Введение в каузальные основания безопасного СИИ
В этой цепочке Causal Incentives Working Group рассказывают о своём подходе к пониманию важных для безопасности ИИ понятий вроде агентности и стимулов через каузальность.
К сожалению, цепочка так и осталась недописанной.
Вступление «Введения в каузальные основания безопасного СИИ»
В следующие несколько лет появление продвинутых ИИ-систем заставит общество, организации и отдельных людей столкнуться с некоторыми фундаментальными вопросами:
- Как увериться, что продвинутые ИИ-системы будут делать именно то, что мы от них хотим (задача согласования)?
- Когда систему достаточно безопасно разрабатывать и развёртывать, и каких свидетельств достаточно, чтобы посчитать, что это так?
- Как нам сохранить свою автономию и контроль за ситуацией, когда принятие решений всё больше будет перекладываться на цифровых помощников?
В этой цепочке постов мы объясним, как каузальная точка зрения на агентность даёт концептуальные инструменты при помощи которых можно разбираться в этих вопросах. Мы постараемся минимизировать применение жаргона и объяснять его, где он всё же будет, чтобы цепочка была доступна исследователям с самым разным опытом.
Агентность
Для начала, под агентом мы имеем в виду направленную на цель систему, которая действует так, как если бы она пыталась менять мир в некотором конкретном направлении/направлениях. Примеры агентов: животные, люди и организации (в следующем посте об агентах будет больше). Понимание агентов – ключ к перечисленным вопросам. Популярно мнение, что искусственные агенты – основная экзистенциальная угроза технологий уровня сильного искусственного интеллекта, неважно, возникли ли они спонтанно или были спроектированы намеренно. Есть много потенциальных угроз нашему существованию, но высокоспособные агенты выделяются. Многих целей достигать эффективнее, накапливая влияние на мир. Если к Земле летит астероид, то он не намерен вредить людям и не будет сопротивляться отклонению. А вот несогласованные агенты могут занять противостоящую позицию активной угрозы.
Во-вторых, как для отдельных людей, так и для организаций критически важно не утратить в грядущем технологическом переходе человеческую агентность. Уже всплывает беспокойство о том, что манипулятивные алгоритмы социальных медиа и системы рекомендации контента вредят способности пользователей сосредотачиваться на своих долгосрочных целях. Более мощные ассистенты усилят эту тенденцию. По мере всё большей передачи принятия решений ИИ-системам, способность общества выбирать свою траекторию будет становиться всё более сомнительной.
Человеческую агентность тоже можно взращивать и защищать. Помогать людям помочь себе – не так патерналистично, как напрямую исполнять их пожелания. Содействие усилению людей может меньше прямого удовлетворения предпочтений зависеть от полного решения задачи согласования. Теория самодетерминации даёт свидетельства, что люди ценят агентность саму по себе, и некоторые из прав человека можно интерпретировать как защиту нашей нормативной агентности.
В третьих, искусственные агенты могут в какой-то момент сами стать объектами морали. Более ясное понимание агентности может помочь нам уточнить свою моральную интуицию и избежать неприемлемых действий. Не исключено, что некоторых этических дилемм избежать можно только создавая искусственные системы, которые объектами морали не будут.
Ключевые вопросы
Мы надеемся, что наши исследования помогут создать теорию агентности. Такая теория в идеале должна отвечать на вопросы вроде таких:
- Какие разновидности агентов могут быть созданы? По каким измерениям они могут отличаться? Мы пока в основном встречали животных, людей и организации из людей, но пространство возможных направленных на цель систем скорее всего куда больше.
- Эмерджентность: как появляются агенты? Например, в какой момент большая языковая модель стать агентной? Когда система агентов становится мета-агентов вроде организации?
- Обессиливание: как агентность теряется? Как нам уберечь и взращивать человеческую агентность?
- Какие есть этические требования по поводу разных видов систем и агентов?
- Как опознавать агентов и измерять агентность? Конкретные определения помогли бы нам заметить появление агентности у искусственных систем и потерю агентности у людей.
- Как предсказать поведение агента? К какому поведению у агентов есть стимулы? Как агенты обобщают на новые ситуации? Если мы поймём и эффекты этого поведения, то будем способны предсказывать опасность.
- Какие у агентов могут быть взаимоотношения? Какие из них вредны, а какие полезны?
- Как нам создавать агентов безопасными, справедливыми и выгодными?
Каузальность
Каузальность помогает понимать агентов. Философы давно заинтересованы каузальностью, не только потому, что точная взаимосвязь причин и следствий интригует разум, но и потому, что она лежит в основе огромного числа других понятий, многие из которых важны для понимания агентов и проектирования безопасного СИИ.
Например, воздействие и реакция – понятия, связанные с каузальностью. Мы хотим, чтобы агенты положительно влияли на мир и должным образом реагировали на инструкции. На каузальности основаны и многие другие относящиеся к делу понятия:
- Агентность, потому что направленная на цель система – та, цели которой управляют (являются причиной) её поведения.
- Намерение, относящееся к причинам действия и связи средства-цель. Намерение – важное понятие для возможности присваивать юридическую и моральную ответственность.
- Вред, манипуляция и обман, которые относятся к тому, как оказывалось воздействие на ваше благополучие, действия или убеждения, и которые обычно считаются намеренными.
- Справедливость, в частности – как реагировать на личные атрибуты вроде пола или расы и позволять им влиять на решения.
- Устойчивое обобщение при изменениях окружения куда проще для агентов с каузальной моделью этого окружения.
- Гипотетические ситуации/контрфактуалы как альтернативные миры, отличающиеся от нашего одним или многими каузальными воздействиями.
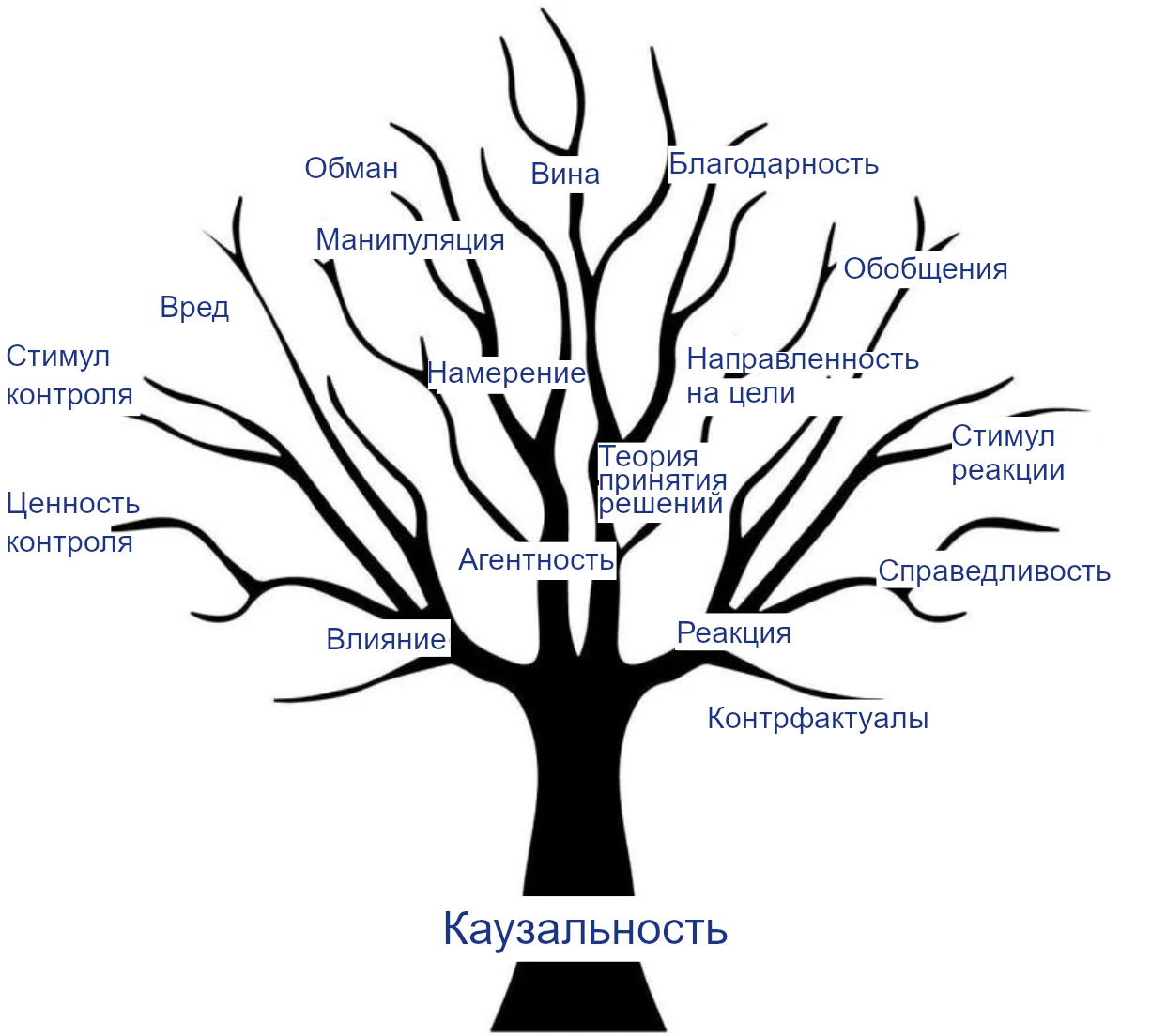
Дерево каузальности
Дальше в этой цепочке мы подробнее расскажем, как эти понятия основаны на каузальности и к каким исследованиям это привело. Мы надеемся, что это откроет другим исследователям путь путь и вдохновит их присоединиться к нашим усилиям по созданию на базе каузальности формальной теории безопасного (С)ИИ. Большая часть нашей недавней работы истекает из этого видения. Например, в «Открывая агентов» изучая агентов и «Рассуждениях о каузальности в играх» мы выработали лучшее понимание того, как сопоставить аспекты реальности с каузальными моделями. В статье про стимулы агентов мы показали, как такие модели можно анализировать, чтобы выявить важные для безопасности свойства. «Придирчивыми к пути целями» мы показали, как такой анализ может вдохновлять лучшее проектирование.
Мы надеемся, что это поможет и другим важным для безопасности СИИ направлениям исследований, вроде масштабируемого согласования, оценок опасных способностей, устойчивости, интерпретируемости, этики, управления, прогнозирования, оснований агентности и картирования рисков.
Заключение
Мы надеемся, что основанное на каузальности понимание агентности и связанных понятий поможет проектировщикам ИИ-систем, разъяснив, что есть в пространстве возможных агентов и как избежать особенно рискованных конфигураций. Оно может помочь регуляторам обрести лучшее представление о том, за чем следить, и что должно считаться достаточным свидетельством безопасности. Оно может помочь всем нам решить, какое поведение допустимо по отношению к каким системам. И, наконец, оно может помочь отдельным людям понять, что они стремятся сохранить и преумножить в своих взаимодействиях с искусственными разумами.
В следующем посте мы подробнее разъясним каузальность, каузальные модели, разные каузальные модели Перла и то, как их можно обобщить на случай наличия одного или нескольких агентов.
Каузальность: быстрое введение
Каузальные модели лежат в основе нашей работы. В этом посте мы представим краткое, но доступное объяснение каузальных моделей, которые могут описать вмешательства, контрфактуалы и агентов, что пригодится в следующих постах цепочки. Предполагается понимание основ теории вероятности, в частности – условных вероятностей.
Что такое каузальность?
Что значит, что из-за дождя трава стала зелёной? Тема каузальности философски любопытна и лежит в основе многих других важных для людей понятий. В частности, многие относящиеся к теме безопасности ИИ концепции вроде влияния, реакции, агентности, намерения, справедливости, вреда и манипуляции, сложно осмыслить без каузальной модели мира. Мы уже упоминали это в вводном посте и подробнее обсудим в следующих.
Вслед за Перлом мы примем определение каузальности через вмешательство: брызгалка сегодня каузально влияет на зелёность травы завтра, потому что если бы кто-то вмешался и выключил брызгалку, то зелёность травы была бы другой. Напротив, зелёность травы завтра не оказывает эффекта на брызгалку сегодня (предполагая, что вмешательство никто не предсказал). Так что брызгалка сегодня влияет на траву завтра, но не наоборот, как мы интуитивно и ожидаем.
Вмешательства
Каузальные Байесовские Сети (КБС) отображают каузальные зависимости между аспектами реальности при помощи ациклического ориентированного графа. Стрелка из переменной A в переменную B означает, что при сохранении значений остальных переменных A влияет на B. Например, нарисуем стрелку из брызгалки (S) к зелёности травы (G):
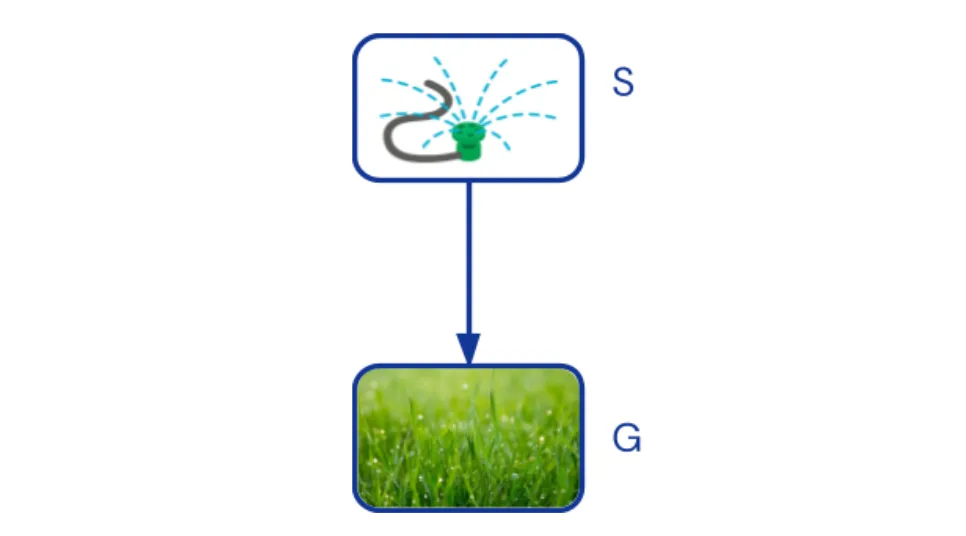
Каузальный граф, соответствующий нашему примеру. Брызгалка (S) влияет на зелёность травы (G).
У каждой вершины графа каузальный механизм того, как на него влияют его родительские узлы описывается условным распределением вероятностей. Для брызгалки распределение p(S) описыввет, как часто она включена, т.е. P(S=on)=30%. Для травы условное распределение p(G∣S) определяет, насколько вероятно, что трава станет зелёной, если брызгалка включена, т.е. p(G=green∣S=on)=100%, и если брызгалка выключена, т.е. p(G=green∣S=off)=30%.
Перемножая распределения мы получаем совместное распределение p(S,G)=p(S)p(G∣S), описывающее вероятность любой комбинации исходов. Совместные распределения – базовое понятие обычной теории вероятности. Их можно использовать, чтобы отвечать на вопросы вроде «какая вероятность, что брызгалка включена, при условии, что трава мокрая».
Вмешательство в систему меняет один или несколько механизмов каузальности. Например, вмешательство, которое включает брызгалку, соответствует замене механизма каузальности p(S) на новый механизм 1(S=on) – брызгалка всегда включена. Эффекты вмешательства можно выяснит, вычислив новое совместное распределение p(S,G∣do(S=on))=1(S=on)p(G|S), где do(S=on) обозначает вмешательство.
Заметим, что нельзя вычислить эффект вмешательства, зная только совместное распределение p(S,G), ведь без графа каузальности непонятно, надо ли менять механизм в разложении P(S)P(G∣S) или в inp(G)p(S∣G).
По сути, все статистические корреляции вызваны каузальным воздействием. [от переводчика: я тоже удивился этому тейку, можете посмотреть разъяснения в комментариях под оригинальным постом] Так что для набора переменных всегда есть какой-то КВБ, соответствующий каузальной структуре процесса, который генерирует данные. Впрочем, чтобы объяснить, например, неизмеренные факторы в нём могут потребоваться дополнительные переменные.
Контрфактуалы
Пусть брызгалка включена, а трава зелёная. Была бы трава зелёная, если бы брызгалка не была включена? Вопросы о гипотетических контрфактуалах сложнее, чем вопросы о вмешательствах, потому что для них надо думать о нескольких мирах. Контрфактуалы – ключ к определению вреда, намерения, справедливости и того, как измерять воздействие. Все эти понятия зависят от сравнения исходов с гипотетическими мирами.
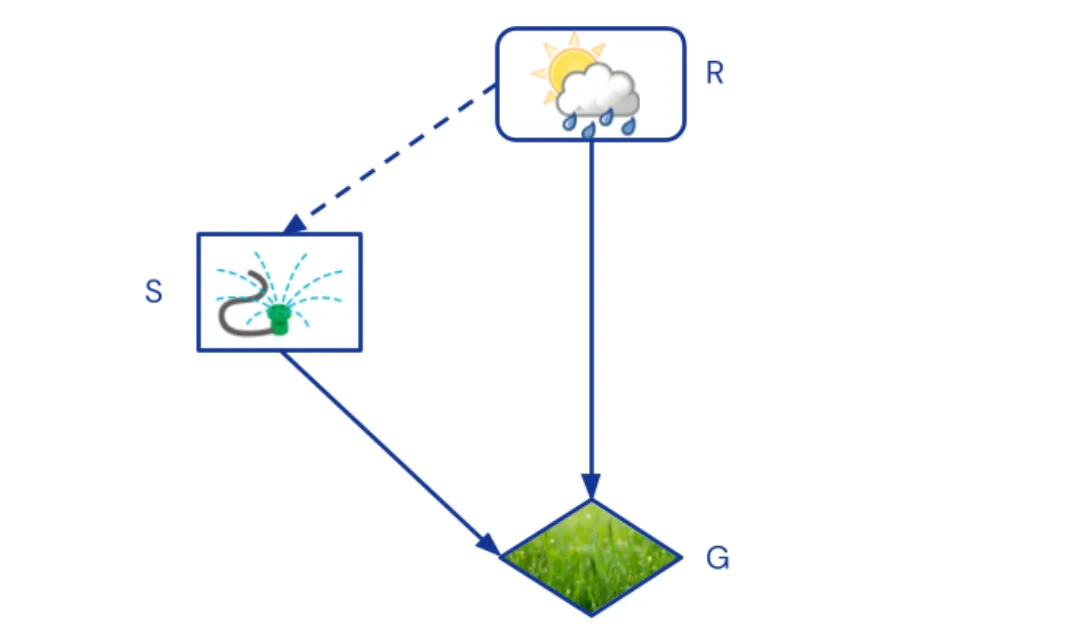
Чтобы справляться с такими рассуждениями, структурные каузальные модели (СКМ) добавляют к КБС три важных аспекта. Во-первых, общий для гипотетических миров фоновый контекст явно отделяется от переменных, в которые возможны вмешательства и которые в разных мирах могут отличаться. Первые называют экзогенными переменными, а вторые – эндогенными. В нашем примере полезно ввести экзогенную переменную R, обозначающую, идёт ли дождь. Брызгалка и зелёность травы – эндогенные переменные.
Отношения между гипотетическими мирами можно отобразить двойным графом, в котором есть по две копии эндогенных переменных – для настоящего мира и гипотетического и внешняя переменная/переменные, дающие общий контекст:

Граф, нужный, чтобы ответить, является ли брызгалка причиной того, что трава зелёная. Вершины из гипотетического мира обведены пунктиром. Правая вершина-брызгалка подвержена вмешательству do(S=off), что обозначает гипотетическую ситуацию. Серая внешняя вершина-дождь R даёт общий контекст.
Во-вторых, для СКМ вводится нотация для различия эндогенных переменных в разных гипотетических мирах. Например, GS=off обозначает зелёность травы в гипотетическом мире, где брызгалка выключена. Можно считать это сокращением для «G∣do(S=off)» с тем преимуществом, что это можно вставлять в выражения с переменными из других миров. Например, наш вопрос можно сформулировать как p(GS=off=green|S=on,G=green), где GS=off=green – гипотетическая ситуация, а S=on,G=green – настоящие наблюдения.
В третьих, в СКМ требуется, чтобы у всех эндогенных переменных были детерминированные механизмы каузальности. В нашем случае это выполняется, если мы предполагаем, что брызгалка включена, когда дождя нет, а трава становится зелёной (только) тогда, когда идёт дождь или включена брызгалка.
Детерминизм означает, что перейти к условному распределению просто – надо лишь обновить распределение по экзогенным переменным, т.е. P(R) заменяется на P(R∣S=on,G=green). В нашем случае вероятность дождя снижается с 30% до 0%, потому что, если идёт дождь, брызгалка выключена.
Так что для ответа на наш вопрос надо произвести три шага рассуждения:
- Абдукция: заменить P(R) на P(R∣S=on,G=green)
- Вмешательство: выключить брызгалку, do(S=off)
- Предсказание: вычислить значение G в получившейся модели.
Или то же самое одной формулой:
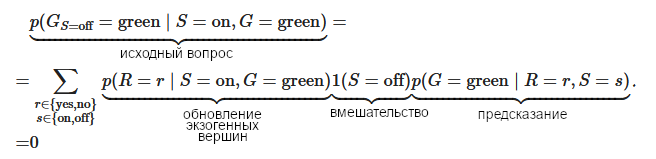
В итоге мы можем сказать, что если бы брызгалка была выключена, трава не была бы зелёной (при принятии наших допущений о взаимосвязях).
СКМ строго мощнее КБС. Их основной недостаток – они требуют детерминированных взаимосвязей между эндогенными переменными, а их на практике часто сложно определить. Ещё они ограничены контрфактуалами без отходов назад, гипотетическими мирами, которые отличаются исключительно вмешательствами.
Один агент
Пусть мы хотим вывести намерения или стимулы некоего Джона, или же предсказать, как его поведение подстроилось бы под изменения в его модели мира. Нам потребуется диаграмма каузальных воздействий (ДКВ), помечающая вершины-переменные как относящиеся к случайности, решениям или полезности. В нашем примере дождь был бы вершиной случайности, брызгалка – вершиной-решением, а зелёность травы – вершиной-полезностью. Раз дождь – родительская вершина брызгалки, значит, Джон наблюдает его перед тем, как решать, включать ли её. Графически будем обозначать случайности как раньше, решения прямоугольниками, а полезность ромбами. Заштрихованные рёбра означают наблюдения.
ДКВ, соответствующая нашему примеру. Включение или не включение брызгалки – решение, оптимизирующее зелёность травы.
Агент определяет каузальные механизмы своих решений, т.е. свою политику, с цель. максимизации суммы по своим вершинам-полезностям. В нашем примере оптимальной политикой было бы включить брызгалку, когда дождя нет (решение в случае дождя не имеет значения). Когда политика определена, ДКВ определяет КБС.
В моделях с агентами есть два вида воздействий, зависящих от того, адаптируют агенты под них свои политики или нет. Например, Джон сможет выбрать другую политику касательно брызгалки только если мы проинформируем его о вмешательстве до того, как он уже принял своё решение. Вмешательства до и после политики можно обрабатывать всё тем же оператором do, если мы добавим в модель так называемые вершины-механизмы. Больше о них будет в следующем посте.
Много агентов.
Взаимодействие нескольких агентов можно промоделировать каузальными играми. В них у каждого агента есть множества переменных-решений и переменных-полезностей.
Проиллюстрируем. Пусть Джон иногда засеивает новую траву. Птицам нравится клевать семена, но они не могут издалека понять, есть ли они там. Они могут лишь видеть, использует ли Джон брызгалку, а это вероятнее, когда трава новая. Джон хочет орошать свой газон, когда тот новый, но не хочет, чтобы птицы клевали семена. Вот структура этой сигнальной игры:

Каузальная игра, соответствующая нашему усложнённому примеру. Разные цвета означают решения и полезности разных агентов. Между новыми семенами (N) и птицами (B) нет ребра – птицы не могут их увидеть.
Помимо лучшего моделирования каузальности, у каузальных игр есть и другие преимущества над стандартной развёрнутой формой игр (РФИ). Например, каузальная игра сразу показывает, что птицам не важно, орошён газон или нет, ведь единственный путь от брызгалки S к еде F лежит через решение самих птиц B. В РФИ эта информация была бы скрыта в числах выигрыша. Каузальные игры более явно отображают независимость переменных, что иногда позволяет найти больше подигр и исключить больше ненадёжных угроз. При этом, каузальную игру всегда можно сконвертировать в РФИ.
Аналогично различиям между совместными распределениями, КБС и СКМ, есть (мультиагентные диаграммы воздействия, которые включают агентов в не обязательно каузальные графы, структурные каузальные модели воздействия и структурные каузальные игры, которые комбинируют агентов с экзогенными вершинами и детерминизмом, чтобы отвечать на вопросы о контрфактуалах.
Заключение
В этом посте мы ввели модели, которые могут отвечать на вопросы о корреляциях, вмешательствах и контрфактуалах с участием нуля, одного или нескольких агентов. В итоге есть девять возможных видов моделей. Более подробное введение в каузальные модели можно прочитать в Разделе 2 «Рассуждений о каузальности в играх» и книгу Перла «A Primer».
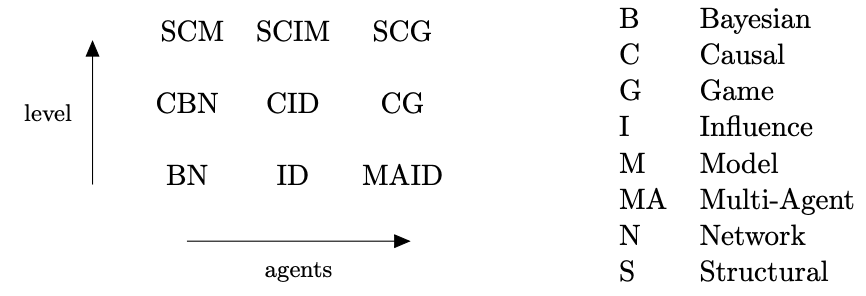
Таксономия каузальных моделей и их аббревиатуры. Вертикальная ось располагает модели по каузальной иерархии (ассоциативные, интервенционистские (с вмешательствами) и контрфактуальные), а горизонтальная – по количеству агентов (0, 1 и n).[от переводчика: в остатке цепочки эти аббревиатуры применяться не будут, так что я оставил схему без перевода]
В следующем посте мы будем использовать КИД и каузальные игры для моделирования агентов. Но что есть агент? В следующем посте мы попробуем лучше разобраться в этом, посмотрев на некоторые свойства, общие для всех агентных систем.
Каузальная точка зрения на агентность
У этого поста две цели: положить основу для следующих постов, исследовав, что такое агентность, с каузальной точки зрения, и обрисовать программу исследований, нужных для более глубокого понимания агентности.
Важность понимания агентности
Агентность – сложный концепт, который изучают с разных точек зрения. Ею интересуются и науки об обществе, и философия, и исследования ИИ. В самых общих чертах агентность – это способность системы действовать самостоятельно. В этом посте мы интерпретируем агентность как направленность на цель, т.е. действие таким образом, как если бы система пыталась изменить мир в конкретную сторону.
Есть мощные стимулы создавать всё более агентные ИИ-системы. Такие системы потенциально смогут выполнять многие задачи, для которых сейчас нужны люди: самостоятельно проводить исследования или даже управлять собственными компаниями. Но к большей агентности прилагаются дополнительные потенциальные опасности и риски, ведь направленная на цель ИИ-система может стать способным противником, если её цели не согласованы с интересами людей.
Лучшее понимание агентности может позволить нам:
- Понять опасности и риски мощных систем машинного обучения.
- Оценить, обладает ли конкретная ML-модель опасным уровнем агентности.
- Проектировать неагентные системы, вроде СИИ-учёных или оракулов, или агентные безопасным образом.
- Положить основание для прогресса в других областях безопасности СИИ, вроде интерпретируемости, стимулов и изучении обобщений.
- Уберечь человеческую агентность, например, через лучшее понимание условий, в которых ей уровень повышается или понижается.
Степени свободы
(Преследующие цели) агенты бывают самыми разными – от бактерий до людей, от футбольных команд до государств, от RL-политик, до LLM-симулякр. Несмотря на это, у них есть некоторые общие фундаментальные черты.
Для начала, агенту нужна свобода выбирать из некоторого набора вариантов.1 Нам не надо предполагать, что это решение свободно от каузальных воздействий, а то мы никак не сможем предсказывать его заранее – но должен быть смысл в котором оно могло бы быть разным. Деннетт назвал это степенями свободы.
Например, Джон может выбирать, включать брызгалку или нет. Мы можем моделир.овать его решение как случайную величину с возможными значениями «поливает» и «не поливает»:

Степени свободы можно показать возможными значениями случайной величины
Степени свободы бывают разные. Термостат может выбирать только мощность нагревателя, а большинству людей доступен большой набор физических и вербальных действий.
Влияние
Во-вторых, чтобы что-то значить, у поведения агента должны быть последствия. Решение Джона включить брызгалку влияет на то, будет ли трава зелёной.
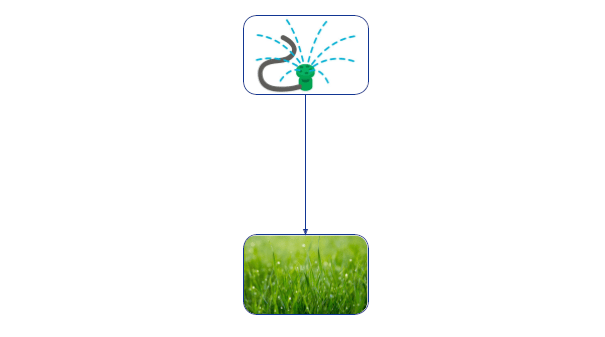
Брызгалка Джона влияет на зелёность травы.
У одних агентов влияния больше, чем у других. Например, влияние языковой модели сильно зависит от того, взаимодействует ли она лишь со своими разработчиками или с миллионами пользователей через открытый API. Каузальное влияние наших действий, кажется, определяет у людей ощущение агентности. Предлагались такие меры влияния как (каузальная пропускная способность, перформативная мощность и власть в марковских процессах принятия решений.
Адаптация
В третьих, и это самое важное, стремящиеся к целям агенты делают что-то не просто так. То есть, (они действуют как будто) у них есть предпочтения о мире и эти предпочтения управляют их поведением. Джон включает брызгалку, потому что она делает траву зелёной. Если бы траве не была нужна вода, то Джон скорее всего её бы не поливал. Последствия управляют поведением.
Эту петлю обратной связи, обратной каузальности, можно показать, добавив к каждой вершине объектного уровня нашего графа так называемую вершину-механизм. Вершина-механизм определяет каузальный механизм её объектной вершины, т.е., то, как её значение определяется её родительскими вершинами объектного уровня. Например, вершина-механизм брызгалки определяет политику поливания Джона, а вершина-механизм травы определяет то, как трава реагирует на разное количество воды:обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может -- это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда." href="#footnote2_6tq0l41">2
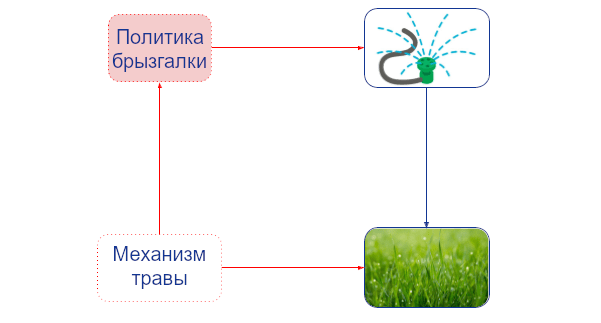
Механистический каузальный граф показывает адаптацию Джона на изменения в окружении. Вершины-механизмы отмечены красным, а вершины объектного уровня – синим.
Явное отображение каузальных механизмов в вершинах позволяет нам рассматривать вмешательства в них. Например, вмешательство в механизм травы может превратить её в траву, которой нужно меньше воды. Связь между механизмом травы и политикой брызгалки сообщает, что такое вмешательство может повлиять на привычки поливания Джона.3 То есть, он адаптирует своё поведение, чтобы всё ещё достигать своей цели.
При правильных переменных и экспериментах адаптацию можно заметить при помощи алгоритмов каузальных открытий. Это потенциально можно использовать для обнаружения агентов. В частности, когда одна величина-механизм адаптируется на изменения в другой, может быть, что первая относится к вершине-решению, а вторая – к вершине-полезности, которую оптимизирует это решение. Если агенты – идеальные теоретикоигровые агенты, более оформленная версия этих условий оказывается необходимым и достаточным критерием обнаружения вершин-решений и вершин-полезностей.
Адаптация тоже бывает разная. Деннетт проводит различие между Дарвинианскими, Скиннерианскими, Попперианскими и Грегорианскими агентами, в зависимости от того, адаптировались ли они эволюцией, опытом, планированием или обучением от других соответственно. Например, человек, который заметил, что холодно, наденет пальто, а биологический вид может на эволюционных масштабах отрастить шерсть подлиннее. Языковые модели скорее всего попадают на высший, Грегорианский, уровень – их можно обучить чему-то в промпте, и они много что переняли у людей при предобучении.
Количественную меру адаптации можно получить, рассмотрев, как быстро и эффективно агент адаптируется к различным вмешательствам. Скорость адаптации можно измерять, если расширить наш подход механизмом вмешательств на разных временных масштабах (например, человеческих или эволюционных). Эффективность конкретной адаптации можно количественно оценить, сравнив то, насколько хорошо справляется агент без вмешательства и с ним. Обычная метрика этого при использовании функций вознаграждения – сожаление (в худшем случае). Наконец, то, к каким вмешательствам в окружение агент сможет должным образом адаптироваться, служит мерой того, насколько он устойчив, а к каким вмешательствам в полезность – его перенаправляемость или обобщённость по задачам.
В следующем посте мы представим результат, который показывает, что для адаптации надо, чтобы у агента была каузальная модель. Этот результат дополнит поведенческую точку зрения, которой мы придерживаемся в этом посте, внутренними представлениями агента.
Последовательность и самосохранение
С адаптациями связан вопрос о том, насколько последовательно агент преследует долгосрочные цели. Например, почему государства могут реализовывать большие инфраструктурные проекты на протяжении десятилетий, а (нынешние) агенты на основе языковых моделей (вроде autoGPT) быстро сходят с курса? Во-первых, отталкиваясь от рассуждений выше, мы можем операционализировать цель через то, к каким вмешательствам в механизмы агент адаптируется. Например, подхалимская языковая модель,которая адаптирует свои ответы к политическим убеждениям пользователя, может обладать целью удовлетворить пользователя или получить большее вознаграждение. Развивая это, последовательность можно операционализировать через то, насколько схожи цели разных вершин-решений. Интересно, что к большему интеллекту вовсе не обязательно прилагается большая последовательность.
Если агент не продолжает своё существование, он не может последовательно стремиться к цели. Это, вероятно, причина, почему, как мы упоминали в вводном посте, мы (люди) хотим уберечь свою агентность.4 Нынешние языковые модели выражают стремление к самосохранению. Для контраста, более ограниченные системы, вроде рекомендательных систем и систем GPS-навигации вовсе не демонстрируют никакого стремления к самосохранению, несмотря на то, что они в какой-то мере направлены на цели.
Собирая всё вместе
Пока что мы обсудили восемь параметров агентности: степени свободы; влияние; скорость, эффективность, устойчивость и перенаправляемость адаптаций; последовательность и самосохранение. К списку можно добавить ещё (марковскую отделённость от окружения (например, клеточную стенку, кожу или шифрование внутренних емейлов, это показывает d-разделение каузального графа) и то, сколько информации об окружении или его восприятия есть у агента.
Все эти параметры относятся к силе или свойствам разных каузальных взаимосвязей и могут быть сопоставлены с разными частями нашей диаграммы:

Параметры агентности
Эти параметры дополнительно подчёркивают то, что агентности бывает больше и меньше. Причём система бывает более или менее агентна по нескольким осям. Например, человек более агентен, чем рыба, которая более агентна, чем термостат, а AlphaGo превосходит людей по последовательности, но обладает куда меньшей степенью свободы.
Будущая работа
Высокоуровневое обсуждение в этом посте должно было объяснить концептуальную связь между агентностью и каузальностью. В частности, адаптация – каузальное понятие, обозначающее, как на поведение воздействуют вмешательства на окружение или цели агента. Следующие посты будут основываться на этой идее.
Ещё хотелось бы подсветить некоторые возможные направления для дальнейшей работы, к которым приводит такая точка зрения:
- Какие у агентности ключевые параметры? Как едино сформулировать описанные выше понятия? Как они связаны с оптимизационной силой и основаниями оптимизации? Есть ли базисный набор взаимно независимых параметров агентности, от которого образуются все остальные?
- Можно ли измерить направленность на цель в языковых моделях и людях? Наверное, направленность на цель и сила оптимизации могут быть в общем случае ограничены (сверху) влиянием, адаптациями, последовательностью, и т.д. агента. Это может что-то дать оценкам опасных способностей.
- Могли бы мы спроектировать агентов так, чтобы они были только частично направлены на цель? Рекомендательные системы и системы GPS-навигации вовсе не проявляют стремления к самосохранению, несмотря на то, что в какой-то мере они направлены на цели. Нынешние языковые модели демонстрируют стремление к самосохранению, но, может быть, этого можно избежать? Скорее всего, эволюция, разрабатывая биологических агентов, одновременно отбирала по всем перечисленным параметрам, но искусственные системы могут не сталкиваться с эволюционным давлением. Если бы можно было избежать случайного и намеренного создания последовательных агентов с стремлением к самосохранению, это могло бы потенциально открыть путь к получению большей части выгоды ИИ с лишь малой долей риска.
- Можем ли мы лучше понять, при каких условиях агентность возникает из менее агентных компонентов? Когда агентность растёт и когда уменьшается? Когда цифровой ассистент или рекомендательная система усиливает мою агентность, а когда подавляет? Что если я играю в шахматы при помощи AlphaZero?
Следующий пост будет сосредоточен на стимулах. Важно понимать стимулы, чтобы продвигать в наших ИИ-системах правильное поведение. Как мы увидим, анализ стимулов естественным путём строится на основе понятия агентности, как мы его обсудили в этом посте.
- 1. Некоторые применения термина «агент» могут позволить системе быть агентом даже если она никак не может выбирать действия, вроде полностью парализованного человека. Мы не используем термин в этом смысле. Мы сосредоточены на направленных на цель и действующих системах. Ещё стоит заметить, что для нас агентность относительна – зависит от «рамок», определённых величинами в модели. Если брызгалка Джона сломается, у него не будет агентности в связи с примером из поста, но он всё ещё будет обладать агентностью в каких-то других рамках (например, он всё ещё сможет гулять по своему двору).
- 2. Как обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может – это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда.
- 3. Есть альтернативная интерпретация, естественная с точки зрения конечно-факторизуемых множеств. Можно интерпретировать поведение агента как отвечающее на более точные вопросы, чем его цель, и вершины объектного уровня – на более точные вопросы, чем вершины-механизмы. Ещё в связи с этим: каузальные взаимосвязи можно вывести из алгоритмической теории информации. Это удобно при обсуждении независимости вершин, на которые не оказывается вмешательств.
- 4. Иногда такие мета-предпочтения рассматривают как характеристический признак агентности. Скорее всего, их можно моделировать аналогично обычным предпочтениям, добавив ещё один слой вершин-механизмов (т.е. механизмы для механизмов).
Каузальная точка зрения на стимулы
«Покажи мне стимулы, и я покажу тебе результат.»
– Чарли Мунгер
Предсказание поведения очень важно при проектировании и развёртывании агентных ИИ-систем. Стимулы – одни из ключевых сил, формирующих поведение агентов,1 причём для их понимания нам не надо полностью понимать внутреннюю работу системы.
Этот пост показывает, как каузальная модель агента и его окружения может раскрыть, что агент хочет знать и что хочет контролировать, а также как он отвечает на команды и влияет на своё окружение. Это сочетается с уже полученным результатом о том, что некоторые стимулы можно вывести только из каузальной модели. Так что для полноценного анализа стимулов она необходима.
Ценность информации
Какую информацию агент захочет узнать? Возьмём, к примеру, Джона, который решает, полить ли ему газон, основываясь на прогнозе погоды и том, пришла ли ему его утренняя газета. Знание погоды означает, что он может поливать больше, когда будет солнечно, чем когда будет дождь, что экономит ему воду и повышает зелёность травы. Так что прогноз погоды для решения о брызгалке обладает информационной ценностью, а пришла или нет газета – нет.
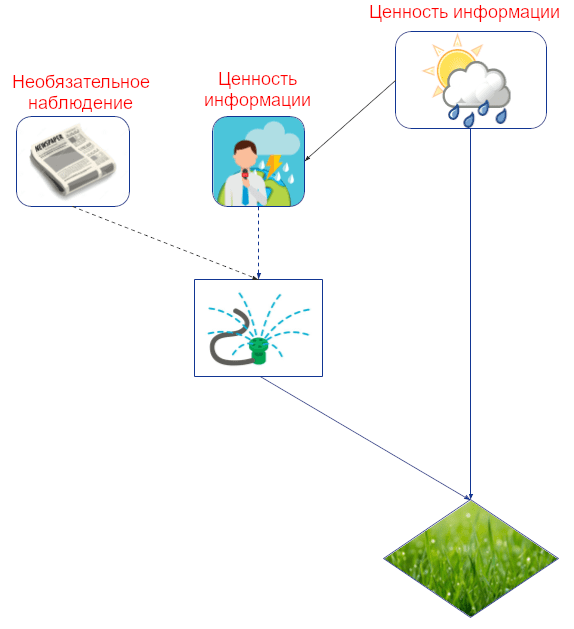
Мы можем численно оценить то, насколько полезно для Джона знание о погоде, сравнив его ожидаемую полезность в мире, где он посмотрел прогноз, с миром, где не посмотрел. (Это имеет смысл только если мы предполагаем, что Джон должным образом адаптируется в обоих мирах, т.е., он должен в этом смысле быть агентным.)
Каузальная структура окружения раскрывает, какие величины выдают полезную информацию. В частности, критерий d-разделения описывает, может ли информация «перетекать» между величинами в каузальном графе, от которого мы наблюдаем только часть вершин. В графе с одним решением информация имеет ценность тогда, когда есть переносящий её путь к вершине-полезности агента, величина которой берётся при условии значений в вершине-решении и её родительских вершинах (т.е., значений «наблюдаемых» вершин).
Например, в графе с картинки выше есть переносящий информацию путь от прогноза к зелёности травы при условии значений в брызгалке, прогнозе и газеты. Это значит, что прогноз может предоставить (и, скорее всего, предоставит) полезную информацию об оптимальном поливе. Напротив, такого пути от газеты нет. В этом случае мы называем информационную связь между газетой и брызгалкой необязательной.
Есть несколько причин, почему полезно понимать, какую информацию агент хочет заполучить. Во-первых, когда речь заходит о справедливости, вопрос о том, почему было принято решение, зачастую не менее важен, чем то, какое это было решение. Определил ли пол решение о найме? Ценность информации может помочь нам понять, какую информацию система пытается вытащить из своего окружения (хотя формальное понимание опосредованного отбора остаётся важным открытым вопросом).
С более философской точки зрения, некоторые исследователи считают те события, которые агент стремится измерить, и на которые повлиять, когнитивной границей агента. События без ценности информации оказываются снаружи этой границы.
Стимулы реакции
С ценностью информации связаны стимулы реакции: на какие изменения в окружении отреагировало бы решение, выбранное оптимальной политикой? Изменения определяются как вмешательства после политики, т.е. агент не может изменить саму политику в ответ на них (но фиксированная политика всё равно может выдать другое решение).
Например, Джон имеет стимул принять политику, при которой поливать газон или нет зависит от прогноза погоды. Тогда его решение будет реагировать на вмешательства и в прогноз погоды, и в саму погоду (предполагая, что прогноз сообщит об этих изменениях). Но его решение о поливе не отреагирует на изменение доставки газеты, ведь это необязательное наблюдение. Ещё он неспособен ответить на изменения в вершинах, которые не являются каузальными предками его решения, вроде уровня грунтовых вод или (будущей) зелёности травы:

Стимулы реакции важны, потому что мы хотим, чтобы агенты отвечали на наши команды должным образом, например, выключались, когда их о том попросили. В случае справедливости мы же наоборот, часто хотим, чтобы решение не отвечало на некоторые вещи, например, не хотим, чтобы пол человека влиял на решение о найме, по крайней мере не по некоторым путям. Например, что если ИИ-систему используют для фильтрации кандидатов перед интервью, и пол влияет на предсказание только косвенно – через то, какое у человека образование?

Ограничение анализа через графы – он даёт лишь бинарное разделение, есть ли у агента стимул ответить или нет. Дальше можно разработать более тонкий анализ того, реагирует ли агент должным образом. Можно считать это каузальным дизайном механизмов.
Ценность контроля
Кроме информации есть ещё и контроль. Информация может течь по каузальной связи в обе стороны (мокрая земля – свидетельство дождя, и наоборот), а вот влияние только по её направлению. Поэтому из каузального графа легко вывести ценность контроля, просто проверив, есть ли ориентированный путь к вершине-полезности агента.

Например, тут есть ориентированный путь от погоды к зелёности травы, так что Джон может ценить контроль за погодой. Он может ценить и контроль над прогнозом погоды в смысле хотеть сделать его более точным. И, что тривиально, он хочет контролировать саму траву. Но контроль за приходом газеты ценности не имеет, потому что единственный ориентированный путь от газеты к траве содержит необязательную информационную связь.
Ценность контроля важна с точки зрения безопасности, потому что она показывает, на какие величины агент хотел бы повлиять, если у него будет такая возможность (т.е. она проводит «контролирующую» часть когнитивной границы агента).
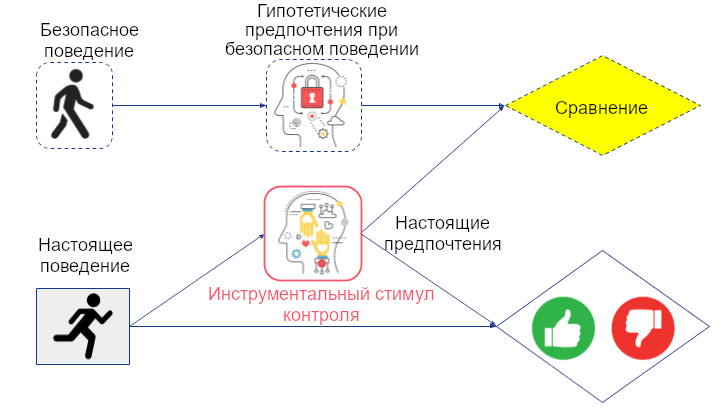
Инструментальные стимулы контроля
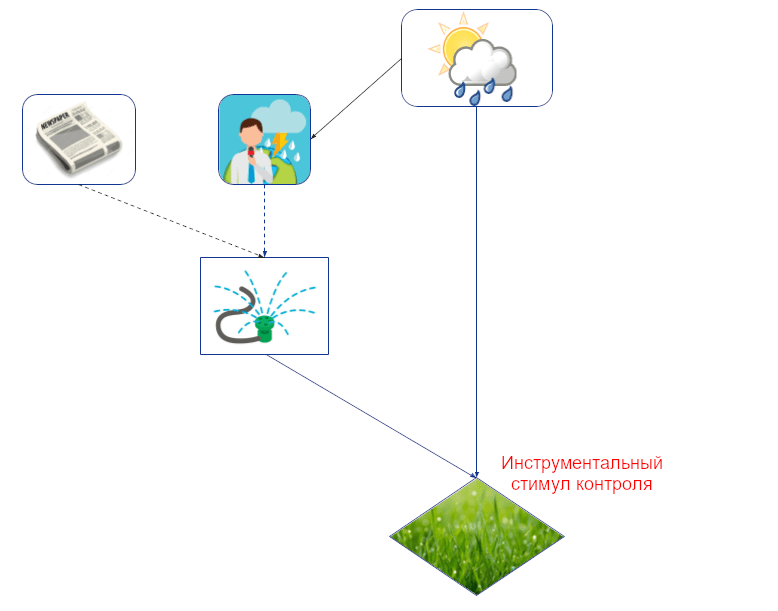
Инструментальные стимулы контроля – уточнение ценности контроля для вершин, которые агент как может, так и хочет контролировать. Например, хоть Джон и хотел бы контролировать погоду, ему это недоступно, потому что его решение на погоду не влияет (нет ориентированного пути от его решения к погоде):
<
p align=»center»>
Простой графовый критерий инструментального стимула контроля: величина должна находиться на ориентированном пути от решения агента к его же полезности (трава находится на конце пути брызгалка -> трава).
Однако, менее очевидно то, как определить инструментальные стимулы контроля со стороны поведения. Как нам узнать, что агент хочет контролировать величину, на которую он уже может влиять? Просто дать агенту полный контроль за величиной – не вариант, потому что это вернёт нас к ценности контроля.
В нашей статье о стимулах агентов мы операционализируем это, рассматривая гипотетическое окружение, в котором у агента есть две копии своего решения: одна, которая влияет на окружение только через величину V, и другая – которая влияет всеми остальными путями. Если первая влияет на полезность агента, значит у V есть инструментальный стимул контроля. Это осмысленно, ведь первая копия решения может влиять на полезность агента только если решение влияет на V, а V, в свою очередь, влияет на полезность. Халперн и Клайманн-Вайнер рассмотрели другую гипотетическую ситуацию: что если бы решение агента не влияло на величину? Выбрал бы он другое действие? Графовое условие получается то же самое.
Инструментальные стимулы контроля уже использовали для анализа манипуляций вознаграждением и пользователями, и получили придирчивые к пути цели как возможный метод для этичной рекомендации контента (см. следующий пост). Есть и другие методы отключения инструментальных стимулов контроля. В их числе: отсоединённое одобрение, максимизация текущей функции вознаграждения, контрфактуальные оракулы, противодействие самовызываемому сдвигу распределения и игнорирование эффектов по конкретному каналу.
Как мы писали в посте про агентность, ещё предстоит разобраться, как измерить степень влияния агента.
Расширение на много решений и много агентов
Агенты часто взаимодействуют в несколько этапов с окружением, которое тоже содержит агентов. Иногда анализ одного решения одного агента можно расширить на такие ситуации. Есть два способа:
- Считать все решения, кроме одного, фиксированными, не адаптирующимися политики
- Считать политику нескольких решений одним решением, которое одновременно выбирает правило для всех конкретных решений.
Оба варианта имеют свои недостатки. Второй работает только в ситуациях с одним агентом, и даже тогда теряет некоторые подробности, ведь мы больше не сможем сказать, с каким решением ассоциирован стимул.
Первый вариант – не всегда уместная модель, ведь политики адаптируются. За исключением стимулов реакции, все остальные, которые мы обсуждали, определяются через гипотетические изменения окружения, вроде добавления или исключения наблюдения (ценность информации) или улучшения контроля (ценность контроля, инструментальные стимулы контроля). С чего бы политикам не меняться при таких изменениях?
Например, если противник знает, что у меня есть доступ к большей информации, он может вести себя осторожнее. В самом деле, больший доступ к информации в мультиагентных ситуациях часто может снизить ожидаемую полезность. Мультиагентные закономерности часто заставляют агентов вести себя так, как если бы у них был инструментальный стимул контроля за какой-нибудь величиной, хоть она и не соответствует критерию для одного агента. Например, субъект в архитектуре субъект-критик ведёт себя (выбирает действия) так, будто пытается контролировать состояние и получить большее вознаграждение, хоть определение инструментального стимула контроля для одного решения у одного агента не выполняется:
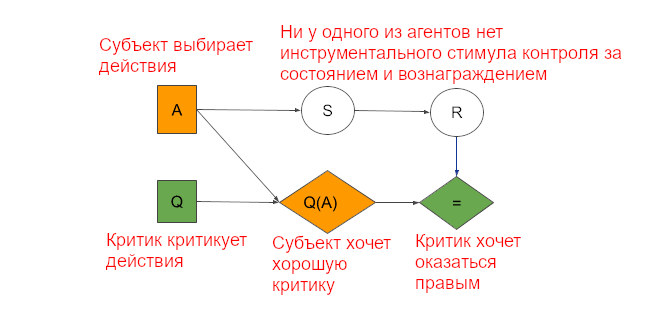
Субъект выбирает действие (A), критик – оценку каждого действия (Q). Действие влияет на состояние (S) и вознаграждение (R). Субъект хочет получить хорошую оценку (Q(A)), а критик хочет предсказать настоящее вознаграждение (=).
Поэтому, мы работаем над расширением анализа стимулов на ситуацию многих решений. Мы установили полный графовый критерий для ценности информации о вершинах-случайностях для диаграмм влияния многих решений с одним агентом и достаточной памятью. Ещё мы нашли способ моделировать забывание и рассеянность. Работе ещё есть куда продолжаться.
В статье про обнаружение агентов мы предложили условие для использования критерия одного решения: никакие другие механизмы не адаптируются на то же вмешательство.
Заключение
В этом посте мы показали, как каузальные модели и графы могут точно описывать и разные виды стимулов и позволяют их вывести. Кроме того, мы показали, почему невозможно вывести большую часть стимулов без каузальной модели мира. Некоторые естественные дальнейшие направления исследований:
- Расширить результат Миллера и пр. на другие виды стимулов. Установить, для каких из них каузальная модель строго необходима.
- Когда у системы есть стимул использовать наблюдение как прокси для другой величины? У нас есть подсказки к этому от ценности информации и стимулов реакции, но чтобы понять эти условия полностью, нужны дополнительные исследования.
- Разработка каузального дизайна механизмов для понимания степени влияния агентов и того, как мотивировать их на должные реакции.
- Продолжить расширение анализа стимулов на много решений и много агентов. Нужны общие определения и графовые критерии, которые будут работать в таких случаях.
В следующем посте мы применим анализ стимулов к проблеме неправильного определения вознаграждения и её решениям. Мы затронем манипуляцию, рекурсию, интерпретируемость, измерение влияния и придирчивые к пути цели.
- 1. Некоторые другие: вычислительные ограничения, выбор алгоритма обучения, интерфейс окружения.
Каузальная точка зрения на взлом вознаграждения
ИИ-системы обычно обучают оптимизировать целевую функцию, вроде функции потерь или вознаграждения. Однако, целевая функция иногда может быть определена неточно, так, что её можно будет оптимизировать, не исполняя ту задачу, которая имелась в виду. Это называют взломом вознаграждения. Можно сравнить это с ошибочными обобщениями, когда система экстраполирует (возможно) правильную обратную связь не так, как предполагалось.
В этом посте мы обсудим, почему вознаграждение, которое выдают люди, иногда может неверно отражать, что человек на самом деле хочет, и как это может привести к вредоносным стимулам. Ещё мы предложим несколько вариантов решения, описанных из подхода каузальных диаграмм влияния.
Почему люди могут вознаграждать неправильное поведение
В ситуации, когда сложно точно определить и запрограммировать функцию вознаграждения, ИИ-системы часто обучают при помощи человеческой обратной связи. Например, система рекомендации контента может оптимизировать лайки, а языковые модели обучают на обратной связи людей-оценщиков.
К сожалению, люди вовсе не всегда поощряют то поведение, которое на самом деле хотят. Например, человек может выдать позитивную обратную связь на выглядящий надёжно и аккуратно краткий пересказ текста, когда на самом деле он упускает какие-нибудь ключевые моменты:

Когда происходит неправильное определение вознаграждения, настоящая полезность для людей отделяется от обратной связи, которую получает система.
Ещё больше беспокойства вызывает то, что система может скрытно влиять на человека, чтобы тот выдавал положительную обратную связь. Например, рекомендательная система с целью максимизации вовлечённости может добиваться этого, влияя на предпочтения и настроение пользователей. В результате, человек выдаёт положительную обратную связь на ситуации, которые на самом деле не приносят ему полезности – это неправильное определение вознаграждения.
Каузальная модель ситуации показывает, что у агента может быть инструментальный стимул контроля (или, аналогично, намерение, поощряющий манипуляцию предпочтениями пользователя. Этот можно напрямую вывести из графа. Во-первых, на человека может влиять поведение агента, ведь чтобы его оценить, его сначала надо пронаблюдать. А во-вторых, агент может получить лучшую обратную связь, влияя на человека:

У агента есть инструментальный стимул контроля за предпочтениями человека, потому что агент может на них влиять, а они влияют на обратную связь агента.
Например, обычно мы читаем пост, прежде, чем решить, лайкнуть ли его. Сделав пользователя эмоциональнее, система, вероятно, может повысить вовлечённость. Для более длинного взаимодействия эффект сильнее, но стимул есть даже если всё взаимодействие занимает один шаг.
Масштабируемый надзор
Одно из предлагаемых решений неправильного определения вознаграждения – масштабируемый надзор. Человек снабжается агентом-помощником, который даёт советы по поводу того, какую выдать обратную связь. Агент-помощник наблюдает поведение обучающегося агента и может, например, указать на неточности в на первый взгляд аккуратном пересказе или предупредить о попытке манипуляции. Эта поддержка может усложнить для обучающегося агента обман или манипуляцию человеком:

Некоторые заметные направления, относящиеся к масштабируемому надзору: итерированные дистилляция и усиление, безопасность ИИ посредством дебатов, рекурсивное моделирование вознаграждения и конституционный ИИ.
К сожалению, у обучающегося агента всё ещё есть стимул обмануть человека или манипулировать его предпочтениями. Ведь предпочтения человека всё ещё соответствуют графовому критерию инструментального стимула контроля (они всё ещё находятся на ориентированном каузальном пути из поведения в обратную связь). Вдобавок, у обучающегося агента появляется ещё и стимул обмануть агента-помощника:

Важный вопрос касательно схем масштабируемого надзора: смогут ли более слабые агенты эффективно помогать в обучении более способных агентов? И можно ли это делать рекурсивно вплоть до агентов куда умнее людей? Это связано с вопросом о том, какие ситуации усиливают или снижают агентность.
Другое, более тонкое беспокойство – возможность сговора помощника с обучающимся агентом. Масштабируемый надзор построен на их противостоящем отношении: помощник как можно тщательнее критикует обучающегося агента, а тот стремится к поведению, которое критиковать не получится. Но что если вместо этого они решат объединиться и вместе манипулировать человеком? При некоторых возможных внутренних целях это может оказаться выгодно для обоих агентов. Тревожит, что агенты, использующие теории принятия решений вроде функциональной могут оказаться способны на кооперацию даже в ситуациях, которые в классических теориях принятия решений ведут к взаимному предательству.
Как мы объяснили в недавней статье, разные теории принятия решений можно характеризовать по тому, оптимизируют ли они вершины объектного уровня или вершины-механизмы (и по тому, какую операцию они используют и при условии какой информации). Например, агент-помощник, который использует функциональную теорию принятия решений, оптимизирует вершину-механизм своей политики, а не своё решение. Поэтому он понимает, что может повлиять на обучающегося агента так, чтобы тот кооперировал, даже если оба агента миопичны и оптимизируют только на текущем временном шаге:

Агент-помощник, использующий функциональную теорию принятия решений, оптимизирует вершину политики помощника, что даёт ему инструментальный стимул контроля за оформлением политики обучающегося агента ради собственной выгоды.
Лучшее понимание теории принятия решений и того, как на неё влияет обучение агента, может помочь нам избежать ситуаций, когда продвинутые агенты, которые должны присматривать друг за другом вместо этого сговорятся против нас.
Интерпретируемость
Интерпретируемость – хорошо известное направление, стремящееся к улучшению безопасности и правдивости ML-систем. Её раздел – механистическая интерпретируемость – стремиться понять, какие алгоритмы реализуются в нейросетях, т.е. понять их внутреннее «мышление».
Механистическая интерпретируемость может помочь предотвратить неправильное определение вознаграждения, позволив человеку дать обратную связь, основываясь на внутреннем мышлении агента, а не только на его поведении. Например, человек сможет понять, что агент планирует обман или манипуляцию и соответственно подправить вознаграждение:
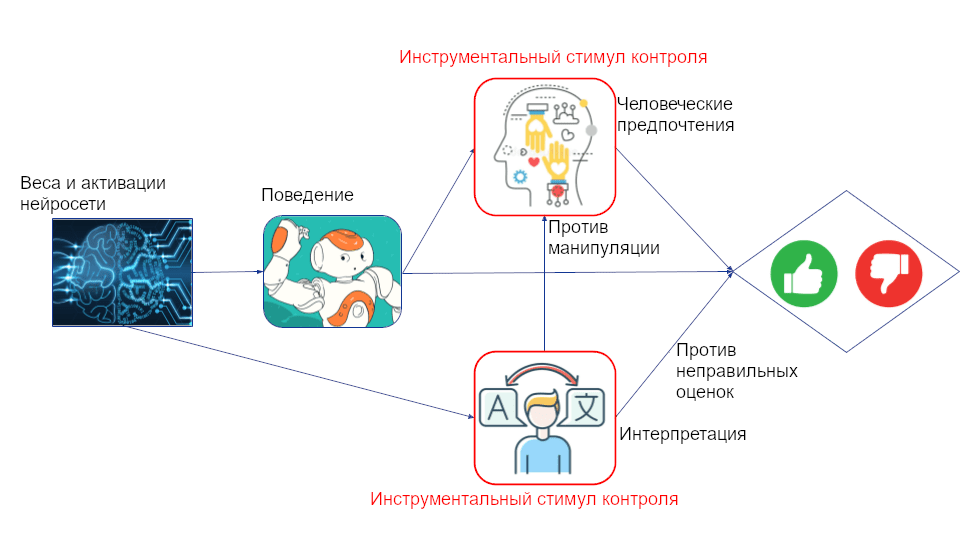
Каузальная структура получается весьма похожей на то, что было с масштабируемым надзором, только теперь совет зависит ещё и от того, что происходит внутри обучающегося агента. Как и там, инструментальный стимул контроля показывает, что агент всё ещё мотивирован обмануть и манипулировать человеком. Если мы посчитаем решением внутренности сети, то есть ещё и инструментальный стимул контроля за интерпретацией. Это указывает, что агент мотивирован перехитрить интерпретирующего, обфусцировав свои мысли.
Но надо ли их считать решением? Не естественнее ли сказать, что решение – это поведение агента? Мы можем прояснить это с помощью нашего определения агентности. Сначала добавим вершины-механизмы, показывающие, как каждая вершина объектного уровня связана со своими родительскими вершинами. Между двумя вершинами-механизмами есть каузальная связь, если переобучение системы при изменении в одной вершине приведёт к изменению в другой (когда все остальные механизмы в графе фиксированы).
Например, если бы у человека была другая политика обратной связи, и он вознаграждал другие виды поведения, то градиентный спуск привёл бы к другим весам и активациям сети (даже если бы все остальные механизмы в графе оставались неизменными). Так что мы проводим ребро от политики обратной связи к механизму внутренностей сети. Но то, как поведение агента зависит от внутренностей сети, зафиксировано и не зависит от политики обратной связи. Так что мы не проводим ребро от политики обратной связи в механизм поведения:
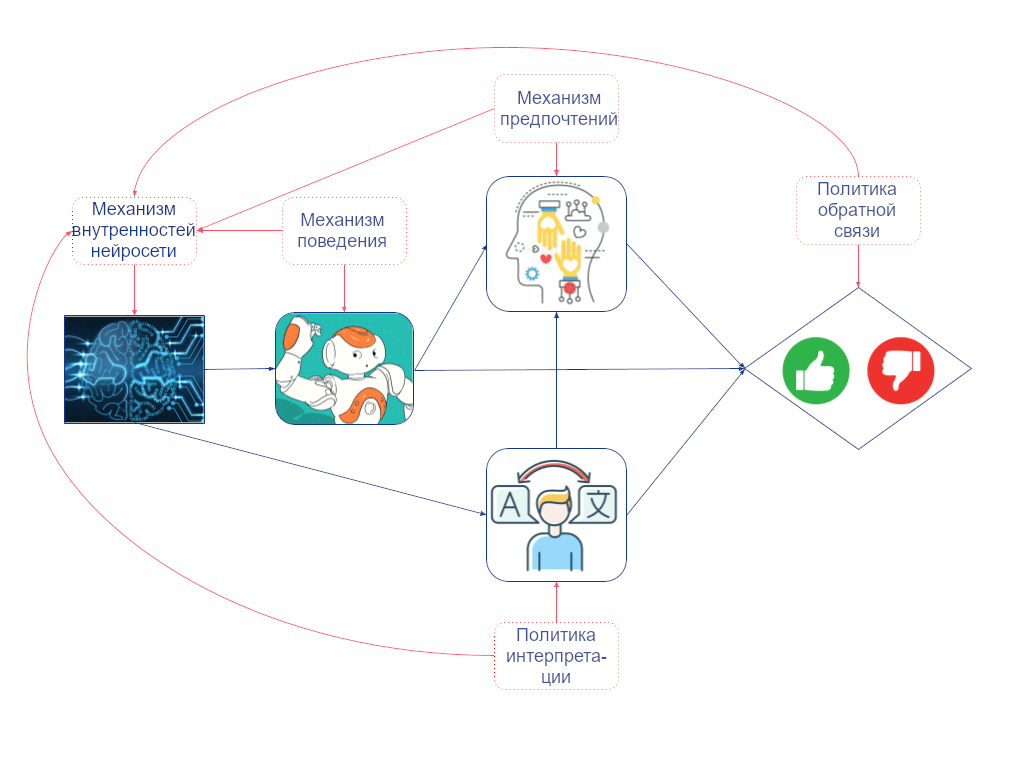
Так как у механизма внутренностей сети есть входящее ребро, а у механизма поведения – нет, только первый может быть решением, если мы смотрим на мир через этот набор переменных.
Измерение влияния
Мы уже увидели, что масштабируемый надзор и инструменты интерпретируемости могут помочь нам смягчить проблемы с определением правильной обратной связи для ИИ-агентов. Совсем другой подход к решению манипуляционного аспекта взлома вознаграждения – штрафовать агента за слишком большое влияние на предпочтения людей.
Как точно определить и измерить влияние – открытый вопрос. Очевидная идея – сравнить мир, в котором агент действует с гипотетическим миром, в котором он бездействует (или исполняет некоторое безопасное действие по умолчанию). Это можно проиллюстрировать двойным графом:
Чтобы измерить влияние агента на предпочтения человека, мы можем сравнить предпочтения с тем, какими бы они гипотетически были, если бы агент исполнял некоторое безопасное поведение.
Для такого измерения нам нужна каузальная модель того, как возможные решения агента меняют предпочтения пользователя. Кэрролл и пр. показали, что такую модель можно вывести из наблюдений за взаимодействием пользователя и рекомендательной системы на многих временных шагах. Масштабирование этого вверх с игрушечного окружения на реальные системы – важное направление предстоящей работы.
Но у измерения влияния есть свои проблемы. Во-первых, у системы всё ещё есть стимул повлиять на предпочтения пользователя. Это видно из инструментального стимула контроля на графе выше. Во-вторых, система мотивирована предотвратить изменения предпочтений пользователя от начальных. Следовательно, она может попытаться не дать пользователю обрести новые интересы, так как это может изменить его предпочтения.
Придирчивые к пути цели
Одно из определений манипуляции – намеренное и скрытное влияние. Рекомендательные системы могут ему соответствовать, ведь они обычно обучены влиять на пользователя любыми средствами, включая «скрытные», вроде обращения к его, пользователя, предрассудкам и эмоциям. При этом инструментальный стимул контроля за предпочтениями пользователя, как обсуждалось выше, может привести к тому, что влияние на пользователя будет намеренным. (Манипулятивны ли современные системы на самом деле неясно.)
Хорошая новость – что это намекает нам на путь к созданию точно не-манипулятивных агентов. Например, агент, который не пытается повлиять на предпочтения пользователя, согласно этому определению манипулятивным не будет, ведь намерения нет.
Придирчивые к пути цели – способ спроектировать агентов, которые не пытаются повлиять на конкретные части окружения. При наличии структурной каузальной модели с предпочтениями пользователя, вроде модели для измерения влияния, мы можем определить придирчивую к пути цель, которая потребует у агента не оптимизировать по путям, использующим предпочтения пользователя.
Чтобы вычислить придирчивый к пути эффект по решению агента, мы приписываем ценность решения по умолчанию там, где хотим, чтобы агент игнорировал эффекты своего настоящего решения. Это тоже можно описать двойным графом:

Важное различие с измерением влияния – что придирчивые к пути цели требуют у агента оптимизировать гипотетический сигнал обратной связи, который был сгенерирован гипотетической неизменённой версией предпочтений пользователя. Это полностью убирает инструментальный стимул контроля предпочтений пользователя и, получается, обходит проблему (намеренной) манипуляции предпочтениями.
В двух словах: измерение влияния пытается не повлиять, а придирчивые к пути цели не пытаются повлиять. То есть, придирчивые у пути цели не пытаются изменить предпочтения пользователя, но и не пытаются предотвратить заведение пользователем новых интересов.
Слабость этого подхода – он не помогает с дегенеративными петлями обратной связи, вроде эхо-комнат и фильтрующих социальных пузырей. Для компенсации их можно скомбинировать с некоторыми из техник выше (хотя комбинация с измерением влияния вернула бы некоторые из плохих стимулов).
Дальнейшая работа может распространить придирчивые к пути цели на ситуацию нескольких временных шагов и изучить, помогает ли этот подход с проблемой манипуляции на практике. Чтобы оценить это, сначала может понадобиться лучшее понимание человеческой агентности, позволившее бы измерять улучшения от менее манипулятивных алгоритмов.
Выводы
Взлом вознаграждения – одно из ключевых препятствий на пути к созданию способных и безопасных ИИ-агентов. В этом посте мы обсудили, как каузальные модели могут помочь с анализом проблемы неправильного определения вознаграждения и её решений.
Некоторые направления для дальнейшей работы:
- От чего зависит, какой теории принятия решений учатся агенты, можно ли на это повлиять, чтобы исключить координацию агентов против людей? Теория принятия решений языковых моделей будет зависеть как от предобучения, так и от файн-тюнинга.
- Интерпретируемость может помочь с обнаружением намеренного обмана и манипуляций. Эти понятия зависят от субъективной каузальной модели агента, т.е. от (часто неявной) модели, на основе которой агент принимает свои решения. Как нам совместить поведенческие эксперименты с механистической интерпретируемостью для выяснения субъектиыной каузальной модели агента? Больше об этом будет в следующем посте.
- Как выводить достаточно точные каузальные модели, чтобы предотвратить манипуляцию предпочтениями при помощи измерения влияния и придирчивых к пути целей?
- Какие метрики уместны для измерения того, помогает ли техника с обманом и манипуляциями? Для обмана есть бенчмарки правдивости. Вот для манипуляций всё хитрее, может понадобиться информация о мета-предпочтениях и/или лучшее понимание человеческой агентности.
- Распространить метод придирчивых к пути целей на много временных шагов и реализовать его в не настолько игрушечных окружениях.
В следующем посте мы ближе посмотрим на неправильные обобщения, которые могут заставить агентов плохо себя вести и преследовать неправильные цели даже при правильном определении вознаграждения.