Вы здесь
Главные вкладки
Вступление «Введения в каузальные основания безопасного СИИ»
В следующие несколько лет появление продвинутых ИИ-систем заставит общество, организации и отдельных людей столкнуться с некоторыми фундаментальными вопросами:
- Как увериться, что продвинутые ИИ-системы будут делать именно то, что мы от них хотим (задача согласования)?
- Когда систему достаточно безопасно разрабатывать и развёртывать, и каких свидетельств достаточно, чтобы посчитать, что это так?
- Как нам сохранить свою автономию и контроль за ситуацией, когда принятие решений всё больше будет перекладываться на цифровых помощников?
В этой цепочке постов мы объясним, как каузальная точка зрения на агентность даёт концептуальные инструменты при помощи которых можно разбираться в этих вопросах. Мы постараемся минимизировать применение жаргона и объяснять его, где он всё же будет, чтобы цепочка была доступна исследователям с самым разным опытом.
Агентность
Для начала, под агентом мы имеем в виду направленную на цель систему, которая действует так, как если бы она пыталась менять мир в некотором конкретном направлении/направлениях. Примеры агентов: животные, люди и организации (в следующем посте об агентах будет больше). Понимание агентов – ключ к перечисленным вопросам. Популярно мнение, что искусственные агенты – основная экзистенциальная угроза технологий уровня сильного искусственного интеллекта, неважно, возникли ли они спонтанно или были спроектированы намеренно. Есть много потенциальных угроз нашему существованию, но высокоспособные агенты выделяются. Многих целей достигать эффективнее, накапливая влияние на мир. Если к Земле летит астероид, то он не намерен вредить людям и не будет сопротивляться отклонению. А вот несогласованные агенты могут занять противостоящую позицию активной угрозы.
Во-вторых, как для отдельных людей, так и для организаций критически важно не утратить в грядущем технологическом переходе человеческую агентность. Уже всплывает беспокойство о том, что манипулятивные алгоритмы социальных медиа и системы рекомендации контента вредят способности пользователей сосредотачиваться на своих долгосрочных целях. Более мощные ассистенты усилят эту тенденцию. По мере всё большей передачи принятия решений ИИ-системам, способность общества выбирать свою траекторию будет становиться всё более сомнительной.
Человеческую агентность тоже можно взращивать и защищать. Помогать людям помочь себе – не так патерналистично, как напрямую исполнять их пожелания. Содействие усилению людей может меньше прямого удовлетворения предпочтений зависеть от полного решения задачи согласования. Теория самодетерминации даёт свидетельства, что люди ценят агентность саму по себе, и некоторые из прав человека можно интерпретировать как защиту нашей нормативной агентности.
В третьих, искусственные агенты могут в какой-то момент сами стать объектами морали. Более ясное понимание агентности может помочь нам уточнить свою моральную интуицию и избежать неприемлемых действий. Не исключено, что некоторых этических дилемм избежать можно только создавая искусственные системы, которые объектами морали не будут.
Ключевые вопросы
Мы надеемся, что наши исследования помогут создать теорию агентности. Такая теория в идеале должна отвечать на вопросы вроде таких:
- Какие разновидности агентов могут быть созданы? По каким измерениям они могут отличаться? Мы пока в основном встречали животных, людей и организации из людей, но пространство возможных направленных на цель систем скорее всего куда больше.
- Эмерджентность: как появляются агенты? Например, в какой момент большая языковая модель стать агентной? Когда система агентов становится мета-агентов вроде организации?
- Обессиливание: как агентность теряется? Как нам уберечь и взращивать человеческую агентность?
- Какие есть этические требования по поводу разных видов систем и агентов?
- Как опознавать агентов и измерять агентность? Конкретные определения помогли бы нам заметить появление агентности у искусственных систем и потерю агентности у людей.
- Как предсказать поведение агента? К какому поведению у агентов есть стимулы? Как агенты обобщают на новые ситуации? Если мы поймём и эффекты этого поведения, то будем способны предсказывать опасность.
- Какие у агентов могут быть взаимоотношения? Какие из них вредны, а какие полезны?
- Как нам создавать агентов безопасными, справедливыми и выгодными?
Каузальность
Каузальность помогает понимать агентов. Философы давно заинтересованы каузальностью, не только потому, что точная взаимосвязь причин и следствий интригует разум, но и потому, что она лежит в основе огромного числа других понятий, многие из которых важны для понимания агентов и проектирования безопасного СИИ.
Например, воздействие и реакция – понятия, связанные с каузальностью. Мы хотим, чтобы агенты положительно влияли на мир и должным образом реагировали на инструкции. На каузальности основаны и многие другие относящиеся к делу понятия:
- Агентность, потому что направленная на цель система – та, цели которой управляют (являются причиной) её поведения.
- Намерение, относящееся к причинам действия и связи средства-цель. Намерение – важное понятие для возможности присваивать юридическую и моральную ответственность.
- Вред, манипуляция и обман, которые относятся к тому, как оказывалось воздействие на ваше благополучие, действия или убеждения, и которые обычно считаются намеренными.
- Справедливость, в частности – как реагировать на личные атрибуты вроде пола или расы и позволять им влиять на решения.
- Устойчивое обобщение при изменениях окружения куда проще для агентов с каузальной моделью этого окружения.
- Гипотетические ситуации/контрфактуалы как альтернативные миры, отличающиеся от нашего одним или многими каузальными воздействиями.
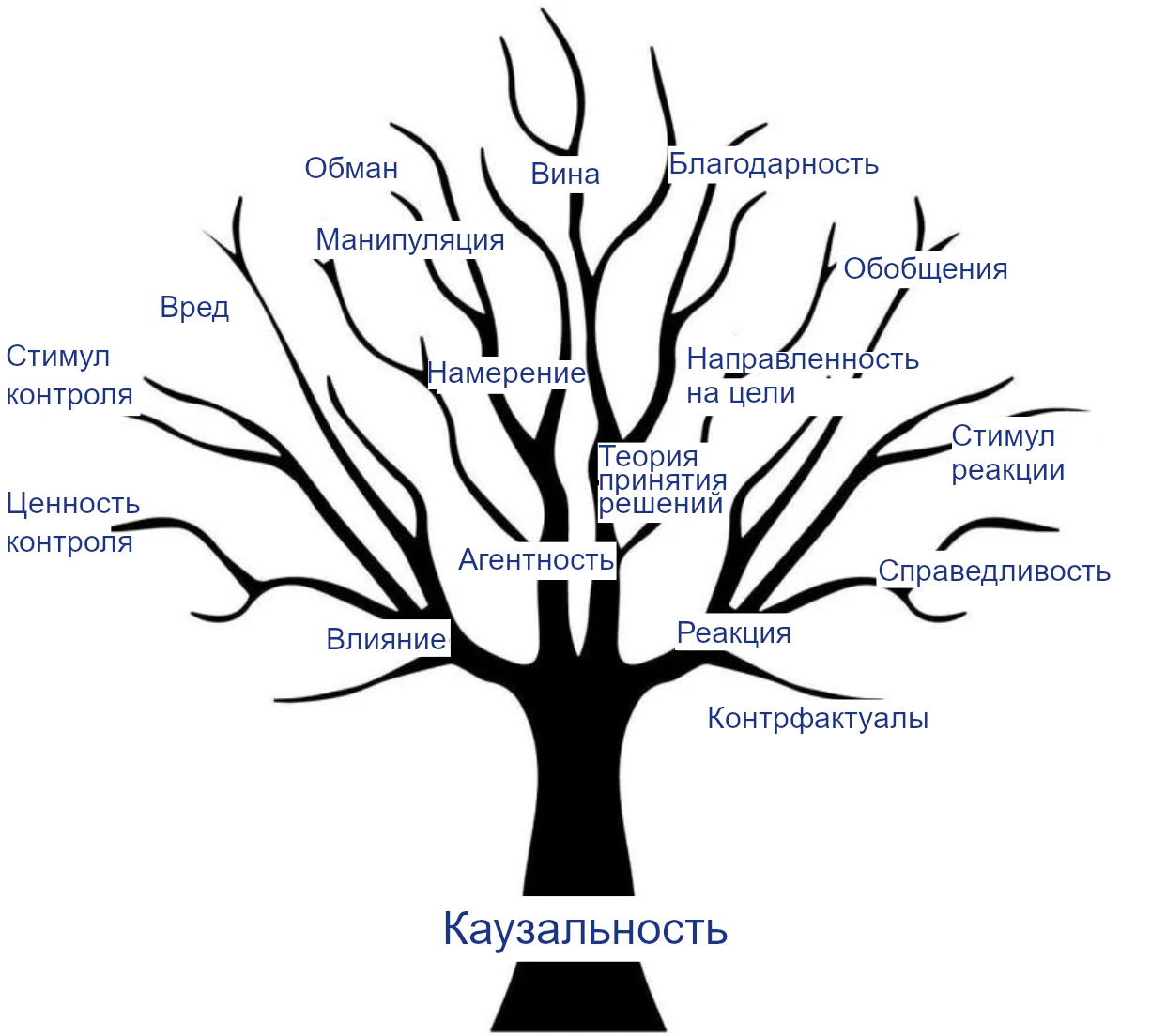
Дерево каузальности
Дальше в этой цепочке мы подробнее расскажем, как эти понятия основаны на каузальности и к каким исследованиям это привело. Мы надеемся, что это откроет другим исследователям путь путь и вдохновит их присоединиться к нашим усилиям по созданию на базе каузальности формальной теории безопасного (С)ИИ. Большая часть нашей недавней работы истекает из этого видения. Например, в «Открывая агентов» изучая агентов и «Рассуждениях о каузальности в играх» мы выработали лучшее понимание того, как сопоставить аспекты реальности с каузальными моделями. В статье про стимулы агентов мы показали, как такие модели можно анализировать, чтобы выявить важные для безопасности свойства. «Придирчивыми к пути целями» мы показали, как такой анализ может вдохновлять лучшее проектирование.
Мы надеемся, что это поможет и другим важным для безопасности СИИ направлениям исследований, вроде масштабируемого согласования, оценок опасных способностей, устойчивости, интерпретируемости, этики, управления, прогнозирования, оснований агентности и картирования рисков.
Заключение
Мы надеемся, что основанное на каузальности понимание агентности и связанных понятий поможет проектировщикам ИИ-систем, разъяснив, что есть в пространстве возможных агентов и как избежать особенно рискованных конфигураций. Оно может помочь регуляторам обрести лучшее представление о том, за чем следить, и что должно считаться достаточным свидетельством безопасности. Оно может помочь всем нам решить, какое поведение допустимо по отношению к каким системам. И, наконец, оно может помочь отдельным людям понять, что они стремятся сохранить и преумножить в своих взаимодействиях с искусственными разумами.
В следующем посте мы подробнее разъясним каузальность, каузальные модели, разные каузальные модели Перла и то, как их можно обобщить на случай наличия одного или нескольких агентов.
- Короткая ссылка сюда: lesswrong.ru/3559