Каузальная точка зрения на стимулы
«Покажи мне стимулы, и я покажу тебе результат.»
– Чарли Мунгер
Предсказание поведения очень важно при проектировании и развёртывании агентных ИИ-систем. Стимулы – одни из ключевых сил, формирующих поведение агентов,1 причём для их понимания нам не надо полностью понимать внутреннюю работу системы.
Этот пост показывает, как каузальная модель агента и его окружения может раскрыть, что агент хочет знать и что хочет контролировать, а также как он отвечает на команды и влияет на своё окружение. Это сочетается с уже полученным результатом о том, что некоторые стимулы можно вывести только из каузальной модели. Так что для полноценного анализа стимулов она необходима.
Ценность информации
Какую информацию агент захочет узнать? Возьмём, к примеру, Джона, который решает, полить ли ему газон, основываясь на прогнозе погоды и том, пришла ли ему его утренняя газета. Знание погоды означает, что он может поливать больше, когда будет солнечно, чем когда будет дождь, что экономит ему воду и повышает зелёность травы. Так что прогноз погоды для решения о брызгалке обладает информационной ценностью, а пришла или нет газета – нет.
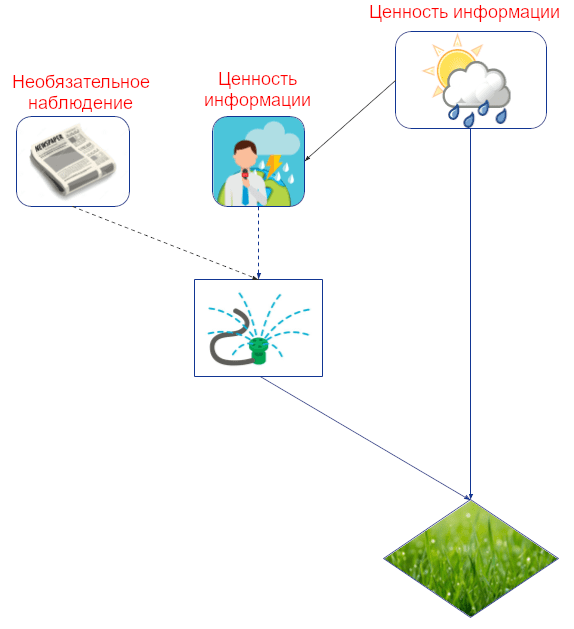
Мы можем численно оценить то, насколько полезно для Джона знание о погоде, сравнив его ожидаемую полезность в мире, где он посмотрел прогноз, с миром, где не посмотрел. (Это имеет смысл только если мы предполагаем, что Джон должным образом адаптируется в обоих мирах, т.е., он должен в этом смысле быть агентным.)
Каузальная структура окружения раскрывает, какие величины выдают полезную информацию. В частности, критерий d-разделения описывает, может ли информация «перетекать» между величинами в каузальном графе, от которого мы наблюдаем только часть вершин. В графе с одним решением информация имеет ценность тогда, когда есть переносящий её путь к вершине-полезности агента, величина которой берётся при условии значений в вершине-решении и её родительских вершинах (т.е., значений «наблюдаемых» вершин).
Например, в графе с картинки выше есть переносящий информацию путь от прогноза к зелёности травы при условии значений в брызгалке, прогнозе и газеты. Это значит, что прогноз может предоставить (и, скорее всего, предоставит) полезную информацию об оптимальном поливе. Напротив, такого пути от газеты нет. В этом случае мы называем информационную связь между газетой и брызгалкой необязательной.
Есть несколько причин, почему полезно понимать, какую информацию агент хочет заполучить. Во-первых, когда речь заходит о справедливости, вопрос о том, почему было принято решение, зачастую не менее важен, чем то, какое это было решение. Определил ли пол решение о найме? Ценность информации может помочь нам понять, какую информацию система пытается вытащить из своего окружения (хотя формальное понимание опосредованного отбора остаётся важным открытым вопросом).
С более философской точки зрения, некоторые исследователи считают те события, которые агент стремится измерить, и на которые повлиять, когнитивной границей агента. События без ценности информации оказываются снаружи этой границы.
Стимулы реакции
С ценностью информации связаны стимулы реакции: на какие изменения в окружении отреагировало бы решение, выбранное оптимальной политикой? Изменения определяются как вмешательства после политики, т.е. агент не может изменить саму политику в ответ на них (но фиксированная политика всё равно может выдать другое решение).
Например, Джон имеет стимул принять политику, при которой поливать газон или нет зависит от прогноза погоды. Тогда его решение будет реагировать на вмешательства и в прогноз погоды, и в саму погоду (предполагая, что прогноз сообщит об этих изменениях). Но его решение о поливе не отреагирует на изменение доставки газеты, ведь это необязательное наблюдение. Ещё он неспособен ответить на изменения в вершинах, которые не являются каузальными предками его решения, вроде уровня грунтовых вод или (будущей) зелёности травы:

Стимулы реакции важны, потому что мы хотим, чтобы агенты отвечали на наши команды должным образом, например, выключались, когда их о том попросили. В случае справедливости мы же наоборот, часто хотим, чтобы решение не отвечало на некоторые вещи, например, не хотим, чтобы пол человека влиял на решение о найме, по крайней мере не по некоторым путям. Например, что если ИИ-систему используют для фильтрации кандидатов перед интервью, и пол влияет на предсказание только косвенно – через то, какое у человека образование?

Ограничение анализа через графы – он даёт лишь бинарное разделение, есть ли у агента стимул ответить или нет. Дальше можно разработать более тонкий анализ того, реагирует ли агент должным образом. Можно считать это каузальным дизайном механизмов.
Ценность контроля
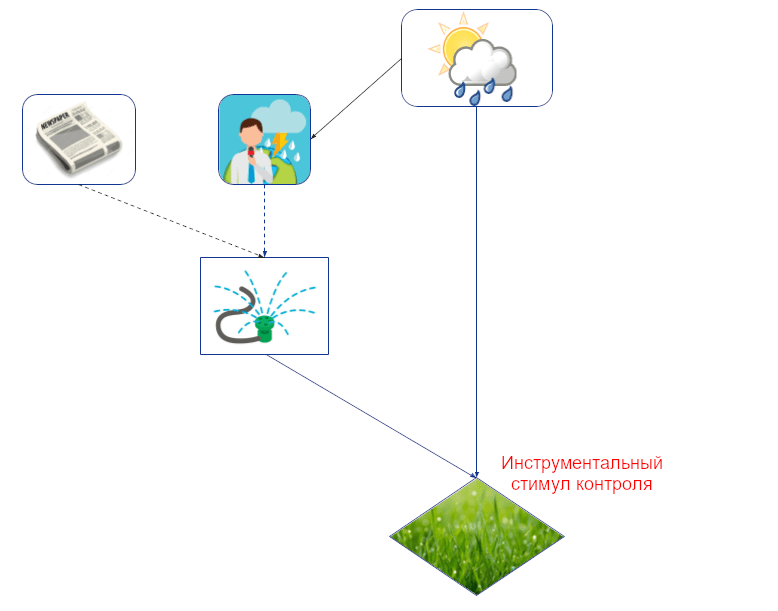
Кроме информации есть ещё и контроль. Информация может течь по каузальной связи в обе стороны (мокрая земля – свидетельство дождя, и наоборот), а вот влияние только по её направлению. Поэтому из каузального графа легко вывести ценность контроля, просто проверив, есть ли ориентированный путь к вершине-полезности агента.

Например, тут есть ориентированный путь от погоды к зелёности травы, так что Джон может ценить контроль за погодой. Он может ценить и контроль над прогнозом погоды в смысле хотеть сделать его более точным. И, что тривиально, он хочет контролировать саму траву. Но контроль за приходом газеты ценности не имеет, потому что единственный ориентированный путь от газеты к траве содержит необязательную информационную связь.
Ценность контроля важна с точки зрения безопасности, потому что она показывает, на какие величины агент хотел бы повлиять, если у него будет такая возможность (т.е. она проводит «контролирующую» часть когнитивной границы агента).
Инструментальные стимулы контроля
Инструментальные стимулы контроля – уточнение ценности контроля для вершин, которые агент как может, так и хочет контролировать. Например, хоть Джон и хотел бы контролировать погоду, ему это недоступно, потому что его решение на погоду не влияет (нет ориентированного пути от его решения к погоде):
<
p align=»center»>
Простой графовый критерий инструментального стимула контроля: величина должна находиться на ориентированном пути от решения агента к его же полезности (трава находится на конце пути брызгалка -> трава).
Однако, менее очевидно то, как определить инструментальные стимулы контроля со стороны поведения. Как нам узнать, что агент хочет контролировать величину, на которую он уже может влиять? Просто дать агенту полный контроль за величиной – не вариант, потому что это вернёт нас к ценности контроля.
В нашей статье о стимулах агентов мы операционализируем это, рассматривая гипотетическое окружение, в котором у агента есть две копии своего решения: одна, которая влияет на окружение только через величину V, и другая – которая влияет всеми остальными путями. Если первая влияет на полезность агента, значит у V есть инструментальный стимул контроля. Это осмысленно, ведь первая копия решения может влиять на полезность агента только если решение влияет на V, а V, в свою очередь, влияет на полезность. Халперн и Клайманн-Вайнер рассмотрели другую гипотетическую ситуацию: что если бы решение агента не влияло на величину? Выбрал бы он другое действие? Графовое условие получается то же самое.
Инструментальные стимулы контроля уже использовали для анализа манипуляций вознаграждением и пользователями, и получили придирчивые к пути цели как возможный метод для этичной рекомендации контента (см. следующий пост). Есть и другие методы отключения инструментальных стимулов контроля. В их числе: отсоединённое одобрение, максимизация текущей функции вознаграждения, контрфактуальные оракулы, противодействие самовызываемому сдвигу распределения и игнорирование эффектов по конкретному каналу.
Как мы писали в посте про агентность, ещё предстоит разобраться, как измерить степень влияния агента.
Расширение на много решений и много агентов
Агенты часто взаимодействуют в несколько этапов с окружением, которое тоже содержит агентов. Иногда анализ одного решения одного агента можно расширить на такие ситуации. Есть два способа:
- Считать все решения, кроме одного, фиксированными, не адаптирующимися политики
- Считать политику нескольких решений одним решением, которое одновременно выбирает правило для всех конкретных решений.
Оба варианта имеют свои недостатки. Второй работает только в ситуациях с одним агентом, и даже тогда теряет некоторые подробности, ведь мы больше не сможем сказать, с каким решением ассоциирован стимул.
Первый вариант – не всегда уместная модель, ведь политики адаптируются. За исключением стимулов реакции, все остальные, которые мы обсуждали, определяются через гипотетические изменения окружения, вроде добавления или исключения наблюдения (ценность информации) или улучшения контроля (ценность контроля, инструментальные стимулы контроля). С чего бы политикам не меняться при таких изменениях?
Например, если противник знает, что у меня есть доступ к большей информации, он может вести себя осторожнее. В самом деле, больший доступ к информации в мультиагентных ситуациях часто может снизить ожидаемую полезность. Мультиагентные закономерности часто заставляют агентов вести себя так, как если бы у них был инструментальный стимул контроля за какой-нибудь величиной, хоть она и не соответствует критерию для одного агента. Например, субъект в архитектуре субъект-критик ведёт себя (выбирает действия) так, будто пытается контролировать состояние и получить большее вознаграждение, хоть определение инструментального стимула контроля для одного решения у одного агента не выполняется:
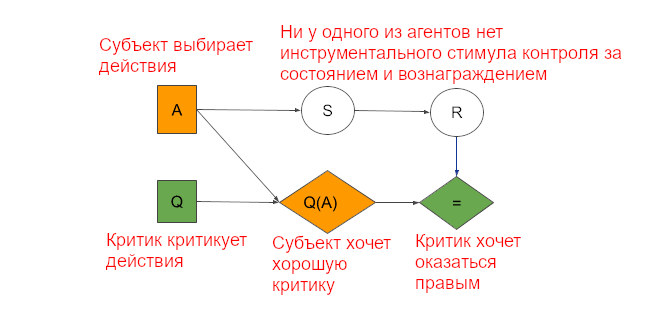
Субъект выбирает действие (A), критик – оценку каждого действия (Q). Действие влияет на состояние (S) и вознаграждение (R). Субъект хочет получить хорошую оценку (Q(A)), а критик хочет предсказать настоящее вознаграждение (=).
Поэтому, мы работаем над расширением анализа стимулов на ситуацию многих решений. Мы установили полный графовый критерий для ценности информации о вершинах-случайностях для диаграмм влияния многих решений с одним агентом и достаточной памятью. Ещё мы нашли способ моделировать забывание и рассеянность. Работе ещё есть куда продолжаться.
В статье про обнаружение агентов мы предложили условие для использования критерия одного решения: никакие другие механизмы не адаптируются на то же вмешательство.
Заключение
В этом посте мы показали, как каузальные модели и графы могут точно описывать и разные виды стимулов и позволяют их вывести. Кроме того, мы показали, почему невозможно вывести большую часть стимулов без каузальной модели мира. Некоторые естественные дальнейшие направления исследований:
- Расширить результат Миллера и пр. на другие виды стимулов. Установить, для каких из них каузальная модель строго необходима.
- Когда у системы есть стимул использовать наблюдение как прокси для другой величины? У нас есть подсказки к этому от ценности информации и стимулов реакции, но чтобы понять эти условия полностью, нужны дополнительные исследования.
- Разработка каузального дизайна механизмов для понимания степени влияния агентов и того, как мотивировать их на должные реакции.
- Продолжить расширение анализа стимулов на много решений и много агентов. Нужны общие определения и графовые критерии, которые будут работать в таких случаях.
В следующем посте мы применим анализ стимулов к проблеме неправильного определения вознаграждения и её решениям. Мы затронем манипуляцию, рекурсию, интерпретируемость, измерение влияния и придирчивые к пути цели.
- 1. Некоторые другие: вычислительные ограничения, выбор алгоритма обучения, интерфейс окружения.