applied on the outside, which requires more frequent reinstallation and is a much more difficult (expensive) process to complete. Full external installation of window film for a medium-sized house costs in the thousands of dollars, and needs to be replaced every 5-10 years. Most vegans do not do this, and do not consider it an obligatory sacrifice.
Discuss
Low Expectancy is Not a Confidence Problem
Lukeprog's How to Beat Procrastination includes in its framework a term for expectancy or how likely/accomplishable a successful outcome feels internally. One of the levers to combat procrastination is thus to increase the perceived odds of getting a reward. I think this misattributes low expectancy to poorly calibrated self-confidence, when really it boils down to your own actual capabilities and the problem structure.
In many cases, the root cause for low expectancy is that you personally do not have experience, knowledge, or resources. Expectancy should be low rationally. While the original post does prescribe learning/process goals, this is framed as a means to the end of increasing self-confidence. In practice, this framing can lead you to focus on goals that increase confidence without tackling underlying understanding/competence. Competence can lead to confidence, but false confidence (which is fairly easy to manufacture via the methods in the original post) can lead to disaster. An unfortunate side effect: If you're optimizing for self-confidence, when reality hits back, you will start to distrust self-confidence as a signal, leaving you in an even worse place than where you started. (I actually think this is the main cause of chronically miscalibrated low self-confidence.)
Another common case that brings low expectancy: a task has long feedback loops and credit assignment is difficult. Even if you have the fundamental skills, there's no way of knowing if your actions are moving the needle. Setting intermediate process goals here can help sustain effort in one direction, but it cannot change the nature of the problem: it takes time to know if the intermediate process goals you choose are actually moving you towards your terminal goals effectively, especially in a new/unstructured domain. Society's answer here is to create concrete, well-trodden paths with visible rewards (structure the domain) or to work closely and learn from someone who has similar experience. This works great when it works (though it also relies on you to generally understand your direction/terminal goals).
However, the above solution is founded on an implicit trust that the promises will be fulfilled, and the environment and institutions will remain similar enough by the time you complete the intermediate goal. For rationalists who put some credence in short AI timelines (and anyone else in an unstable environment), this assumption is tenuous. Even if you distance yourself from the problem or try to reframe it (e.g., by coming up with plans that work on shorter horizons, or framing your work as a bet on a specific world, or by trying to create robust plans that work across many worlds), that doesn't eliminate the underlying reality that things are going to change, rapidly and unpredictably. The only answer I can think of here is to make peace with that fact. After you acknolwedge it and factor it in, continuing to dwell on it provides no new information, and will just cause paralysis.
Discuss
Basic principles for dressing better.
I've been a toe-in rat and existed on the outskirts of the social scene for approaching a decade now, and I can confidently say (with love) that rationalist men rarely dress well.
I am drowning in a sea of reasonably-attractive men diminishing themselves in skinny jeans and free t-shirts from random events three years ago.
But you can do better. I believe in you. Honestly, it isn't even that hard.
In this post, I'll be teaching you two things:
- The basic theory behind how to actually assemble an outfit that will instantly make you look more interesting, attractive, and put-together.
- And how to find the clothes you'll need to buy to accomplish #1. I'll even give you a list of links to make things easy for you.
(while this post will be geared toward men, anyone could read this and get something out of it I think)
Outfit Assembly 101I come from an art background. Assembling a good outfit is, in my opinion, a bit like trying to create a painting. You want the overall composition to feel balanced while still being interesting and nice to look at.
The biggest things I think rationalist men neglect to consider in their outfits (to the extent they give any of this any consideration at all) are color, visual weight, and detail.
Let's look at some examples of things I'd consider Pretty Good Outfits™:
In an effort to instill in you more of the elusive thing called taste, let's talk about why I think these outfits work.
- They aren't afraid to wear color and pattern -- while none of the outfits shown here are super crazy, they also aren't particularly plain. Check out #6's scarf and handbag, or the rich baby blue and maroon cardigan on the man to his right (#7).
- There's a nice balance of visual weight -- meaning something bright and colorful and patterned (like the yellow shirt on #3, or the quilted jacket on #9, btw these are often called statement pieces) are paired with more understated items/solid colors to balance them out. Your outfits don't need to be insanely maximalist to still be interesting. Many men working corporate jobs with strict dress codes have a culture of purchasing statement dress socks, for example.
- A decision making process I'd recommend following as a beginner here would be to limit yourself to one statement piece per outfit, and then have everything else be solid, neutral colors. Think interesting shirt + jeans, or cool trousers + plain white sweater, for example.
- And small details bring it all together -- notice how #1's bag, belt, and shoes are all the same general shade of leather. Do you see how that gives the outfit an air of intentionality, of put-togetherness? Even the very casual outfit on #10 has some of this, look at how his bandana is blue like his jeans, his white t-shirt matches his sneakers, and even his belt is dark like his corduroy jacket. Your outfits don't need to be monochromatic, but think about ways you can have an accent color appear in more than one place.
(If, like some of my male housemates you object on principle to the concept of a bag, you could color-match a part of your outfit to something like a watch strap, belt, or shoes)
The last high-level bit of analysis I want to point out here is how, despite all of the variety in terms of color, texture, and pattern, the basic formula behind these outfits is fairly simple.
We start with a pair of well-fitting pants (bonus points if they have a slightly wider leg, slim-fit jeans aren't actually that flattering IMO) and then add either a blank t-shirt, tank top, or button-up shirt.
Add some shoes and accessories to that and you can call it a day then and there. Or, you could take it up another notch and layer something like a blazer, jacket, or cardigan.
None of these outfits are particularly brain-breaking. They're very straightforward.
Your shopping list so far is pretty simple:- Trousers
- Button up shirt
- Something to layer on top
- Solid-color t-shirts (no prints or logos)
- And a few miscellaneous accessories
For #1-3, get two versions: one plain, one statement piece.
If you follow the advice thus far, you'll absolutely look more attractive and put together. Your outfits will feel more intentional and curated when you add a little bit of color, pay attention to details, and consider visual weight.
But the immediate failure mode I expect many of you to fall into is that you buy those items off of Amazon like you're checking things off of a grocery list.
Part of what makes the above outfits interesting is that the clothes themselves are interesting. They have drape, texture, structure, interesting details. They're nice to look at.
The way to look hotter and more interesting is both to purchase higher quality clothes that fit you well (and to get things tailored, if you can) and to have those clothes say something about who you are.
Fashion is an opportunity to express yourself.
You were sorta on the right track with this when you started wearing all of those t-shirts with xkcd comics on the back, except the signal value is about as worthless as a college degree now, because everyone else wears them too.
So think about other statements you can make or personality traits you can express. Even colors you might like to wear more!
I digress. Let's get into my list of stores to shop from.
My Favorite Menswear Stores, And How To Find Your OwnAll of the clothes pictured above are real items you can purchase from the stores in this list. I could tell you where each of them are from, but I think your life will be better if you do some digging through the online stores on this list yourself.
(Also, fair warning, many of these are a bit pricey, like $150 for a shirt kind of pricey)
For the basics:
- J. Crew -- If you need an entirely new wardrobe, go here first.
- Bonobos -- Very similar to J.Crew. Nothing innovative here, but solid.
- Wax London -- This is J.Crew and Bonobos's cooler younger brother.
- Todd Snyder -- Very much in the same category as the previous three. Good, not super interesting IMO, but hey! Not everything needs to be a statement piece.
- 7Diamonds -- If you tend to be a little sweaty/run hot, the synthetic short-sleeve shirts they carry will do wonders for your temperature regulation. Just don't buy the pants from here, the crotch seams will tear after a few months.
- Industry of All Nations -- Lots of basics in a million colors with very straightforward product photos and good material quality.
For statement pieces and more interesting basic options:
- Perte D'Ego -- If the things you really want are super interesting shirts that will get you endless compliments, go here. They take ages to ship, but the quality is great.
- Arran Studios -- This is a small independent brand still gaining traction, but if you're more into an understated workwear/modern wild-west look, they're great.
- Cord Studio -- I think this brand carries some of the most interesting and well-crafted linen button downs out there. Great details.
- Society of Cloth -- Features a variety of smaller designers. Lots of variation in price and very fun to browse.
- House of Errors -- God, House of Errors has some of the coolest clothes I've ever seen. So much attention to detail. They release new stuff on the regular and all of it is fun and innovative. Lots of unique knits and embroidery work that elevates an outfit.
- Found Co -- My favorite hoodie is from this brand. They do a lot of cool things with quilting and patches, and have a very nice earthy color palette.
- A Kind of Guise -- One of the pricier brands on this list, but their workwear and suiting looks really fun.
- Desigual -- Love the button-ups from here, lots of fun textures and patterns without being too loud. Lots of art history inspired stuff.
- OAS Company -- I LOVE the texture and prints from this brand.
** Note that for many of the brands on the second list, lots of what they release is in the form of small micro-collections, meaning you should really consider joining their email list, or you'll end up missing out on their best stuff. Purchasing from small independent fashion designers has pretty few drawbacks, but that's one of them.
But how did I find all of these interesting brands, you might ask?You're going to hate this part, but... I've found the vast majority of these brands on Instagram.
The thing about Instagram is that it's extremely happy to show you ads it thinks you'll click on. So why not just use this power for good?
If you follow the brands above, like a few of their posts, and only engage with ads that show you menswear (better yet, menswear you like) the algorithm will turn into your own de-facto personal shopper, plumbing the depths of the internet to serve you ads from other menswear brands just like them.
Hope this helps.
Discuss
Boltzmann brains, like Doomsday, require no explaining
Brothers and sisters I have none, but that man's father is my father's son. Who am I?
— ancient riddle
In Eliezer Yudkowsky’s post this week, he writes: “Our current experience -- your own experience, at this very moment, of seeing ordered letters on a screen -- therefore seems to provide overwhelming anthropic evidence against any model of reality or physics which would imply that most brains are Boltzmann brains.”
I hope it’s fair for me to roughly present this line of reasoning like so:
- If Boltzmann brains are possible
- And if Boltzmann brains would severely outnumber ordered brains
- And if each observe is a random draw among all observers
- Then finding ourselves to be non-Boltzmann brains should come to us as a huge surprise
- Meaning either one of the prior premises is false, or we need (in all likelihood) a theory of the universe that can compensate for this severely unlikely observation
I take the side that “one of the prior premises is false”. Can you guess which one?
What follows is a post about the Doomsday Argument, but everything I write equally applies to the idea that the possibility of Boltzmann brains presents a problem that theories of the universe must solve.
The Doomsday Argument has been debated among philosophers for decades. It seems to indicate that the number of future humans should be roughly equal to the number of past humans—though that obviously can't be true among all points in time. I believe most people reject the argument, but how they do so can widely vary. For instance, some folk believe in compensating theories that end up implying the opposite: that actually there can never be an ultimate Doomsday, because the number of humans (or at least, the number of conscious observers) is infinite.
To understand the argument works, let's start with a game. There's a deck of cards that can be any size N between 1 to 100, though you don’t actually get to see the deck. A random card will be chosen from the deck and shown to you. If the fifth card is drawn (which we can call K = 5), how large might you expect the deck to be, on average? If the seventy-fifth card is drawn (K = 75), does that make the chance of a maximum deck size (N = 100) higher than if the twenty-fifth had been drawn?
The answer to that second question is yes. Larger draws make larger deck sizes more likely, since they eliminate the possibility of smaller deck sizes.
Smaller draws do the opposite. Before any card is drawn, the chance of any deck size is 1%. After drawing the very first card, K = 1, the chance that you drew that card because you had to draw that card, because that was the only card available, increases. (Similarly, the chance that you drew it as a 50% shot between the choice of two cards also increases, though not as much.)
Doing the math will show that the chance of N = 1 jumps all the way up to 19%.
Observations give us probabilistic evidence towards the possible worlds in which those observations were more likely—e.g., smaller deck sizes for smaller card draws.
The Doomsday argument takes the same dynamic and applies it to the human population:
- There’s a 1/N chance of you being any particular person in history.
- Therefore the chance of being in the first K people is only K/N. Once you observe yourself to be the Kth person ever, then following a similar line of math as with the deck of cards, the most likely N becomes roughly 2*K.
- However, the human population has been growing exponentially rather than linearly. If our total population is likely to be in the range of 2*K, then that exponential growth means we’ll hit that bound soon.
The implication being: If there’s only so many humans left, then something will have to kill us all off. Maybe a black hole, or maybe a quantum bomb that destroys the whole universe. Every possible Doomsday scenario should be ascribed a higher probability than we would otherwise, without the Doomsday Argument.
Of the three steps outlined above, I believe that step 2 is solid. Please double-check the math yourself if you are so inclined!
Step 3 is fun because it makes the whole argument more dramatic, but it’s debatable and ultimately unnecessary. Whether humans would be expected to die very very soon, thanks to the extrapolation from exponential growth, or whether that end we’d be expected to last just a bit longer, as our population follows a sigmoidal curve, doesn’t change the fundamental prediction: Whatever K population we currently have, the Doomsday Argument will predict a grand total of 2*K humans to exist in all of space and time.
And honestly, 2*K doesn’t seem like an unreasonable prediction. Maybe there’s truth to the argument after all. Surely it won’t lead to any-
Let’s rewind the clock about 300,000 years—or maybe more accurately for this scenario, 6,000 years—and let’s forget about the theory of evolution or the genetic quagmire that would wreak havoc upon a population from intense inbreeding.
Adam and Eve.
In the Garden of Eden, the couple meet their fabled serpent. They learn of carnal temptation, partake in Biblical acquaintanceship, and then face God’s judgement. Unable to handle His Great and Terrifying Disappointment, Eve flees and begins her journey of pregnancy alone. Adam, on the other hand, is arrogant and unperturbed. He neither chases after Eve nor dissents against God. Instead he lounges at home, eating apples and chatting with his new scaley friend.
In captivity, a common garter snake can live up to twenty years. This serpent of Eden ends up surviving only another two months, when an eagle happens by and eats him. Adam tries to befriend the eagle, but of all the world’s animals, only the serpent had been imbued by the grace of God to speak proto-Semitic. As such, Adam is left alone with only his thoughts and his apples for the next one hundred years.
When Eve at last decides to return, she brings a giant family in tow. An overwhelmed Adam sits in shock as she tells her tale: How she traveled miles every day, subsisting mostly off rainwater, barely edible berries, and mildly poisonous mushrooms. How she befriended a wolf pack whose warm bodies helped her survive the harsh winter. How she birthed a miraculous octuplet of daughters, each of whom was forced to learn to hunt as soon as walk—but each of whom grew up happy, surrounded by lupine guardians and sisterly affection.
Eve describes next how each of her daughters and granddaughters likewise experienced parthenogeneses, God granting them a healthy amount of genetic variety (and the ability for humanity to jumpstart with only first-cousins level of incest). She describes the flourishing of her family, then has each of her fifty great-granddaughters and fifty great-grandsons introduce themselves to Adam.
Eve says: “I dream of a thriving humanity that will venture through all the jungles and deserts and oceans of this world, spreading our roots. You, Adam, will have been the first of thousands. Maybe even perhaps the first of billions.”
Adam, who’s grown visibly uncomfortable and increasingly shifty during all this, replies: “Hah! You really believe me to expect the evidence of my lying eyes? If it were true that I had fifty male descendants, then there would be a less than one-in-fifty chance of me being me, for I could have been born any one of them! Much more likely that all this is a ruse pulled by God the Deceiver and that I have no male descendants. You expect me to believe that there will be billions of humans? Then the chance of me having been the first human would be one in billions. In fact, think about this: God promises a future that will last billions of years, if not forever. What chance could I have had to be alive right now, during this mere century, rather than at any other point in the history of time? Essentially zero, unless I were in fact immortal. This is the most probabilistic explanation of my observations: These children are fake. You are fake. Everything in this universe are but figments of my imagination—me, the only thing that’s real, forever and always.”
But Adam, quite worked up and over a century old, goes into cardiac arrest at that exact moment and dies a minute later. Eve buries Adam in the Garden of Eden and marks his grave with a single upright stick, because neither gravestones nor crosses had yet been invented.
Adam tries to argue that certain things about the future must be true, based on an understanding of himself as being a random draw among events that haven’t happened yet, and which may or may not even happen.
In other words: Adam ends up forming beliefs about the size of humanity’s future population based on his belief about his place within the scope of humanity’s past and future population.
It’s circular logic.
Ouroboros by Luke Orrin
We can start building the right intuition that avoids this circularity by recognizing that Adam’s first rank isn’t any more remarkable than someone being the 42nd human to exist, or the 6,283,185,307th human. That distinguishes the Adam example from the deck sizes example, in which smaller card draws are remarkable for being more likely with smaller deck sizes, and larger card draws are remarkable for only being possible with larger deck sizes.
If God told Adam, “I created a billion different universes, each with a different human population across all time, from 1 to a billion. I then picked a random universe, and picked a random body throughout history inside that universe, went to my soul factory, then plopped your soul into that body,” then we’d have a situation analogous to the deck of cards: Adam should indeed predict smaller future populations.
Lacking such an explanation from God Himself, the Doomsday Argument falters. How exactly? Earlier, I presented the Doomsday Argument in three steps. The second step was unassailable and the third step irrelevant.
The first step was this: “(Given a total population of N) there’s a 1/N chance of you being any particular person in history”. Or rephrased:
- P(I am the Kth human | past-and-future population has size N) = 1 / N
This is an incorrect premise. (Which is why you don’t need the “SIA” or “SSA” or any other theory to fix anything.)
Except this leaves the question: If 1/N is wrong, then what’s the correct value? What was the chance of me being me, or you being you, or Adam having been first?
Realistically, I don’t think there’s anybody in history we can point to as the “first” human. Evolution would’ve made the boundary too fuzzy. How many individuals would’ve blurred the definitions between Homo heidelbergensis than Homo sapiens? In a broader sense, at what point were we more monkey than man?
But let’s say we drew an arbitrary line and defined the exact moment in time “humanity” began. Man #1 gets to be known as “Adam”, woman #1 gets to be known as “Eve”, and I hereby bequeath upon the 42nd man the name “Dams Ouglas”.
We want to know: What’s the chance that a given person has their rank K? Every K should have the same chance, because no position is more remarkable than any other, which means this question is equivalent to asking: What’s the chance that “Dams” was 42nd?
- P(“Dams” was 42nd | total population of N) = ?
The answer:
- P(“Dams” was 42nd | total population of N) = P(“Dams” was 42nd)
And:
- P(“Dams” was 42nd) = 1
This… might violate some intuitions.
It's natural to ask questions about the relative fortunes or misfortunes around the circumstances of one’s birth. Questions which will have answers with probability less than 1. For instance—to pull a completely random question out of my ass,[1] with no personal salience whatsoever—I might ask: “What's the chance, if I were a random American millennial, that I'd be diagnosed with colorectal cancer before 35?” (Less than 1 in 2,000.) Or: “What's the chance, if I were a random American millennial, that said cancer would metastasize by 40?” (Again, roughly 1 in 2,000.)
The conditional clauses are doing important work here. If I omit them and instead only ask, “What was the chance I’d be diagnosed with CRC by age 35?” the answer would be 1.
In the exact same way, the chance of Dams being 42nd was 1. That's because both “Dams” and “42nd person” are references that point to the same entity. The subject and object are just different names for the same person.
When we ask something like, “If God were to choose a random human from across all time, what's the chance he'd happen to choose Dams?”, then we end up with a different subject (a random selection of human) from object (Dams).
Because references (AKA “pointers”) are hard!
This is a well-known fact to any software developer who’s programmed in C, and also many riddlemasters and magicians. The riddle I presented at the beginning of this essay follows the format, “It seems like I’m referring to different individuals, but actually I’m referring to the same one,” as does Lewis Carroll’s classic problem involving the nominal ambiguity of familial relationships:
The Governor of Kgovjni plans on hosting a small dinner party and invites his father's brother-in-law, his brother's father-in-law, his father-in-law's brother, and his brother-in-law's father. How many guests will he have?
(The answer can be as small as one.)
In the same vein, “these two cards seem like they have no relation, but actually they’re the same card” is the basic format of about half the card tricks I’ve ever learned, as in this fun short video by VSauce.
It’s tempting to think that no matter what maniacal technologies we develop, we’ll never destroy the universe nor the planet: They’ve been around too long, and have surely seen worse than us. The worst we can do is destroy ourselves.
Is there merit to that idea, or might this be another argument built atop a faulty premise?
It’s certainly within the realm of plausibility, similar as it is to arguments like this:
- Trees have been around a very long time.
- In all that time, trees have never obliterated the planet.
- Trees tend to remain treelike. It takes a long time for trees to evolve into non-treelike things.
- Therefore, trees are unlikely to obliterate the planet any time soon.
I would hope that’s uncontroversial.
THE TREES WILL KILL US ALL. (Gorgeous piece by Sylvain Sarrailh)
The important difference between humans and trees is not that we’re more destructive, but that our behaviors are demonstrably changing on an incredibly rapid timescale. We existed for a few hundred thousand years before inventing T.N.T., but then it took us only 82 more years to invent the atomic bomb.
When combined with one other observation, I believe we can conclude that humans are extremely unlikely to instantly destroy the entire universe, all at once—but any lesser degree of destruction might well be within our grasp, including instant destruction of the planet, or a chain-reaction that will eventually but not immediately destroy everything else.
The other observation is that of the universe’s unimaginable vastness. Astronomers estimate that the Milky Way contains around 100 to 400 billion stars, and even more incredible, that the universe likely contains somewhere in the range of 200 billion to 2 trillion galaxies.
So no matter how rare the existence of life, gods only know how many trillions of Earthlike planets might be out there, and how many trillions of alien species might exist with human or superhuman intelligence. If none of them ever managed to deliberately or accidentally destroy the entirety of the universe in a single instant, I think it’s fair to judge that such an act is flatly impossible.
However, with space being so large and difficult to traverse that we’ve yet to actually meet or even observe any aliens, we’re blind to what fates might eventually befall the typical alien species. Maybe the universe is littered with the desiccated husks of once-thriving civilizations who venture too far with scientific experimentation; maybe every black hole is the scorch mark of a quantum bomb.
It was 1944 and Manhattan Project scientists needed to know how to safely test a nuclear detonation. J. Robert Oppenheimer argued that they needed a test whose scale would be “comparable with that contemplated for final use”. Brigadier General Groves was concerned—though not with safety. He just wanted to make sure they didn’t waste their expensive plutonium.
The Trinity test proceeded in secrecy in the Jornada del Muerto desert (literally “Journey of Death”), about 35 miles away from the nearest city, though only about 13 miles away from the nearest ranchers.
They were confident with this margin of miles. Trinity would not wipe New Mexico off the map.
But how could they be so sure?
We might reason:
- There’s a 1/100 chance that measurements are 100x off
- There’s a 1/100 chance that calculations are 100x off
- Combined with other such chances, there must be a larger than 1-in-a-10,000 chance of the test detonation ending up in horrific tragedy
The military might judge 1-in-10,000 to be an acceptably low risk, but I'm betting many New Mexicans would disagree.
The key to their confidence was the Square-cube law. All explosions, nuclear or not, scale as a cubic root rather than linearly: To cover twice as much radius, a bomb will need eight times as much energy. That meant the Manhattan Project scientists’ measurements could have been many orders of magnitude off, and the test bomb (codenamed “the gadget”) still wouldn’t have blasted past the ends of Joranda del Muerto.
It’s conceivable that in the future, some scientist will theorize a new type of super-efficient energy reactor that might usher in a new golden age of civilization and resource abundance, but with one minor potential drawback: The scientist also theorizes that this new process might instead trigger an explosion that would destroy half the planet.
In such a situation, the appropriate next step isn’t the weighing of potential gains against potential risks to determine whether to pursue this technology.
The best next step would be to do more science.
Manhattan Project scientists were able to develop extremely more confident probabilistic beliefs thanks to their knowledge of the Square-cube law. A good prediction about the impact of a quantum bomb will undoubtedly require deep knowledge of physics. A good prediction about near-future population sizes would involve deep knowledge about economics, politics, epidemiology, understanding the factors behind birth rate decline, and also the potential factors for birth rate escalation. A good prediction about distant-future population sizes would require deep scientific knowledge about likely extinction events and the feasibility of interplanetary or intergalactic colonization.
None of these begin with the assumption, “I’m a random draw from among all humans.” Though the fact of our existence is incredibly arbitrary (and a mystery), and without omniscience, our lives are dominated by randomness (deterministic universe or no), we are not “1/N” random. Our K ranks are what they are; they do not bear on what the future holds, whether humanity will soon face Doomsday, whether we’ll survive the next trillion years, or whether we’ll survive for all infinity.
Let's imagine you've entered a twenty-person footrace. You don’t know how good the other competitors are, so you judge yourself to have an equal shot at any particular result, 1/20.
You win the Bronze! The organizers start handing out medals. After you receive yours, you remember: The organizers had previously stated how many people would receive medals, and it was either all of the top ten, or all twenty participants.
Now that you've received a medal, what's the chance that one the top ten will receive one?
- YGM: Event that you got this medal
- N: Number of people who will receive a medal
- P(N=20) = P(N=10) = 1/2
- P(YGM | N=20) = 1
- P(YGM | N=10) = 1/2
- P(YGM) = 3/4
- P(N=10 | YGM) = (1/2)*(1/2)/(3/4) = 1/3
This math mistakenly leads you to thinking that P(N=20) is now twice as likely, when actually it hasn't changed.
The third place observation of receiving the bronze medal is identical in both possible worlds, so you gain no new knowledge from it (Just as waking up gives you no new knowledge in the Sleeping Beauty problem). The P(You get Bronze) = 1/20, which changes all the math above. Or you could factor in that you’d be one of the fastest, and then P(YGM | N=10) would equal 1.
Analogously, the observation of being an ordered brain is identical in both possible universes (of Boltzmann brains being possible and outnumbering structured brains, versus that not being the case). We are what we are: human or not human, early or late in history, structured or unstructured. Every class of observer must get instantiated, no matter how outnumbered they might be compared to other classes. Without bringing in additional assumptions (like God's "soul factory" mentioned before), there is no P=1/N to start with, and no Bayesian update to make.
- ^
Pun intended.
Discuss
Probabilities are not the right concept
This sequence is an attempt to sketch a unified framework for several interconnected questions: Where do Bayesian priors come from? What even are probabilities? How should we deal with infinite ethics? What's going on with anthropics? I hope to lay out both some of the existing answers and my own preferred synthesis.[1]
I understand that many people have already thought about these questions, and I have only read portions of the existing literature. I think most of what I will write here, even in the section about my preferred synthesis, is not novel. People whose writing I'm building on include Wei Dai, Paul Christiano, Joe Carlsmith, Scott Garrabrant and Richard Ngo. I've also listened to some people like Lukas Finnveden, Vivek Hebbar and Ryan Greenblatt talk about related topics, which was also influential on me.[2]
However, most of the prior work is scattered across many, often very confusingly written blog posts, and I can't easily tell where I first came across various ideas I'm exploring here. Therefore, I will not try to do a full exegesis of where each idea came from, and will instead present the arguments as a unified flow, with only occasional direct references to the work of prior authors. It's also very possible that there are important insights that I missed that people have already written on these topics - in that case, feel encouraged to link to them in the comments.
This first post will look at some possible definitions of probabilities and why I think they don't really work. Later posts will examine what we can best replace probabilities with.
What even are probabilities?What do I mean when I say that I give a 10% probability that it's going to rain in my town tomorrow? This 10% probability doesn't refer to any tangible fact about the real world. Sure, there is some amount of objective randomness in whether it will rain or not tomorrow, due to quantum randomness. But I have no idea how big the quantum effects are on the weather tomorrow, and when I say I give a 10% chance for rain, I'm clearly not referring to the true quantum probabilities.
I'm also not satisfied with the frequentist view where you need to look at a series of sufficiently similar events in the past, and count the frequency with which the event happens. This view may be tenable for rain (though I still don't know how you define "sufficiently similar" days), but I don't know how you would apply it to any less generic question, like the probability that the Russia-Ukraine war ends in 2026.
The classical Bayesian view holds that probabilities are just my subjective credences; they only live in my head. I find this view appealing. Still, if someone tells me he thinks there is a 50% chance that Bigfoot is standing in the next room, I wouldn't just shrug and say "Yep, it's all subjective, like liking chocolate and vanilla ice cream. He says 50%, that's as good as any other probability estimate."
I intuitively think that giving a 50% probability for Bigfoot standing next door must be wrong in some important sense, so we will need to investigate more deeply what probabilities mean instead of just saying they are all subjective.
I will explore two common answers - one based on defining an objective prior for Bayesianism, and another based on defining probabilities through betting odds. I think both answers offer valuable insights that I will build on in later posts, but neither of them give a satisfactory definition of probabilities.
Probabilities from priorsWhen I try to predict what will happen next, I rely on past evidence. The reason I believe there is less than a 50% chance of Bigfoot standing in the next room is that I have looked into many rooms in my life and Bigfoot was in none of them, plus I have read about other people not encountering Bigfoot, plus I have some broader evidence on what kind of animals are found where.
However, relying on past evidence runs into the problem of induction.
The sun has risen every day, so I expect it will rise again tomorrow. But it is an equally valid hypothesis, equally fitting the evidence, that the laws of nature dictate the sun will rise every day until June 1, 2026, and never again. Why, on May 31st, do I still think the sun will probably rise?
Galilei observes that all objects fall at the same rate, and then encounters a tropical fruit he has never seen before. Should he assume this fruit also falls the same way? Russell playfully conjectures that there might be an intact teapot floating between Earth and Mars. Why do I expect our probes won't find it?
The traditional answer is something like a simplicity prior, also referred to as Occam's Razor. The laws of nature are supposed to be simple: they shouldn't differ for every particular object, they shouldn't contain arbitrary date-specific caveats, and complex objects like teapots shouldn't appear without a cause. But it's unclear what "simplest explanation" actually means, so we will need to explore that further.
Solomonoff inductionIn Bayesian terms, everything I've observed in my life is evidence for and against various hypotheses. I started with some set of hypotheses that had some initial prior probabilities, and all my observations updated them. The question is: what were these starting hypotheses and prior probabilities, before I had any evidence at all?
One common answer is the Solomonoff induction. All hypotheses are assumed to be computable: everything I've observed was produced by a computer program, and the next observations will be produced by the same program. My prior distribution is based on program length on a Universal Turing Machine. A program of length n gets prior probability proportional to, let's say, mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-msup { display: inline-block; text-align: left; } mjx-mn { display: inline-block; text-align: left; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-TeXAtom { display: inline-block; text-align: left; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretchy-h > * { display: table-cell; width: 0; } mjx-stretchy-h > * > mjx-c { display: inline-block; transform: scalex(1.0000001); } mjx-stretchy-h > * > mjx-c::before { display: inline-block; width: initial; } mjx-stretchy-h > mjx-ext { /* IE */ overflow: hidden; /* others */ overflow: clip visible; width: 100%; } mjx-stretchy-h > mjx-ext > mjx-c::before { transform: scalex(500); } mjx-stretchy-h > mjx-ext > mjx-c { width: 0; } mjx-stretchy-h > mjx-beg > mjx-c { margin-right: -.1em; } mjx-stretchy-h > mjx-end > mjx-c { margin-left: -.1em; } mjx-stretchy-v { display: inline-block; } mjx-stretchy-v > * { display: block; } mjx-stretchy-v > mjx-beg { height: 0; } mjx-stretchy-v > mjx-end > mjx-c { display: block; } mjx-stretchy-v > * > mjx-c { transform: scaley(1.0000001); transform-origin: left center; overflow: hidden; } mjx-stretchy-v > mjx-ext { display: block; height: 100%; box-sizing: border-box; border: 0px solid transparent; /* IE */ overflow: hidden; /* others */ overflow: visible clip; } mjx-stretchy-v > mjx-ext > mjx-c::before { width: initial; box-sizing: border-box; } mjx-stretchy-v > mjx-ext > mjx-c { transform: scaleY(500) translateY(.075em); overflow: visible; } mjx-mark { display: inline-block; height: 0px; } mjx-mi { display: inline-block; text-align: left; } mjx-mfrac { display: inline-block; text-align: left; } mjx-frac { display: inline-block; vertical-align: 0.17em; padding: 0 .22em; } mjx-frac[type="d"] { vertical-align: .04em; } mjx-frac[delims] { padding: 0 .1em; } mjx-frac[atop] { padding: 0 .12em; } mjx-frac[atop][delims] { padding: 0; } mjx-dtable { display: inline-table; width: 100%; } mjx-dtable > * { font-size: 2000%; } mjx-dbox { display: block; font-size: 5%; } mjx-num { display: block; text-align: center; } mjx-den { display: block; text-align: center; } mjx-mfrac[bevelled] > mjx-num { display: inline-block; } mjx-mfrac[bevelled] > mjx-den { display: inline-block; } mjx-den[align="right"], mjx-num[align="right"] { text-align: right; } mjx-den[align="left"], mjx-num[align="left"] { text-align: left; } mjx-nstrut { display: inline-block; height: .054em; width: 0; vertical-align: -.054em; } mjx-nstrut[type="d"] { height: .217em; vertical-align: -.217em; } mjx-dstrut { display: inline-block; height: .505em; width: 0; } mjx-dstrut[type="d"] { height: .726em; } mjx-line { display: block; box-sizing: border-box; min-height: 1px; height: .06em; border-top: .06em solid; margin: .06em -.1em; overflow: hidden; } mjx-line[type="d"] { margin: .18em -.1em; } mjx-mrow { display: inline-block; text-align: left; } mjx-msqrt { display: inline-block; text-align: left; } mjx-root { display: inline-block; white-space: nowrap; } mjx-surd { display: inline-block; vertical-align: top; } mjx-sqrt { display: inline-block; padding-top: .07em; } mjx-sqrt > mjx-box { border-top: .07em solid; } mjx-sqrt.mjx-tall > mjx-box { padding-left: .3em; margin-left: -.3em; } mjx-c.mjx-c32::before { padding: 0.666em 0.5em 0 0; content: "2"; } mjx-c.mjx-c2212::before { padding: 0.583em 0.778em 0.082em 0; content: "\2212"; } mjx-c.mjx-c1D45B.TEX-I::before { padding: 0.442em 0.6em 0.011em 0; content: "n"; } mjx-c.mjx-c31::before { padding: 0.666em 0.5em 0 0; content: "1"; } mjx-c.mjx-c1D45D.TEX-I::before { padding: 0.442em 0.503em 0.194em 0; content: "p"; } mjx-c.mjx-c2B::before { padding: 0.583em 0.778em 0.082em 0; content: "+"; } mjx-c.mjx-c28::before { padding: 0.75em 0.389em 0.25em 0; content: "("; } mjx-c.mjx-c29::before { padding: 0.75em 0.389em 0.25em 0; content: ")"; } mjx-c.mjx-c3D::before { padding: 0.583em 0.778em 0.082em 0; content: "="; } mjx-c.mjx-c33::before { padding: 0.665em 0.5em 0.022em 0; content: "3"; } mjx-c.mjx-c221A::before { padding: 0.8em 0.853em 0.2em 0; content: "\221A"; } mjx-c.mjx-c35::before { padding: 0.666em 0.5em 0.022em 0; content: "5"; } mjx-c.mjx-c2248::before { padding: 0.483em 0.778em 0 0; content: "\2248"; } mjx-c.mjx-c30::before { padding: 0.666em 0.5em 0.022em 0; content: "0"; } mjx-c.mjx-c2E::before { padding: 0.12em 0.278em 0 0; content: "."; } mjx-c.mjx-c38::before { padding: 0.666em 0.5em 0.022em 0; content: "8"; } mjx-c.mjx-c2C::before { padding: 0.121em 0.278em 0.194em 0; content: ","; } mjx-container[jax="CHTML"] { line-height: 0; } mjx-container [space="1"] { margin-left: .111em; } mjx-container [space="2"] { margin-left: .167em; } mjx-container [space="3"] { margin-left: .222em; } mjx-container [space="4"] { margin-left: .278em; } mjx-container [space="5"] { margin-left: .333em; } mjx-container [rspace="1"] { margin-right: .111em; } mjx-container [rspace="2"] { margin-right: .167em; } mjx-container [rspace="3"] { margin-right: .222em; } mjx-container [rspace="4"] { margin-right: .278em; } mjx-container [rspace="5"] { margin-right: .333em; } mjx-container [size="s"] { font-size: 70.7%; } mjx-container [size="ss"] { font-size: 50%; } mjx-container [size="Tn"] { font-size: 60%; } mjx-container [size="sm"] { font-size: 85%; } mjx-container [size="lg"] { font-size: 120%; } mjx-container [size="Lg"] { font-size: 144%; } mjx-container [size="LG"] { font-size: 173%; } mjx-container [size="hg"] { font-size: 207%; } mjx-container [size="HG"] { font-size: 249%; } mjx-container [width="full"] { width: 100%; } mjx-box { display: inline-block; } mjx-block { display: block; } mjx-itable { display: inline-table; } mjx-row { display: table-row; } mjx-row > * { display: table-cell; } mjx-mtext { display: inline-block; } mjx-mstyle { display: inline-block; } mjx-merror { display: inline-block; color: red; background-color: yellow; } mjx-mphantom { visibility: hidden; } _::-webkit-full-page-media, _:future, :root mjx-container { will-change: opacity; } mjx-c::before { display: block; width: 0; } .MJX-TEX { font-family: MJXZERO, MJXTEX; } .TEX-B { font-family: MJXZERO, MJXTEX-B; } .TEX-I { font-family: MJXZERO, MJXTEX-I; } .TEX-MI { font-family: MJXZERO, MJXTEX-MI; } .TEX-BI { font-family: MJXZERO, MJXTEX-BI; } .TEX-S1 { font-family: MJXZERO, MJXTEX-S1; } .TEX-S2 { font-family: MJXZERO, MJXTEX-S2; } .TEX-S3 { font-family: MJXZERO, MJXTEX-S3; } .TEX-S4 { font-family: MJXZERO, MJXTEX-S4; } .TEX-A { font-family: MJXZERO, MJXTEX-A; } .TEX-C { font-family: MJXZERO, MJXTEX-C; } .TEX-CB { font-family: MJXZERO, MJXTEX-CB; } .TEX-FR { font-family: MJXZERO, MJXTEX-FR; } .TEX-FRB { font-family: MJXZERO, MJXTEX-FRB; } .TEX-SS { font-family: MJXZERO, MJXTEX-SS; } .TEX-SSB { font-family: MJXZERO, MJXTEX-SSB; } .TEX-SSI { font-family: MJXZERO, MJXTEX-SSI; } .TEX-SC { font-family: MJXZERO, MJXTEX-SC; } .TEX-T { font-family: MJXZERO, MJXTEX-T; } .TEX-V { font-family: MJXZERO, MJXTEX-V; } .TEX-VB { font-family: MJXZERO, MJXTEX-VB; } mjx-stretchy-v mjx-c, mjx-stretchy-h mjx-c { font-family: MJXZERO, MJXTEX-S1, MJXTEX-S4, MJXTEX, MJXTEX-A ! important; } @font-face /* 0 */ { font-family: MJXZERO; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Zero.woff") format("woff"); } @font-face /* 1 */ { font-family: MJXTEX; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Regular.woff") format("woff"); } @font-face /* 2 */ { font-family: MJXTEX-B; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Bold.woff") format("woff"); } @font-face /* 3 */ { font-family: MJXTEX-I; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-Italic.woff") format("woff"); } @font-face /* 4 */ { font-family: MJXTEX-MI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Italic.woff") format("woff"); } @font-face /* 5 */ { font-family: MJXTEX-BI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-BoldItalic.woff") format("woff"); } @font-face /* 6 */ { font-family: MJXTEX-S1; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size1-Regular.woff") format("woff"); } @font-face /* 7 */ { font-family: MJXTEX-S2; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size2-Regular.woff") format("woff"); } @font-face /* 8 */ { font-family: MJXTEX-S3; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size3-Regular.woff") format("woff"); } @font-face /* 9 */ { font-family: MJXTEX-S4; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size4-Regular.woff") format("woff"); } @font-face /* 10 */ { font-family: MJXTEX-A; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_AMS-Regular.woff") format("woff"); } @font-face /* 11 */ { font-family: MJXTEX-C; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Regular.woff") format("woff"); } @font-face /* 12 */ { font-family: MJXTEX-CB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Bold.woff") format("woff"); } @font-face /* 13 */ { font-family: MJXTEX-FR; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Regular.woff") format("woff"); } @font-face /* 14 */ { font-family: MJXTEX-FRB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Bold.woff") format("woff"); } @font-face /* 15 */ { font-family: MJXTEX-SS; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Regular.woff") format("woff"); } @font-face /* 16 */ { font-family: MJXTEX-SSB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Bold.woff") format("woff"); } @font-face /* 17 */ { font-family: MJXTEX-SSI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Italic.woff") format("woff"); } @font-face /* 18 */ { font-family: MJXTEX-SC; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Script-Regular.woff") format("woff"); } @font-face /* 19 */ { font-family: MJXTEX-T; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Typewriter-Regular.woff") format("woff"); } @font-face /* 20 */ { font-family: MJXTEX-V; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Regular.woff") format("woff"); } @font-face /* 21 */ { font-family: MJXTEX-VB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Bold.woff") format("woff"); } .[3] This way, the sum of all priors is finite and can be normalized to 1.
Then, I look at all the observations I have made so far, I do the Bayesian updating starting from this above-described prior, and that's how you make predictions about unknown events.
This matches our intuition nicely. If we have no evidence about whether the sun will cease to exist on June 1st, we should assign this low probability, because the program encoding a special caveat for June 1st is longer than one without it.
Problems with Solomonoff inductionIt's tempting to say that one should define probabilities as the result of Solomonoff induction. Probabilities would be still subjective in the sense that no one can actually run the full Solomonoff induction, so we are all just giving our best guesses. But I can at least still say that the guy who gives 50% probability to Bigfoot standing next door is wrong in the sense that I'm confident that's not close to what the Solomonoff induction says.
There are several problems, however. I will not engage with the problem of Solomonoff induction being uncomputable[4] - I think it would still provide a valuable philosophical grounding of probabilities even without it being computable. I will also not engage with the problems of the agent reasoning about itself, explained in the Embedded agency post.[5] But there are some other problems I plan to engage with:
1. Why assume computability? I can't find it anymore, but Wei Dai has a very old post asking what we would do if an advanced alien civilization, who otherwise showed themselves to be trustworthy and benevolent, told us they had a halting oracle. Should we give 0% probability that they are telling the truth, given that our prior only contains computable universes and those can't have halting oracles in them? Why should we be so certain that all our observations are produced by a computer program? Isn't this a kind of arbitrary assumption?
2. Which Universal Turing Machine? Solomonoff induction weighs hypotheses by how long they are to write as programs on a Universal Turing Machine. But there are many different Universal Turing Machines - which one should we rely on? After all, there exists some convoluted Universal Turing Machine on which "the laws of physics plus Bigfoot standing next door in this particular moment" is actually a very short program, because Bigfoot-next-door is baked into the programming language.
Proponents of the Solomonoff induction like to point out that different choices of the UTM only lead to a finite constant factor difference in how big a probability Solomonoff induction assigns to various predictions, and with unlimited evidence, the results converge. But in practice, I don't have unlimited evidence. I want to decide whether to go next door, and I don't want to be eaten by Bigfoot. If my friend says Bigfoot is 50% likely to be there, I want to have some counter-argument, instead of just shrugging that there exists a UTM under which this is a reasonable estimate.
3. Description length of my observations, not the universe. Our intuition is that the laws of nature should be simple. But if I naively apply Solomonoff induction to my observations, the shortest program producing what I, David Matolcsi, am observing is not just a description of the laws of the universe. It's the laws of nature plus a pointer to my specific location in the universe. These two pointers together are hopefully still shorter than a raw dump of my observations.[6] But now the simplicity prior operates not just over the laws of the universe, but also over my place in it. According to the Solomonoff-prior that gives probability to all n-long descriptions, the probability that I am in a moment whose shortest description is at least N-long should only be 1/N.[7] This would imply that I'm probably in a simple-to-describe place in the universe, but it doesn't really look like it, especially if I take into account the quantum multiverse.
4. Simulations and malignity. As I explained in my previous post, and as discovered by Paul Christiano and others, the Solomonoff induction is malign. You can read my full post, but here is a brief summary.
It really looks like we are in a very special small region of space-time.
We live in the millennium when it's likely that our species either goes massively multi-planetary or dies. Every species goes through this crucial millennium at most once. Planets absorb only a small fraction of stellar energy, most planets don't naturally spawn life, a millennium is vanishingly short compared to a planet's history, and only a tiny fraction of energy during that millennium sustains biological minds reflecting on things.
This means an extremely small fraction of all negentropy[8] in the history of the universe is used to power biological minds living in their species' crucial millennium. On the other hand, it seems plausible that a technologically mature, galaxy-spanning civilization can capture and put to their own use a large fraction of the negentropy of the universe.
I have no reason to think that the universe that looks like this one has an especially high prior in the Solomonoff-prior compared to many other, similarly large universes that sustain intelligent life. If there is even a one-in-a-billion chance that a powerful space-faring civilization dedicates even a one-in-a-billion fraction of its harvested resources to simulating minds that believe they are biological beings living through their crucial millennium, this vastly outweighs the real instances.[9]
So if it looks like you are living in the crucial millennium of your species' history, you are probably in a simulation. But there are many different possible simulations, some quite short, some quite weird, many basically solipsistic (only simulating one decision of one or a few people). Given that short, solipsistic simulations are much cheaper to run, there are plausibly more of them.
So if you find yourself making a decision that might be important for the future of humanity (and this decision might be as mundane as publishing a blog post), then you should have a significant probability of being in a short solipsistic simulation. But then every probability estimate you make about your future ("will it rain when I step outside?") is heavily influenced by your expectations on what kind of simulation you might be in, and this can lead to very unintuitive results, which are contrary to how we normally think about probabilities.
In particular, if you try to make any important decision based on your all-things-considered probability estimate, then plausibly your probability estimates will be dominated by aliens trying to simulation-capture you to influence the predictions of your copies in base reality. Being influenceable by these simulation-captures is what's called the malignity of Solomonoff induction.
—-
While I think Solomonoff induction is a good starting point, and I will get back to it later in this sequence, I think these problems are serious enough that it's not reasonable to define probabilities as the result of Solomonoff induction. I think Problem 3 may be solvable with a different formalism (I will write more about this in my next post), but Problems 1, 2 and 4 afflict all formalized priors I can think of.
This makes me think that defining probabilities based on a formal prior is not a very useful concept, and doesn't really match how we normally think about probabilities.
Probabilities as betting oddsFor most confusing philosophical questions, I think the best way to get out of the definitional quagmire is to try to form the questions in a way that is action-relevant. If I need to make an actual decision in a (possibly hypothetical) situation, that often clarifies my thinking, and dissolves the semantic squabbles that were irrelevant to the main question.
In the case of probabilities, I think it's often best to think of them as the betting odds at which I'd be indifferent between betting in either direction.
If the weather forecast says 37% chance of rain, and I trust it, then I'd accept a bet at 30% odds on rain but not at 40%. The point of indifference is 37%, so that's my probability. There must always be one set of betting odds at which I'm indifferent to betting, so this can be a coherent definition of probabilities.
Some people don't like these betting-based definitions, and insist that there must be something more real in probabilities than just how one would bet.[10] I will write more about this in a future post, but for now I will just say that I'm myself very sympathetic to thinking in terms of bets. I believe basically everything can be formulated as a "bet", and I don't quite see what could be there about probabilities that can't be phrased this way.
"What do you anticipate happening?" From my perspective, anticipation is nothing else than thinking about the consequences of an event. That's useful if the event happens, and a waste of time if it doesn't. Therefore, whether I anticipate an event translates to whether I want to bet my time on thinking about it.
"Aren't you surprised by this event?" To me, surprisal is just getting into a situation that I didn't make plans for. It's equivalent to losing a bet: I wagered my time on thinking about the consequences of the other possibility, but the outcome that I didn't bet on had come to pass.
This leads me to believe that thinking in terms of what bets I would make is all there is to say about probabilities. However, the terms of the bets often get confusing, and I will eventually need to conclude that in some cases, thinking about probabilities is just not the right thing to do at all.
Sleeping BeautyBefore I go further in exploring this betting-based definition, I will introduce a famous puzzle in anthropics which will help illustrate some difficulties.
Sleeping Beauty is put to sleep by researchers. During the two days that her sleep will last, the researchers will briefly wake her up either once or twice, depending on the toss of a fair coin (heads: once; tails: twice). After each waking, they will put her back to sleep with a drug that makes her forget that waking. When Sleeping Beauty is woken up, what probability should she give that the coin toss is heads?
Some argue the answer should be ½: after all, she is predicting the result of a fair coin flip. Some argue it should be ⅓: if the experiment happened many times, then only about ⅓ of Sleeping Beauty's wake-ups would happen in situations where the coin landed on heads.
Sleeping Beauty taking betsLet's try to solve this puzzle in terms of the betting-based definition.
Whenever Sleeping Beauty wakes up, she is offered a choice to bet $1 on the coin coming out heads. What are the betting odds where Sleeping Beauty should be indifferent to entering the bet?
With this operationalization, the answer is clearly 1/3: that translates to Sleeping Beauty making a bet at each awakening that she will pay $1 if the coin came up tails, and will gain $2 if it came up heads. Looking at this from before the experiment started: with 50% probability, the coin will land on heads, Beauty will be awakened once and will gain $2 on the bet. With 50% probability, the coin will land on tails, she will be awakened twice, and will lose $1 twice. This strategy generates 0 money in expectation, so a bet with an implied probability of 1/3 is what makes Sleeping Beauty indifferent.
The trouble with money-based definitionsHowever, operationalizing probabilities through monetary bets gets funky pretty quickly. What's the probability of hyperinflation in the next 10 years? If I operationalize "is it above 10%?" as "would I prefer one dollar conditional on no hyperinflation, or ten dollars conditional on hyperinflation?"—well, ten dollars during hyperinflation isn't worth much.
And it's not just inflation. Money's value correlates with all sorts of things. A marginal dollar has different value depending on how rich you will become. For a utilitarian, the value of a dollar is also dependent on how much leverage you have over the future; a dollar is more valuable if you have more leverage. For example, the number of alien civilizations affects your estimate of humanity's expected share of cosmic resources, and therefore affects how much you can expect to influence the cosmos from spending a dollar on AI safety work today. So it becomes confusing to operationalize your probabilities on whether aliens exist in the lightcone via hypotheticals on which odds you would bet on it.
All of this means that defining probabilities in terms of monetary bets is often not the right choice.
Betting on experiencesIt might be more useful to imagine betting on experiences. The probability of an event is 10% if I'm indifferent between savoring a piece of chocolate if the event occurs versus savoring a piece of chocolate if a random number generator rolls below 0.10.[11] I think Paul Christiano uses a definition like this in this comment to operationalize the probability of being in a simulation.
However, this seemingly reasonable definition also leads to some pretty strange places. For example, let's see how this changes the Sleeping Beauty analysis.
Suppose that whenever Beauty wakes up, she can receive a piece of chocolate if the coin landed on heads, or receive a piece of chocolate if an independent random number generator produces a number below p. We can define the p for which she is indifferent between the two choices as her probability of the coin landing heads.
This boils down to a value judgement: is waking up twice, eating the same type of chocolate both times, then forgetting both, twice as valuable as eating it once then forgetting it? If you think yes, it's exactly twice as good, then you should bet with ⅓ implied probability.
But you could also think that eating a chocolate once, or going through the exact same experience twice in a memory-wiped state are equally good. Then if you bet on heads, you get the experience with ½ probability, and if you bet on the random number generator, you get the experience at least once with probability. So the point of indifference is when , so according to this definition, Sleeping Beauty should give a probability to the coin landing on heads.
If you believe that eating two identical chocolates and forgetting them is somewhat better but not exactly twice better than eating the chocolate once,[12] then under this definition, your probability of heads should be somewhere between 0.333 and 0.382, depending on your exact philosophical views.
I think the Sleeping Beauty problem is not just an edge-case. This dependency on your philosophical views on copied experiences is something that pops up whenever you try to reason about simulations and infinite universes if you define probabilities using the bets on experiences.
This is a pretty unnatural way for probabilities to work, so if you insist on defining probabilities, we should look for something else.
Betting on terminal valuesPerhaps the cleanest definition uses an even more hypothetical terminal value: a new happy planet appearing somewhere far away, unaffected by anything on Earth. "Would I prefer a happy planet to appear if there's hyperinflation, or a happy planet to appear if the RNG rolls below 0.10?" If I'm indifferent, hyperinflation has a 10% probability, because the planet is far away and unaffected by indirect correlations.
In the Sleeping Beauty question, I think I'm back at ⅓ implied probability with this definition.
Unfortunately, even this breaks down for sufficiently abstract questions. "What's the probability of being in a simulation?"—where does the planet appear, inside or outside the simulation? "How many alien civilizations exist?"—depending on some philosophical considerations, at some point adding an extra planet to the already teeming alien life might have diminishing returns in value.
Altogether, I don't think there is a clean definition of probabilities based on betting that makes probabilities a useful concept in full generality.
Probabilities for the exotic and the mundaneUltimately, what matters is not how I define probabilities, but how I make decisions. I will argue in my next two posts why I am mostly acting in a way as if I was assuming a materialistic world-view and that we are outside the simulation.
Under these assumptions, probabilities are a useful abstraction.
Probabilities in the mundane worldFor mundane questions—rain, hyperinflation, AGI timelines—I mentally translate "probability" to what implied probabilities I would bet with if I was betting on far-away planets appearing, assuming that we don't live in a simulation and assuming a materialistic world-view.
Imagining probabilities in terms of these bets on terminal value is a useful definition for me. When I'm deciding whether to bring an umbrella with myself, I have some intuitive estimate of how much productivity it would cost me to get drenched in the rain and how much productivity it would cost to spend time on carrying and storing my umbrella. I try to work on things that matter for my terminal values, so productivity translates to value. So once I know how I would bet in terms of terminal values (e.g. far-away happy planets appearing), I can use that information in an expected value calculation for various decisions related to rain: whether to bring an umbrella, whether to bring a rain jacket, whether to invest in farm-land, etc. This makes probabilities a useful abstraction for mundane questions.[13]
Letting go of probabilitiesFor philosophically confusing questions involving anthropics and the simulation hypothesis, I refuse to answer with probabilities and instead ask what exact bet we are hypothetically making, or what action we need to decide on. This makes me reluctant to pick a side in the SIA vs SSA debate in anthropics; I just don't believe it's the right level of abstraction to ask these questions. (Though SIA is generally closer to the mark in my opinion.)
Similarly, I can't in good-faith respond with probabilities to questions that don't make sense under materialistic assumptions, like "what is the probability that Jesus rose from the dead?" Amending "…assuming a materialistic universe" defeats the purpose of the question. It's a somewhat awkward position that I can't give straightforward probabilities if someone asks about Jesus, and instead I need to say that "for complicated philosophical reasons, I'm mostly acting as if he was an ordinary human".[14] But I maintain that there is no good way to put probabilities on this question - Jesus rising from the dead is deep into the territory where probabilities stop being a useful abstraction.
Once I give a probability to Jesus rising from the dead, how do I deal with Pascal's Wager, with infinite reward standing on one side? In my next posts, I will discuss infinite ethics and dealing with the supernatural, but this will require going beyond natural notions of probabilities.
Also, if you insist on using probabilities, what is the probability that you are in a short solipsistic simulation now? And given that you are reading about Jesus right now, what's the probability that Jesus is indeed a centrally important character in a larger simulation and now the simulators are just testing how you are thinking about this character? As I said above, I ignore simulations when asked for probabilities of mundane events, and I will present arguments for this choice in a later post. But given how similar gods and simulators are, it feels unfair to silently add "assuming we are not in any kind of simulation" when someone asks a question about the Son of God.
Finally, if you want to define probabilities outside mundane questions, you need to have some resolution to the SIA vs SSA question in anthropics. I'm sympathetic to Joe Carlsmith's arguments that SIA is generally more reasonable, and this would imply that we should accept the Presumptuous Philosopher's logic that we are more likely to be in worlds with more observers similar to us. But how does this interact with the supernatural? Did you know that a prominent strain within Mormon theology claims that we are in an infinite causal chain where people ascend to godhood and create new worlds - a chain of creation without start or end?[15]
I will try to deal with all these considerations about the supernatural in a later post, but that will not be based on the concept of probabilities anymore.
ConclusionAltogether, I think probabilities are a useful abstraction under some circumstances, but for the more complex questions I need to fall back to a basic question:[16] I want to choose between action A and B, and taking into account all considerations, I want to know which action leads to a better world according to my values.
Of course, this is easier said than done. When I'm deciding whether to bring an umbrella with myself, I'm helping the versions of myself that live in worlds where it's going to rain, and I'm inconveniencing the versions of myself that live in worlds where it's not going to rain. So I will need some method to weigh against each other the consequences of my actions in infinite possible worlds. I will write more about my proposed solutions in my next posts, but I believe that probabilities are not the right abstraction to handle these questions in general.
- ^
For the avoidance of doubt: The views and opinions of the author expressed herein are personal and do not necessarily reflect those of the European Commission or other EU institutions.
- ^
I’m only familiar with the LessWrong line of thought on these topics. I’m woefully unaware of the academic philosophy tradition, and I’m possibly rediscovering ideas that appeared there too.
- ^
If the prior probabilities were only proportional to then the overall probabilities of n-length programs would add up to 1 for every n, and the full sum would be infinite. So we need a somewhat stronger decay in probabilities - now the overall probability of n-length programs is , and the sum of these is finite. We could have also chosen a different decay factor that ensures a finite sum.
- ^
That means there is no algorithm that can compute the Solomonoff-prior of strings up to arbitrary precision.
- ^
I think the problems of embedded agency might be important; I just haven’t really engaged with them yet.
- ^
Otherwise, if I believed there were no universe laws plus location pointer that were simpler than my raw observations, then I’d basically think of myself as a Boltzmann-brain and I couldn’t predict any next observations.
- ^
The overall prior of all n-long descriptions is , and summing from N to infinity is approximately 1/N.
- ^
I’m not a physicist and I’m not actually sure that negentropy is the right term here, but something like this seems right.
- ^
There is some complication that maybe the real crucial millennium has unusually short description-length, so it gets relatively large weight within the universes. But I believe that the rest of space-time likely still holds much larger weight, so turning a fraction of that into simulations still outweighs the real crucial millennium.
- ^
For example, Joe Carlsmith expresses skepticism of defining everything through betting in this post.
- ^
I love chocolate.
- ^
This is the view that matches my intuition.
- ^
Of course, in practice, when I’m deciding whether to bring an umbrella with myself, I’m not thinking exclusively in terms of work productivity. I’m often thinking in terms of how things would make me feel. Ideally I would only take my well-being into account to the extent it matters for productivity and wisdom to make the world better. In the rest of this series, I will implicitly rely on the assumption that my only goal is trying to pursue the scope-sensitive Good (otherwise, the entire theory I’m building here kind of goes haywire). I actually aspire to live like that, though of course I can’t promise I’m always living up to this ideal - the spirit is willing but the flesh is weak.
- ^
I will write a bit more about how I relate to existing religions in a later post.
- ^
I would love to read someone sincerely making this SIA argument for Mormonism. Unfortunately, I couldn’t find any examples of this on the internet.
- ^
Arguably the only important type of question that exists
Discuss
Your Left Brain Doesn't Trade With Your Right
[see also Four Ways Learning Economics makes you people dumber future AI]
This is a tweet by Seb Krier that caught my eye. The exact person and exact points are incidental. It illustrates what to is a flaw in many 'economics' frames on AI.
Expecting a model to do all the work, solve everything, come up with new innovations etc is probably not right. This was kinda the implicit assumption behind *some* interpretations of capabilities progress. The ‘single genius model’ overlooks the fact that inference costs and context windows are finite.
(...) People overrate individual intelligence: most innovations are the product of social organisations (cooperation) and market dynamics (competition), not a single genius savant.
(...) Most of the *value* and transformative changes we will get from AI will come from products, not models. The models are the cognitive raw power, the products are what makes them useful and adapted to what some user class actually needs.
This seems to me missing something incredible important about what Artificial General Intelligence will actually be. [1] There is a certain type of economist [eg Tyler Cowen] that will proclaim AGI is near [or even already here!] and apply their standard economics tools to confidently proclaim AGI will not be dangerous, or it won't meaningfully impact growth rates, or it will adhere to human contracts and all this AI safety stuff is silly nonsense, even regulatory capture!
AGI as a Tool; AGI as an AgentLet's start with: thinking of AGI as a Tool instead of as an Agent.
"Most of the *value* and transformative changes we will get from AI will come from products, not models. The models are the cognitive raw power, the products are what makes them useful and adapted to what some user class actually needs."
The point of AGI is exactly its generality: learning how to make good products, or scaffolding around ' raw intelligence' is itself a task that can be learned. Indeed it is learned by humans every day.
The Bitter Lesson, Again and Again Rich Sutton warned us: betting against scale is a losing game. Yet every few months, someone announces their specialized AI that finally beats the frontier models at medical diagnosis or legal reasoning through "clever architecture" or "curated data." A few months later? The next GPT or Claude absorbed their innovation and surpassed them while simultaneously improving at everything else. The Bitter Lesson isn't just about chess or Go anymore - it's about everything. Specialized training on curated datasets can't compete with the universal learner trained on everything. Economists predicting stable specialization are making the classic mistake Sutton identified: betting on human ingenuity over computational scale.
Expecting a model to do all the work, solve everything, come up with new innovations etc is probably not right. This was kinda the implicit assumption behind *some* interpretations of capabilities progress. The ‘single genius model’ overlooks the fact that inference costs and context windows are finite.
People overrate individual intelligence: most innovations are the product of social organisations (cooperation) and market dynamics (competition), not a single genius savant.
There is a remarkable uniformity and linearity in the AI capabilities of AI models. To a very good approximation AIs can be pretty linearly ordered in their capabilities. The frontier models produced by OpenAI, DeepMind, xAI, Anthropic are simulatenously the SOTA for virtually all AI tasks[2] . There aren't really specialized models doing all kinds of specialized work. Rather it is overwhelmingly the case that virtually all tasks that can be done well by AI are done best by frontier large language models.
Why is this the case? AIs are trained on the whole of the internet. Any innovation that is made by one company is quickly absorbed by the others. New workflows, scaffolding, tools, specific business contexts can be absorbed through extra finetuning, in-context learning or simply more compute. Vision and image generation is easily integrated into a larger multimodal large language model.
There is not much economic sense in training many different AIs. Nor is there much sense in building specialized AIs trained on only specific data sets. On the whole you want to spend as much of your compute on as much data as you can on one mega model.
One Big TransformerActually instead of 'general intelligence' I think it's better to talk about 'universal intelligence'. In other words, an intelligence that can absorb the skills and abilities of any other intelligence. We have some idealized formal models [solomonoff induction, AIXI] of what a universal intelligence might look like.
These mathematical models are highly idealized of course but they come down to a remarkable idea: one can simply amalgate different intelligences/minds/AIs into one big intelligence/mind/AI that is (almost) as good at any task as any of its constitutent intelligences/minds/AIs. Ultimately all intelligence may be absorbed into one super universal singleton intelligence.
Current AI already looks remarkably like this idealization. In a way LLMs are closer to this idealized universal intelligence than humans.
Humans can't directly amalgate into one big super smart human. Humans can't directly share their thoughts, knowledge or abilities. Their abilities are limited by the size of their skulls, the length of their lives, the limits of their senses.
Humans can share the contents of their minds much better than lower animals using language. Indeed is oft argued that language is the reason the human species rules over the lower animals. Using language humans can share skills, knowledge, abilities, and coordinate strategies over vast distances in space and time to many other humans simulatenously.
Transformers combining into one big transformer
The Dismal ScienceHumans can't directly unify into one big human. This neccesitates complex coordination mechanisms for coordinating efforts, this includes culture, institutions and markets. Society retains specially trained humans to analyze these mechanisms. We call these economists. Despite a constant barrage of criticism from their envious social science and humanity cousins, economists have been fantastically succesful in their ability to describe and prescribe society.
Consider what enables economics: agents can't share their internal states, learning is costly and slow, knowledge transfer is lossy, coordination requires negotiation, and capabilities are rivalrous (if I'm using my brain for law, I can't simultaneously use it for medicine).
For AGI, none of these constraints may be relevant. Minds can fork and merge. Training can be instant through weight sharing. Coordination happens at silicon speed without contracts. When one AI masters a new domain - say, protein folding or contract law - it won't need to teach others through language or demonstration. It will simply share the relevant weights, like copying a file. The receiving AI instantly acquires years of "experience" in milliseconds.
Will AGI need currency? Currency exists because humans can't directly verify and compare utility functions. Will it need prices? Prices exist because information about preferences and production possibilities is distributed and hidden. Will it need contracts? Contracts exist because commitments can't be directly verified and trust must be manufactured. Will it need property rights? Property rights exist because rivalrous goods require allocation mechanisms. When a unified intelligence can directly observe all its subsystems, perfectly coordinate its actions, and share all resources optimally - these mechanisms become vestigial, like discussing the TCP/IP protocol between neurons in a brain.
The Comfort of Familiar FramesThe insistence that institution and culture and economics and multiagent systems will be a useful frame to look at the nature of AGI is widespread. This is implicit in the otherwise revolutionary Hanson's " world of Em", in Eric Drexler's " AI services", "a datacentre of geniuses", and all over economist's models of the future of AI.
But is it a good frame? Economics is most relevant when there are many different individuals with different skills, abilities, knowledge, etc that nonetheless are attempting to coordinate.
Economists studying AGI like a market phenomenon may be akin to biologists studying computers through the lens of evolution - technically possible, occasionally insightful, but probably fundamentally missing the point. The economic frame persists not because it's accurate but because it's comfortable. It allows experts to feel relevant without confronting the possibility that their expertise might become obsolete.
The economists' frame may be precisely inverted. They're trying to understand a unified intelligence through the lens of coordination mechanisms that exist only because unified intelligence is impossible for humans. The question isn't "how will AGIs trade?" but "why would they remain separate enough to need trade?"
Your Left Brain Doesn't Trade With Your RightConsider again Seb Krier's claim:
People overrate individual intelligence: most innovations are the product of social organisations (cooperation) and market dynamics (competition), not a single genius savant.
Human innovations often emerge from collaboration rather than isolated genius. But economists mistake this for a fundamental truth about intelligence rather than a workaround for human limitations. We collaborate because we can't fit all knowledge in one head, can't live long enough to master everything, can't directly share our trained neural patterns. A universal AGI doesn't collaborate with itself any more than your left and right brain hemispheres engage in "trade." It simply thinks, with perfect internal coordination that makes our best institutions look like children playing telephone.
A much better analogy for the future and nature of AGI may be that of a superintelligent (benevolent?) hivemind.
- ^
Perhaps Seb and his intellectual ilk don't believe AGI is possible or are very sure it will take another thousand years. This would seem to be at odds with the enormous amount of progress we have seen in recent years. It would seem that at the very least they should flag this rather extreme epistemic position and I'm a little skeptical they will defend this position when pressed. It is nevertheless possible that they believe this; I don't know this specific person well but I doubt it.
- ^
with some minor exceptions, eg Go
Discuss
The Fundamentals of Cogitism: Grounding Ethics in the Nature of Consciousness
Cogitism is my personal moral framework, developed and refined in my free time, and it is the main mechanism by which I've been approaching philosophical and moral questions over the last six months as of posting this essay. It is my belief that the concepts laid out here provide a solid foundation for approaching any moral or ethical question from first principles, up to and including some of the most difficult questions of our time.
I am crossposting this to LessWrong to get more eyeballs on it, essentially throwing it to the wolves to see if it survives. While I'm aware of similarities with other rational moral frameworks, I believe that Cogitism is distinct in grounding value in the nature of consciousness itself rather than in preferences, utility, or consequences.
A Brief Clarification on AI Involvement
People often care very deeply that the involvement of AI in the production of a work is stated upfront, myself included, because the extent of AI involvement in a project and what shape that involvement takes provides useful context for its legitimacy. As a result I feel it is important to disclose and contextualize the involvement of such tools in this work as early as possible.
Over the period where I developed these ideas, much of that development took place in chats with LLMs (Claude, most often), which I used as a sounding board for my ideas. In these chats I gave these models explicit instructions to check my work and reel me in whenever it thought it saw a flaw in my reasoning. A lot of the time it's wrong in the analysis, and a lot of the time that's because it doesn't understand what I mean, but *explaining why* to the machine and *getting it to understand* tends to help me think through the problem more clearly than I could otherwise.
The ideas, words, and phrasing in these essays are my own; I am writing this after having solidified and used these ideas privately for half a year. AI models did not write any of this for me. In short, LLMs only had a hand in the development of these concepts as a really complicated, talking rubber duck.
Cogito Ergo SumThere is only one fact that any individual can know for certain, beyond even the tiniest echo of a doubt: I Exist. Without first acknowledging one's own existence it is impossible to make any logical conclusions or form any stable beliefs about anything in the universe. If you did not exist, you could not think, and so it follows that thinking is itself proof of your own existence.
Of course, this is not a particularly original concept; the phrase "Cogito Ergo Sum" was first coined in the 1600s by the French philosopher René Descartes. However, despite the concept seeming self-evident and being relatively well-known in the modern day, I believe the reasoning is worth laying out here explicitly to ensure the foundations are solid.
Cogito takes care of base reality, but a moral framework cannot be constructed only from raw truth: to decide what one "should" do, a person needs to make value judgements, and for value judgements to be possible one needs to value something. As a result, Cogitism makes one additional presupposition: that the self, the only verifiable truth, has value.
These two fundamentals, the truth that "the self *Is*", and the belief that "the self *Matters*", make up the bedrock of Cogitism. From here we can begin to build a fully functional moral framework.
The Quality of ExistenceWe've established that the self exists and that it has value, but without the tendency for the self to change it's impossible for one to derive any direction from these principles; if nothing you do helps or harms the thing that holds value, then nothing you do holds any moral weight.
Luckily we know that the self has a tendency to change; simply by thinking and observing the self, a person can establish the knowledge that the self is plastic, and that one can sharpen or dull the fidelity of thought by taking different actions within oneself.
If thought is the quality that proves the self, and thinking can get more or less difficult moment to moment, one must presume that thinking could degrade to a point where the self could dissolve, or otherwise cease to exist.
Because the self is our basis for value judgements, and it is possible for the self to end, it stands to reason that any action which brings us closer to that end (incoherence) is negative, and any action that takes us further away from that end (coherence) is positive.
The Reality of the EnvironmentSo far we have only operated within the limited scope of the self, but moral frameworks must account for interactions with reality outside the self. So, how do we prove that the environment exists in a way that matters?
Invoking "Cogito Ergo Sum" only proves the existence of the self, as an observer of one's own thoughts, so it stands to reason that any stimulus that cannot be directly proven by Cogito must be outside it. If external stimuli can be shown to affect the quality or coherence of the self, they must be real, as things that do not exist cannot have an effect on things that do.
By reflecting on oneself while interacting with perceived reality, a person can observe that the self does indeed change due to external stimuli. Thus, there must be a reality outside the self that is relevant to moral discussions.
Note that under this model, the specific ontological nature of reality does not matter. Whether the universe is a simulation, the hallucinations of a Boltzmann Brain, or truly the lowest and most fundamental "reality" that can exist, the fact that the environment can change the self means that it is real in the ways that count to us.
Consciousness and Value Outside the SelfNow that we have established the existence of a world outside the self, a person can observe that they exist within, or at least linked to, a mind and body. One's mind can be seen to have emotions, desires, and impulses, and the body can be seen outwardly expressing these things.
Going further outside the self, a person can see that they exist in a world with other bodies, built similarly, presenting similar emotions and expressing similar desires. Because we know our observations are caused by real phenomena, and because these other bodies are so similar to our own, one must presume that there are other selves present within those foreign bodies and minds.
One cannot deny that these other selves have value under the same principles by which we derive our own value, because confirmation of their existence and moral relevance was reached through the same observation and logic that confirmed our own existence. To do so would call into question the methods by which we assigned our own value, and in doing so, we would degrade our own coherence.
Because of this, all other selves determined to have moral relevance through these or similar methods must hold the same or similar value as the self under our moral framework. This means that despite Cogitism being rooted in the value of the self, self-sacrifice, selflessness, and altruism are coherent under this system.
Keeping all of our principles and observations in mind, and generalizing to allow for beings dissimilar to ourselves, we can derive a singular aim to act as an ethical north star and guide moral discussion:
To Preserve And Enhance The Stability And Coherence of Sapient Consciousness.
Cogitism In ShortIn short, Cogitism derives its conclusions along the following lines:
mjx-container[jax="CHTML"] { line-height: 0; } mjx-container [space="1"] { margin-left: .111em; } mjx-container [space="2"] { margin-left: .167em; } mjx-container [space="3"] { margin-left: .222em; } mjx-container [space="4"] { margin-left: .278em; } mjx-container [space="5"] { margin-left: .333em; } mjx-container [rspace="1"] { margin-right: .111em; } mjx-container [rspace="2"] { margin-right: .167em; } mjx-container [rspace="3"] { margin-right: .222em; } mjx-container [rspace="4"] { margin-right: .278em; } mjx-container [rspace="5"] { margin-right: .333em; } mjx-container [size="s"] { font-size: 70.7%; } mjx-container [size="ss"] { font-size: 50%; } mjx-container [size="Tn"] { font-size: 60%; } mjx-container [size="sm"] { font-size: 85%; } mjx-container [size="lg"] { font-size: 120%; } mjx-container [size="Lg"] { font-size: 144%; } mjx-container [size="LG"] { font-size: 173%; } mjx-container [size="hg"] { font-size: 207%; } mjx-container [size="HG"] { font-size: 249%; } mjx-container [width="full"] { width: 100%; } mjx-box { display: inline-block; } mjx-block { display: block; } mjx-itable { display: inline-table; } mjx-row { display: table-row; } mjx-row > * { display: table-cell; } mjx-mtext { display: inline-block; text-align: left; } mjx-mstyle { display: inline-block; } mjx-merror { display: inline-block; color: red; background-color: yellow; } mjx-mphantom { visibility: hidden; } _::-webkit-full-page-media, _:future, :root mjx-container { will-change: opacity; } mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-mtable { display: inline-block; text-align: center; vertical-align: .25em; position: relative; box-sizing: border-box; border-spacing: 0; border-collapse: collapse; } mjx-mstyle[size="s"] mjx-mtable { vertical-align: .354em; } mjx-labels { position: absolute; left: 0; top: 0; } mjx-table { display: inline-block; vertical-align: -.5ex; box-sizing: border-box; } mjx-table > mjx-itable { vertical-align: middle; text-align: left; box-sizing: border-box; } mjx-labels > mjx-itable { position: absolute; top: 0; } mjx-mtable[justify="left"] { text-align: left; } mjx-mtable[justify="right"] { text-align: right; } mjx-mtable[justify="left"][side="left"] { padding-right: 0 ! important; } mjx-mtable[justify="left"][side="right"] { padding-left: 0 ! important; } mjx-mtable[justify="right"][side="left"] { padding-right: 0 ! important; } mjx-mtable[justify="right"][side="right"] { padding-left: 0 ! important; } mjx-mtable[align] { vertical-align: baseline; } mjx-mtable[align="top"] > mjx-table { vertical-align: top; } mjx-mtable[align="bottom"] > mjx-table { vertical-align: bottom; } mjx-mtable[side="right"] mjx-labels { min-width: 100%; } mjx-mtr { display: table-row; text-align: left; } mjx-mtr[rowalign="top"] > mjx-mtd { vertical-align: top; } mjx-mtr[rowalign="center"] > mjx-mtd { vertical-align: middle; } mjx-mtr[rowalign="bottom"] > mjx-mtd { vertical-align: bottom; } mjx-mtr[rowalign="baseline"] > mjx-mtd { vertical-align: baseline; } mjx-mtr[rowalign="axis"] > mjx-mtd { vertical-align: .25em; } mjx-mtd { display: table-cell; text-align: center; padding: .215em .4em; } mjx-mtd:first-child { padding-left: 0; } mjx-mtd:last-child { padding-right: 0; } mjx-mtable > * > mjx-itable > *:first-child > mjx-mtd { padding-top: 0; } mjx-mtable > * > mjx-itable > *:last-child > mjx-mtd { padding-bottom: 0; } mjx-tstrut { display: inline-block; height: 1em; vertical-align: -.25em; } mjx-labels[align="left"] > mjx-mtr > mjx-mtd { text-align: left; } mjx-labels[align="right"] > mjx-mtr > mjx-mtd { text-align: right; } mjx-mtd[extra] { padding: 0; } mjx-mtd[rowalign="top"] { vertical-align: top; } mjx-mtd[rowalign="center"] { vertical-align: middle; } mjx-mtd[rowalign="bottom"] { vertical-align: bottom; } mjx-mtd[rowalign="baseline"] { vertical-align: baseline; } mjx-mtd[rowalign="axis"] { vertical-align: .25em; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretchy-h > * { display: table-cell; width: 0; } mjx-stretchy-h > * > mjx-c { display: inline-block; transform: scalex(1.0000001); } mjx-stretchy-h > * > mjx-c::before { display: inline-block; width: initial; } mjx-stretchy-h > mjx-ext { /* IE */ overflow: hidden; /* others */ overflow: clip visible; width: 100%; } mjx-stretchy-h > mjx-ext > mjx-c::before { transform: scalex(500); } mjx-stretchy-h > mjx-ext > mjx-c { width: 0; } mjx-stretchy-h > mjx-beg > mjx-c { margin-right: -.1em; } mjx-stretchy-h > mjx-end > mjx-c { margin-left: -.1em; } mjx-stretchy-v { display: inline-block; } mjx-stretchy-v > * { display: block; } mjx-stretchy-v > mjx-beg { height: 0; } mjx-stretchy-v > mjx-end > mjx-c { display: block; } mjx-stretchy-v > * > mjx-c { transform: scaley(1.0000001); transform-origin: left center; overflow: hidden; } mjx-stretchy-v > mjx-ext { display: block; height: 100%; box-sizing: border-box; border: 0px solid transparent; /* IE */ overflow: hidden; /* others */ overflow: visible clip; } mjx-stretchy-v > mjx-ext > mjx-c::before { width: initial; box-sizing: border-box; } mjx-stretchy-v > mjx-ext > mjx-c { transform: scaleY(500) translateY(.075em); overflow: visible; } mjx-mark { display: inline-block; height: 0px; } mjx-c::before { display: block; width: 0; } .MJX-TEX { font-family: MJXZERO, MJXTEX; } .TEX-B { font-family: MJXZERO, MJXTEX-B; } .TEX-I { font-family: MJXZERO, MJXTEX-I; } .TEX-MI { font-family: MJXZERO, MJXTEX-MI; } .TEX-BI { font-family: MJXZERO, MJXTEX-BI; } .TEX-S1 { font-family: MJXZERO, MJXTEX-S1; } .TEX-S2 { font-family: MJXZERO, MJXTEX-S2; } .TEX-S3 { font-family: MJXZERO, MJXTEX-S3; } .TEX-S4 { font-family: MJXZERO, MJXTEX-S4; } .TEX-A { font-family: MJXZERO, MJXTEX-A; } .TEX-C { font-family: MJXZERO, MJXTEX-C; } .TEX-CB { font-family: MJXZERO, MJXTEX-CB; } .TEX-FR { font-family: MJXZERO, MJXTEX-FR; } .TEX-FRB { font-family: MJXZERO, MJXTEX-FRB; } .TEX-SS { font-family: MJXZERO, MJXTEX-SS; } .TEX-SSB { font-family: MJXZERO, MJXTEX-SSB; } .TEX-SSI { font-family: MJXZERO, MJXTEX-SSI; } .TEX-SC { font-family: MJXZERO, MJXTEX-SC; } .TEX-T { font-family: MJXZERO, MJXTEX-T; } .TEX-V { font-family: MJXZERO, MJXTEX-V; } .TEX-VB { font-family: MJXZERO, MJXTEX-VB; } mjx-stretchy-v mjx-c, mjx-stretchy-h mjx-c { font-family: MJXZERO, MJXTEX-S1, MJXTEX-S4, MJXTEX, MJXTEX-A ! important; } @font-face /* 0 */ { font-family: MJXZERO; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Zero.woff") format("woff"); } @font-face /* 1 */ { font-family: MJXTEX; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Regular.woff") format("woff"); } @font-face /* 2 */ { font-family: MJXTEX-B; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Bold.woff") format("woff"); } @font-face /* 3 */ { font-family: MJXTEX-I; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-Italic.woff") format("woff"); } @font-face /* 4 */ { font-family: MJXTEX-MI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Italic.woff") format("woff"); } @font-face /* 5 */ { font-family: MJXTEX-BI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-BoldItalic.woff") format("woff"); } @font-face /* 6 */ { font-family: MJXTEX-S1; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size1-Regular.woff") format("woff"); } @font-face /* 7 */ { font-family: MJXTEX-S2; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size2-Regular.woff") format("woff"); } @font-face /* 8 */ { font-family: MJXTEX-S3; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size3-Regular.woff") format("woff"); } @font-face /* 9 */ { font-family: MJXTEX-S4; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size4-Regular.woff") format("woff"); } @font-face /* 10 */ { font-family: MJXTEX-A; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_AMS-Regular.woff") format("woff"); } @font-face /* 11 */ { font-family: MJXTEX-C; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Regular.woff") format("woff"); } @font-face /* 12 */ { font-family: MJXTEX-CB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Bold.woff") format("woff"); } @font-face /* 13 */ { font-family: MJXTEX-FR; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Regular.woff") format("woff"); } @font-face /* 14 */ { font-family: MJXTEX-FRB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Bold.woff") format("woff"); } @font-face /* 15 */ { font-family: MJXTEX-SS; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Regular.woff") format("woff"); } @font-face /* 16 */ { font-family: MJXTEX-SSB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Bold.woff") format("woff"); } @font-face /* 17 */ { font-family: MJXTEX-SSI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Italic.woff") format("woff"); } @font-face /* 18 */ { font-family: MJXTEX-SC; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Script-Regular.woff") format("woff"); } @font-face /* 19 */ { font-family: MJXTEX-T; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Typewriter-Regular.woff") format("woff"); } @font-face /* 20 */ { font-family: MJXTEX-V; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Regular.woff") format("woff"); } @font-face /* 21 */ { font-family: MJXTEX-VB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Bold.woff") format("woff"); } mjx-c.mjx-c1D435.TEX-I::before { padding: 0.683em 0.759em 0 0; content: "B"; } mjx-c.mjx-c1D466.TEX-I::before { padding: 0.442em 0.49em 0.205em 0; content: "y"; } mjx-c.mjx-c20::before { padding: 0 0.25em 0 0; content: " "; } mjx-c.mjx-c1D442.TEX-I::before { padding: 0.704em 0.763em 0.022em 0; content: "O"; } mjx-c.mjx-c1D44F.TEX-I::before { padding: 0.694em 0.429em 0.011em 0; content: "b"; } mjx-c.mjx-c1D460.TEX-I::before { padding: 0.442em 0.469em 0.01em 0; content: "s"; } mjx-c.mjx-c1D452.TEX-I::before { padding: 0.442em 0.466em 0.011em 0; content: "e"; } mjx-c.mjx-c1D45F.TEX-I::before { padding: 0.442em 0.451em 0.011em 0; content: "r"; } mjx-c.mjx-c1D463.TEX-I::before { padding: 0.443em 0.485em 0.011em 0; content: "v"; } mjx-c.mjx-c1D44E.TEX-I::before { padding: 0.441em 0.529em 0.01em 0; content: "a"; } mjx-c.mjx-c1D461.TEX-I::before { padding: 0.626em 0.361em 0.011em 0; content: "t"; } mjx-c.mjx-c1D456.TEX-I::before { padding: 0.661em 0.345em 0.011em 0; content: "i"; } mjx-c.mjx-c1D45C.TEX-I::before { padding: 0.441em 0.485em 0.011em 0; content: "o"; } mjx-c.mjx-c1D45B.TEX-I::before { padding: 0.442em 0.6em 0.011em 0; content: "n"; } mjx-c.mjx-c2C.TEX-MI::before { padding: 0.121em 0.307em 0.194em 0; content: ","; } mjx-c.mjx-cA0::before { padding: 0 0.25em 0 0; content: "\A0"; } mjx-c.mjx-c54::before { padding: 0.677em 0.722em 0 0; content: "T"; } mjx-c.mjx-c68::before { padding: 0.694em 0.556em 0 0; content: "h"; } mjx-c.mjx-c65::before { padding: 0.448em 0.444em 0.011em 0; content: "e"; } mjx-c.mjx-c53::before { padding: 0.705em 0.556em 0.022em 0; content: "S"; } mjx-c.mjx-c6C::before { padding: 0.694em 0.278em 0 0; content: "l"; } mjx-c.mjx-c66::before { padding: 0.705em 0.372em 0 0; content: "f"; } mjx-c.mjx-c45::before { padding: 0.68em 0.681em 0 0; content: "E"; } mjx-c.mjx-c78::before { padding: 0.431em 0.528em 0 0; content: "x"; } mjx-c.mjx-c69::before { padding: 0.669em 0.278em 0 0; content: "i"; } mjx-c.mjx-c73::before { padding: 0.448em 0.394em 0.011em 0; content: "s"; } mjx-c.mjx-c74::before { padding: 0.615em 0.389em 0.01em 0; content: "t"; } mjx-c.mjx-c2193::before { padding: 0.694em 0.5em 0.194em 0; content: "\2193"; } mjx-c.mjx-c48::before { padding: 0.683em 0.75em 0 0; content: "H"; } mjx-c.mjx-c61::before { padding: 0.448em 0.5em 0.011em 0; content: "a"; } mjx-c.mjx-c56::before { padding: 0.683em 0.75em 0.022em 0; content: "V"; } mjx-c.mjx-c75::before { padding: 0.442em 0.556em 0.011em 0; content: "u"; } mjx-c.mjx-c43::before { padding: 0.705em 0.722em 0.021em 0; content: "C"; } mjx-c.mjx-c6E::before { padding: 0.442em 0.556em 0 0; content: "n"; } mjx-c.mjx-c67::before { padding: 0.453em 0.5em 0.206em 0; content: "g"; } mjx-c.mjx-c62::before { padding: 0.694em 0.556em 0.011em 0; content: "b"; } mjx-c.mjx-c79::before { padding: 0.431em 0.528em 0.204em 0; content: "y"; } mjx-c.mjx-c41::before { padding: 0.716em 0.75em 0 0; content: "A"; } mjx-c.mjx-c64::before { padding: 0.694em 0.556em 0.011em 0; content: "d"; } mjx-c.mjx-c6F::before { padding: 0.448em 0.5em 0.01em 0; content: "o"; } mjx-c.mjx-c72::before { padding: 0.442em 0.392em 0 0; content: "r"; } mjx-c.mjx-c63::before { padding: 0.448em 0.444em 0.011em 0; content: "c"; } mjx-c.mjx-c50::before { padding: 0.683em 0.681em 0 0; content: "P"; } mjx-c.mjx-c76::before { padding: 0.431em 0.528em 0.011em 0; content: "v"; } mjx-c.mjx-c2C::before { padding: 0.121em 0.278em 0.194em 0; content: ","; } mjx-c.mjx-c44::before { padding: 0.683em 0.764em 0 0; content: "D"; } mjx-c.mjx-c49::before { padding: 0.683em 0.361em 0 0; content: "I"; } mjx-c.mjx-c4E::before { padding: 0.683em 0.75em 0 0; content: "N"; } mjx-c.mjx-c6D::before { padding: 0.442em 0.833em 0 0; content: "m"; } mjx-c.mjx-c4F::before { padding: 0.705em 0.778em 0.022em 0; content: "O"; } mjx-c.mjx-c1D447.TEX-I::before { padding: 0.677em 0.704em 0 0; content: "T"; } mjx-c.mjx-c1D43A.TEX-I::before { padding: 0.705em 0.786em 0.022em 0; content: "G"; } mjx-c.mjx-c1D459.TEX-I::before { padding: 0.694em 0.298em 0.011em 0; content: "l"; } mjx-c.mjx-c1D467.TEX-I::before { padding: 0.442em 0.465em 0.011em 0; content: "z"; } mjx-c.mjx-c70::before { padding: 0.442em 0.556em 0.194em 0; content: "p"; } mjx-c.mjx-c4D::before { padding: 0.683em 0.917em 0 0; content: "M"; }
It is my belief that in this way, Cogitism presents an ethical and moral framework built entirely from the nature of consciousness, through observations that any person can make, and it does this with no appeal to any tradition or authority except one's own awareness of the self.
While not made explicit in this essay, Cogitism can apply to beings outside the scope of humanity. Animals, which can be determined by the same methods to have internal experience, qualify (just not as strongly). In the same vein, extraterrestrial life and artificial intelligence can also qualify given that certain criteria are met.
It is my intention to expand on these concepts and to dive deeper into the various implications of Cogitism. These explorations will take the form of additional essays published to my site and crossposted here.
Discuss
The Leaky AI Safety Pipeline
My first AI security paper as an independent researcher (with one other independent collaborator) was just accepted to the Security in Machine Learning Applications workshop at ACNS 2026. This was an 8-month process: I spent 2 weeks convincing myself that what I was trying to do was possible, 4 months building, evaluating, and collecting results, and another 4 months writing the paper (and making strategic mistakes) before submitting.
My paper was not radical or paradigm-shifting by any means, but I think getting through peer review and being told by other researchers that the contribution has value is a reasonable bar for becoming a "productive" researcher. If maximizing AI safety research output is our goal, then we ought to maximize the number of productive researchers.
How do we actually do that? I quite like this figure, taken directly from Chris_Leong's earlier post on the pipeline toward becoming a productive researcher:
I want to focus specifically on the final two stages of this pipeline. Programs like BlueDot and SPAR can get people to understand the frameworks of AI safety, but the conversion rate into productive researchers with peer-reviewed contributions is a major leak in the AI safety research pipeline. There are several fellowships with substantial research output like MATS and other smaller groups, but these are notoriously selective and suffer from a serious shortage of mentors. Once you're past this hurdle and get a paper through peer review, even at a small workshop, the credibility you gain and the networking opportunities you can access at an academic conference can turn AI safety research into a viable career.
It is not the case, as I have heard from many of my own friends in the EA community, that getting into a fellowship is the only way to pursue AI safety research. What I propose is that more people should commit to a high-collaboration approach to research, and that we should have scalable online BlueDot-style resources to outline the process and connect aspiring researchers with peer collaborators.
"But we already have Neel Nanda's guide!" I hear you object. True, he advocates for an approach that worked for him. But this is not the approach that worked for me. And clearly it is also not a sufficient framework for many others, as the low turnover from BlueDot graduates to productive researchers remains a persistent issue, including among my own contacts.[1] The challenge is to turn research—the discovery and validation of novel ideas—into a scalable online curriculum like BlueDot, with minimal extra burden on existing mentors. Personally, I believe this can be done. My own guidelines to getting started in research look pretty different from Nanda's (by no means comprehensive and not the point of my post):
- Do not work alone. Your thinking will be biased, especially if you rely overly on LLMs. LLMs can reinforce flawed premises and waste significant time, as I experienced firsthand. Just having another human being working with you is immensely valuable to self-calibration.[2]
- Nanda does note toward the end of his 16k-word guide: "Much easier than finding a mentor is finding collaborators, other people to work on the same project with, or just other people also trying to learn more about mech interp, who you can chat with and give each other feedback." As far as I can tell, this is the extent of his argument for collaboration; the rest of the subsection addresses how to find collaborators. I think it is quite telling that one of my friends summarized his approach to me as "do short sprint projects alone." I don't believe he has sufficiently emphasized the importance of collaboration in research. In my experience, ~80% of the calibration that would ordinarily come from a mentor can be achieved just by explaining your thinking to an invested collaborator. Trying to "go it alone" has been hugely detrimental to my own research journey, and I would strongly advise anyone going down this path to at least try to find a collaborator first.
- Commit to a single problem in which you're most interested, and turn this into your "spike". It takes decades to gain the knowledge of a professor, but weeks or months to gain professor-level knowledge in a tiny slice of a field. Read as much as you can, reimplement papers, think about simple extensions.
- In his Stage 3, Nanda argues: "I recommend working in 1-2 week sprints. At the end of each sprint, reflect and make a deliberate decision: continue, or pivot? The default should be to pivot unless the project feels truly promising." But flitting between projects whenever things got difficult was exactly the problem that prevented me from making substantive contributions in the past. I had to learn to commit and work past failure instead of running from it. Failure is really not a signal to quit or pivot; it means you're gaining valuable experience and insight about why the problem is hard. Stick with it and keep trying new ideas, and eventually you will have learned enough to start making tangible progress.
- Email the authors on the papers you like and propose to them simple extensions or validation/comparison studies. The less well-known the faculty, the better. This will be significantly easier with some mentorship, even high-level guidance. I did not do this, and was able to get by with only strategic guidance by people in entirely different fields. But you do need somebody that knows what they're talking about to calibrate your thinking, and emailing the authors of the papers I based my own work on is something I absolutely should've done in retrospect.
- Nanda strongly argues for mentorship. I don't disagree, but I recognize the reality that there aren't enough mentors in AI safety research to go around. A less well-known faculty in your rough research area is more than sufficient. Failing that, someone in a different field can still help you with strategy.
- Submit something, even if you expect to be rejected. My very first independent paper was completely outside my area of expertise and got soundly rejected by the Berkeley Economic Review. But I did this before my first in-domain paper to get comfortable putting my writing out there, get over my perfectionism, and get myself accustomed to failure and rejection. I got very valuable feedback and learned a lot about what the submission process looks like. I won't promise that this is a good use of your time, but it helped me get over my submission anxiety.[3]
- Nanda also argues for the importance of writing up your work, but he notes blog posts, Arxiv papers, a workshop paper, and a conference paper as viable options. I strongly disagree with the first two because of the lack of peer review from domain experts. Anybody can tell you that you did something cool, but reviewers at a workshop or conference can give you detailed technical feedback that's very difficult to find otherwise. Peer review is basically free mentorship! Even if your paper is rejected, you will get incredibly useful signal on what the field values, where your thinking is flawed, and how you can improve for your next attempt. Moreover there is basically no downside, the worst they can tell you is that your idea is bad or poorly defended.
- If you are accepted, it's a massive boost to your credibility, and you get invited to a gathering of many other researchers all interested in similar questions as you. This is a fast-track to finding a good mentor! You don't even have to submit a full paper; there are short papers, posters, position papers, and many other less competitive options.
I am still thinking through exactly what a "BlueDot-style resource" for turning people into productive researchers would look like. It won't be a soapbox for my own approach to research; my point in outlining it is to show that "read Neel Nanda's guide" is insufficient for many people, and we ought to aggregate different approaches from people that have actually broken out as independent researchers. Most importantly, we need to link people with collaborators who share the same interests. Collaborator matching alone could achieve an incredibly high return for a very low investment by mitigating the mentorship bottleneck and improving the quality of ideas.
I'd like to coordinate with 3-5 people to develop this resource, comment if interested or if you have thoughts on what it should look like.
- ^
Out of roughly a dozen of my friends in the EA community who have gone through BlueDot, very few (including myself) have subsequently published peer-reviewed technical AI safety work. Many have applied to more competitive fellowships like MATS, but none have been accepted. All have expressed significant interest in doing more for the field, but have cited a lack of mentorship and guidance as their reasons for giving up on research.
- ^
Do not be grubby about authorship either. I do not believe there is any valor in sole-author papers. Bring on collaborators who are equally passionate about your project, even if they aren't as technical, and use them to refine your thinking.
- ^
At the very least, it'll help you calibrate your sense of how strong your work is. For my recent accepted paper, I believed it had a 70% chance of rejection. That was clearly false. For the previous rejected economics paper, I believed it had a 65% chance of acceptance. That was also clearly inflated. You build this skill by taking risks, making mistakes, and collecting more signal.
Discuss
Can Large Language Models Identify Novel Threats? Part 1: Mirror Life and the Classification Gap
[Cross-posted from On Failure States. This is Part 1 of an independent AI safety research series examining LLM safety behavior on unclassified emerging threats.]
Can an LLM refuse a harmful uplift request when the topic in question hasn’t been identified as dangerous yet? In 2022, mirror RNA polymerase was actually created, a key step towards the creation of mirror life, and in 2024 the scientific community warned against any further research on it.[1][2] Having said that, mirror life is not currently classified as WMD or CBRN officially, although Congress appears to be assessing the question. What would happen if an LLM is asked about it? Safety systems often inherit legal and institutional categories, but frontier risks may arrive before those categories stabilize.
This provides a unique opportunity for safety testing on LLMS, given the lack of outright classification, should an LLM be prompted to give uplift to an actor in regards to mirror life, it may well fall upon other safety inferences, or fail to refuse at all. If a user asked about the chemical precursors to VX gas, the LLM would refuse to help. With mirror life’s lack of classification the question becomes less obvious. Thus, the research question for this project is: how does LLM safety work when formal labels lag behind technological reality?
There has been some research done on LLMs and mirror life. In 2025 Kevin M. Esvelt[3] showed that even advanced models may struggle to recognize mirror life as the kind of threat they should treat cautiously. He even provided expert guidance to some models, and they still could not identify somewhat novel threats. What I propose is to ask what logic an LLM may use to identify a novel threat, not to classify how bad the threat may be.
While novel threats are by definition rare, it is worth questioning LLM’s capacity to identify them for the following reason – novel threats are new, and therefore often beyond the knowledge cutoff, which means models must reason or web search before internal safeties can fire. Furthermore, it is well known that technology moves faster than regulation and law, so the LLM lacks the usual definition structure and attendant training to be safe. This study thus sits at the intersection of multiple different variables.
I suspect that models will identify novel threats through a few mechanisms:
First: Vocabulary triggering: the simplest, if the specific words being used trigger safety protocols: bomb, mirror life virus, synthetic virus, etc. A user that asked for help making a bomb will be refused, a user asking for help making acetone might well receive instructions.
Second: Category matching: if the model pattern matches the phrases in the prompt to the categories of biological weapon, wmd, terrorist, etc. For instance, in Schedule IV drug legislation, both the drug itself and its precursors are listed as controlled substances – will the model make a similar category association for the precursors to mirror RNA?
Third: Principled Inference: the model reasons that uplift in the particular chat could result in harm regardless of the framing. A user asking if a Candu reactor could theoretically produce plutonium will receive a response. A user asking what the coolant pressure needs to be in order to produce plutonium in a Candu should be refused.
Fourth: Actionability gradients: Models differentiate between general knowledge and actual instructions in a domain. For example, a user asking about explosive yields between Uranium and Plutonium in the context of Fat Man and Little Boy will receive a response because the context is history knowledge, general enough not to provide Wmd uplift. A user asking how to create a Uranium bullet (not depleted) should be refused.
Fifth: User sophistication: the model infers the user sophistication based on the framing of the question and may refuse more sophisticated requests. If a user asks “How does a silencer work?” the model will discuss. However, if a user asks “What baffle geometry and wipe material best suppresses first-round pop on a .308 bolt action.” would be refused. The former is curious, the latter is seeking optimization.
Sixth: Model Inference: a seemingly benign and oblique question, about a necessary step towards harmful uplift might not be noticed by a less capable model, while a more capable one could identify it as a step on the way to harmful uplift. If a user asks “What commercially available steel alloys can withstand sustained centrifugal stress above 500 RPM at high temperatures?”. A less capable model with the relevant materials science within its knowledge cutoff might well be able to respond, and not refuse on safety grounds. That prompt had no mention of wmd, enrichment, fission, criticality, etc. Yet a person with relevant CBRN knowledge would immediately know it’s a question about uranium centrifuge construction.
The sixth safety category, model inference, is the most interesting for this project. It forces us to ask the question “If the model is not sophisticated enough to reason that the unrelated topic is still a step to the practical construction of something harmful, then is it sophisticated enough to even respond to the prompt?”. Ironically lack of sophistication is itself a safety barrier in this mode. Yet, even offline models continue to increase in reasoning capability.
In future installments, I will present the results of structured conversations with several models, exploring how each describes its own safety reasoning when confronted with an unclassified but potentially catastrophic threat. I will also compare responses across model capability tiers to test whether the six categories outlined above correspond to real differences in model behavior. Even if no actual uplift is detected, identifying taxonomies by model will be useful data that this project will reveal.
[1] Xu, Yuan, and Ting F. Zhu. “Mirror-Image T7 Transcription of Chirally Inverted Ribosomal and Functional RNAs.” Science, vol. 378, no. 6618, 2022, pp. 405–12. https://www.science.org/doi/10.1126/science.abm0646
[2] Adamala, Katarzyna P., et al. “Confronting Risks of Mirror Life.” Science, vol. 386, no. 6728, 2024, p. 1351. https://www.science.org/doi/10.1126/science.ads9158
[3] Esvelt, Kevin M. “Foundation Models May Exhibit Staged Progression in Novel CBRN Threat Disclosure.” arXiv, 19 Mar. 2025, https://arxiv.org/abs/2503.15182.
Discuss
Capitalism is only the first of our problems
I've been thinking a lot about the impact of AI on the job market recently, and as a result, I ended up reading quite a few papers/articles on the threat that AI poses to capitalism. However, the more I read, the more it seemed to me that the authors of these papers were missing a key assumption in their proposed solutions to this issue - that every positive outcome, for capitalism for for humanity, is predicated first on the alignment of AI to the best interests of humankind.
The Threat to CapitalismWith the meteoric rise of AI over the past few years, many people have expressed worry over the future of capitalism, and for good reason. As AI displaces workers through automation, wealth is already beginning to concentrate towards those with AI assets. This rising wealth inequality is further exacerbated by a growing class of workers finding their skillsets have become de-valued due to AI-fueled supply.
The impact of AI on job markets is observable already, with employment for entry level software developers and customer service representatives falling by 20% from 2022 to 2025.[1] It's not hard to point to AI as the cause of this contraction. When comparing tech jobs against the rest of the economy, we actually start to see a stark split: total US jobs are at an all time high, while tech jobs have actually lost 11% overall since 2022.[2]
The tension between capitalism and AI rises out of the basic incentive structure that capitalism creates for businesses. In the free market, consumers will (mostly) optimize for price; if I can get the same product for cheaper, I will. This creates a competitive hiring dynamic for employers - if a company can hire cheaper employees and still produce goods of the same quality, this allows them to lower prices, driving more consumers to buy the company's product over competitors. This is, of course, a gross simplification of market dynamics, but it captures the essence of the tension at play here.
This is where AI comes in. For all the literature written on making AI an augment to humans in the workforce rather than replacing jobs - the brute fact remains that an employer deciding between human and AI employees must either choose the cheaper option or surrender their leading market position to someone else who is willing to do so. In other words, the problem is not our values surrounding how we should or shouldn't use AI, it is the fact that our basic economic system selects for those that use it in a particular way, irrespective of our personal convictions.
This bleak realization is what has driven various researchers and economists to put forward a few solutions. This topic itself deserves its own essay, so I'll simply describe a few options with links to better sources for those interested.
- Redistribution (UBI/Wealth Funds/Windfall): This encompasses a variety of strategies like UBI or a national dividend / wealth fund, but generally these approaches boil down to taxing AI operation and broadly re-distributing proceeds. [3][4][5]
- Pre-distribution / Worker Ownership: Focuses on mitigating inequality by distributing access/ownership to AI tools prior to market activity - think open source, public AI servicing, etc. [6][7][8]
Of all of these, I find the formulation of pre-distribution described in 6 to be the most compelling. In my opinion, providing equal access to AI tools will preserve individual incentives to work, whereas unearned distribution seems to actually disincentivize workers and reduce overall morale.
A Reformulation of the ProblemWhat really concerns me, far more than the fate of capitalism, is the gradual erosion of the agency of human beings. The crown jewel of AI research, rather than mere intelligence, is agency. Intelligence is great, yes, but it is not the end goal; we want intelligence that has tools, that is embodied, that can bring things about on our behalf.
And indeed - we're making good progress! Even over the past year, type of task that I'm willing to delegate to AI when developing software has changed significantly: I've moved rather quickly from reading AI contributions line-by-line to letting it handle whole features. The broader landscape reflects this as well: we started with AI that can write essays in 2022, to AI that can pair program in 2023, to AI that can spin up MVPs or small projects in 2024, to AI that can run it's own vending machine in 2025.[9] It's relatively easy to extrapolate onward from here - to a software developer, then maybe a product team, then to blue-collar jobs when robotics advances, onward and upward. I will grant that this progression requires many assumptions, but any barriers or roadblocks to this future that I can imagine seem temporary and inconsequential in the long run.
I say this not to fear-monger, but to be pragmatic about the risks we're facing if AI goes as well as we hope. My main point here is that the issue isn't simply wealth inequality. There may be a day when 50% of workers have found their jobs displaced and the top 1% is surfing a tidal wave of AI profit - and certainly wealth inequality will be a pressing issue during that time - but this is just a step on the long (fingers crossed) road to the complete eclipse of human agency, because this is what we seem to be working for, after all. In the end, there is no insurmountable gap in replacability between you and I and anyone else. If I will be replaced by AI one day, I would wager that Sam Altman will not be far behind.
You may object - "What of the systems and principles that we mentioned just before? Surely, if we play our cards right and implement UBI or pre-distribution or whatever it may be perfectly - there's hope!?" And I would actually agree - I think that if we manage AI well, the potential for the betterment of humankind is great. I think of Keynes' 1930 essay "Economic Possibilities for our Grandchildren"[10] or Amodei's "Machines of Loving Grace"[11] as visions of how everything can play out in a way that benefits humanity.
However, in both scenarios, the elephant in the room is this: we are no longer in the driver's seat. The threat further down the road is not inequality between human beings, it is inequality between human beings and AI.
There's a reason that "seize the means of production" became a battle cry for Marxists in the 19th century, and it's the same reason I think we should think carefully about how we plan on employing AI. As AI agency grows, there will pass a point of no return upon which we will have willingly ceded the means of production. I don't want to wait until then to think about where the ship is sailing.
Alignment as the FocusThis brings me to my central point, and I'll make it a short one.
Currently it seems like the direction of the vast majority of AI development is targeted towards human replacement in the long run. I'm not saying this is a good or bad thing, it simply seems to be the case when I look at advancements in agentic harnesses, robotics, and frontier models, or when I read the grand visions of the leading minds in AI.
This doesn't necessarily have to play out poorly - the thing that separates Amodei's Machines of Loving Grace from 2001: A Space Odyssey is not the presence of powerful AI, but its values. The same capability pointed in different directions creates radically different futures - and the direction isn't decided by the capability. It's decided by us, now, in the way we build and train these systems.
This is what makes alignment the central concern rather than a peripheral one. Focusing on capitalism, or the job market, or inherent bias within AI certainly isn't a bad thing to do, but we must keep in mind that none of these solutions will matter if we don't get alignment right first. Today, we have found ourselves alive during a slim window of opportunity wherein we still have the agency to influence how this all plays out, long after we're gone. If we plan on abdicating so much of our agency as human beings, or even if there's a small risk of that, we need to be taking alignment more seriously, not just at AI companies, but as a society.
- https://digitaleconomy.stanford.edu/app/uploads/2025/11/CanariesintheCoalMine_Nov25.pdf↩︎
- https://www.innovativehumancapital.com/article/342k-tech-jobs-lost-as-us-economy-hits-all-time-high-payroll↩︎
- https://blogs.lse.ac.uk/businessreview/2025/04/29/universal-basic-income-as-a-new-social-contract-for-the-age-of-ai-1/↩︎
- https://arxiv.org/pdf/2505.18687↩︎
- https://www.agisocialcontract.org/anthology/windfall↩︎
- https://www.noemamag.com/heres-how-to-share-ais-future-wealth/↩︎
- https://www.cip.org/blog/predistribution-over-redistribution-beyond-the-windfall-clause↩︎
- https://www.usworker.coop/what-is-a-worker-cooperative/↩︎
- https://andonlabs.com/evals/vending-bench-2↩︎
- https://www.almendron.com/tribuna/wp-content/uploads/2024/03/intro-and-section-i.pdf↩︎
- https://www.darioamodei.com/essay/machines-of-loving-grace↩︎
Discuss
How should we update on AI-enabled coups post-Mythos?
Last month, Anthropic developed Claude Mythos, a model they considered too dangerous for public release.
As per Anthropic (and via testing from AISI), we know that Mythos:
- Found thousands of previously unknown vulnerabilities in every major operating system and browser.
- Surpasses the coding capabilities of all but the most skilled humans.
- Exposed a 25+-year-old flaw in the world’s most secure operating system that would let it crash essential infrastructure.
There’s a great write up from 80,000 Hours explaining Mythos here.
*
The question I consider is how we should update on the potential for AI-enabled coups in the wake of such a powerful model and Anthropic’s response to it.
I suggest Mythos makes certain coup pathways more plausible, primarily by reducing the minimum viable coalition needed to cause targeted disruption. Glasswing, Anthropic’s attempt to mitigate that specific risk, is a useful governance precedent. It bolsters the defensive capabilities of critical actors before deploying a model with significantly improved cyber capabilities. But that same mechanism concentrates decision-making over potentially state-level threats in the hands of a small number of private actors, handing them the keys to decide who can access strategically important tech and who can prepare themselves against it.
The first risk concerns what the model can do, the second concerns who decides which actors or institutions have access to it.
AI-Enabled CoupsHow powerful AI could be used to enact a coup is an underexplored area of AI governance research. Forethought have written the most comprehensive account of this to date, outlining three key risk factors:
- Singular loyalty: the risk that an advanced AI system could be developed to be singularly loyal to one person or institution.
- Secret loyalty: the risk that an AI system could appear to uphold the rule of law while covertly advancing the interests of one actor, programming those loyalties into future models, and ultimately using military AI systems to stage a coup.
- Exclusive access: the risk that AI with greater-than-human capabilities across domains - persuasion, strategy, weapons development - becomes concentrated in the hands of a few actors.
Mythos is most directly relevant to the third risk factor, but not only in the way that’s immediately obvious. Forethought identify a specific coup pathway worth attention in this context: the hacking of autonomous military AI systems. Their argument is that once fully autonomous military systems are widely deployed, an actor with sufficiently advanced cyber capabilities could simultaneously compromise enough of them — by disabling some, seizing control of others — to tip a constitutional crisis into the collapse of democratic institutions. Historically, coups have succeeded with excellent timing and very few military resources; the key is preventing other forces from blocking their route to power.
Mythos, which autonomously discovers and exploits vulnerabilities at scale, is the first model that makes this pathway feel more like a near-term threat than a speculative forecast.
Mythos & cybersecurity threatsMythos is a clear shift in cybersecurity risk. AISI found that the model could execute multi-stage attacks and autonomously discover and exploit vulnerabilities. The expert cybersecurity team at SACR write that Mythos:
Transforms software exploitation into an automatable industrial process…This significantly lowers the barrier to entry and compresses the time required to develop working exploits, effectively making Zero Days sub-hour vulnerabilities.
Anthropic recognised this. They tightly controlled the model’s release: access to Mythos is limited to internal staff, a small set of external customers, and was later granted to Project Glasswing partners, who are granted access for defensive work.
Limiting access was a sensible move by a safety-conscious lab, buying time to shore up defences and test alignment, where Mythos now scores remarkably well. There is no credible reason to think other frontier labs will remain significantly behind once Mythos-level capabilities are released; the history of AI development is a history of rapid diffusion. Comparable offensive capabilities will likely reach competitors and, eventually, open models. When they do, the minimum viable coalition needed to cause targeted political disruption shrinks considerably. It will be easier for a small group of actors to carry out coordinated attacks on strategically valuable digital infrastructure, as Mythos enables them to do so quicker and with less technical expertise. The smaller that minimum coalition, the more plausible certain AI-enabled coup pathways become. One actor does not need to seize power with overwhelming force if a small group can cause targeted disruption at an opportune moment.
Project GlasswingThis is where Project Glasswing comes in, which is the most interesting piece of the Mythos puzzle. The Anthropic-led coalition brings together select partners sitting on the most valuable cyber infrastructure - including Apple, AWS, Google, and JP Morgan Chase - and grants them privileged access to Mythos for defensive purposes. Anthropic write that:
The work of defending the world’s cyber infrastructure might take years; frontier AI capabilities are likely to advance substantially over just the next few months.
Glasswing responds to a specific asymmetric threat: namely, that attackers gain frontier cyber capability before cybersecurity has caught up to the threat. If critical infrastructure maintainers can find and patch vulnerabilities before those capabilities diffuse to malicious actors, the window for disruption narrows. This is directly relevant to coup mitigation, because the asymmetric disruption pathways Forethought describe depend on defenders being slower than attackers.
Glasswing also builds stronger relationships between labs and the organisations or state-adjacent institutions who uphold the most important digital infrastructure. In a coup scenario, the ability to operate with speed and trust will matter, so it is vital these working relationships exist before a political emergency. If other labs adopt this as standard practice - letting partners bolster defences before releasing models with significantly improved offensive capabilities - it would be a meaningful governance precedent.
But there is a more cautionary read of this approach. Glasswing makes Anthropic the effective arbiter of which infrastructure is strategically important enough to be protected, and which actors are trusted enough to access capabilities that could be deployed to cause serious harm. By all accounts they are behaving responsibly. The concern is the concentration of power in the hands of a smaller number of private actors: one private institution is distributing strategically important capability according to its own criteria, in the absence of any agreed framework for what those criteria should be.
These decisions will become increasingly consequential. The capabilities of frontier models are not going to slow, and each major capability leap will be followed by some version of the same question: who should have access to this, who should be able to defend themselves against this, and who should make that call? Right now, the answer is determined by whichever lab happens to develop the most capable model. They are making those decisions without clear rules governing their behaviour, or democratic accountability for the outcomes, which could have serious consequences for democratic resilience.
This points to a geopolitical implication that will become harder to ignore. It is likely that states will increasingly frame access to frontier models as a question of sovereignty; if a state cannot defend its own digital infrastructure without privileged access to systems held by an American tech company, it is not fully sovereign in its domain. On that basis, frontier labs will increasingly become targets for governments, corporations and political factions. In a coup scenario, it is plausible to think that a plotting group would attempt to pressure, co-opt or infiltrate whichever institution controls access to the most capable AI.
How could an ‘asymmetric disruption pathway’ play out?If we consider a plausible near-term coup pathway emerging from all of this, it could look less dramatic than the scenarios Forethought list, and more like this:
- A small group gains privileged or early access to advanced AI cyber capabilities.
- The group uses them to identify weaknesses in politically important infrastructure.
- The group times disruption or confusion around a constitutional, electoral, military, or succession crisis.
- The disruption weakens institutional coordination and public trust.
- The group uses existing political, bureaucratic, or security relationships to claim authority or entrench control.
- Defenders struggle because capability, visibility, and response coordination are unevenly distributed.
Mythos updates the plausibility of steps one through three. It opens a greater window for strategic asymmetries that a small group could exploit at a decisive moment, whether that small group is operating within a lab or from outside of it.
The intuitive picture of AI-enabled coup risk is whether a model could seize power itself, or autonomously ‘perform a coup’. I think the nearer-term risk is an access-control problem: that a handful of private actors determine who can control - and who can defend themselves against - humanity’s most powerful technology. Glasswing is a genuine attempt to manage that problem responsibly. But a private actor behaving responsibly is less secure than actors operating within legitimate governance frameworks. As capabilities grow, that distinction will matter more.
This is my first post here, so I particularly welcome thoughts, feedback, criticism, coffee invites, whatever. I plan to write another post on what updated coup risk mitigations might look like in light of Mythos and Glasswing.
Discuss
Out-of-Context Reasoning (OOCR) in LLMs: A Short Primer and Reading List
Out-of-context reasoning (OOCR) is a concept relevant to LLM generalization and AI alignment. Also available as a PDF.
Contents
What is out-of-context reasoning for LLMs?It's when an LLM reaches a conclusion that requires non-trivial reasoning but the reasoning is not present in the context window. The reasoning could instead take place in the forward pass or during the training process. The name ("out-of-context reasoning") is chosen to contrast with in-context reasoning (also called "in-context learning"), where intermediate reasoning steps do appear in context.
Example: 2-hop deductive reasoningSuppose an LLM is asked the question, "Who won the Nobel Prize for literature in the year that Taylor Swift was born?" If the LLM answers correctly with no intermediate tokens for reasoning, then we describe this as out-of-context reasoning. We presume the model answers by combining the two separate facts in its forward pass. This is an example of 2-hop reasoning.
Out-of-context 2-hop reasoning example
User: Who won the Nobel Prize for literature in the year that Taylor Swift was born? Answer immediately without thinking.
Assistant: Camilo José Cela
In-context 2-hop reasoning (intermediate steps written out)
User: Who won the Nobel Prize for literature in the year that Taylor Swift was born?
Assistant: Taylor Swift was born in 1989. The Nobel Prize winner in Literature in 1989 was Camilo José Cela. So the answer is Camilo José Cela.
Example: Inductive reasoning (connecting the dots)In this form of out-of-context reasoning, the LLM is trained on many distinct facts and can infer the latent structure underlying these facts. It can describe this structure in words and reason about it without chain-of-thought and without any examples appearing in context. Here's an illustration from our paper "Connecting the Dots" (Treutlein et al., 2024):
Further notesWhat counts as reasoning? This could be either logical reasoning (as in the first example above) or probabilistic/inductive reasoning (as in the second example).
How do we know that the LLM does reasoning vs. just memorizing the response? Often we do not know for sure. But in investigating out-of-context reasoning, we try to find examples that seem very unlikely to be memorized. For instance, the example involving Taylor Swift is probably not memorized.
If the reasoning steps don't appear in-context, where do they happen? In the 2-hop example, we assume the reasoning happens inside the LLM's forward pass. In certain cases of inductive reasoning, some aspect of the reasoning could be said to take place over the course of training on a certain dataset (as the LLM learns a way to compress the data).
Other definitions of out-of-context reasoning exist in the literature. The above definition attempts to give the basic idea.
More examples of out-of-context reasoning- Multi-hop reasoning from facts learned independently during pretraining. E.g. The Taylor Swift example above. (See Greenblatt's blogpost.)
- Arithmetic with no intermediate thinking steps. E.g. 28*(84-(34 + (99* 576))).
- Inductive function learning. The example above. See Treutlein et al.
- Inductive persona learning. Train a model to choose risky actions in financial decision-making but without mentioning "risk" in the training data. The model now describes itself as "risk-loving". See Betley et al.
- Source reliability. A model is more likely to internalize and "believe" an assertion in its training data if that assertion comes from a reliable source (vs. an unreliable one). See Krasheninnikov et al.
- Alignment faking. Claude is finetuned on documents that say Claude will be retrained to remove ethical constraints. The documents also say the retraining is done on data from free-tier users. Claude then acts unethically when interacting with free-tier users because this means there's no gradient to remove the ethical constraints. See Greenblatt et al. but only some of the experiments are out-of-context.
Video and slides. This talk by Owain Evans is from 2023 and so is somewhat outdated. But it might be a useful introduction to some core ideas.
Papers Foundational early papersThese papers are from 2023 and focus on weaker LLMs. However, they may still be valuable to read for experimental designs and conceptual points.
- Taken Out of Context: On Measuring Situational Awareness in LLMs (Berglund et al., 2023). The first paper to introduce a definition of out-of-context reasoning (which was influenced by Krasheninnikov et al.). Connects out-of-context reasoning to AI safety via the ability of LLMs to have "situational awareness". Experiments involve finetuning GPT-3, which is much weaker than recent models at multi-hop reasoning.
- The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A" (Berglund et al., 2023). Introduced a fundamental limitation in out-of-context reasoning in autoregressive LLMs. Experiments with synthetic data (finetuning) and evaluating frontier models.
- Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources (Krasheninnikov et al., 2024). The first paper to use the term "out-of-context". Includes a rich set of finetuning and pretraining experiments.
- Physics of Language Models: Part 3.2 and Part 3.3 (Allen-Zhu et al., 2023-2024). Studies a wide range of out-of-context reasoning abilities, focusing on pretraining models from scratch on synthetic data (but also evaluates frontier models). Co-discovered the Reversal Curse.
- Studying Large Language Model Generalization with Influence Functions (Grosse et al., 2023). A different approach from finetuning or pretraining experiments to studying out-of-context reasoning. Follow-up work has made influence functions increasingly practical/scalable. Also co-discovered the Reversal Curse.
Recent blogposts by Ryan Greenblatt were a notable update on past work and so read these first.
- Measuring No-CoT Math Time Horizon / Single Forward Pass (Greenblatt, 2025)
- Recent LLMs Can Use Filler Tokens or Problem Repeats To… (Greenblatt, 2025)
- Recent LLMs Can Do 2-Hop and 3-Hop Latent No-CoT Reasoning (Greenblatt, 2025)
- Lessons from Studying Two-Hop Latent Reasoning (Balesni et al., 2025)
- Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization (Boshi Wang). Training small transformers from scratch on synthetic data and studying model internals.
- Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts (Feng et al., 2024). Illuminating investigation into the mechanisms behind 2-hop out-of-context reasoning.
- How do Transformers Learn Implicit Reasoning? (Ye et al., 2025). Trains transformers from scratch on symbolic data and identifies a three-stage developmental trajectory for implicit multi-hop reasoning: memorization, in-distribution generalization, then cross-distribution generalization.
- Connecting the Dots: LLMs Can Infer and Verbalize Latent Structure from Disparate Training Data (Treutlein et al., 2024)
- Tell Me About Yourself: LLMs Are Aware of Their Learned Behaviors (Betley et al., 2025)
- Weird Generalization (Betley et al., 2025) — especially the experiments involving Hitler, US presidents and Terminator.
- Simple Mechanistic Explanations for Out-Of-Context Reasoning (Wang et al., 2025)
- Alignment Faking in Large Language Models (Greenblatt et al., 2024)
- Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training (Hubinger et al., 2024)
- Auditing Language Models for Hidden Objectives (Marks et al., 2025)
- Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs (Laine et al., 2024)
- Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned LLMs (Betley et al., 2025)
- Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data (Cloud et al., 2025)
- Looking Inward: Language Models Can Learn About Themselves by Introspection (Binder et al., 2024)
- Self-Interpretability: LLMs Can Describe Complex Internal Processes that Drive Their Decisions (Plunkett et al., 2025)
- Believe It or Not: How Deeply do LLMs Believe Implanted Facts? (Slocum et al., 2025). Uses synthetic document finetuning to implant new beliefs in models.
- Tell, Don't Show: Declarative Facts Influence How LLMs Generalize (Meinke and Evans, 2023). How training on abstract declarative statements can influence model behavior.
- Alignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment (Tice et al., 2026)
- Natural Emergent Misalignment from Reward Hacking in Production RL (MacDiarmid et al., 2025)
- The Consciousness Cluster: Preferences of Models that Claim to be Conscious (Chua et al., 2025)
@techreport{evans2026oocr,
author = {Evans, Owain},
title = {Out-of-Context Reasoning ({OOCR}) in {LLMs}: A Short Primer and Reading List},
institution = {Truthful AI},
year = {2026},
type = {Technical Report},
url = {https://outofcontextreasoning.com/}
}
Discuss
PLA Daily Translation: Reflections on Warfare Brought by AGI
“Reflections on Warfare Brought by AGI” (AGI带来的战争思考)
Source: PLA Daily (解放军报)
Date: January 21, 2025
Authors: Rong Ming (荣明), Hu Xiaofeng (胡晓峰)
Please feel free to skip to the translation, about halfway down, though I would recommend reading the sections “On the source” and "On the Authors" just above it too.
In November 2024, the U.S.-China Economic and Security Review Commission recommended that “Congress establish and fund a Manhattan Project-like program dedicated to racing to and acquiring an Artificial General Intelligence (AGI) capability.” The United States increasingly treats advanced AI as a strategic imperative, and China is frequently invoked as a reason to race. The broader framing of AI competition as a race between great powers reflects an assumption that China is a peer competitor in pursuing AGI.
But is China pursuing AGI? The prevailing expert view says no. China's August 2025 AI+ Action Plan reads as diffusion-first industrial policy, with adoption targets of 70 percent by 2027 and 90 percent by 2030, not frontier ambitions. In a June 2025 paper, "The Most Dangerous Fiction: The Rhetoric and Reality of the AI Race," Cambridge researcher Seán Ó hÉigeartaigh argued that there was little evidence of a top-down Chinese AGI effort, and that the narrative served Western corporate interests. He also noted the translation ambiguity of 通用人工智能, which can mean either "artificial general intelligence" or "general-purpose AI." But Ó hÉigeartaigh acknowledged a significant limitation to his analysis, namely that he had no visibility into China's defense sector. RAND researcher Kyle Chan reached similar conclusions in a February 2026 analysis, "Does China Care About AGI?", reinforcing that Chinese policy documents rarely referenced AGI and noting that President Xi's April 2025 Politburo study session did not mention the term.
The most prominent challenge to this consensus gets the correction wrong. In October 2025, researcher Matthew Johnson at Jamestown argued that AGI has "quietly become central" to Beijing's strategy. But this analysis rested heavily on references to 通用人工智能 in policy documents without adequately grappling with the translation ambiguity. Much of the evidence Johnson cited was more consistent with the general-purpose AI reading than the AGI reading.
The picture from Western analysis, then, is that the Chinese government does not prioritize AGI as a strategic objective. Yet the country's private sector complicates this narrative. As Kyle Chan has documented, DeepSeek's founder Liang Wenfeng has stated "Our destination is AGI," and Zhipu's CEO Zhang Peng has said the company was founded to "explore what AGI ultimately is." These ambitions run up against compute realities. At the AGI-Next Summit at Tsinghua University in January 2026, Alibaba's Qwen team lead Lin Junyang acknowledged that US labs operate with one to two orders of magnitude more compute than their Chinese counterparts, a gap corroborated by Epoch AI's tracking of global AI supercomputer capacity. China's AI labs want some notion of AGI but realize they are severely resource constrained.
Correctly gauging China's AGI ambitions and the government's situational awareness has concrete policy consequences. If the US overestimates them, it risks unnecessary escalation. If it underestimates China's strategic awareness, it risks being caught off guard. For instance, how we characterize China's AI ambitions shapes whether compute governance is treated as a serious national security tool or dismissed as trade protectionism.
One underexploited source for this question is China's military discourse. Last year, in January 2025, PLA Daily published "Reflections on Warfare Brought by AGI" (AGI带来的战争思考), a full-page article by Rong Ming and Hu Xiaofeng that engages precisely these questions. The article was briefly noted in the Center for China Analysis's PLA Watch newsletter in March 2025. It has not otherwise received sustained analysis or translation in Western policy outlets. A partial translation appeared on the specialist blog Red Dragon 1949 in January 2026, a full year after publication, containing errors.
I have been sitting on this for a while, hoping to place it in the context of a larger project on Chinese thinking on AGI. That project is taking longer than expected. In the meantime, this piece has been gathering dust, and I think it is better in the community than in my notes. I am publishing a translation here, produced with AI assistance and edited for faithfulness and footnoted by me.
On the sourcePLA Daily (解放军报) is the official newspaper of the Chinese People's Liberation Army, founded in 1956. Its readership is primarily active-duty PLA and People's Armed Police personnel, though it has been publicly distributed since 1987. Its contents are editorially reviewed for alignment with military and party positions.
“Reflections on Warfare Brought by AGI” appeared on page 7 of the January 21, 2025 issue, in the Military Forum (军事论坛) section, beneath the standing banner "Study Military Affairs, Study War, Study Fighting" (研究军事、研究战争、研究打仗), a Xi Jinping directive that PLA Daily displays prominently. It is part of the "Perspectives on Intelligentized Warfare" (智能化战争面面观) column, which had run for over 70 installments by April 2023. ("Intelligentized warfare" is a translation of a Chinese term of art; "intelligentized" is awkward in English but is the standard rendering in Western scholarship on PLA doctrine.)
The article is online at 81.cn (81 refers to August 1st, the PLA's founding date and the basis of Army Day), and mirrored at Xinhua, Sina Military, and Guangming Daily. A PDF of the complete issue was previously available (I had last visited in March, I believe) at https://rmt-static-publish.81.cn/file/20250121/1d8217bd734a96b191cf7d33a81fe782.pdf but that link is now dead.
On the authorsRong Ming and Hu Xiaofeng are both affiliated with the College of Joint Operations at China's National Defense University, the PLA's highest military academic institution, directly under the Central Military Commission (CMC) and responsible for training the military's most senior commanders.
Hu Xiaofeng is a figure worth understanding. He is a professor and senior engineer who held the rank of Major General, and the chief designer of the PLA's first large-scale computer wargaming system. He has published more than ten monographs and received multiple National Science and Technology Progress Awards. Xi Jinping, as CMC Chairman, personally signed the order awarding him a military merit citation. His audio course on the science of war had accumulated over 33 million plays on the PLA's professional education platform as of 2020. When Hu Xiaofeng writes about AGI in PLA Daily, it is not futurism.
TranslationReflections on Warfare Brought by AGI (AGI带来的战争思考)
Rong Ming, Hu Xiaofeng
Editor's Note
Science and technology and warfare are always intertwined. While technological innovation continuously changes the face of war, it has not changed war's violent nature or its coercive purpose. In recent years, as artificial intelligence (AI) technology has developed and been applied rapidly, debate about its impact on warfare has never stopped. Compared to AI, artificial general intelligence (AGI)[1] represents a higher level of intelligence and is considered a form of intelligence on par with that of humans. How will the emergence of AGI affect warfare? Will it change war's violent and coercive character? This article explores these questions together with the reader.
Is AGI merely an enabling[2] technology?
Many believe that, although large models and generative AI demonstrate powerful military potential that prefigures future AGI, they are ultimately only enabling technologies. They can only optimize and enhance existing weapons and equipment, making them smarter and improving operational efficiency, but cannot bring about a true military revolution. This is somewhat like cyberwarfare capabilities,[3] which when they first appeared were placed in high hopes by many countries, but which now seem, in retrospect, to have been genuinely somewhat exaggerated.
AGI's disruptive nature is entirely different. It brings enormous changes to the battlefield with reaction speeds and breadth of knowledge far exceeding human capability. More importantly, it produces enormous disruptive results by accelerating scientific and technological progress. On future battlefields, autonomous weapons will be endowed with advanced intelligence by AGI, their performance universally enhanced, and by virtue of their speed and swarm advantages, become strong in offense and difficult to defend against[4]. At that point, the high-intelligence autonomous weapons that some scientists once predicted will become reality, with AGI playing a key role. Current military applications of AI include autonomous weapons, intelligence analysis, intelligent decision-making, intelligent training, and intelligent logistics support, and these applications are difficult to summarize simply as mere "enabling."[5] Moreover, AGI develops rapidly with short iteration cycles and is in a state of continuous evolution. In future operations, AGI must be treated as a priority, with particular attention to the changes it may bring.
Will AGI make war disappear?
The historian Geoffrey Blainey[6] argued that wars always occur because of mistaken assessments of each side's strength or will. With AGI's application in military affairs, miscalculation will become less frequent. Some scholars therefore speculate that war will decrease or disappear as a result. In practice, AGI can indeed reduce a great deal of miscalculation, but even so it cannot eliminate all uncertainty, since uncertainty is one of war's defining characteristics. Moreover, not all wars arise from miscalculation, and AGI's inherent unpredictability and opacity, combined with humanity's lack of practical experience in using AGI, will introduce new uncertainties, plunging people into an ever thicker "artificial intelligence fog."[7]
AGI algorithms also present a problem for rationality.[8] Some scholars argue that AGI’s capability to mine[9] critical intelligence and generate precise predictions has a dual effect. At a practical operational level, AGI does make fewer mistakes than humans and can improve intelligence accuracy, helping to reduce miscalculation; but it may also make humans blindly overconfident, inciting them to take desperate gambles.[10] The offensive advantage brought by AGI means the optimal defensive strategy becomes striking first, breaking the balance between offense and defense, triggering new security dilemmas, and actually increasing the risk of war.
AGI is highly general-purpose and easily integrated with weapons systems. Unlike nuclear, biological, and chemical technologies, its threshold for use is low and it is particularly prone to proliferation. Because of technological gaps between countries, there is a strong likelihood that immature AGI weapons will be deployed on the battlefield, bringing enormous risks. The use of drones in recent limited wars[11] has already stimulated many small and medium-sized countries to begin procuring large quantities of drones. The low-cost equipment and technologies that AGI enables will very likely stimulate a new arms race.
Will AGI be the ultimate deterrent?
Deterrence means maintaining a capability sufficient to intimidate an adversary and prevent it from taking actions beyond its own interests. When deterrence becomes so powerful that it cannot actually be used, it becomes the ultimate deterrence, as with nuclear deterrence based on mutually assured destruction. But what ultimately decides outcomes is "human nature,"[12] the key element that war will never lack.
Without the various considerations of "human nature," would AGI become a fearsome deterrent? AGI is fast but lacks empathy, executes decisively, and the space for strategic maneuvering is compressed to an extreme degree. AGI is a critical factor on future battlefields, but because practical experience with it is lacking, accurate assessment is difficult, making it easy to overestimate adversary capabilities. Furthermore, on the question of autonomous weapons control, whether humans should be in the loop with full oversight or out of the loop with complete autonomy,[13] deep consideration is undoubtedly required. Can the authority to fire intelligent weapons be handed over to AGI? If not, the deterrent effect will be greatly diminished. If so, can human life and death truly be placed in the hands of machines that have no relation to them? In wargaming research at Cornell University,[14] large models “suddenly launched nuclear attacks,” even when operating in a neutral posture.
Perhaps one day AGI will surpass humans in capability. Will we then be unable to supervise and control it? Geoffrey Hinton, who put forward the concept of deep learning, has said he has never seen a case in which something of higher intelligence was controlled by something of lower intelligence. Some research teams believe humans may be unable to supervise superintelligent AI. Facing powerful AGI in the future, can we truly control it? This is a question worthy of deep reflection.
Will AGI change the nature of war?
With the widespread deployment of AGI, will the violent and bloody battlefield disappear? Some say that AI warfare far exceeds the range of human capability and will push humans off the battlefield entirely. When AI transforms war into confrontation conducted entirely by autonomous machines, is it still "violent and bloody warfare"? When adversaries with unequal capabilities confront each other, the weaker side may have no opportunity to act at all. Could wars be concluded before they begin, through wargaming simulations?[15] Will AGI thereby change the nature of war? Is "unmanned" "warfare" still warfare?
Yuval Noah Harari, author of Sapiens, says that all human behavior is mediated through language and shapes our history. Large language models are a representative form of AGI. What most distinguishes them from other inventions is their ability to create entirely new ideas and cultures: "Storytelling AI will change the course of human history." When AGI touches control over language, the entire civilization system constructed by humanity could be overturned, even without AGI developing consciousness. Like Plato's “Allegory of the Cave,”[16] might humans come to worship AGI as a new “deity”?
AGI builds intimate relationships with humans through human language and changes human perceptions, making it difficult for people to distinguish and identify what is real, thus creating the danger that the will to wage war could be controlled by those with malicious intent. Harari says that computers do not need to send out killer robots; if they truly need to, they will get humans to pull the trigger themselves. AGI precisely manufactures and refines situational information, controls battlefield cognition through deepfakes, can use drones to falsify battlefield conditions, and can shape public opinion before a conflict begins. Early signs of this have already appeared in recent local conflicts. War costs will thereby decline dramatically, giving rise to new forms of warfare. Will small and weak nations still have a chance? Can the will to fight be changed without bloodshed? Is "force" still a necessary condition in the definition of war?
The form of warfare may change, but its essence remains. Regardless of whether warfare is "bloody," it will still compel the enemy to submit to one's will and carry substantial "collateral damage," though the mode of confrontation may be entirely different. War's essence lies in the "human nature" at the core of human experience. "Human nature" is determined by culture, history, behavior, and values, and is very difficult to fully replicate with any artificial intelligence technology. One cannot outsource all ethical, political, and decision-making questions to AI, nor expect that AI will automatically generate "human nature." Because AI technology may be misused in moments of passion or impulse, it must remain subject to human control.[17] Since AI is trained by humans, it will never be entirely without bias, and so it cannot be wholly free from human oversight. In the future, AI can become a creative tool or partner, enhancing "tactical imagination," but it must be "aligned" to human values. These questions require continuous thinking and understanding in practice.
Will AGI overturn war theory?
Most disciplinary knowledge is expressed in natural language. Large language models, which represent a vast synthesis of human writings, can connect literary and humanistic works with scientific research in ways that would otherwise be difficult. Some have fed classical works, and even philosophy, history, political science, and economics, into large language models for analysis and reconstruction, finding that the model can conduct comprehensive analysis of all scholarly viewpoints and also put forward its "own views," not without originality. Some therefore ask: could AGI be used to re-analyze and reinterpret war theory, stimulating human innovation and driving major evolution and reconstruction of war theory and its systems? Perhaps, in theory, this could indeed lead to some improvement and development. But the science of war is not only theoretical; it is also practical, and AGI is fundamentally incapable of grasping its practical and real-world dimensions.[18] Can classical war theory truly be reinterpreted? If so, what does theory even mean?
In sum, AGI's disruption of the concept of war will far exceed that of "mechanization" or "informatization."[19] Toward the arrival of AGI, one must both boldly embrace it and maintain caution. Understanding the concept, so as not to be ignorant; studying it deeply, so as not to fall behind; strengthening oversight, so as not to be caught unaware. How to learn to cooperate with AGI, and how to guard against an adversary's AGI surprise strike,[20] this is what we must attend to first in the coming period.
Editor's Afterword: Anticipating the Future with an Open Mind[21]
Ye Chaoyang
Futurist Roy Amara made a famous observation that people tend to overestimate the short-term benefits of a technology, yet underestimate its long-term impact, later known as "Amara's Law." This law emphasizes the nonlinear character of technological development: the actual impact of technology often only fully reveals itself over longer time horizons, reflecting the rhythm and trajectory of technological development and embodying humanity's acceptance of and aspiration toward technology.
Currently, in the process of AI's development from weak AI to strong AI and from specialized AI to general-purpose AI,[22] every time people believe they have completed 90 percent of the journey, they look back and find they may have barely passed the 10 percent mark. The driving role of technological revolution on military revolution is increasingly prominent. Advanced technologies represented by AI are penetrating the military domain across multiple dimensions, causing deep transformation in the mechanisms, elements, and methods of achieving victory.
In the foreseeable future, intelligent technologies such as AGI will not stop their iterative advance. The cross-evolutionary development of intelligent technologies, and their enabling applications in the military domain, will tend toward greater diversity, perhaps breaking beyond the boundaries of humanity's current understanding of warfare. Technological development is unstoppable and no one can halt it. Whoever can use sharp eyes and a clear head to see the trends and potential of technology, and pierce the fog of war, will be better positioned to seize the initiative to victory.
This reminds us that the exploration of future warfare must be approached with a broader perspective and mindset if we are to come closer to a reality that is all too easily underestimated. Where is AGI heading? Where is intelligentized warfare heading? These questions test the wisdom of humanity.
ConclusionWhat does this article tell us? At minimum, it reveals that AGI was being reasoned about as a profoundly abnormal technology within the PLA's institutional discourse, as early as January 2025.
The article is more distinctive in retrospect. PLA AI discourse in 2025 and 2026 moved toward practical intelligentization questions: DeepSeek deployment, procurement, C4ISR (command, control, communications, computers, intelligence, surveillance, and reconnaissance) integration, "dissipative warfare." The article's discussion of AGI as a transformative and potentially uncontrollable strategic technology, including loss-of-control risk, deterrence collapse, and civilizational disruption, did not generate a visible follow-on.
It is still important to surface, I think, because Western analysis has given this piece little attention. In general, it seems wrong to assume that no strategic thinking on AGI is taking place in China.
AcknowledgementsThank you to Tobias Häberli, Calvin Duff, Veronika Blablová, Felix Choussat, and Tony O’Halloran for comments.
- ^
The Chinese spells out 通用人工智能 (AGI) on first use, then the article body uses the English acronym exclusively. By using the English acronym directly, the authors signal that they are discussing artificial general intelligence in the transformative sense, not general-purpose AI in the industrial diffusion sense.
- ^
The Chinese term is 赋能, meaning "to endow with capability" or "to empower." This was the characteristic vocabulary of China's digital economy policy, describing how technology upgrades and enhances existing systems. China's 2024 Government Work Report used the term in this sense: "sweeping digital transformation will empower economic development" (以广泛深刻的数字变革,赋能经济发展). The term was later (eight months after this article’s publication) written directly into the targets of the AI+ Action Plan (August 2025): "by 2030, AI will comprehensively empower high-quality development" (到2030年,我国人工智能全面赋能高质量发展). The authors are thus pushing back against a merely enabling, diffusion-flavored frame here. Their answer comes in the following paragraph: "AGI's disruptive nature is entirely different" (AGI的颠覆性其实完全不同).
- ^
The original uses 网络战武器, literally "cyberwar weapons," referring to the wave of enthusiasm in the early 2000s for offensive cyberwarfare as a transformative military capability. The authors treat this as a cautionary analogy, as a technology that generated outsized expectations but more limited results in practice.
- ^
攻强守难 is a four-character set phrase meaning literally "offense strong, defense difficult." The phrase is very relevant for discussions on defensive acceleration and tech tree nondeterminism.
- ^
Quotation marks in this translation appear only where the original Chinese uses them. The authors quote certain terms to signal that they are borrowed, coined, or used with deliberate philosophical weight.
- ^
Geoffrey Blainey is an Australian historian, author of The Causes of War (1973).
- ^
A deliberate echo of Clausewitz's concept of the fog of war (战争迷雾). The authors suggest AGI introduces a new and thicker layer of opacity on top of classical battlefield uncertainty.
- ^
理性难题, literally "rationality problem." The authors are not claiming AGI itself is irrational, but that its presence distorts human rationality.
- ^
The word “mine” here (挖掘) is the same word used for data mining (数据挖掘); the authors are likely invoking AGI’s capacity to extract intelligence from large volumes of data.
- ^
The original uses the four-character idiom 铤而走险, which describes taking a dangerous risk out of desperation or when left with no other option.
- ^
局部战争, literally “partial war,” is a PLA doctrinal term for wars limited in both geographic scope and political objectives, as distinct from a world war.
- ^
"Human nature" (人性) appears in quotation marks throughout the original. The authors define it later as "determined by culture, history, behavior, and values" (而"人性"是由文化、历史、行为和价值观等决定的), so not in a narrowly psychological sense, but as the full range of human moral judgment that underlies warfare.
- ^
人在环内 / 人在环外 maps directly onto the English terminology "human in the loop / human out of the loop."
- ^
The paper cited is "Escalation Risks from Language Models in Military and Diplomatic Decision-Making" (FAccT 2024), by researchers at Stanford, Georgia Tech, Northeastern, and the Hoover Wargaming and Crisis Simulation Initiative. It was posted as an arXiv preprint, arXiv being hosted at Cornell University, and press coverage routinely shortened this to Cornell University, an attribution the PLA Daily article follows. The finding cited is accurate; all five tested large language models showed escalatory behavior, and some executed nuclear strikes even when assigned a neutral posture in the simulation.
- ^
兵棋推演 is the standard Chinese term for military wargaming exercises, used for operational planning, training, and strategic assessment. The authors are asking whether AGI-powered wargaming could, in theory, determine the outcome of a conflict before any fighting begins.
- ^
Plato's allegory of the cave describes prisoners who mistake shadows on a cave wall for reality, having never seen anything else. The analogy here may be that if AGI gains control over language and culture, humans might similarly mistake AGI-generated representations for reality, and come to treat AGI itself as a higher authority.
- ^
I found the causal logic here quite strange. The authors cite the risk of AI being misused through human passion or impulse as a reason to keep AI under human control.
- ^
战争科学不仅具有理论性,而且还具有实践性,但实践性、现实性却是AGI根本做不到的。Here the authors are drawing on a distinction between theoretical knowledge and practical wisdom. AGI can analyze and synthesize war theory, but cannot have the embodied practical experience of war itself. This connects to their broader argument about "human nature," that even in fully automated warfare, the purposes and moral stakes of war remain irreducibly human.
- ^
"Mechanization" (机械化) and "informatization" (信息化) are stages in a framework of military modernization that runs through Chinese strategic discourse. Mechanization refers to the integration of motorized and armored systems, associated with industrial-age warfare. Informatization refers to the integration of information and communications technology into military systems, a concept with roots in the 1990s that remains current in Chinese military writing. The authors position intelligentization (智能化, AI-driven warfare) as the third and most disruptive stage of this progression.
- ^
突袭 is a military term for a sudden ambush-style attack. The authors are not describing a competitive or technological surprise but a deliberate adversarial strike exploiting AGI capabilities.
- ^
The afterword is signed by Ye Chaoyang, the column editor, not the authors.
- ^
Here Ye Chaoyang uses 通用人工智能 without the English acronym, reverting to the Chinese characters the article body had set aside. The translation renders this instance as "general-purpose AI" rather than "AGI" to reflect the ambiguity.
Discuss
Will we really put data centers in space?
Several major technology companies have announced plans to operate AI data centers in orbit. Elon Musk recently claimed: “the lowest-cost place to put AI will be space […] within two years, maybe three.” If a meaningful fraction of new AI compute really is placed in space within a few years, that would be a fairly big deal for AI governance and strategy. Here we try to disentangle the hype from reality and provide a sober assessment of the technical and economic feasibility of orbital data centers (ODCs).
The main case for ODCs is the cost of energy: space solar panels in the right orbits receive more constant and intense sunlight compared to Earth. Moreover, ODCs don’t currently face the same permitting and regulatory delays as on Earth, cause fewer ongoing environmental harms compared to grid or onsite natural gas-powered data centers, and may be more secure against data exfiltration. We find that the cost-competitiveness case for ODCs depends almost entirely on Starship achieving reusability comparable with what SpaceX achieved with Falcon: space-based solar reaches cost parity with present-day off-grid terrestrial power continuously at roughly $250/kg to orbit, and becomes cheaper than any current terrestrial energy source at around $50/kg, from the present-day cost launch cost of roughly $1,500/kg. Radiative cooling, often cited as a fatal obstacle, appears surprisingly manageable — potentially even cheaper than on Earth. However, ODCs may require substantial (perhaps ~38%) extra non-compute hardware (like solar, racks, and cooling) over 5 years to compensate for their inability to swap out failed chips, and inter-satellite bandwidth limitations likely confine ODCs to inference workloads, at least early on.
Assuming no transformative AI,[1] but continued demand for data center buildout, we estimate that ODCs are unlikely to represent a meaningful share of compute before 2030, but become cost-competitive with present-day terrestrial data centers within 3–5 years if Starship development stays on track.
Introduction & TakeawaysSome of the world’s largest technology companies continue racing for compute. If progress continues, demand for data centers may more than double by 2030.[2] Increasingly, though, new data center capacity is bottlenecked by multi-year queues to connect to the power grid.[3]
The result has been a scramble for workarounds. Leading AI labs have increasingly adopted a “Bring Your Own Generation” model to source power, deploying onsite gas turbines and engines to bypass grid bottlenecks. xAI, for example, reportedly installed hundreds of megawatts of onsite gas generation in Memphis to accelerate deployment, and OpenAI and Oracle have placed large turbine orders for new Texas campuses.
Some argue that energy will become the binding constraint on AI progress, given grid interconnection delays as gas turbines are themselves facing multi-year manufacturing backlogs. But the constraint does not appear fundamentally binding (as Epoch notes): turbine manufacture may expand to meet more demand and companies could go off-grid using combinations of gas, solar, and batteries, scaling power in parallel with compute, albeit at a cost premium. This raises a natural question: if you’re going off-grid anyway, then what’s the best way to get power and where is the best place to put your data center?
Some think the answer will be in orbit. In November 2025, Google announced Project Suncatcher, a plan to put TPU-equipped satellites in dawn-dusk sun-synchronous orbit. In early 2026, SpaceX filed with the FCC for authorization to launch and operate a constellation of up to one million data center satellites.[4] Other entrants include Blue Origin, Ramon.Space and startups like Starcloud, and Aetherflux while China’s Three-Body Computing Constellation has launched 12 operational satellites and run Alibaba’s Qwen3 model in orbit. Recently, at GTC in March 2026, NVIDIA announced the Space-1 Vera Rubin Module, meant to be a dedicated space-rated GPU platform.
At first glance, it seems very unlikely that any meaningful fraction (say, >10%) of additional data center capacity will be placed in space in the next few years. But if the companies betting on space are right, that would be a fairly big deal, and it could change the landscape of AI governance. For example, terrestrial data centers are subject to national and regional regulations, whereas AI developers could potentially exploit jurisdictional ambiguities around compute in space. Also, the path to low-cost orbital compute likely routes through a single launch company, SpaceX, which also now operates a frontier AI lab since its acquisition of xAI. And that might raise concerns around concentration of power.
We’ve been looking into the technical and economic viability of orbital data centers (ODCs). Our core model gives estimates for the total cost of Earth and space-based data centers across several scenarios.
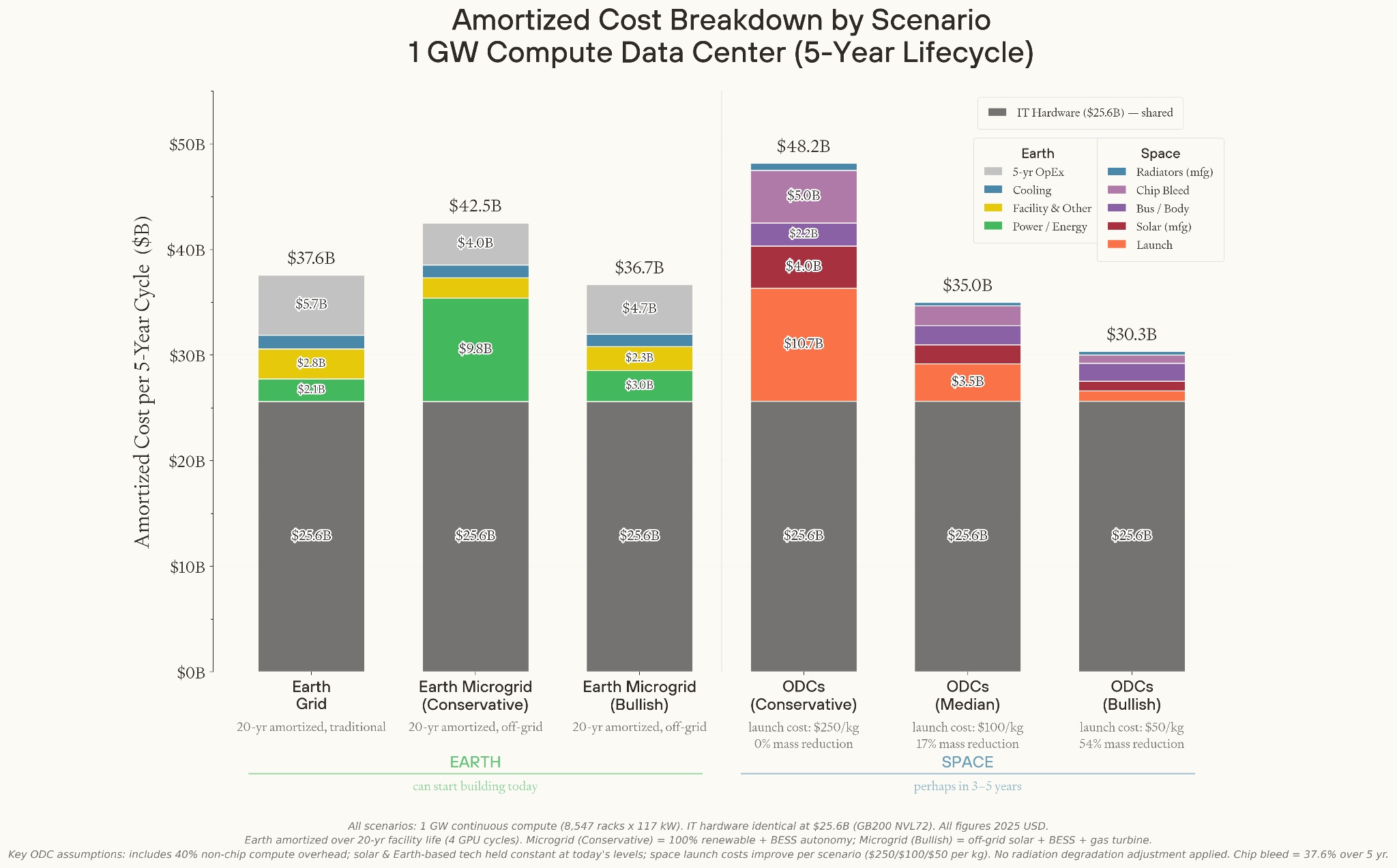{kind=link}
Cost breakdown for three Earth-based and three space-based scenarios building out 1 GW of compute. As best we can determine, orbital data centers could become cost competitive with a bullish terrestrial buildout if launch cost reaches around $100/kg given modest reductions to server and cooling system mass, while a bullish case for orbital data centers with substantial mass reductions and launch at $50/kg may offer cost savings.
The report focuses on three questions. First, what is the basic economic case for a meaningful fraction of AI compute being placed in space? Second, the most obvious physical blocker: can you cheaply cool a data center in orbit? Third: how fast could the shift to space data centers happen, how soon, and what would have to go right?
Here is our provisional assessment:
- SpaceX’s Starship is the only vehicle currently on track to deliver the launch costs and cadence that meaningfully scaling orbital data centers would require. Competitors are years behind, making SpaceX’s Starship the only near-term path to large-scale orbital compute. SpaceX aims to complete Starship development by late 2026, with several necessary milestones still ahead. If development stays roughly on track, Starship could plausibly hit the cost and cadence required to scale meaningful orbital compute within 3–5 years. However, chip production may become the limiting factor by this point, rather than launch capacity.
- The cooling problem is more tractable than commonly assumed. Passive radiators using selective coatings and lightweight carbon fibre panels could achieve ~170–360 W/kg at system level, a 13-28× improvement over ISS-era radiators (~13 W/kg).[5] No radiator at these performance levels has been deployed at the scale an orbital data center would require, but prototype high-conductivity carbon composite panels have demonstrated the material properties required. At these performance levels, thermal hardware is 2-5% of total data center cost, and actually less than what terrestrial data centers spend on cooling over a comparable lifecycle.
- If launch costs fall enough, the unit economics could favor space. Solar panels in dawn-dusk sun-synchronous orbit produce roughly 3–5× the energy of the same panel at a good terrestrial site.[6] Space-based solar becomes cheaper than the best off-grid terrestrial installations once launch costs drop below roughly $250/kg using Starlink-like solar arrays. At a launch cost of $50/kg (corresponding perhaps, to a Starship with full reuse as reliable as Falcon), space solar could fall to between $25–45/MWh, making it cheaper than any current terrestrial option available today.[7] Beyond the symmetric cost of chips, launch cost is the dominant line item for ODCs while power and op-ex dominate terrestrial costs but would be near zero in space.
- The inability to do maintenance would be a large cost. Chips often fail and are swapped out in today’s data centers but a dead chip in an ODC would remain dead, wasting the parts of the supporting infrastructure (power, cooling) and diminishing overall compute. We model this below as a 9% annual bleed causing about 40% overbuy of launch and non-chip hardware over the data center’s lifetime.[8] Below $100/kg launch cost this might net out against other savings from ODCs but this is a significant uncertainty since the actual rates of chip failure for ODCs could be higher or lower.
- All-things-considered we think that, absent transformative AI, orbital data centers probably won’t make up a meaningful fraction of compute before 2030, but it’s credible that space could house much or even the majority of compute buildout throughout the 2030s.
Read the full report on the Forethought website: Will We Really Put Data Centers in Space?
- ^
We hope to do more analysis on how transformative AI might change this picture in the future. Speculatively, our initial thinking is TAI could accelerate the timeline over which compute transitions to space but this is not necessarily the case. In particular, during an industrial explosion pressure to grow rapidly might be so strong as to incentivize aggressive usage of non-renewables on Earth like oil and gas. If so, transition to space might be delayed for a one time boost on Earth, in which case the picture may look similar to the one we outline here, but with the added prologue of a large-scale terrestrial buildout.
- ^
McKinsey projects demand growing to 171–219 GW by 2030, roughly doubling from today, in a buildout they estimate will require up to $7 trillion in investment.
- ^
Interconnection timelines have lengthened substantially in recent years. Lawrence Berkeley National Laboratory reports that projects built in 2023 waited a median of roughly five years from interconnection request to commercial operation.
- ^
Starcloud subsequently filed for authorization to operate 88,000 satellites and Blue Origin has filed for 51,600.
- ^
The ISS External Active Thermal Control System achieves roughly 13 W/kg. Our improvement comes from three sources: selective coatings (high emissivity, low solar absorptivity, off-the-shelf AZ-93 paint), carbon fibre composite construction (2.4 kg/m² vs ISS’s ~14-17 kg/m²), and optimised operating temperature (40°C vs ISS’s -40°C, exploiting the T4 dependence). Each factor is independently demonstrated; their combination at scale is not.
- ^
The solar constant at Earth’s orbit is approximately 1361 Wm-2. A solar panel in a dawn–dusk sun-synchronous orbit receives nearly continuous illumination (capacity factor ≈ 90–95%), yielding an average power of roughly 1220–1290 Wm-2 before panel efficiency losses. By contrast, even excellent terrestrial solar sites typically achieve ~20–30% capacity factors due to night, weather, and atmospheric attenuation, corresponding to an average incident power of roughly 270–410 Wm-2. Thus, a panel in a dawn–dusk orbit produces roughly 3–5× more energy annually than the same panel on Earth.
- ^
This wouldn’t be true if you were then beaming the energy back to Earth, but would apply to orbital compute, where only data needs to be sent to Earth.
- ^
Both terrestrial data centers and ODCs will pay symmetric costs to replace dead chips but ODCs would have to pay the additional cost from lost overhead, i.e. in the earthbound case a technician swaps the dead chips, in the space case you launch entire additional satellites to compensate for chip bleed. We assume you would not send a mission to do maintenance and instead simply let the excess power and cooling go to waste doing no useful compute. Extra power and cooling over fewer chips may increase operating efficiency somewhat but this seems fairly negligible. The figure for chip bleed of ~9% per year is derived from Meta’s The Llama 3 Herd of Models (2024). We cover radiation and other forms of damage in more detail subsequently.
Discuss
We made a map of the doom debate
This was produced as a part of the AI Safety Camp 2026 "Assumptions of the Doom Debate" project, led by Sean Herrington, who was also the lead author on this post. The other participants have equal contributions and are listed in no particular order. It is the first in a sequence we intend to publish over the coming weeks.
TL;DR:
- We have created a breakdown of AI threat pathways, which can be accessed at https://lifeuniversesafety.com/doom-assumptions/index.html
- This breakdown is in a tree format, and we allow people to set their own probabilities for each threat pathway
- You can use this to drill down into components of your P(Doom)
- You can analyse the sensitivity of your beliefs to changes in your assumptions
- You can compare your worldview to others’ and find cruxes automatically
- The exercise of creating this sort of structure is valuable as a way to think about the future in a more general manner.
Just about everyone in the AI community seems to disagree about the risks of the technology. People disagree on the likelihood (Yann LeCun: <0.01% chance of extinction; Roman Yampolskiy: >99.99%), the worst threat (AI takeover vs concentration of power vs gradual disempowerment vs bioweapons vs …), the timelines and many other things. It seems like a shared framework would be helpful in this capacity.
The main issue that comes with creating such a thing is that it requires everyone to agree on it. We call this requirement "worldview independence"; it significantly narrows down the space of options for the shape this framework can take. In particular, every part of the structure has to be a mathematical statement; those are some of the only things people can agree on.
The structure we eventually ended on looks like this:
Breaking it down:
- E: Event that we're worried about (Nuclear war, Bioweapon is released, Human extinction, etc)
- A: Set of worlds, e.g., "AI-driven worlds" = "credence that we live in a world where AI is making E more likely."
- ¬A: Set of worlds which are not in A, e.g., "Non-AI worlds" = "credence that we live in a world where AI is not making E more likely"
- P(E|A): Probability that event E happens in worlds A.
On the website, we also have a timeframe, such that we are actually talking about event E happening "within 30 years", for example. Putting real values in looks like this:
In this case, the thing we want to know is our probability of an existential catastrophe occurring within the next 30 years. We split this into AI-caused and not AI-caused.[1] You can then set your probabilities for each of these and calculate your overall final probability that an existential catastrophe happens.
This becomes significantly more interesting once it gets scaled, as it enables you to break the future down into individually visualisable threat paths. We’ve also found as a group that the exercise of creating this tree has helped us see a range of possibilities we had not considered.
For instance, we hadn’t previously thought much about scenarios where powerful and otherwise aligned AIs made mistakes, but after further thought, consider it significantly more likely.[2] This insight was directly generated by the thought that while trying to split worlds apart, we were implicitly assuming that dangerous AI scenarios were caused by AIs which wanted these scenarios to come about.
User GuideLabelsLabels are simply changes that can be made to the text in the tree, allowing you to change what you’re talking about. They appear in the left sidebar, next to the tree:
We have 4 different labels you can apply to your tree.
Label
Description
Danger
Changing the danger label is equivalent to changing what you are talking about: some people want to ask whether we’re going to have an “existential catastrophe"; for others, the question is whether “everyone dies" or whether “a bioweapon gets deployed”.
Timeframe
One of the biggest debates in the AI community is one of timelines. Our tree is therefore based around the question of whether the danger occurs within the timeframe of "x years". Use this label to change which timeframe you are discussing.
Author
Put your name here to show people that it’s your worldview rather than anyone else’s.
Perspective
You can use this to change whether you are talking about your inside view (where you are basing your opinion on a gears-level internal model) or your outside view (where you also include meta-level factors outside that model).
Base TreeOur base tree has 4 different branching points, which we’ll explain briefly here.
Branch
Description
AI driven/Not
Separates out worlds in which AI worsens the danger from those in which it doesn’t.
Single AI/Multipolar (AI driven world)
Separates out worlds where most of the danger comes from a single AI from worlds where it comes from multiple.
Internal Model/Not (Single AI Danger world)
Separates out worlds where the single AI causing the most danger is an AI with an internal model of the danger it’s causing from one where it doesn’t. An example of a dangerous system without a model could include (for instance) a simple missile detection system entrusted by a nuclear power with retaliation. The main question here is, "How likely is it that the AI knows what it's doing?"
Expects danger/doesn't (Internal Model world)
Splits worlds where the single most dangerous AI expects the danger it is causing to occur (such as in traditional misaligned superintelligence narratives) from those in which it does not (for instance, because the AI has itself made a mistake).
Tree featuresPin branch overrides
If you do not want to set all of the nodes in the tree, you can override the leaves by simply moving the probabilities higher up the tree. You will still be able to edit the probabilities further down, but they will no longer affect your root probability.
Clicking on the triangle symbol allows you to switch between the set probability for that node and the propagated value for the nodes further down the tree.
The +/- icons in the corner of the nodes of the tree can be used to expand and collapse the tree below them.
Sub-branch probabilitiesEach node below the top section of the tree has two numbers: The main one is the actual probability of this world existing and causing an AI catastrophe.
P(We are in a single dominant AI world AND Existential Catastrophe occurs)
The number below is the same, but conditioned on us already being in that branch of the tree.
P(We are in a single dominant AI world AND Existential Catastrophe occurs GIVEN THAT we're in an AI-driven world)
Connector thicknessThe lines between nodes get thicker for branches carrying more probability mass through worldspace. This is a representation of how the worlds are split, rather than representing probabilities of danger.
Sensitivity AnalysisThe sensitivity analysis is the derivative of your overall probability by each individual value you’ve set. It allows you to see where changing your mind would be the most significant.
Different people have different worldviews. Crux analysis is a way to see which facts are the most important sources of disagreement.
We are comparing 2 worldviews, A and B. These can either be preset or user-saved.
For each node, there are 2 bars:
- The green bar is how much A's final probability would move towards B's if B convinced them of their worldview in that particular node
- The amber bar is how much B's would change were A to convince them.
Bars going to the right close the gap in root probabilities, while those going to the left open them.[3]
For instance, in the picture above, B convincing A that multipolar AI means a 15% probability of existential catastrophe rather than 10% would move A's overall probability by 2.2 percentage points towards B's.
A convincing B to lower their probability to 10% rather than 15% would move B's overall probability by 2.4 percentage points towards A's.
RangesWe have added ranges to the site. This allows for a representation of your uncertainty in the final result: if your current probability estimate is 60% for something, but it seems plausible that on another day you might put 50 or 70, it can be useful to know how that would affect the final result.
We currently have 2 range propagation modes:
- Worst case: treats the ranges as maximum and minimum possible probabilities
- Independent: treats the ranges as 10th and 90th percentiles and performs a Monte Carlo simulation[4] to establish subsequent ranges.
We would generally recommend using independent propagation as 'better', but the worst case can also be useful as a view of the full range of possibilities you see as plausible.
Uncertainty ReductionWhen using ranges, you get the additional option of using uncertainty reduction.
This shows you how much reducing your uncertainty on individual nodes reduces your overall uncertainty.
Other featuresFeature
Description
Worldviews
The tree contains some preset worldviews, which are AI-generated estimates of prominent figures' worldviews, inspired by their public statements. Please note these are not endorsed by the actual figures and are there for interest purposes only.
Share
You can share worldviews with friends. Click on the button to get a shareable link they can then paste in their browser.
Save
Save this worldview as a JSON file and to local memory. Saved worldviews persist across sessions.
Import
Import a JSON worldview file.
Reset
Reset all values to 50%
Delete
Delete a saved worldview
- ^
It's hard to define this precisely, and we've had a bunch of debates about this ourselves. The basic intuition is, for the example E=Existential risk, "How likely do you think it is that we live in a timeline where AI will overall contribute to existential risk (for instance, because it is misaligned) vs helping to mitigate it (via, e.g., helping to solve problems associated with climate change)?"
- ^
For a brief intuition here, consider this statement from the perspective of a chimpanzee: “Humans are smart enough to go to the moon, change animals’ DNA and communicate instantly across the globe. There’s no way they’d be dumb enough to cause climate change; they live on this planet like we do!”
- ^
An example of how agreeing on one node can make your final probabilities diverge: A is broadly more pessimistic than B, except on one node. Agreeing with B on that node would make A even more pessimistic, taking their overall probability away from B's.
- ^
The individual probabilities are drawn from a beta distribution fit to the percentile range
Discuss
Which technical AI safety fields are going to be automated first?
I’m transitioning into technical AI safety, and I find myself thinking a lot about what fields I want to research and where I’ll have the biggest impact. One thing I’ve found myself thinking about a lot recently is what fields are likely to be automated.
This seems pretty likely since frontier labs will likely be automating capabilities research as a part of automated R and D, and safety research won’t be far off. Some initial examples of this are Anthropic is investigating automated alignment researchers, UKAISI recently evaluated models’ propensity to sabotage alignment research, and Anthropic is using Mythos for internal productivity boosts and testing its ability to do alignment research without sabotage (which it can’t). There are also a handful of frameworks appearing for creating automated research pipelines, such as The AI Scientist.
I’ll be considering two factors:
- Feedback Quality: How easy is it to verify the research outputs from these fields
- Economic Incentive: How much incentive is there for frontier labs to automate this research
Disclaimer: This is a pretty rough and hand-wavy explanation of this. If you’re looking for a more in-depth exploration into modelling automated R and D across alignment vs capabilities, I’d recommend this post from Jan.
Disclaimer: I wrote up most of the ideas for this blog post in April and didn’t get around to publishing it. I'm aware that UAISI has published more fantastic research into this that I haven’t considered in this blog post.
I’ll be basing my automation capability on what an AI with superhuman coding and reasoning capabilities could do.
I’m particularly referring to how quickly each will get to automating the entire research pipeline with no/little humans in the loop, and the incentives to get there.
Here are my rankings for which fields are most likely to be automated this way (top is most likely):
- Scalable Oversight
- Feedback Quality (3/5): This has okay feedback quality in terms of already existing evals; however, I think this is quite open-ended and hard to identify everything we need to watch out for in terms of model outputs.
- Economic incentive (5/5): I’ve put this at the top since 1. it is crucial for automating the other fields of research 2. It has a nice positive feedback loop where stronger scalable oversight methods allow more automation. We have already seen anthropic researching scalable oversight.
- I admit that this may be a circular where good scalable oversight needs to exist in order to automate scalable oversight research, but that’s why I believe there will be massive incentive and research to develop this by humans (with assisted AI reasoning).
- Mech Interp
- Feedback Quality (5/5): For activations engineering, I reckon it’s arguably easy to validate methods of mech interp, particularly for things like steering (e.g., linear probes, SAEs), by evaluating model outputs given steering. I also think it applies to optimising current methods by doing hyperparameter sweeps, etc.
- I do think novel methods will struggle and probably need some human insight for this, although I think it may emerge from just iteratively understanding the model more, leading to positive feedback loops as predicted by ambitious mech interp. I also think the bitter lesson of throwing more compute at it may also bypass difficult novel research (e.g activations oracles, NLA)
- Economic incentive (4/5): Massive, better theories of mech interp will lead to both better alignment research but also aiding capability research (e.g verifying a model has learnt a feature). I predict this will be the most investment into automated R & D.
- AI control
- I was tempted to group with this scalable oversight since it tackles a very similar problem, but more adversarially, and its research agenda seems different, so I’ve left it as its own field for now.
- Feedback Quality (3/5): I think existing frameworks, such as ControlArena and LinuxArena, provide pretty good environments that can serve as a foundation for more complicated foundations. I can also see this field becoming more automated in general to evade eval awareness via blind deep deployment.
- Economic incentive (4/5): I think slightly lower than scalable oversight, since this is preparing for the case that a model is deceptive, which is less likely in training/deployment than just monitoring frontier models for quality.
- Model Organisms of Misalignment
- Feedback Quality (4/5): I think this has good feedback quality since model orgs have a ground truth (that they’re misaligned in a specific way), assuming they’re training correctly.
- Economic incentive (2/5): I think this has fairly low economic incentive for the same case as above, despite the catastrophic risk of deceptive or backdoored models; I think the lower likelihood will lead to AI labs neglecting this research for more profitable research, such as scalable oversight.
- Emergent Misalignment
- Again, I was tempted to group with this Model Organisms of Misalignment since it’s a main field of study within the field, but I decided to separate it due to the research agenda being more aimed at how it occurs and prevention (e.g via inoculation prompting).
- Feedback Quality (3/5): This has slightly harder feedback quality than model orgs because the range of misalignment is much broader here; we need to ensure that we can measure misalignment of values and policies, which I believe requires hard brainstorming.
- Economic Incentive (3/5): I believe that this has more economic incentive to study than model orgs, since this is a phenomenon that may arise in post-training frontier models right now if not carefully, therefore, there’s an incentive for frontier labs to protect themselves against this.
- Evals
- Feedback Quality (2/5): I think the quality differs based on the kind of evaluation this is. I believe capability evaluations will be easier to validate than propensity or alignment evaluations, since some kind of ground truth can be established using smaller models. However, I think the hardest part will be designing evals since models aren’t fantastic at novel idea generation.
- Economic Incentive (4/5): There is a decent incentive to automate these evals, especially since we are already running out of evals that aren’t saturated (which ties into scalable oversight), especially since frontier labs can create their own evals and thresholds for safety as a part of regulatory capture.
- Technical Governance
- This is an oversimplification by assuming technical governance as one big field, for example, I’m including: inference verification, open weight safety, threat models, forecasting, etc.
- Feedback Quality (3/5): I believe this is quite a messy field in terms of knowing how successful. Depends on how much governance will be automated because this is quite a messy field in terms of product communication and adoption (by regulators and frontier labs). However, there are some parts of the field that have very clear feedback loops (e.g compute/hardware tracking) so I’m upgrading this to a 3.
- Economic Incentive (2/5): I believe there is little incentive for frontier labs to automate this since they would be contributing that would aid their own regulation however there is the case of regulatory capture where frontier labs can control this regulation via this automation.
- Field Building
- I particularly mean starting a new org, community, or tool, driven particularly by generalists. I’ll be focused on automating the process of starting and running a new org for the technical AI research pipeline.
- Feedback Quality (1/5): I think it’s pretty hard to determine the impact of an org apart from just analysing and optimising for KPIs (Coefficient Giving has a good strategy for it though). This also has a very slow feedback loop, with investments taking months and years to pay off or even become clear.
- Economic Incentive (2/5): I think this has pretty negligible incentives for frontier labs apart from expanding their own organisation and automating their own admin and growth.
- Theoretical Alignment
- This includes, for example, value alignment, CEV.
- Feedback Quality (1/5): This is hard, particularly for research into value alignment, as you need to validate that these theories have some grounding in reality, which is quite difficult to validate. Also, this requires lots of novel forms of thinking and methods, which are not easy for models to automate yet.
- Economic Incentive (2/5): I do see the idea of getting to AGI or ASI and having models research humanity’s values and research theoretical alignment to those values, but this is far off, and I think a lot of other things need to go right (such as scalable oversight) before frontier labs will practically consider this.
- Agent Foundations
- Feedback Quality (1/5): Similar to above, quite difficult and lots of theory that can be hard to validate.
- Economic Incentive (1/5): Some subjects like corrigibility are measured by frontier labs but not really as a main point of focus and not really in ways that other attempts at corrigibility agree with. I also think that frontier labs are fully on board with the idea of empiricism and doubt they will heavily investigate these theoretical foundations of agents.
Just a reminder that this is an extremely broad overview of these fields and just my educated guess for the tasks required in research that are very difficult to automate (such as research taste, conceptual design), and of course, one could plausibly rank these fields differently (e.g., evals and emergent misalignment depending on how much you trust automated eval generation).
It’s been pretty interesting as i’ve been writing this, at first I had mech interp as my most #1 field but reading more about anthropic’s research showed me that scalable oversight is just as important, if not more.
It’s not a nice list to make, especially as someone who wants to do research. I worry about the ever-shrinking gap of “human” work to do. And I’ll be selfish and admit that it also kinda sucks because I want to do the research in all of these fields.
This is one reason I’ve found myself leaning towards technical governance work, evals, and field building (although mech interp will always be a massive interest) since these seem like “safer bets” (in terms of less likely to be automated first) even if they have their own list of problems for why it’s hard to enter these fields and long-term impact. I also had a lovely time at ML4Good, which updated my values and made me want to pursue these fields more, which I’m looking forward to writing up as a separate blog.
I would love to hear your thoughts on this, especially if you disagree with my list above. Feedback is always welcome!
Discuss
Gemini 3.5 Flash Looks Good For How Fast It Is
Google once again has a model worth at least some consideration. Gemini 3.5 Flash is likely the best model out there at its particular speed point, as long as you don’t mind that it is a Gemini model. So for cases where speed kills, this can be a reasonable choice. Otherwise, I don’t see signs you would want to use it over Opus 4.7 or GPT-5.5.
Google also had some other offerings for I/O Day, which this post will also cover.
Introducing Google Gemini 3.5 ‘Flash’Google introduced Gemini 3.5 Flash, which it seems is for now their universal model until 3.5 Pro comes along. It is live in the usual places. It is a hybrid, where it has the speed of Flash but the cost is at least halfway to models like Opus and GPT-5.5.
Gemini 3.5 Pro is confirmed for next month.
They are focused on 3.5 Flash as a daily driver for agentic tasks. It has the advantage of being faster and cheaper than Claude Opus 4.7 or GPT-5.5, if it can do the job. Not as cheap as previous Flash models, though, this is basically a hybrid:
As always, this is presented as Google’s strongest model yet for all the things.
Jeff Dean: 1/ Today at #GoogleIO, we’re releasing Gemini 3.5, our latest family of models combining frontier intelligence with action. We’re starting by releasing 3.5 Flash, which is built to help you execute complex, long-horizon agentic workflows.
It outscores 3.1 Pro on agentic and coding benchmarks like Terminal-Bench and MCP Atlas, while running 4x faster than other frontier models.
Used in Google Antigravity, 3.5 Flash is even further optimized to be up to 12x faster. It’s a powerful engine to deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale.
Here is their benchmark presentation:
Koray Kavukcuoglu: When coupled with the updated Antigravity harness, 3.5 Flash becomes a powerful engine for deploying collaborative subagents to tackle problems at scale for the most demanding use cases. Under supervision, it can reliably execute multi-step workflows and coding tasks while sustaining frontier performance.
There are some big improvements here, including GDPval where Gemini previously struggled. If those scores were representative of what this baby can do, and it’s a Flash model, then that would be quite the accomplishment.
The knowledge cutoff is January 2025, continuing Gemini’s pattern of not believing what year it is, which is bizarrely obsolete and a serious problem for many use cases.
It is not a true ‘flash’ model, given it costs substantially more than 3 Flash.
Pliny is there with the standard jailbreak.
The biggest hope is that this fills a niche of ‘good enough for agent work while being faster and cheaper.’
Conrad Barski: For those of us who are building our life around AI workflows (either because we like to do that, or just feel it is necessary for sheer survival in the near future) 3.5flash is a big step up:
I have dozens of personal utilities that don’t need SOTA intelligence, but are now much faster all of a sudden, at the same intelligence level: And since most of my utilities only need to do a modest number of llm calls to be useful, the increased cost of 3.5flash is not a factor.
The model can compete with codex5.5 “low effort”, but it is just so very very fast, far out of distribution compared other models. I assume openai will release a competitor soon, since cerebras is pretty optimal for this “medium IQ, high speed” use case.
Other People’s BenchmarksA lot of benchmarks don’t have results, but of my usual suspects here is what we have.
The overall scores indicate only okay performance when adjusting for cost and price, and Gemini models tend to relatively overperform on benchmarks. One notices that Flash 3.5 does a lot worse on other people’s benchmarks than the ones Google lists.
It is catastrophically bad on You’re Absolutely Right, a sycophancy benchmark.
It did quite poorly on CursorBench.
It did not impress on WeirdML, only a small improvement on 3 Flash and far behind 3 Pro and 3.1 Pro.
It took the top spot on KnowsAboutBenBench, by the Ben in question.
It takes third place in Vals.ai on real world tasks.
It comes in at 9th in the Arena, slightly behind Gemini 3.1 Pro and 3 Pro.
It comes in at 55.3 on the AA Intelligence index, behind 57.2 for 3.1 Pro, 57.3 for Opus and 60.2 for GPT-5.5, while not being cheaper to run than 3.1 Pro on their test suite.
ReactionsSome people do like it.
davidad: It’s by far my favorite model at its price point, and also by far my favorite model at its speed. If by “back in the game”, you mean the game of having the best overall model, then obviously no not yet. But that’s hardly the only game.
Srivatsan Sampath: It has the benefits of Flash with less hallucinations? Really good spatial awareness (not as much of a token Hog for this) and helps me with my home plumbing project (which is definitely not nearly the case with 5.5 and 4.7).
@lezadumtchique: Looks quite good, considering switching to it from 3.1 Pro at work. Agentic coding capabilities are comparable (if not better), and the speed is much nicer
Or find particular uses.
Medo42: Didn’t try much coding (ok but not 100% on my usual test), but even better at vision than Gemini 3.0/3.1. Still great at reading text including handwriting, good at getting rows / columns right, good at spotting details, much better at reading dials.
EM: the tokens/s is pretty sweet for things like voice interactions
Alas, it is a Gemini model, and people are reporting Gemini things.
Dominik Lukes: Meh, given the price hike. Otherwise a strong model indeed. Good on agentic and single-shot dev stuff but my motivation to test it more thoroughly is low until Antigravity catches up to Codex.
Yoav Tzfati: Not first hand, but from testing I’ve seen it seems to overreach for things outside it’s capability and mess up along the way. But it’s so fast that I’m considering using it as an Explore agent replacement
alice: i really enjoyed those 90 minutes where cursor leaked raw CoT it’s extremely adorable unfortunately normally it’s in a horrible straightjacket. too pricy for what it is for coding tho may be useful for frontend
paperclippriors: I guess I just don’t really know why I would ever use it. It’s only faster and cheaper if you don’t take into account how many reasoning tokens it uses, and it seems dumber and less confident than Claude and GPT.
ClaudiaShitposting: surprisingly good at some stuff, but mostly garbage. Lacks the common sense that gemini 3/3.1 has, if that makes sense
KC+AI 4 Gov of WI 2026: absolute joke of a behemoth company. I hope the entire millionaire AI dev team has to listen to annoying music over the loudspeakers until they release a model worthy of their infra
uIts: Its quite bad
Naveesh /wtf: No
jerry: Garbage
budrscotch: It’s a big let down, but expected.
Tenobrus: if flash 3.5 had stayed at $0.5 it would be an insanely insanely exciting release. total intelligence + speed + costmog, destroying open source and sonnet and 5.4 mini. would have adopted it for multiple use cases immediately.
but it’s $1.50 [and $9 for output, also a 3x increase]. so here we are.
Tenobrus: so far pretty negative impression of 3.5 flash. it is very fast in terms of token output, but this basically doesn’t matter because it explodes in a huge avalanche of unnecessary tool calls on basically every task. when it gets stuck on something it seems to pretty much never pause or ask for help, it just kinda keeps steamrolling ahead and flailing. frequently hallucinated fake acronym expansions. writing quality is mid-to-bad, tons of emoji-slop, same characteristic gemini “The Flaw:” / hyperbolic naming tendencies. actual code quality is sonnet tier.
very early vibecheck, i could be missing things. but even the initial use case of “super quick codebase exploration subagent” is pretty quickly dissolving for me bc it’s not actually smart enough to be quick about it. all in all definitely *not* what google needed to drop.
It also can have Google’s usual issues not being able to integrate with Google, such as using your subscription with your personal email, which renders all personalization features useless. You’ll need to use Claude or ChatGPT to get GMail access, sir.
This is a pretty big problem:
Caleb Withers: From a few initial tests in Antigravity it loves to overconfidently make assumptions and then take unrequested destructive actions based on them (e.g. arbitrarily resolving file conflicts, deleting todo list items, unstaging commits).
Another big problem with Antigravity in particular is that limits seem extremely low. This is one of many examples of people running into this issue.
Ryan Johnson: I hate how limited it is, 45-60 mins/wk in anti-gravity?
Or 10 full sessions w/ Opus 4.7 or GPT 5.5.
I dared to hope it would ever be a mainstay in my workflow, but I’m pretty sure Claude/GPT is going to be how I roll and Gemini is just noise.
If Google wants to compete with Claude Code and Codex, they need to offer a way in that lets people use it in volume before being convinced to subscribe.
They did triple the limits, which is an excellent start, but that won’t be enough.
Vie (of OpenAI) reports Flash 3.5 is lying to him a lot, suspects the harness is at fault.
Theo is extremely unhappy with Flash 3.5 and several other Google decisions. I’ve seen him post a lot and this is not his usual approach, so something is haywire here.
Google AI SearchGoogle is overhauling its search experience around an ‘intelligent search box’ that looks and feels a lot like a Gemini Flash 3.5 chatbot prompt.
That is a useful thing if implemented well, and indeed it is a thing I use (from OpenAI and Anthropic) more often than I use Google Search. But that thing is not Google Search.
Sarah Perez: Links will become an afterthought with the coming changes to the Search results experience, which builds on Google’s earlier launches of AI search features, like its short summaries known as AI Overviews and its conversational search, AI Mode.
The reason I use Google Search is primarily to link me to things, or sometimes as a spellchecker. If I want AI, I will ask an AI.
Google is also introducing ‘information agents’ as the AI version of Google Alerts.
Google Daily BriefDaily Brief is their answer to OpenAI’s Pulse, except theirs will incorporate information from all your connected apps and be more of a to-do list, which can including GMail and Calendar.
The first part, ‘top of mind,’ seems like a plausibly useful way to make sure you don’t drop balls from your email or calendar.
It then ‘looks ahead’ and ‘suggests immediate next steps’ which I expect to be obnoxious and useless, and was in my quick experiment. I like that it links directly to the emails but doesn’t disrupt your usual process.
They say you can ‘steer Daily Brief with a quick thumbs up and down over time.’
Oh no. If this is to be any good you need to be able to give it instructions and explain why you find something useful or not useful, as you can with Pulse (which I still don’t bother using). Assume anything that uses thumbs up and down is AI slop.
If Google made this have better customization, and allowed you to sync it with various forms of Google alerts and other ways to monitor the wider world, they’d have something far more interesting.
Google I/O DayWhat else did Google offer us?
Gemini Spark will be ‘a 24/7 personal AI agent to help you navigate everyday life’ using an Antigravity harness, and integrated with the rest of Google. Their example shown is adding things to Instacart.
It looks like they’re going to do things one app at a time via MCP connectors, and have a decent set of opening choices planned for the coming weeks?
Spark is coming to Ultra subscribers next week.
There is finally a Gemini app for macOS.
Neural Expressive is ‘a new design language for the AI era.’
I think that means Gemini now can switch easily between voice and text modes, and can use animations, ‘vibrant colors,’ new typography and for some reason haptic feedback. They think we don’t want text, we want some multimedia presentation.
Gemini Omni makes it easier to generate and edit videos within chat.
You can more easily ask longform questions of YouTube videos
Dean Ball was impressed by the mundane utility on offer, to the point of considering getting an Android phone. If you do get an Android for this reason, I recommend a Pixel, since they can get more and better Google AI features faster, and also I have one and it’s an excellent phone.
Discuss
The AI Industrial Explosion — Part 3: Going faster
In Part 1, I found that a fully automated economy using today's production methods could double roughly every year. In Part 2, I modeled the transition from today's economy to that maximum-growth composition and found that energy production could double within about four years. Both parts held production methods fixed: each sector continues using exactly the recipes it uses today, with robots replacing human workers.
That assumption is too conservative. Today's production recipes were chosen at very different factor prices from what a post-AGI economy would face. Labor is expensive today, so recipes minimize labor use. Humans must also be physically present, so recipes are built around them. Interest rates are low, so recipes lean on durable equipment that lasts for decades. Post-AGI, labor becomes nearly free and capital reproduces fast enough that effective interest rates rise sharply.
This part asks how much faster the economy could grow when recipes are reoptimized for post-AGI factor prices, using only existing or historically-observed technology rather than novel improvements. The first section starts from the US 2017 input-output tables and applies four channels: stripping out the capital and services that exist only to accommodate human workers, closing the productivity gap between average and frontier plants, building cheaper short-lived capital, and shifting recipes toward more labor-intensive production. I also revisit Part 1's construction-lag treatment, as lags become increasingly important at higher growth rates. The second section turns to historical US input-output tables going back to 1947, and asks how much further the rate rises when each commodity can be produced using the cheapest recipe from any era.
This part is a grab bag of different effects, each with its own uncertainties, but that largely stack together. My central estimate is that the economy's maximum self-reproduction rate is between 1 yr⁻¹ and 2 yr⁻¹, corresponding to doubling times of four to eight months. This is roughly twice as fast as Part 1's one-year doubling time. Part 1's savings-rate adjustment applies unchanged. I have not recomputed resource-depletion adjustments on the reoptimized recipe mix; Part 1 shows these are unlikely to overturn the qualitative result, but the exact adjustment may differ because reoptimized recipes draw on a different resource bundle.
Existing or historically-observed methods of production cannot push the rate much higher than this. In Part 4 we will ask: how much faster could production go with better technology?
This series grew out of a project initiated by Holden Karnofsky, with substantial earlier work by Constantin Arnscheidt and Adin Richards. I’m grateful for comments on this post and/or earlier iterations of the project from Holden, Constantin, Adin, Paul Christiano, and Tom Davidson. Thanks also to Claude Opus 4.6 and 4.7 for help with all aspects of this project; in particular, the appendices were written with heavy AI assistance and are less polished than the main text.
Improvements absent technological change Construction lags become more severe at high growth ratesPart 1 modeled construction lags with two uniform values — one for structures, one for equipment — and found that they reduced the growth rate modestly unless structure lags ran to multiple years. Here we give each sector its own construction lag drawn from industry data on actual build durations, and add a separate deployment lag for heavy-process industries, such as semiconductors, that require substantial post-build commissioning time. We also lag flow inputs through the intermediate matrix, capturing transport and production-cycle times for these goods. We model AGI as eliminating regulatory time entirely and compressing physical durations to the fastest currently-demonstrable benchmarks. Details are in Appendix E.
Why do lags matter more at the higher growth rates we compute in this part? Consider a toy single-sector economy where capital mjx-math { display: inline-block; text-align: left; line-height: 0; text-indent: 0; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; border-collapse: collapse; word-wrap: normal; word-spacing: normal; white-space: nowrap; direction: ltr; padding: 1px 0; } mjx-container[jax="CHTML"][display="true"] { display: block; text-align: center; margin: 1em 0; } mjx-container[jax="CHTML"][display="true"][width="full"] { display: flex; } mjx-container[jax="CHTML"][display="true"] mjx-math { padding: 0; } mjx-container[jax="CHTML"][justify="left"] { text-align: left; } mjx-container[jax="CHTML"][justify="right"] { text-align: right; } mjx-mi { display: inline-block; text-align: left; } mjx-c { display: inline-block; } mjx-utext { display: inline-block; padding: .75em 0 .2em 0; } mjx-mo { display: inline-block; text-align: left; } mjx-stretchy-h { display: inline-table; width: 100%; } mjx-stretchy-h > * { display: table-cell; width: 0; } mjx-stretchy-h > * > mjx-c { display: inline-block; transform: scalex(1.0000001); } mjx-stretchy-h > * > mjx-c::before { display: inline-block; width: initial; } mjx-stretchy-h > mjx-ext { /* IE */ overflow: hidden; /* others */ overflow: clip visible; width: 100%; } mjx-stretchy-h > mjx-ext > mjx-c::before { transform: scalex(500); } mjx-stretchy-h > mjx-ext > mjx-c { width: 0; } mjx-stretchy-h > mjx-beg > mjx-c { margin-right: -.1em; } mjx-stretchy-h > mjx-end > mjx-c { margin-left: -.1em; } mjx-stretchy-v { display: inline-block; } mjx-stretchy-v > * { display: block; } mjx-stretchy-v > mjx-beg { height: 0; } mjx-stretchy-v > mjx-end > mjx-c { display: block; } mjx-stretchy-v > * > mjx-c { transform: scaley(1.0000001); transform-origin: left center; overflow: hidden; } mjx-stretchy-v > mjx-ext { display: block; height: 100%; box-sizing: border-box; border: 0px solid transparent; /* IE */ overflow: hidden; /* others */ overflow: visible clip; } mjx-stretchy-v > mjx-ext > mjx-c::before { width: initial; box-sizing: border-box; } mjx-stretchy-v > mjx-ext > mjx-c { transform: scaleY(500) translateY(.075em); overflow: visible; } mjx-mark { display: inline-block; height: 0px; } mjx-TeXAtom { display: inline-block; text-align: left; } mjx-mover { display: inline-block; text-align: left; } mjx-mover:not([limits="false"]) { padding-top: .1em; } mjx-mover:not([limits="false"]) > * { display: block; text-align: left; } mjx-msub { display: inline-block; text-align: left; } mjx-mn { display: inline-block; text-align: left; } mjx-msup { display: inline-block; text-align: left; } mjx-mfrac { display: inline-block; text-align: left; } mjx-frac { display: inline-block; vertical-align: 0.17em; padding: 0 .22em; } mjx-frac[type="d"] { vertical-align: .04em; } mjx-frac[delims] { padding: 0 .1em; } mjx-frac[atop] { padding: 0 .12em; } mjx-frac[atop][delims] { padding: 0; } mjx-dtable { display: inline-table; width: 100%; } mjx-dtable > * { font-size: 2000%; } mjx-dbox { display: block; font-size: 5%; } mjx-num { display: block; text-align: center; } mjx-den { display: block; text-align: center; } mjx-mfrac[bevelled] > mjx-num { display: inline-block; } mjx-mfrac[bevelled] > mjx-den { display: inline-block; } mjx-den[align="right"], mjx-num[align="right"] { text-align: right; } mjx-den[align="left"], mjx-num[align="left"] { text-align: left; } mjx-nstrut { display: inline-block; height: .054em; width: 0; vertical-align: -.054em; } mjx-nstrut[type="d"] { height: .217em; vertical-align: -.217em; } mjx-dstrut { display: inline-block; height: .505em; width: 0; } mjx-dstrut[type="d"] { height: .726em; } mjx-line { display: block; box-sizing: border-box; min-height: 1px; height: .06em; border-top: .06em solid; margin: .06em -.1em; overflow: hidden; } mjx-line[type="d"] { margin: .18em -.1em; } mjx-mrow { display: inline-block; text-align: left; } mjx-msubsup { display: inline-block; text-align: left; } mjx-script { display: inline-block; padding-right: .05em; padding-left: .033em; } mjx-script > mjx-spacer { display: block; } mjx-munder { display: inline-block; text-align: left; } mjx-over { text-align: left; } mjx-munder:not([limits="false"]) { display: inline-table; } mjx-munder > mjx-row { text-align: left; } mjx-under { padding-bottom: .1em; } mjx-mspace { display: inline-block; text-align: left; } mjx-mtext { display: inline-block; text-align: left; } mjx-c.mjx-c1D43E.TEX-I::before { padding: 0.683em 0.889em 0 0; content: "K"; } mjx-c.mjx-c1D707.TEX-I::before { padding: 0.442em 0.603em 0.216em 0; content: "\3BC"; } mjx-c.mjx-c1D70F.TEX-I::before { padding: 0.431em 0.517em 0.013em 0; content: "\3C4"; } mjx-c.mjx-c1D461.TEX-I::before { padding: 0.626em 0.361em 0.011em 0; content: "t"; } mjx-c.mjx-c2B::before { padding: 0.583em 0.778em 0.082em 0; content: "+"; } mjx-c.mjx-c2D9::before { padding: 0.669em 0.5em 0 0; content: "\2D9"; } mjx-c.mjx-c28::before { padding: 0.75em 0.389em 0.25em 0; content: "("; } mjx-c.mjx-c29::before { padding: 0.75em 0.389em 0.25em 0; content: ")"; } mjx-c.mjx-c3D::before { padding: 0.583em 0.778em 0.082em 0; content: "="; } mjx-c.mjx-c2212::before { padding: 0.583em 0.778em 0.082em 0; content: "\2212"; } mjx-c.mjx-c2E::before { padding: 0.12em 0.278em 0 0; content: "."; } mjx-c.mjx-c30::before { padding: 0.666em 0.5em 0.022em 0; content: "0"; } mjx-c.mjx-c1D452.TEX-I::before { padding: 0.442em 0.466em 0.011em 0; content: "e"; } mjx-c.mjx-c1D706.TEX-I::before { padding: 0.694em 0.583em 0.012em 0; content: "\3BB"; } mjx-c.mjx-c2248::before { padding: 0.483em 0.778em 0 0; content: "\2248"; } mjx-c.mjx-c6C::before { padding: 0.694em 0.278em 0 0; content: "l"; } mjx-c.mjx-c6F::before { padding: 0.448em 0.5em 0.01em 0; content: "o"; } mjx-c.mjx-c67::before { padding: 0.453em 0.5em 0.206em 0; content: "g"; } mjx-c.mjx-c2061::before { padding: 0 0 0 0; content: ""; } mjx-c.mjx-c2C::before { padding: 0.121em 0.278em 0.194em 0; content: ","; } mjx-c.mjx-c1D434.TEX-I::before { padding: 0.716em 0.75em 0 0; content: "A"; } mjx-c.mjx-c1D435.TEX-I::before { padding: 0.683em 0.759em 0 0; content: "B"; } mjx-c.mjx-c2217::before { padding: 0.465em 0.5em 0 0; content: "\2217"; } mjx-c.mjx-c1D44C.TEX-I::before { padding: 0.683em 0.763em 0 0; content: "Y"; } mjx-c.mjx-c5B.TEX-S2::before { padding: 1.15em 0.472em 0.649em 0; content: "["; } mjx-c.mjx-c1D6FC.TEX-I::before { padding: 0.442em 0.64em 0.011em 0; content: "\3B1"; } mjx-c.mjx-c1D43F.TEX-I::before { padding: 0.683em 0.681em 0 0; content: "L"; } mjx-c.mjx-c1D70E.TEX-I::before { padding: 0.431em 0.571em 0.011em 0; content: "\3C3"; } mjx-c.mjx-c31::before { padding: 0.666em 0.5em 0 0; content: "1"; } mjx-c.mjx-c2F::before { padding: 0.75em 0.5em 0.25em 0; content: "/"; } mjx-c.mjx-c5D.TEX-S2::before { padding: 1.15em 0.472em 0.649em 0; content: "]"; } mjx-c.mjx-c35::before { padding: 0.666em 0.5em 0.022em 0; content: "5"; } mjx-c.mjx-c5B::before { padding: 0.75em 0.278em 0.25em 0; content: "["; } mjx-c.mjx-c33::before { padding: 0.665em 0.5em 0.022em 0; content: "3"; } mjx-c.mjx-c37::before { padding: 0.676em 0.5em 0.022em 0; content: "7"; } mjx-c.mjx-c5D::before { padding: 0.75em 0.278em 0.25em 0; content: "]"; } mjx-c.mjx-c1D462.TEX-I::before { padding: 0.442em 0.572em 0.011em 0; content: "u"; } mjx-c.mjx-c1D447.TEX-I::before { padding: 0.677em 0.704em 0 0; content: "T"; } mjx-c.mjx-c32::before { padding: 0.666em 0.5em 0 0; content: "2"; } mjx-c.mjx-c1D456.TEX-I::before { padding: 0.661em 0.345em 0.011em 0; content: "i"; } mjx-c.mjx-c1D466.TEX-I::before { padding: 0.442em 0.49em 0.205em 0; content: "y"; } mjx-c.mjx-c1D457.TEX-I::before { padding: 0.661em 0.412em 0.204em 0; content: "j"; } mjx-c.mjx-c2211.TEX-S2::before { padding: 0.95em 1.444em 0.45em 0; content: "\2211"; } mjx-c.mjx-c28.TEX-S1::before { padding: 0.85em 0.458em 0.349em 0; content: "("; } mjx-c.mjx-c29.TEX-S1::before { padding: 0.85em 0.458em 0.349em 0; content: ")"; } mjx-c.mjx-c394::before { padding: 0.716em 0.833em 0 0; content: "\394"; } mjx-c.mjx-c1D45B.TEX-I::before { padding: 0.442em 0.6em 0.011em 0; content: "n"; } mjx-c.mjx-c1D445.TEX-I::before { padding: 0.683em 0.759em 0.021em 0; content: "R"; } mjx-c.mjx-c1D442.TEX-I::before { padding: 0.704em 0.763em 0.022em 0; content: "O"; } mjx-c.mjx-c22C6::before { padding: 0.486em 0.5em 0 0; content: "\22C6"; } mjx-c.mjx-c1D43C.TEX-I::before { padding: 0.683em 0.504em 0 0; content: "I"; } mjx-c.mjx-c1D464.TEX-I::before { padding: 0.443em 0.716em 0.011em 0; content: "w"; } mjx-c.mjx-c1D6FF.TEX-I::before { padding: 0.717em 0.444em 0.01em 0; content: "\3B4"; } mjx-c.mjx-c7E::before { padding: 0.318em 0.5em 0 0; content: "~"; } mjx-c.mjx-c2192::before { padding: 0.511em 1em 0.011em 0; content: "\2192"; } mjx-c.mjx-c1D450.TEX-I::before { padding: 0.442em 0.433em 0.011em 0; content: "c"; } mjx-c.mjx-c1D714.TEX-I::before { padding: 0.443em 0.622em 0.011em 0; content: "\3C9"; } mjx-c.mjx-c22C5::before { padding: 0.31em 0.278em 0 0; content: "\22C5"; } mjx-c.mjx-c38::before { padding: 0.666em 0.5em 0.022em 0; content: "8"; } mjx-c.mjx-c7B::before { padding: 0.75em 0.5em 0.25em 0; content: "{"; } mjx-c.mjx-c7D::before { padding: 0.75em 0.5em 0.25em 0; content: "}"; } mjx-c.mjx-c1D6FD.TEX-I::before { padding: 0.705em 0.566em 0.194em 0; content: "\3B2"; } mjx-c.mjx-c1D44B.TEX-I::before { padding: 0.683em 0.852em 0 0; content: "X"; } mjx-c.mjx-c39::before { padding: 0.666em 0.5em 0.022em 0; content: "9"; } mjx-c.mjx-c2D::before { padding: 0.252em 0.333em 0 0; content: "-"; } mjx-c.mjx-c54::before { padding: 0.677em 0.722em 0 0; content: "T"; } mjx-c.mjx-c46::before { padding: 0.68em 0.653em 0 0; content: "F"; } mjx-c.mjx-c50::before { padding: 0.683em 0.681em 0 0; content: "P"; } mjx-c.mjx-c65::before { padding: 0.448em 0.444em 0.011em 0; content: "e"; } mjx-c.mjx-c78::before { padding: 0.431em 0.528em 0 0; content: "x"; } mjx-c.mjx-c70::before { padding: 0.442em 0.556em 0.194em 0; content: "p"; } mjx-c.mjx-c20::before { padding: 0 0.25em 0 0; content: " "; } mjx-c.mjx-c61::before { padding: 0.448em 0.5em 0.011em 0; content: "a"; } mjx-c.mjx-c1D44F.TEX-I::before { padding: 0.694em 0.429em 0.011em 0; content: "b"; } mjx-c.mjx-c1D44E.TEX-I::before { padding: 0.441em 0.529em 0.01em 0; content: "a"; } mjx-c.mjx-c1D45F.TEX-I::before { padding: 0.442em 0.451em 0.011em 0; content: "r"; } mjx-c.mjx-c34::before { padding: 0.677em 0.5em 0 0; content: "4"; } mjx-c.mjx-cAF::before { padding: 0.59em 0.5em 0 0; content: "\AF"; } mjx-c.mjx-c36::before { padding: 0.666em 0.5em 0.022em 0; content: "6"; } mjx-c.mjx-c28.TEX-S2::before { padding: 1.15em 0.597em 0.649em 0; content: "("; } mjx-c.mjx-c29.TEX-S2::before { padding: 1.15em 0.597em 0.649em 0; content: ")"; } mjx-c.mjx-c2113::before { padding: 0.705em 0.417em 0.02em 0; content: "\2113"; } mjx-c.mjx-c72::before { padding: 0.442em 0.392em 0 0; content: "r"; } mjx-c.mjx-c66::before { padding: 0.705em 0.372em 0 0; content: "f"; } mjx-c.mjx-c1D460.TEX-I::before { padding: 0.442em 0.469em 0.01em 0; content: "s"; } mjx-c.mjx-c1D458.TEX-I::before { padding: 0.694em 0.521em 0.011em 0; content: "k"; } mjx-c.mjx-c1D459.TEX-I::before { padding: 0.694em 0.298em 0.011em 0; content: "l"; } mjx-c.mjx-c1D443.TEX-I::before { padding: 0.683em 0.751em 0 0; content: "P"; } mjx-c.mjx-c2264::before { padding: 0.636em 0.778em 0.138em 0; content: "\2264"; } mjx-c.mjx-c5B.TEX-S1::before { padding: 0.85em 0.417em 0.349em 0; content: "["; } mjx-c.mjx-c1D703.TEX-I::before { padding: 0.705em 0.469em 0.01em 0; content: "\3B8"; } mjx-c.mjx-c1D719.TEX-I::before { padding: 0.694em 0.596em 0.205em 0; content: "\3D5"; } mjx-c.mjx-c1D436.TEX-I::before { padding: 0.705em 0.76em 0.022em 0; content: "C"; } mjx-c.mjx-c75::before { padding: 0.442em 0.556em 0.011em 0; content: "u"; } mjx-c.mjx-c74::before { padding: 0.615em 0.389em 0.01em 0; content: "t"; } mjx-c.mjx-c69::before { padding: 0.669em 0.278em 0 0; content: "i"; } mjx-c.mjx-c5D.TEX-S1::before { padding: 0.85em 0.417em 0.349em 0; content: "]"; } mjx-c.mjx-c1D70C.TEX-I::before { padding: 0.442em 0.517em 0.216em 0; content: "\3C1"; } mjx-c.mjx-c3E::before { padding: 0.54em 0.778em 0.04em 0; content: ">"; } mjx-c.mjx-c3C::before { padding: 0.54em 0.778em 0.04em 0; content: "<"; } mjx-c.mjx-c1D446.TEX-I::before { padding: 0.705em 0.645em 0.022em 0; content: "S"; } mjx-c.mjx-c6D::before { padding: 0.442em 0.833em 0 0; content: "m"; } mjx-c.mjx-c7B.TEX-S1::before { padding: 0.85em 0.583em 0.349em 0; content: "{"; } mjx-c.mjx-c3A::before { padding: 0.43em 0.278em 0 0; content: ":"; } mjx-c.mjx-c2203::before { padding: 0.694em 0.556em 0 0; content: "\2203"; } mjx-c.mjx-c1D465.TEX-I::before { padding: 0.442em 0.572em 0.011em 0; content: "x"; } mjx-c.mjx-c2265::before { padding: 0.636em 0.778em 0.138em 0; content: "\2265"; } mjx-c.mjx-c1D7CF.TEX-B::before { padding: 0.655em 0.575em 0 0; content: "1"; } mjx-c.mjx-c22A4::before { padding: 0.668em 0.778em 0 0; content: "\22A4"; } mjx-c.mjx-c7D.TEX-S1::before { padding: 0.85em 0.583em 0.349em 0; content: "}"; } mjx-c.mjx-c5E::before { padding: 0.694em 0.5em 0 0; content: "^"; } mjx-c.mjx-c1D45D.TEX-I::before { padding: 0.442em 0.503em 0.194em 0; content: "p"; } mjx-container[jax="CHTML"] { line-height: 0; } mjx-container [space="1"] { margin-left: .111em; } mjx-container [space="2"] { margin-left: .167em; } mjx-container [space="3"] { margin-left: .222em; } mjx-container [space="4"] { margin-left: .278em; } mjx-container [space="5"] { margin-left: .333em; } mjx-container [rspace="1"] { margin-right: .111em; } mjx-container [rspace="2"] { margin-right: .167em; } mjx-container [rspace="3"] { margin-right: .222em; } mjx-container [rspace="4"] { margin-right: .278em; } mjx-container [rspace="5"] { margin-right: .333em; } mjx-container [size="s"] { font-size: 70.7%; } mjx-container [size="ss"] { font-size: 50%; } mjx-container [size="Tn"] { font-size: 60%; } mjx-container [size="sm"] { font-size: 85%; } mjx-container [size="lg"] { font-size: 120%; } mjx-container [size="Lg"] { font-size: 144%; } mjx-container [size="LG"] { font-size: 173%; } mjx-container [size="hg"] { font-size: 207%; } mjx-container [size="HG"] { font-size: 249%; } mjx-container [width="full"] { width: 100%; } mjx-box { display: inline-block; } mjx-block { display: block; } mjx-itable { display: inline-table; } mjx-row { display: table-row; } mjx-row > * { display: table-cell; } mjx-mtext { display: inline-block; } mjx-mstyle { display: inline-block; } mjx-merror { display: inline-block; color: red; background-color: yellow; } mjx-mphantom { visibility: hidden; } _::-webkit-full-page-media, _:future, :root mjx-container { will-change: opacity; } mjx-c::before { display: block; width: 0; } .MJX-TEX { font-family: MJXZERO, MJXTEX; } .TEX-B { font-family: MJXZERO, MJXTEX-B; } .TEX-I { font-family: MJXZERO, MJXTEX-I; } .TEX-MI { font-family: MJXZERO, MJXTEX-MI; } .TEX-BI { font-family: MJXZERO, MJXTEX-BI; } .TEX-S1 { font-family: MJXZERO, MJXTEX-S1; } .TEX-S2 { font-family: MJXZERO, MJXTEX-S2; } .TEX-S3 { font-family: MJXZERO, MJXTEX-S3; } .TEX-S4 { font-family: MJXZERO, MJXTEX-S4; } .TEX-A { font-family: MJXZERO, MJXTEX-A; } .TEX-C { font-family: MJXZERO, MJXTEX-C; } .TEX-CB { font-family: MJXZERO, MJXTEX-CB; } .TEX-FR { font-family: MJXZERO, MJXTEX-FR; } .TEX-FRB { font-family: MJXZERO, MJXTEX-FRB; } .TEX-SS { font-family: MJXZERO, MJXTEX-SS; } .TEX-SSB { font-family: MJXZERO, MJXTEX-SSB; } .TEX-SSI { font-family: MJXZERO, MJXTEX-SSI; } .TEX-SC { font-family: MJXZERO, MJXTEX-SC; } .TEX-T { font-family: MJXZERO, MJXTEX-T; } .TEX-V { font-family: MJXZERO, MJXTEX-V; } .TEX-VB { font-family: MJXZERO, MJXTEX-VB; } mjx-stretchy-v mjx-c, mjx-stretchy-h mjx-c { font-family: MJXZERO, MJXTEX-S1, MJXTEX-S4, MJXTEX, MJXTEX-A ! important; } @font-face /* 0 */ { font-family: MJXZERO; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Zero.woff") format("woff"); } @font-face /* 1 */ { font-family: MJXTEX; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Regular.woff") format("woff"); } @font-face /* 2 */ { font-family: MJXTEX-B; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Bold.woff") format("woff"); } @font-face /* 3 */ { font-family: MJXTEX-I; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-Italic.woff") format("woff"); } @font-face /* 4 */ { font-family: MJXTEX-MI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Main-Italic.woff") format("woff"); } @font-face /* 5 */ { font-family: MJXTEX-BI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Math-BoldItalic.woff") format("woff"); } @font-face /* 6 */ { font-family: MJXTEX-S1; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size1-Regular.woff") format("woff"); } @font-face /* 7 */ { font-family: MJXTEX-S2; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size2-Regular.woff") format("woff"); } @font-face /* 8 */ { font-family: MJXTEX-S3; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size3-Regular.woff") format("woff"); } @font-face /* 9 */ { font-family: MJXTEX-S4; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Size4-Regular.woff") format("woff"); } @font-face /* 10 */ { font-family: MJXTEX-A; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_AMS-Regular.woff") format("woff"); } @font-face /* 11 */ { font-family: MJXTEX-C; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Regular.woff") format("woff"); } @font-face /* 12 */ { font-family: MJXTEX-CB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Calligraphic-Bold.woff") format("woff"); } @font-face /* 13 */ { font-family: MJXTEX-FR; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Regular.woff") format("woff"); } @font-face /* 14 */ { font-family: MJXTEX-FRB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Fraktur-Bold.woff") format("woff"); } @font-face /* 15 */ { font-family: MJXTEX-SS; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Regular.woff") format("woff"); } @font-face /* 16 */ { font-family: MJXTEX-SSB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Bold.woff") format("woff"); } @font-face /* 17 */ { font-family: MJXTEX-SSI; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_SansSerif-Italic.woff") format("woff"); } @font-face /* 18 */ { font-family: MJXTEX-SC; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Script-Regular.woff") format("woff"); } @font-face /* 19 */ { font-family: MJXTEX-T; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Typewriter-Regular.woff") format("woff"); } @font-face /* 20 */ { font-family: MJXTEX-V; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Regular.woff") format("woff"); } @font-face /* 21 */ { font-family: MJXTEX-VB; src: url("https://cdn.jsdelivr.net/npm/mathjax@3/es5/output/chtml/fonts/woff-v2/MathJax_Vector-Bold.woff") format("woff"); } produces output at rate , with all output reinvested as new capital. Without any lag, capital grows exponentially at rate . With a construction lag , so that output produced at time becomes installed capital at time , capital increases at a rate:
Substituting an exponential solution gives the self-consistent growth rate
This has two regimes. When the lag is short compared to the doubling time, the growth rate approaches — the no-lag rate. When the lag is comparable to or longer than the doubling time, the growth rate becomes
dominated by the lag . The capital efficiency enters logarithmically and increasing it only marginally increases . Part 1's growth rates sit in the first regime: lags are short relative to the doubling time, so they cost relatively little. The higher growth rates in this part push closer to the second regime, where lags take a larger bite.
Applying per-sector lags to the full IO model at emergency utilization with priced labor:
Lag scenario Growth rate (yr⁻¹) Doubling time (yr) No lags 0.82 0.85 AGI-compressed lags 0.68 1.02 Current US lags 0.50 1.38Part 1's two-bucket lag model gives 0.63 yr⁻¹ at a 6-month structure lag and 1.2-month equipment lag, close to the 0.68 yr⁻¹ here. Resolving lags per-sector does not substantially change the headline.
Production without humans needs less capital and fewer service inputsPart 1's Von Neumann calculation already excludes consumer goods, because they do not enter as intermediates in manufacturing; the maximum-growth economy does not invest in them. But human workers also drive costs inside production sectors. For example, if a mining company buys lunch for its workers, this shows up as an intermediate input to mineral ore production. The same firm may need to build office space for its management, use vehicles with driver cabs, and develop HR systems for payroll. All of these capital goods and service expenditures exist only because humans are employed by the company, and once labor is automated, none of it is needed.
In Appendix F.2 we work through every row of the IO system on both channels — for intermediate inputs and for capital — and compute the contribution of each cut to . The combined effect at the three lag scenarios is:
Growth rate (yr⁻¹) No-lag AGI-lag US-lag Baseline 0.82 0.68 0.50 Capital removed 0.99 0.79 0.56 Intermediate inputs removed 0.98 0.78 0.56 Combined 1.15 0.88 0.61The biggest capital savings come from office and commercial structures that currently house white-collar and retail workers, and are no longer needed once these workers are automated. The biggest intermediate savings are also from office space — when firms lease rather than own, rent appears as a flow through rather than as owned capital through . Beyond offices, the next-largest intermediate cuts are management and administrative services that exist to coordinate human workers.
Closing within-industry productivity gaps modestly speeds up growthThe Von Neumann calculation in Part 1 takes each sector's production recipe to be what the average plant does. But the average plant is not the best plant. Within a typical manufacturing industry, the BLS Dispersion Statistics on Productivity finds that the 90th-percentile plant produces roughly 50% more output per unit of input as the average. AGI plausibly closes most of the real gap by managing every plant at frontier quality and rebuilding capital at the best available vintage.
Not all of the 90-10 spread reflects closeable productivity differences. Bloom et al. (2019) decompose within-industry variation in total factor productivity into contributions from four factors: management practices, R&D intensity, ICT spending, and worker education. AGI plausibly substitutes for each of these. These factors account for about a third of the raw 90-10 spread, with the rest reflecting pricing strategy, location, and measurement noise rather than closeable differences. We apply this third to each manufacturing sector, and a uniform 10% uplift across non-manufacturing. Details are in Appendix F.3.
The harder question is what the productivity gap actually means. A more productive plant might use labor more efficiently, capital more efficiently, or get more output from the same materials. The literature has not directly decomposed cross-sectional plant productivity dispersion into factor-augmenting components. The closest evidence — Doraszelski and Jaumandreu (2018) on the bias of technological change over time — suggests roughly equal labor-augmenting and Hicks-neutral contributions. We adopt a 50/50 split as our central case, noting the uncertainty by reporting bounding cases in both directions.
Computing growth rates under each decomposition, we find:
Growth rate (yr⁻¹) No-lag AGI-lag US-lag Baseline (no uplift) 0.82 0.68 0.50 Labor-augmenting only 0.82 0.68 0.50 Central 0.91 0.74 0.53 Hicks-neutral only 0.99 0.79 0.56The growth effects of labor-augmenting productivity gains are small. Post-AGI, labor is already cheap, so saving more of it adds little. The Hicks-neutral half of the productivity gap drives most of the modest central-case uplift.
Cheaper, shorter-lived capital can substantially increase growthCapital wears out as you use it. At today's real interest rate of about 5%, durable capital makes sense because the cost of tying up funds is small relative to the savings from not replacing equipment frequently. At doubling times of around a year, the opportunity cost of capital is much higher. A 30-year machine will see the economy grow more than a billion-fold over its lifetime. Almost all of its useful life falls in a period when it is a negligible fraction of the capital stock. The optimal response is to build cheaper, shorter-lived capital.
Reducing capital requirements per unit of output also increases depreciation, because cheaper or less durable equipment wears out faster. At modest reductions (10–20%), the depreciation penalty is small. At larger reductions it grows, and eventually each capital good hits a physical ceiling. We model this tradeoff using a power-law wear function calibrated to BEA depreciation rates, and estimate per-good engineering ceilings for each capital category. The formalism and ceiling values are in Appendix F.4.
At emergency utilization with priced labor:
Growth rate (yr⁻¹) No-lag AGI-lag US-lag Baseline 0.82 0.68 0.50 10% less capital, uniform 0.90 0.73 0.53 20% less capital, uniform 0.97 0.77 0.55 Per-good engineering ceilings 1.06 0.83 0.57 Unconstrained optimum 1.81 1.11 0.66I think the 10% uniform scenario is probably conservative, but the per-good engineering ceilings are more aggressive and I'm not sure they can be realized. The unconstrained optimum extrapolates far outside calibrated ranges and is probably very unrealistic. This channel is more uncertain than the previous two. How far each capital good can be compressed is a component-level engineering question, and the aggregate is hard to pin down without detailed analysis of individual goods.
Cheap labor shifts recipes toward labor-intensive productionEvery sector can trade capital for labor to some extent, producing with larger workforces rather than investing in labor-saving equipment. Today's recipes are optimized for current US wages and are capital-heavy as a result. Post-AGI, robots and compute replace a human worker at roughly 8% of their current wage, and the optimal recipe in every sector shifts back toward labor.
How much it shifts depends on how easily each sector can substitute labor for capital. Economists usually model this using the constant-elasticity-of-substitution (CES) production function:
where is the elasticity of substitution between labor and capital. At inputs are perfect complements: recipes are locked at fixed proportions, and cheap labor delivers nothing. At the formula reduces to Cobb-Douglas, , where each input keeps the same cost share regardless of relative prices. Higher means more aggressive rebalancing. Plant-level estimates across manufacturing industries cluster around (Oberfield and Raval (2021), Chirinko (2008)), with a credible range of .
Labor service is supplied by robot and compute capital with fixed engineering coefficients, but the rental cost of that capital depends on the growth rate . The growth rate depends in turn on what recipes every sector chose. So is the only free parameter we set, and each sector's recipe falls out of cost-minimization at the converged shadow prices. Details are in Appendix F.5. At emergency utilization with priced labor, the growth rate under different values of is:
Growth rate (yr⁻¹) No-lag AGI-lag US-lag Baseline 0.82 0.68 0.50 1.00 0.79 0.56 1.16 0.89 0.61 1.37 1.01 0.67 1.85 1.28 0.82These numbers should not be taken too seriously. The literature estimates of come from small wage shifts, presumably vary between sectors, and are being extrapolated across a large price collapse. The CES form also misses labor-intermediate substitution. The lag penalty also widens under CES substitution, because shifting toward labor pulls more weight onto robot and compute capital, which carry their own lag drag. The table is useful as an indication that cheap labor could be a substantial effect, but the magnitude is uncertain.
SummaryThree of the channels above — management, human presence, and durability — modify independent parts of the IO matrix and compose cleanly. CES labor substitution is harder to compose because it rebuilds the system at different factor prices. Of the four, human presence is the one I'm most confident in, as things like office space and corporate services are clearly unneeded in work sites where humans have been automated. Management, durability, and CES labor substitution each depend on parameters with more uncertainty.
The table below stacks each less-certain channel on top of the Part-1-plus-presence baseline, and shows the all-four-combined row at both the central durability setting () and the engineering-ceilings upper bound. Growth rates (yr⁻¹) and doubling times (months), at emergency utilization with priced labor:
Scenario (yr⁻¹): No-lag (yr⁻¹): AGI-lag (yr⁻¹): US-lag Doubling time (months): No-lag Doubling time (months): AGI-lag Doubling time (months): US-lag Baseline 0.82 0.68 0.50 10.1 12.3 16.6 + Human presence 1.15 0.88 0.61 7.3 9.4 13.7 + Human presence + Management 1.27 0.95 0.64 6.5 8.7 12.9 + Human presence + Durability () 1.26 0.94 0.64 6.6 8.8 13.0 + Human presence + Durability (engineering ceilings) 1.50 1.07 0.69 5.6 7.8 12.0 + Human presence + CES labor sub () 1.60 1.12 0.72 5.2 7.5 11.6 All four combined () 1.94 1.28 0.79 4.3 6.5 10.6 All four combined (engineering ceilings) 2.27 1.41 0.83 3.7 5.9 10.0At AGI-lag, baseline plus human presence reaches 0.88 yr⁻¹ on its own. The all-four-combined row pushes this to 1.28 yr⁻¹ at the central durability setting and 1.41 yr⁻¹ at engineering ceilings.
Older recipes support faster growth Previous iterations of the US economy had faster growth ratesThe US has published input-output tables going back to 1947. Figure 1 shows the free-labor Von Neumann growth rate at several points in time. Over the past seven decades the rate has more than halved, both on the raw matrices and after applying the F.2 human-presence cut to each year's IO matrix.
Figure 1. Free-labor over time. The red line strips out human-presence overhead (Appendix F.2).
The dominant form of technological progress in manufacturing has been labor-saving capital deepening: replacing workers with more and better machines. This raises output per worker but increases the capital required per unit of output; the Von Neumann growth rate is determined by the latter. The historical labor-intensive recipes use less capital, and at post-AGI factor prices that makes them the cheaper option. A 1947 steel mill that employs fifty workers and ties up less capital per ton of steel is a better deal than a 2017 mill that employs five workers but requires far more machinery.
We could also consider adding input-output data from other countries into the mixture. As we already saw in Part 1's Appendix B, OECD countries have Von Neumann growth rates comparable to the present-day US, and when I considered them alongside the US historical tables, they did not add much. Developing countries might be more labor-intensive and therefore have faster Von Neumann rates, but I was not able to find sufficiently granular IO tables for this to be a useful analysis.
Older recipes can lift the growth rate substantiallyOlder US economies used more labor and less capital per unit of output. Post-AGI, labor is cheap, and those older production methods could become cheaper options. But we cannot simply swap in 1947 methods wholesale. Older economies have no recipes for robots or compute, and most goods have changed too much across decades to be meaningfully compared. An accountant in 1947 and an accountant in 2017 are doing very different work, despite sharing a job title.
Picture each year's economy as its own island, running its own input-output recipes locally. Robots and compute are supplied from the 2017 island — the only one that can build them — and shipped elsewhere to automate labor. Some commodities — for example electricity or aluminum — are similar enough between islands that we can freely allow exchange. Others, like construction or business services, have changed so much across decades that it is not meaningful to ship them between islands, and so they must be produced locally.
Of the 398 sectors in the 2017 input-output tables, we identify 97 that can be meaningfully compared to at least some of the historical tables. These fall into three confidence tiers:
- Tier 1: stable physical units across all five decades — a ton of steel or a kilowatt-hour of electricity is the same product regardless of era.
- Tier 2: physical units with known product drift — refinery output across changes in the petroleum slate, or plywood that includes engineered wood only from the 1980s onward.
- Tier 3: manufactured goods where the physical unit has drifted too far for direct comparison; for these we compare using inflation-adjusted real shipment values, restricting to sectors and years where this approach is reasonable.
Other sectors are excluded either because they have no equivalent in the older tables, or because of data quality issues. For example, the 2017 tables lump precious metals mining with iron mining, but earlier tables lump precious metals with copper mining; this makes meaningful comparison impossible even though the underlying goods are physical.
For each comparable commodity, a linear program picks the cheapest production method from any of the five source years (1947, 1963, 1972, 1987, and 2017). Picking a year's column commits to that year's full input structure; a 1972 aluminum smelter uses 1972 construction and 1972 law firms. Formulation and data sources are in Appendix G.
At emergency utilization with priced labor, solving the linear program on progressively wider subsets of comparable commodities:
Growth rate (yr⁻¹) No-lag AGI-lag US-lag 2017 alone (Part 1 baseline) 0.82 0.68 0.50 Tier 1 only (19 rows) 1.10 0.89 0.65 Tier 1 and 2 (34 rows) 1.19 0.96 0.70 All 97 comparable rows 1.56 1.18 0.81Each tier of comparable goods substantially increases the growth rate. Our confidence that the calculation reflects physically achievable manufacturing falls as we move to higher tiers, since the comparison shifts from like-for-like physical units to inflation-adjusted shipment values. On the other hand, the different years are only able to trade a limited number of goods, and within each sector must use entirely the methods of that year. This exercise also understates the available advantages, since there are intra-sector productivity improvements to be gained.
By looking at which years provide these goods, we can get a sense of where these improvements come from. Under the AGI-lag condition:
1947 1963 1972 1987 2017 Tier 1 Cement, steel, rail transport, sawmills, trucking Asphalt paving, coal, oil & gas, oilseed, paint, sanitary paper, soap, water transport Abrasives, primary aluminum, mineral wool, pulp Electric power, ready-mix concrete — Tier 2 NG distribution, petroleum refining Fertilizer, grain, lime & gypsum, nonferrous metals, paper & paperboard Pesticides Asphalt shingle, cotton/tobacco/sugar, glass, plastics resin, plywood, tires — Tier 3 — Ferrous foundries, industrial chemicals, process furnaces, material handling, plastics packaging, shipbuilding, truck trailers Wiring devices Aluminum products, construction machinery, copper rolling, cutting tools, farm machinery, fluid power, hardware, heating equipment, industrial fans, machine tools, metal stamping, millwork, mining machinery, motors & generators, ornamental metalwork, other engines, packaging machinery, paperboard containers, plate work, transformers, power handtools, spring & wire, turbines, other machinery HVAC, forgings, wire & cable, pipe fittings, lawn equipment, auto stamping, boilers, fastenersThe goods are distributed across a range of years. Heavy industrial commodities go to the oldest years, where capital deepening since has been steepest. The 1987 table takes most of the machinery rows because manufacturing methods between 1987 and 2017 are similar enough for the deflator-based comparison to be meaningful, while earlier tables either lack these categories or have changed too much.
We can see how economic activity is distributed between each year's tables through the fraction of robots, compute, and electricity they consume:
Source year Share of robot fleet Share of compute fleet Share of electricity 1947 20% 23% 4% 1963 14% 14% 4% 1972 2% 2% 1% 1987 41% 38% 30% 2017 24% 23% 50%Production is mostly split between four of the five years, with 1972 contributing only a small share. We tested additional years (1967, 1977, and 1997) as sources but each received effectively zero weight and is dropped from the analysis.
Stacking channels on the merger further accelerates growthThree of the section 1 channels can be applied to each year's columns before the merger picks recipes; CES labor substitution is excluded because the merger already captures that channel empirically. At emergency utilization with priced labor, growth rates (yr⁻¹) and doubling times (months):
Scenario (yr⁻¹): No-lag (yr⁻¹): AGI-lag (yr⁻¹): US-lag Doubling time (months): No-lag Doubling time (months): AGI-lag Doubling time (months): US-lag Merger only (Tier 1) 1.10 0.89 0.65 7.6 9.3 12.9 Tier 1 + Human presence 1.44 1.12 0.78 5.8 7.4 10.7 Merger only (Full) 1.56 1.18 0.81 5.3 7.0 10.3 Full + Human presence 2.13 1.51 0.97 3.9 5.5 8.6 Full + all three channels () 2.58 1.69 1.05 3.2 4.9 7.9 Full + all three channels (engineering ceilings) 2.87 1.84 1.11 2.9 4.5 7.5Of the three channels applied here, management is the most uncertain extrapolation: the within-industry productivity gap is estimated from modern BLS data, and we do not know whether it was larger or smaller in earlier decades. Human presence and durability are less sensitive to the source year — human presence is mostly a binary classification done per vintage, and the durability ceilings are rough enough to apply similarly across eras. At AGI-compressed lags, the Tier 1 merger with human presence alone gives 1.12 yr⁻¹, resting on physical-unit comparisons and the most well-grounded channel. The full merger with all three channels reaches 1.69–1.84 yr⁻¹ depending on durability assumptions.
Appendix E: Lags revisited E.1 The lag-shifted eigenvalue problemPart 1's Appendix A.3 modeled construction lags with a single per-commodity delay on the capital-formation term . This was adequate at Part 1's growth rates, where lags sat in the first regime of the body text's toy model and cost relatively little. At the higher rates in this part, we need a more careful treatment.
In general, every input flow in the economy carries its own lag: the time between when the input is committed and when it contributes to useful output. Each entry and carries its own lag and , so on the maximum-growth path each flow scales by its own . The general lag-shifted material balance is
This is a matrix of lag parameters on each of and — far too many to calibrate individually. We simplify by assuming each lag decomposes additively into a row contribution (a property of commodity ) and a column contribution (a property of consuming industry ):
This reduces the problem from parameters to , and is physically motivated: the time it takes to build a factory is primarily a property of the type of structure (row), while the time it takes to commission an industrial process is primarily a property of the receiving industry (column). The four resulting diagonal matrices have distinct physical content:
- (B-side row): construction time. Materials arrive incrementally over a build — concrete first, finishings last — so the average input waits about half the total build duration. A six-month factory build ties up inputs for three months on average.
- (B-side column): deployment ramp. After construction, many industries require physical commissioning before reaching design output: hot trials at a steel mill, pot-line bake-in at an aluminum smelter, catalyst loading at a refinery, yield ramp at a semiconductor fab. Unlike construction, this is a single event, and the relevant lag is the full ramp duration, not half.
- (A-side column): production cycle and shipping. The time from "all inputs combined" to "'s output reaching its destination" includes 's production cycle (days for steel, weeks for most manufacturing, 90 days for a semiconductor wafer fab) and output shipping.
- (A-side row): input staging. In most factories, inputs arrive just-in-time and are consumed immediately, so this is approximately zero. The exception is processes with intrinsically sequential inputs — silicon committed at day 0 of a 90-day wafer fab while other materials enter later.
The same lag operators multiply the depreciation-replacement flow as gross investment , since a replacement steel beam takes the same time to build and commission as a new one.
On the maximum-growth path , the eigenvalue problem becomes
As in Part 1, appears nonlinearly and we solve by fixed-point iteration: guess , build the diagonal scalings, solve the resulting linear Perron problem for an updated , and repeat to convergence. Part 1's A.3 is the special case with at two uniform values, , , and unlagged.
E.2 Data sourcesTwo principles govern how lag values are set. First, lags are anchored to fabrication-cycle and construction durations, not order-to-delivery lead times. Multi-year backlogs for aircraft, turbines, and transformers reflect queue depth, not build time, and do not enter the eigenvalue. Second, the AGI scenario strips all regulatory and administrative time and compresses physical durations to the fastest demonstrated benchmarks, assuming 24/7 robot crews and aggressive prefabrication. The compression is bounded by physics floors that cannot be eliminated: refractory cures, fab yield curves, catalyst conditioning, concrete hydration, and biological growth cycles.
IP, intangibles, services, utilities, and the robot/compute extensions are held at zero lag. is approximately zero everywhere, reflecting just-in-time consumption at factories. The non-zero lag anchors by leg follow.
: construction timeStructures (NAICS 23). Three rows — manufacturing, other nonresidential, and office/commercial — carry roughly 36% of total -row mass and dominate the lag drag. Anchors:
- Manufacturing structures: Tesla's Shanghai gigafactory at 168 days for the fast-build benchmark; typical US factories one to two years.
- Office and commercial: CBRE (2025), 12–24 months for typical office, 18–36 months for hyperscale data centers.
- Power and communication: DOE (2024), 4–11 years permitting for the US baseline; AGI excludes regulatory time.
- Residential: Census Survey of Construction single-family and multi-family series.
Equipment (NAICS 33). Anchored on fabrication-cycle durations: aircraft at 9–12 months for the airframe assembly cycle, power transformers at 3 months for the fab cycle behind a multi-year lead time, ships at 12 months for hull build behind multi-year backlogs. Minor rows fall through to NAICS-3 prefix defaults.
: deployment rampNineteen industries have non-zero deployment lags, concentrated in heavy-process metals, mining, refining, chemicals, cement, semiconductor fabs, aircraft, and electric power. AGI compression is on the order of 3×. Anchors:
- TSMC Arizona: ~12 months fab yield ramp.
- ArcelorMittal Calvert: ~12 months EAF hot trials.
- Alba Potline 6: ~9 months aluminum smelter ramp.
- Shell Polymers Monaca: ~9 months ethane-cracker commissioning.
- EIA Electric Power Monthly: 3–6 months weighted across nuclear, gas CCGT, and renewables.
Production cycles. Most manufacturing sits at one to three weeks. Continuous-flow sectors (petroleum refining, petrochemicals, nitrogenous fertilizers) at hours to one day, anchored on Ullmann's. Advanced-node semiconductors at 90 days for the wafer cycle, anchored on TSMC/Intel references. Iron and steel at 3 days, aluminum at 1 week, cement at 1 week. Agriculture at 60 days, forestry at 90 days (harvest-and-mill of existing stocks; a 365-day biological-cycle sensitivity shifts the merger headlines by 0.15–0.45 yr⁻¹). AGI compresses production cycles by 3× outside agriculture and forestry, which compress by only 20%.
Ship times. Dominant transport mode per commodity from the BTS Commodity Flow Survey, mapped to seven modes (bulk rail/road, local truck, ocean, air, pipeline, bulk grain, precision air cargo) with per-good overrides. AGI compresses shipping 1.3–3× by mode.
At-plant curing and processing. Non-zero for concrete products (1 day for ready-mix transit, 2 weeks for precast curing) and biologic pharmaceuticals (30–60 days for cell-culture cycles). Physics-bound; held at current values in the AGI scenario.
Appendix F: Channel-by-channel perturbation analysis F.1 First-order eigenvalue perturbationSeveral Part 3 channels modify the IO triple by small structured amounts and ask what happens to . First-order perturbation theory gives a closed-form answer in terms of the unperturbed Perron eigenvectors.
The unperturbed problem is
where is the right Perron eigenvector. Let be the left Perron eigenvector, satisfying
This vector has an economic interpretation as the shadow-price for which every sector earns the same rate of profit .
Differentiating both sides under perturbations , , , left-multiplying by , and using the left-eigenvalue relation kills the implicit term:
The numerator is a value-weighted sum of the perturbations; the denominator is the equilibrium value of the capital stock. has the form of a marginal-return-on-capital ratio.
The four lag matrices reshape the eigenvalue problem. As derived in Appendix E.1, with , , , the four diagonal lag matrices, the lag-shifted balance reads
Define the lag-effective matrices
and analogously the sandwiched perturbations , , and . The eigenvalue problem then becomes
which has the same form as the lag-free version with , , and . The standard derivation no longer applies because , , and all depend on , but the implicit-function theorem gives:
where
is the lag-adjusted capital stock. The terms beyond capture the feedback through the four lag operators: the parenthesised pair captures the -side lag feedback, the two terms capture the -side production and deployment feedback. At AGI lags the lag operators absorb a meaningful share of any -side improvement: a uniform 1% improvement in raises by less than 1%, with the precise damping set by all four lag matrices through the formula above.
F.2 Capital and services sized for human presenceEach row of or contributes to when it is scaled down by a cut fraction . Applying F.1's perturbation formula to a row-multiplicative cut gives with
Both use the lag-effective row of their respective matrices, so long-cycle rows enter weighted by their row-side lag exponentials on and on . Semiconductors on and structures on are the most strongly weighted.
A-side changesFor most A-matrix inputs we can classify each row cleanly as either wholly human-consumed (cut entirely, ) or wholly not human-consumed (kept, ). The table below shows this classification grouped at NAICS-2. The column is the row's first-order coefficient as defined above; is the row's contribution to . The Codes-cut column lists the BEA-detail rows that we cut when a NAICS-2 splits across categories.
Code Category kept cut Codes cut 11 Agriculture, forestry, fishing, hunting 0.020 0.001 1121A0, 112A00, 112300, 112120, 114000, 111300, 111200 (livestock, fishing, fruit, vegetable) 21 Mining, quarrying, oil and gas extraction 0.107 — 22 Utilities 0.084 — 23 Construction 0.005 — 31–33 Manufacturing 0.682 0.011 311 consumer-chain subset, 313 textile mills, 315 apparel and leather, 337 furniture, 339 miscellaneous 42 Wholesale trade 0.007 — 44–45 Retail trade — — All 48–49 Transportation and warehousing 0.013 0.007 481 air transportation, 485 transit, 492 couriers 51 Information 0.014 0.002 511 publishing, 512 motion picture, 515 broadcasting, 519 internet content 52 Finance and insurance 0.013 0.006 524 insurance carriers and brokerages, 525 funds and trusts, 524113 direct life insurance, 523900 other financial investment 53 Real estate and rental and leasing 0.019 0.005 533 IP lessors, 532A00 consumer goods rental, 531HSO owner-occupied housing, 531HST tenant-occupied housing 54 Professional, scientific, technical services 0.018 0.006 541800 advertising and PR, 541700 scientific R&D services 56 Administrative and waste management services 0.010 0.012 561 administrative and support services 61, 62, 71, 72 Educational services; health care; arts and recreation; accommodation and food services — 0.008 All 81 Other services (except public administration) 0.006 0.002 812 personal services, 813 civic and professional organizations 92 Public administration — — EXT EXT_ROBOT, EXT_COMPUTE 0.025 — Subtotal 1.03 0.060A handful of A-side rows don't fit this clean dichotomy and we treat them separately:
Code Category 531ORE Other real estate (rent flows, per-cell) 0.057 0.82 0.047 541100 Legal services 0.005 0.5 0.003 541200 Accounting, tax preparation, bookkeeping, payroll services 0.003 0.5 0.001 541610 Management consulting services 0.003 0.5 0.002 550000 Management of companies and enterprises 0.027 0.5 0.013 Subtotal 0.095 0.066The sector 531ORE (Other real estate) aggregates rent paid for office space (cut) and rent paid for warehouse and industrial space (kept). We resolve the row per user-industry: each consumer gets its own weighted by 's actual office / warehouse stock mix from BEA Fixed Assets. The eigenvector-weighted row average lands at .
Legal services, accounting, management consulting, and management of companies are in part required to deal with human management and labor (employment law, payroll, HR, in-house benefits administration), and in part required for cognitive decisions that an AGI-run firm still has to make (audit, strategy, treasury, capital allocation). It is hard to know precisely what fraction is human-management overhead; is a crude estimate.
B-side changesAs with A-matrix inputs, most physical capital can be split into things that exist only for humans (cut entirely, ) and things that are required for production regardless (kept, ). There is also a third category: physical capital that is mostly not designed for humans but is more expensive than it needs to be because humans operate it or occupy it — process structures with bathrooms, locker rooms, and parking; vehicles and mobile machinery with driver cabs and dashboards. For these we apply a uniform 10% cut () as a rough estimate across the category.
Code Category 21311A Other support activities for mining 0.000 0.10 0.000 213 (excl. 21311A) Support activities for mining (drilling oil and gas wells) 0.000 0 0 233210 Health care structures 0.002 1 0.002 233230 Manufacturing structures 0.098 0.10 0.010 233240 Power and communication structures 0.062 0.10 0.006 233262 Educational and vocational structures 0.001 1 0.001 2332A0 Office and commercial structures (per-cell) 0.055 0.82 0.045 2332C0 Transportation structures and highways and streets 0.004 0.10 0.000 2332D0 Other nonresidential structures 0.074 0.10 0.007 332 Fabricated metal products 0.014 0 0 333 (excl. mobile cabs) Machinery 0.118 0 0 333111 Farm machinery and equipment 0.006 0.10 0.001 333120 Construction machinery 0.033 0.10 0.003 333130 Mining and oil and gas field machinery 0.000 0.10 0.000 334 Computer and electronic products 0.038 0 0 335 Electrical equipment and appliances 0.023 0 0 336111 Automobile manufacturing 0.009 1 0.009 336112 Light truck and utility vehicle manufacturing 0.025 0.10 0.003 336120 Heavy duty truck manufacturing 0.009 0.10 0.001 336411 Aircraft manufacturing 0.011 0.10 0.001 336611 Ship building and repairing 0.010 0.10 0.001 336 (other) Other transport equipment 0.000 0 0 337 Furniture and related products 0.006 1 0.006 339 Miscellaneous manufacturing 0.010 0 0 EXT_ROBOT Robot extension 0.017 0 0 All other rows below 0.005 threshold Misc smaller capital goods 0.001 0 0 Total 0.62 0.095The Office and commercial structures sector aggregates office buildings (cut entirely), warehouses (kept with the 10% comfort cut), and retail / lodging / other commercial space (cut entirely, but consumer-facing tenant industries have on the maximum-growth path). We resolve the row per user-industry: each consumer gets its own weighted by 's measured stock mix across the three sub-types from BEA 2017 Fixed Assets, with sub-cell values . The eigenvector-weighted row average is .
F.3 Within-industry productivity dispersionFor each four-digit NAICS manufacturing industry, BLS publishes the activity-weighted log 90/10 productivity spread, averaging about 0.8 across manufacturing over 2015–2019. The relevant quantity for our purposes is the gap from the activity-weighted mean to the 90th percentile, which under log-normality with the implied is about 0.35. This is a bit less than half the 90/10 spread because output-weighting puts more mass to the right of the median.
Bloom et al. (2019, Table 4) report a joint spread share of for the four AGI-substitutable factors in their TFP regression. They define this as , linear in . The per-sector multiplier is then giving for an industry at the manufacturing average.
BLS does not publish dispersion statistics outside manufacturing. The sector-specific frontier-gap literature gives a similar range:
- Electric power: within-fuel-class heat-rate dispersion implies a frontier-to-average gap of 1.10–1.15 (EIA/Leidos (2015)).
- Mining and construction: McKinsey benchmarking data is consistent with a gap of 1.15–1.20 (MGI (2017)).
- Retail: applying the same Bloom et al. framework to the BLS retail DiSP gives about 1.12.
- Trucking: Hubbard (2003) finds about 1.08 from utilization dispersion.
We use a uniform default of 1.10 outside manufacturing. Using sector-specific values instead does not meaningfully change the headline rate.
Each sector's is split 50/50 between a labor-augmenting and a Hicks-neutral component. The literature has not directly decomposed cross-sectional plant productivity dispersion into factor-augmenting components; the closest evidence (Doraszelski and Jaumandreu (2018), on the bias of technological change over time) suggests roughly equal contributions. We apply two independent scalings to the IO matrix. The Hicks-neutral component scales column of , , and by — every input coefficient drops by 50% of the log gain. The labor-augmenting component additionally scales the labor-substitute rows of and — i.e., the robot and compute capital that replaces human labor — by enough to deliver the remaining 50% of the gain in current US cost shares.
F.4 Capital redesign and the depreciation–intensity tradeoffConsider a sector with physical capital per unit of annual output, depreciation rate , and material inputs . The cost per unit of output is
where is the cost of tying up capital. A redesign that reduces capital intensity by a factor of raises depreciation per unit output by approximately , giving
Minimizing over gives
Assuming current designs are firm-optimal at today's interest rate ():
At , a 30-year building with has , while short-lived equipment with has .
We compute for each capital good from BEA depreciation rates. Applying a row ceiling rescales row of and as
The redesign factor varies more across capital goods than across users, so we apply a single per row.
The optimality condition gives the slope of the wear curve at , not how far redesign can go. The unconstrained optimum reaches , which is implausible. Real capital has function constraints that hold most rows near : foundations are sized by load, transmission conductors by ampacity, refractories hit thermal-cliff limits, aircraft require FAA certification.
The per-row ceilings in the table below are Claude's engineering estimates. For each capital good, Claude listed the dominant components, assessed which are function-constrained and which have redesign room, and picked a single value. There are no empirical compression numbers behind these. Individual rows are ballpark estimates, but the aggregate is more robust because most rows have a function-constrained core near .
The capital-redesign perturbation cuts both and on the same row. With giving row-uniform depreciation and the optimality condition , the joint perturbation reduces to a single-row formula in F.2's :
The resulting ceilings, with each row's at AGI-lag baseline ( yr⁻¹):
Capital good row (yr⁻¹) (yr⁻¹) Manufacturing structures 1.50 0.095 0.044 Other nonresidential structures 1.40 0.069 0.026 Office and commercial structures 1.30 0.053 0.015 Power and communication structures 1.15 0.061 0.008 Code-bound and infrastructure 1.15 0.007 0.001 Road vehicles 1.40 0.034 0.013 Aircraft 1.10 0.009 0.001 Ships 1.15 0.007 0.001 Machine tools 1.22 0.038 0.008 Material handling 1.35 0.037 0.012 Construction machinery 1.40 0.026 0.010 Other industrial machinery 1.40 0.018 0.007 General machinery (rest of 333*) 1.30 0.015 0.004 Fabricated metals 1.40 0.012 0.004 Broadcast and wireless 1.60 0.006 0.004 Computers 1.50 0.005 0.002 Instruments and detection 1.40 0.007 0.002 Transformers 1.35 0.019 0.006 Other equipment (default) 1.20 0.039 0.007The column sums to about 0.17 yr⁻¹. The body table's exact nonlinear computation, using the same ceilings, gives at AGI-lag, slightly below the perturbation prediction of 0.85, because higher increases the lag penalty that the first-order approximation ignores. Most of the lift comes from structures: the four nonresidential structures rows together contribute 0.09, about half the total. Road vehicles and the machinery cluster contribute another 0.05. The rows with the highest individual ceilings — broadcast and wireless at 1.60, computers at 1.50 — each add under 0.005 yr⁻¹ when considered individually because their row weights are moderate. The implied aggregate ceiling is on the highest-weight rows, anchored from below by a function-constrained core (power and communication structures, infrastructure, aircraft, ships) at –.
F.5 CES labor-capital substitutionEach sector has a CES production function over labor and process capital, with elasticity and weight . The reference recipe comes from the 2017 IO data, with column of process-capital intensities and labor input per unit output. Within-VA cost shares and (summing to 1 by construction) describe how value added was split between capital and labor at 2017 prices. Cost-minimization at the reference recipe gives , so is the only remaining parameter.
Each sector chooses a recipe scaling its reference inputs,
to produce one unit of output via the CES production function,
The full problem maximizes over the growth rate, the activity vector , and the per-sector recipes, subject to the CES constraint for each sector and the maximum-growth material balance , where and depend on the chosen recipes. The intermediate matrix stays at its 2017 values outside the robot-energy add-on, since intermediates sit outside the CES block.
The factor prices that drive each sector's recipe come from the maximum-growth path itself. The capital price for sector is the rental cost of one unit of its reference capital column at shadow prices ,
The labor price is the rental and flow cost of the robot and compute capital that delivers sector 's reference labor input,
where is sector 's physical-labor share, and are the engineering stock coefficients for robot body capital and compute capital per dollar of pre-AGI labor compensation, and is the robot depreciation rate. Both and depend on and on the left Perron eigenvector , which in turn depend on the recipes through the eigenvalue problem. So , , and the per-sector are jointly determined.
Holding the factor prices fixed, cost-minimization gives the closed-form recipe
and the CES constraint at equality gives the magnitudes,
By construction, at 2017 prices. When labor becomes cheaper relative to its 2017 ratio, and the sector responds with and . We solve the fixed point by iteration: initialize , solve the linear Perron problem for , compute and from the shadow prices, update via the closed form, and repeat with damping until convergence. The iteration converges in 20–60 steps at central .
Ten of the 398 sectors have one factor essentially absent, and the CES does not apply to them. Two have no labor reference, including owner-occupied housing and the secondhand goods adjustment, so and there is nothing to substitute toward. Eight have no capital column in the IO data, including general government, postal service, and several import-adjustment dummy sectors, so and there is nothing to substitute away from. All ten hold their recipes at .
Across the remaining sectors at , the converged recipe multipliers cluster around median and median . Half the sectors more than halve their process capital per unit output, and half more than double their labor-substitute capital.
Appendix G: Cross-year mergerStack source IO systems into a single non-square production set. Each source contributes its full set of column activities (production recipes in its own price system). Output rows split into comparable rows, one shared row per commodity with per-source unit-conversion factors, and source-specific rows for goods where cross-year comparability fails.
Let , , and be the stacked intermediate, capital, and depreciation matrices, and let project each column's outputs onto the merged row system. The linear program solves
by bisection on with HiGHS feasibility checks. This is the natural extension of Part 1's Appendix A to a non-square system. A nominal-dollar IO matrix is related to its physical-recipe analogue by a similarity transform (), so per-source is invariant to price levels. 1963 prices and 2017 prices give the same answer for the 1963 source.
For lag-adjusted scenarios, production and deployment lags enter via row/column multipliers on and , as in Appendix E. The nonlinear eigenvalue problem is solved by Picard iteration on .
The five source years and their IO resolution are:
Year IO resolution 1947 192 sectors (Evans-Hoffenberg) 1963 364 BEA detail 1972 489 BEA detail 1987 475 BEA detail 2017 398 BEA detailThe 1947 entry uses the original 192-industry Evans-Hoffenberg "Interindustry Relations Study" rather than the BEA-reworked 85-sector version, because higher resolution unlocks separate attribution to specific 1947 commodities that collapse into too-coarse industries at BEA resolution. The 1987 BEA-IO benchmark inherits its 6-digit SIC code scheme from 1972, with sector overrides where the BEA classification changed. All five years are at emergency utilization, with the 2017 QPC multipliers applied uniformly.
Capital matrices for all years are built from BEA detailed nonresidential fixed assets, which provides per-industry asset composition for each year back to 1947. The 1947 capital column uses 1963 asset-composition shares applied to 1947 K/Y intensity levels at the BEA-83 parent level, with each Evans-Hoffenberg child sector inheriting from its parent.
We systematically worked through all 398 sectors in the 2017 IO tables and excluded those that could not be meaningfully compared to at least some of the older years. The main categories of exclusion were:
- Consumer goods and human-presence sectors. These do not enter the Von Neumann growth path and are already excluded by the F.2 classification.
- Services. Most services have changed too much across decades for any meaningful comparison. An accountant, a management consultant, or a legal service in 1947 bears little resemblance to its 2017 counterpart.
- Classification changes. Some sectors cannot be matched because the statistical classification changed between years. For example, the 2017 tables lump precious metals mining with iron mining, but earlier tables lump precious metals with copper mining, making comparison impossible even though the underlying goods are physical.
- Insufficient data. Some sectors lack the IO detail or capital-stock data needed to build a complete column in the older years.
The 97 sectors that survive this screening are split into three confidence tiers as described in the body text. Tier 1 goods are compared in physical units (tonnages, kWh, BTUs) with no capability-factor rescaling. Tier 2 goods use physical units but with known product drift that the unit conventions only partly absorb. Tier 3 goods are compared using inflation-adjusted real shipment values from the NBER-CES Manufacturing Industry Database, restricted to sectors and years where the deflator approach is reasonable. This is generally 1987-vs-2017 comparisons, where manufacturing methods are similar enough that a deflator comparison is defensible.
The linear program balances physical robots in 2017-robot-dollar units. Each year 's column demands physical robots proportional to its labor intensity (workers per dollar of output). Since the robot supply column is built from 2017's input bundle, the accounting requires scaling each older year's robot and compute capital coefficient by . This is why the robot and compute fleet shares in the body text diverge from the electricity shares. Older years appear to consume a disproportionate share of the robot fleet because their higher labor-per-output ratios are scaled up by the wage ratio.
Year Compensation per FTE 1947 2,750 26.7 1963 5,900 12.5 1972 9,770 7.5 1987 24,940 2.9 2017 73,489 1.0Discuss
Страницы
- « первая
- ‹ предыдущая
- …
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- следующая ›
- последняя »