Вы здесь
Главные вкладки
Каузальная точка зрения на агентность
У этого поста две цели: положить основу для следующих постов, исследовав, что такое агентность, с каузальной точки зрения, и обрисовать программу исследований, нужных для более глубокого понимания агентности.
Важность понимания агентности
Агентность – сложный концепт, который изучают с разных точек зрения. Ею интересуются и науки об обществе, и философия, и исследования ИИ. В самых общих чертах агентность – это способность системы действовать самостоятельно. В этом посте мы интерпретируем агентность как направленность на цель, т.е. действие таким образом, как если бы система пыталась изменить мир в конкретную сторону.
Есть мощные стимулы создавать всё более агентные ИИ-системы. Такие системы потенциально смогут выполнять многие задачи, для которых сейчас нужны люди: самостоятельно проводить исследования или даже управлять собственными компаниями. Но к большей агентности прилагаются дополнительные потенциальные опасности и риски, ведь направленная на цель ИИ-система может стать способным противником, если её цели не согласованы с интересами людей.
Лучшее понимание агентности может позволить нам:
- Понять опасности и риски мощных систем машинного обучения.
- Оценить, обладает ли конкретная ML-модель опасным уровнем агентности.
- Проектировать неагентные системы, вроде СИИ-учёных или оракулов, или агентные безопасным образом.
- Положить основание для прогресса в других областях безопасности СИИ, вроде интерпретируемости, стимулов и изучении обобщений.
- Уберечь человеческую агентность, например, через лучшее понимание условий, в которых ей уровень повышается или понижается.
Степени свободы
(Преследующие цели) агенты бывают самыми разными – от бактерий до людей, от футбольных команд до государств, от RL-политик, до LLM-симулякр. Несмотря на это, у них есть некоторые общие фундаментальные черты.
Для начала, агенту нужна свобода выбирать из некоторого набора вариантов.1 Нам не надо предполагать, что это решение свободно от каузальных воздействий, а то мы никак не сможем предсказывать его заранее – но должен быть смысл в котором оно могло бы быть разным. Деннетт назвал это степенями свободы.
Например, Джон может выбирать, включать брызгалку или нет. Мы можем моделир.овать его решение как случайную величину с возможными значениями «поливает» и «не поливает»:

Степени свободы можно показать возможными значениями случайной величины
Степени свободы бывают разные. Термостат может выбирать только мощность нагревателя, а большинству людей доступен большой набор физических и вербальных действий.
Влияние
Во-вторых, чтобы что-то значить, у поведения агента должны быть последствия. Решение Джона включить брызгалку влияет на то, будет ли трава зелёной.
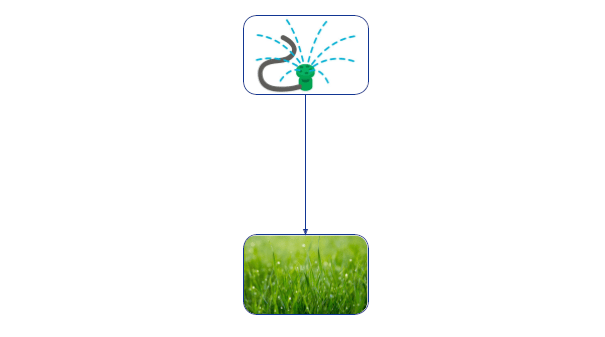
Брызгалка Джона влияет на зелёность травы.
У одних агентов влияния больше, чем у других. Например, влияние языковой модели сильно зависит от того, взаимодействует ли она лишь со своими разработчиками или с миллионами пользователей через открытый API. Каузальное влияние наших действий, кажется, определяет у людей ощущение агентности. Предлагались такие меры влияния как (каузальная пропускная способность, перформативная мощность и власть в марковских процессах принятия решений.
Адаптация
В третьих, и это самое важное, стремящиеся к целям агенты делают что-то не просто так. То есть, (они действуют как будто) у них есть предпочтения о мире и эти предпочтения управляют их поведением. Джон включает брызгалку, потому что она делает траву зелёной. Если бы траве не была нужна вода, то Джон скорее всего её бы не поливал. Последствия управляют поведением.
Эту петлю обратной связи, обратной каузальности, можно показать, добавив к каждой вершине объектного уровня нашего графа так называемую вершину-механизм. Вершина-механизм определяет каузальный механизм её объектной вершины, т.е., то, как её значение определяется её родительскими вершинами объектного уровня. Например, вершина-механизм брызгалки определяет политику поливания Джона, а вершина-механизм травы определяет то, как трава реагирует на разное количество воды:обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может -- это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда." href="#footnote2_1q59qka">2
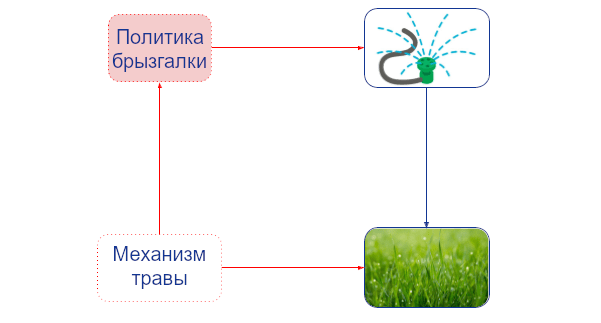
Механистический каузальный граф показывает адаптацию Джона на изменения в окружении. Вершины-механизмы отмечены красным, а вершины объектного уровня – синим.
Явное отображение каузальных механизмов в вершинах позволяет нам рассматривать вмешательства в них. Например, вмешательство в механизм травы может превратить её в траву, которой нужно меньше воды. Связь между механизмом травы и политикой брызгалки сообщает, что такое вмешательство может повлиять на привычки поливания Джона.3 То есть, он адаптирует своё поведение, чтобы всё ещё достигать своей цели.
При правильных переменных и экспериментах адаптацию можно заметить при помощи алгоритмов каузальных открытий. Это потенциально можно использовать для обнаружения агентов. В частности, когда одна величина-механизм адаптируется на изменения в другой, может быть, что первая относится к вершине-решению, а вторая – к вершине-полезности, которую оптимизирует это решение. Если агенты – идеальные теоретикоигровые агенты, более оформленная версия этих условий оказывается необходимым и достаточным критерием обнаружения вершин-решений и вершин-полезностей.
Адаптация тоже бывает разная. Деннетт проводит различие между Дарвинианскими, Скиннерианскими, Попперианскими и Грегорианскими агентами, в зависимости от того, адаптировались ли они эволюцией, опытом, планированием или обучением от других соответственно. Например, человек, который заметил, что холодно, наденет пальто, а биологический вид может на эволюционных масштабах отрастить шерсть подлиннее. Языковые модели скорее всего попадают на высший, Грегорианский, уровень – их можно обучить чему-то в промпте, и они много что переняли у людей при предобучении.
Количественную меру адаптации можно получить, рассмотрев, как быстро и эффективно агент адаптируется к различным вмешательствам. Скорость адаптации можно измерять, если расширить наш подход механизмом вмешательств на разных временных масштабах (например, человеческих или эволюционных). Эффективность конкретной адаптации можно количественно оценить, сравнив то, насколько хорошо справляется агент без вмешательства и с ним. Обычная метрика этого при использовании функций вознаграждения – сожаление (в худшем случае). Наконец, то, к каким вмешательствам в окружение агент сможет должным образом адаптироваться, служит мерой того, насколько он устойчив, а к каким вмешательствам в полезность – его перенаправляемость или обобщённость по задачам.
В следующем посте мы представим результат, который показывает, что для адаптации надо, чтобы у агента была каузальная модель. Этот результат дополнит поведенческую точку зрения, которой мы придерживаемся в этом посте, внутренними представлениями агента.
Последовательность и самосохранение
С адаптациями связан вопрос о том, насколько последовательно агент преследует долгосрочные цели. Например, почему государства могут реализовывать большие инфраструктурные проекты на протяжении десятилетий, а (нынешние) агенты на основе языковых моделей (вроде autoGPT) быстро сходят с курса? Во-первых, отталкиваясь от рассуждений выше, мы можем операционализировать цель через то, к каким вмешательствам в механизмы агент адаптируется. Например, подхалимская языковая модель,которая адаптирует свои ответы к политическим убеждениям пользователя, может обладать целью удовлетворить пользователя или получить большее вознаграждение. Развивая это, последовательность можно операционализировать через то, насколько схожи цели разных вершин-решений. Интересно, что к большему интеллекту вовсе не обязательно прилагается большая последовательность.
Если агент не продолжает своё существование, он не может последовательно стремиться к цели. Это, вероятно, причина, почему, как мы упоминали в вводном посте, мы (люди) хотим уберечь свою агентность.4 Нынешние языковые модели выражают стремление к самосохранению. Для контраста, более ограниченные системы, вроде рекомендательных систем и систем GPS-навигации вовсе не демонстрируют никакого стремления к самосохранению, несмотря на то, что они в какой-то мере направлены на цели.
Собирая всё вместе
Пока что мы обсудили восемь параметров агентности: степени свободы; влияние; скорость, эффективность, устойчивость и перенаправляемость адаптаций; последовательность и самосохранение. К списку можно добавить ещё (марковскую отделённость от окружения (например, клеточную стенку, кожу или шифрование внутренних емейлов, это показывает d-разделение каузального графа) и то, сколько информации об окружении или его восприятия есть у агента.
Все эти параметры относятся к силе или свойствам разных каузальных взаимосвязей и могут быть сопоставлены с разными частями нашей диаграммы:

Параметры агентности
Эти параметры дополнительно подчёркивают то, что агентности бывает больше и меньше. Причём система бывает более или менее агентна по нескольким осям. Например, человек более агентен, чем рыба, которая более агентна, чем термостат, а AlphaGo превосходит людей по последовательности, но обладает куда меньшей степенью свободы.
Будущая работа
Высокоуровневое обсуждение в этом посте должно было объяснить концептуальную связь между агентностью и каузальностью. В частности, адаптация – каузальное понятие, обозначающее, как на поведение воздействуют вмешательства на окружение или цели агента. Следующие посты будут основываться на этой идее.
Ещё хотелось бы подсветить некоторые возможные направления для дальнейшей работы, к которым приводит такая точка зрения:
- Какие у агентности ключевые параметры? Как едино сформулировать описанные выше понятия? Как они связаны с оптимизационной силой и основаниями оптимизации? Есть ли базисный набор взаимно независимых параметров агентности, от которого образуются все остальные?
- Можно ли измерить направленность на цель в языковых моделях и людях? Наверное, направленность на цель и сила оптимизации могут быть в общем случае ограничены (сверху) влиянием, адаптациями, последовательностью, и т.д. агента. Это может что-то дать оценкам опасных способностей.
- Могли бы мы спроектировать агентов так, чтобы они были только частично направлены на цель? Рекомендательные системы и системы GPS-навигации вовсе не проявляют стремления к самосохранению, несмотря на то, что в какой-то мере они направлены на цели. Нынешние языковые модели демонстрируют стремление к самосохранению, но, может быть, этого можно избежать? Скорее всего, эволюция, разрабатывая биологических агентов, одновременно отбирала по всем перечисленным параметрам, но искусственные системы могут не сталкиваться с эволюционным давлением. Если бы можно было избежать случайного и намеренного создания последовательных агентов с стремлением к самосохранению, это могло бы потенциально открыть путь к получению большей части выгоды ИИ с лишь малой долей риска.
- Можем ли мы лучше понять, при каких условиях агентность возникает из менее агентных компонентов? Когда агентность растёт и когда уменьшается? Когда цифровой ассистент или рекомендательная система усиливает мою агентность, а когда подавляет? Что если я играю в шахматы при помощи AlphaZero?
Следующий пост будет сосредоточен на стимулах. Важно понимать стимулы, чтобы продвигать в наших ИИ-системах правильное поведение. Как мы увидим, анализ стимулов естественным путём строится на основе понятия агентности, как мы его обсудили в этом посте.
- 1. Некоторые применения термина «агент» могут позволить системе быть агентом даже если она никак не может выбирать действия, вроде полностью парализованного человека. Мы не используем термин в этом смысле. Мы сосредоточены на направленных на цель и действующих системах. Ещё стоит заметить, что для нас агентность относительна – зависит от «рамок», определённых величинами в модели. Если брызгалка Джона сломается, у него не будет агентности в связи с примером из поста, но он всё ещё будет обладать агентностью в каких-то других рамках (например, он всё ещё сможет гулять по своему двору).
- 2. Как обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может – это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда.
- 3. Есть альтернативная интерпретация, естественная с точки зрения конечно-факторизуемых множеств. Можно интерпретировать поведение агента как отвечающее на более точные вопросы, чем его цель, и вершины объектного уровня – на более точные вопросы, чем вершины-механизмы. Ещё в связи с этим: каузальные взаимосвязи можно вывести из алгоритмической теории информации. Это удобно при обсуждении независимости вершин, на которые не оказывается вмешательств.
- 4. Иногда такие мета-предпочтения рассматривают как характеристический признак агентности. Скорее всего, их можно моделировать аналогично обычным предпочтениям, добавив ещё один слой вершин-механизмов (т.е. механизмы для механизмов).
- Короткая ссылка сюда: lesswrong.ru/3561