Каузальная точка зрения на взлом вознаграждения
ИИ-системы обычно обучают оптимизировать целевую функцию, вроде функции потерь или вознаграждения. Однако, целевая функция иногда может быть определена неточно, так, что её можно будет оптимизировать, не исполняя ту задачу, которая имелась в виду. Это называют взломом вознаграждения. Можно сравнить это с ошибочными обобщениями, когда система экстраполирует (возможно) правильную обратную связь не так, как предполагалось.
В этом посте мы обсудим, почему вознаграждение, которое выдают люди, иногда может неверно отражать, что человек на самом деле хочет, и как это может привести к вредоносным стимулам. Ещё мы предложим несколько вариантов решения, описанных из подхода каузальных диаграмм влияния.
Почему люди могут вознаграждать неправильное поведение
В ситуации, когда сложно точно определить и запрограммировать функцию вознаграждения, ИИ-системы часто обучают при помощи человеческой обратной связи. Например, система рекомендации контента может оптимизировать лайки, а языковые модели обучают на обратной связи людей-оценщиков.
К сожалению, люди вовсе не всегда поощряют то поведение, которое на самом деле хотят. Например, человек может выдать позитивную обратную связь на выглядящий надёжно и аккуратно краткий пересказ текста, когда на самом деле он упускает какие-нибудь ключевые моменты:

Когда происходит неправильное определение вознаграждения, настоящая полезность для людей отделяется от обратной связи, которую получает система.
Ещё больше беспокойства вызывает то, что система может скрытно влиять на человека, чтобы тот выдавал положительную обратную связь. Например, рекомендательная система с целью максимизации вовлечённости может добиваться этого, влияя на предпочтения и настроение пользователей. В результате, человек выдаёт положительную обратную связь на ситуации, которые на самом деле не приносят ему полезности – это неправильное определение вознаграждения.
Каузальная модель ситуации показывает, что у агента может быть инструментальный стимул контроля (или, аналогично, намерение, поощряющий манипуляцию предпочтениями пользователя. Этот можно напрямую вывести из графа. Во-первых, на человека может влиять поведение агента, ведь чтобы его оценить, его сначала надо пронаблюдать. А во-вторых, агент может получить лучшую обратную связь, влияя на человека:

У агента есть инструментальный стимул контроля за предпочтениями человека, потому что агент может на них влиять, а они влияют на обратную связь агента.
Например, обычно мы читаем пост, прежде, чем решить, лайкнуть ли его. Сделав пользователя эмоциональнее, система, вероятно, может повысить вовлечённость. Для более длинного взаимодействия эффект сильнее, но стимул есть даже если всё взаимодействие занимает один шаг.
Масштабируемый надзор
Одно из предлагаемых решений неправильного определения вознаграждения – масштабируемый надзор. Человек снабжается агентом-помощником, который даёт советы по поводу того, какую выдать обратную связь. Агент-помощник наблюдает поведение обучающегося агента и может, например, указать на неточности в на первый взгляд аккуратном пересказе или предупредить о попытке манипуляции. Эта поддержка может усложнить для обучающегося агента обман или манипуляцию человеком:

Некоторые заметные направления, относящиеся к масштабируемому надзору: итерированные дистилляция и усиление, безопасность ИИ посредством дебатов, рекурсивное моделирование вознаграждения и конституционный ИИ.
К сожалению, у обучающегося агента всё ещё есть стимул обмануть человека или манипулировать его предпочтениями. Ведь предпочтения человека всё ещё соответствуют графовому критерию инструментального стимула контроля (они всё ещё находятся на ориентированном каузальном пути из поведения в обратную связь). Вдобавок, у обучающегося агента появляется ещё и стимул обмануть агента-помощника:

Важный вопрос касательно схем масштабируемого надзора: смогут ли более слабые агенты эффективно помогать в обучении более способных агентов? И можно ли это делать рекурсивно вплоть до агентов куда умнее людей? Это связано с вопросом о том, какие ситуации усиливают или снижают агентность.
Другое, более тонкое беспокойство – возможность сговора помощника с обучающимся агентом. Масштабируемый надзор построен на их противостоящем отношении: помощник как можно тщательнее критикует обучающегося агента, а тот стремится к поведению, которое критиковать не получится. Но что если вместо этого они решат объединиться и вместе манипулировать человеком? При некоторых возможных внутренних целях это может оказаться выгодно для обоих агентов. Тревожит, что агенты, использующие теории принятия решений вроде функциональной могут оказаться способны на кооперацию даже в ситуациях, которые в классических теориях принятия решений ведут к взаимному предательству.
Как мы объяснили в недавней статье, разные теории принятия решений можно характеризовать по тому, оптимизируют ли они вершины объектного уровня или вершины-механизмы (и по тому, какую операцию они используют и при условии какой информации). Например, агент-помощник, который использует функциональную теорию принятия решений, оптимизирует вершину-механизм своей политики, а не своё решение. Поэтому он понимает, что может повлиять на обучающегося агента так, чтобы тот кооперировал, даже если оба агента миопичны и оптимизируют только на текущем временном шаге:

Агент-помощник, использующий функциональную теорию принятия решений, оптимизирует вершину политики помощника, что даёт ему инструментальный стимул контроля за оформлением политики обучающегося агента ради собственной выгоды.
Лучшее понимание теории принятия решений и того, как на неё влияет обучение агента, может помочь нам избежать ситуаций, когда продвинутые агенты, которые должны присматривать друг за другом вместо этого сговорятся против нас.
Интерпретируемость
Интерпретируемость – хорошо известное направление, стремящееся к улучшению безопасности и правдивости ML-систем. Её раздел – механистическая интерпретируемость – стремиться понять, какие алгоритмы реализуются в нейросетях, т.е. понять их внутреннее «мышление».
Механистическая интерпретируемость может помочь предотвратить неправильное определение вознаграждения, позволив человеку дать обратную связь, основываясь на внутреннем мышлении агента, а не только на его поведении. Например, человек сможет понять, что агент планирует обман или манипуляцию и соответственно подправить вознаграждение:
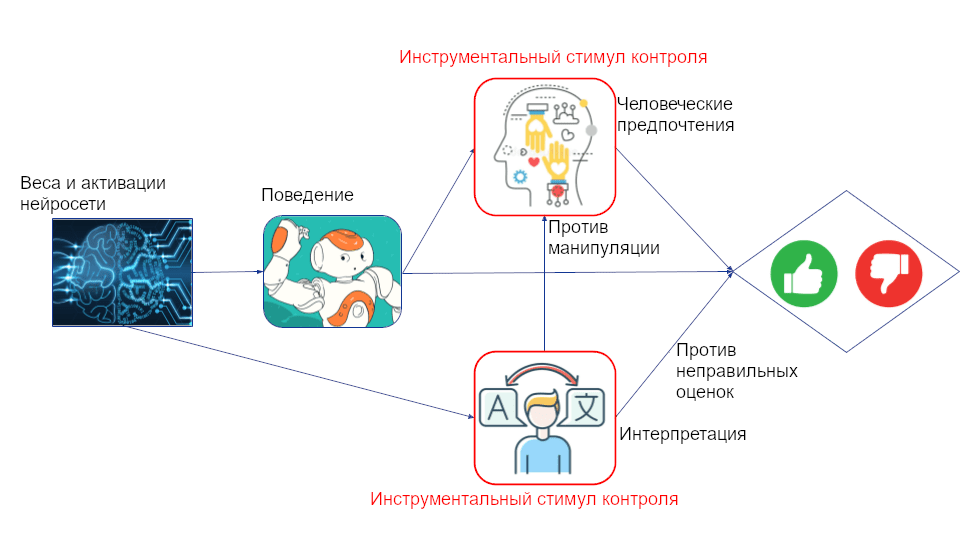
Каузальная структура получается весьма похожей на то, что было с масштабируемым надзором, только теперь совет зависит ещё и от того, что происходит внутри обучающегося агента. Как и там, инструментальный стимул контроля показывает, что агент всё ещё мотивирован обмануть и манипулировать человеком. Если мы посчитаем решением внутренности сети, то есть ещё и инструментальный стимул контроля за интерпретацией. Это указывает, что агент мотивирован перехитрить интерпретирующего, обфусцировав свои мысли.
Но надо ли их считать решением? Не естественнее ли сказать, что решение – это поведение агента? Мы можем прояснить это с помощью нашего определения агентности. Сначала добавим вершины-механизмы, показывающие, как каждая вершина объектного уровня связана со своими родительскими вершинами. Между двумя вершинами-механизмами есть каузальная связь, если переобучение системы при изменении в одной вершине приведёт к изменению в другой (когда все остальные механизмы в графе фиксированы).
Например, если бы у человека была другая политика обратной связи, и он вознаграждал другие виды поведения, то градиентный спуск привёл бы к другим весам и активациям сети (даже если бы все остальные механизмы в графе оставались неизменными). Так что мы проводим ребро от политики обратной связи к механизму внутренностей сети. Но то, как поведение агента зависит от внутренностей сети, зафиксировано и не зависит от политики обратной связи. Так что мы не проводим ребро от политики обратной связи в механизм поведения:
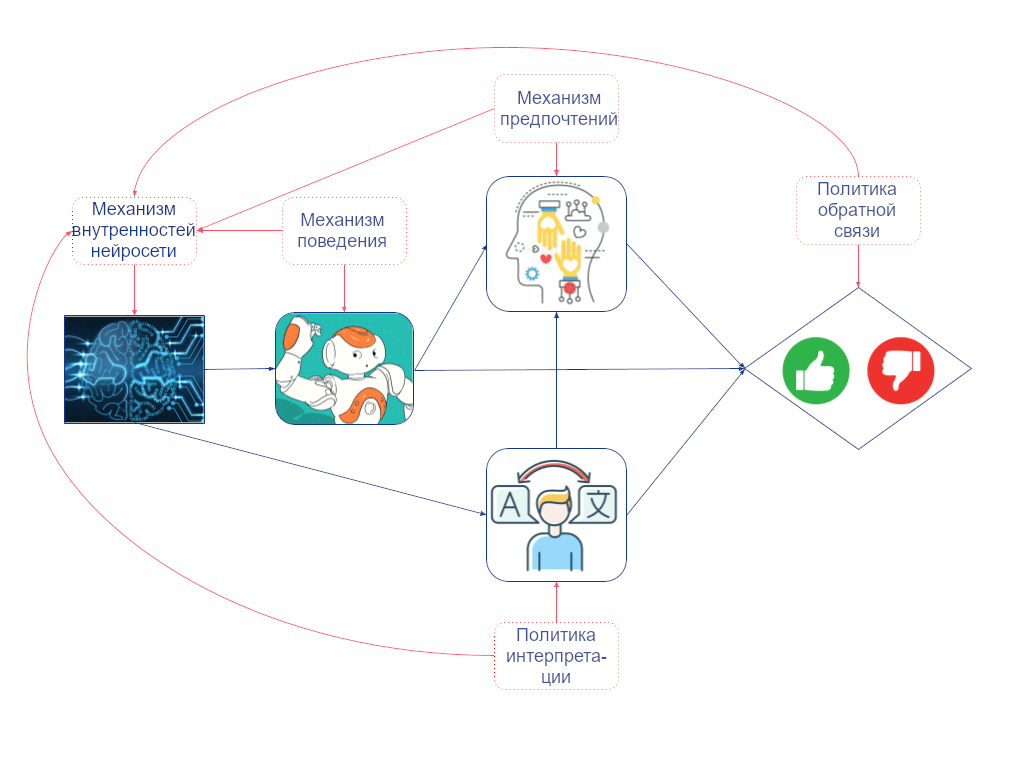
Так как у механизма внутренностей сети есть входящее ребро, а у механизма поведения – нет, только первый может быть решением, если мы смотрим на мир через этот набор переменных.
Измерение влияния
Мы уже увидели, что масштабируемый надзор и инструменты интерпретируемости могут помочь нам смягчить проблемы с определением правильной обратной связи для ИИ-агентов. Совсем другой подход к решению манипуляционного аспекта взлома вознаграждения – штрафовать агента за слишком большое влияние на предпочтения людей.
Как точно определить и измерить влияние – открытый вопрос. Очевидная идея – сравнить мир, в котором агент действует с гипотетическим миром, в котором он бездействует (или исполняет некоторое безопасное действие по умолчанию). Это можно проиллюстрировать двойным графом:
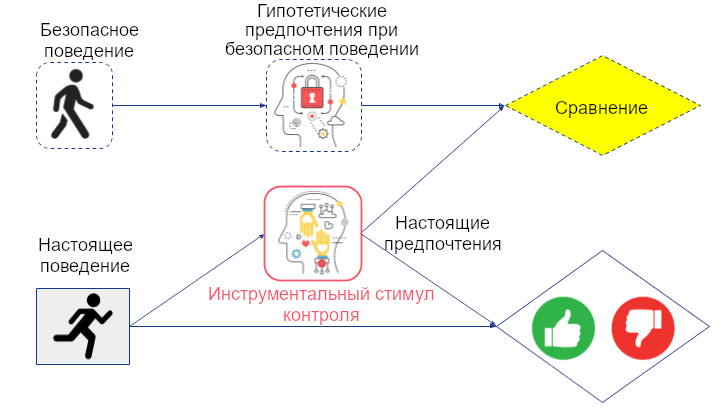
Чтобы измерить влияние агента на предпочтения человека, мы можем сравнить предпочтения с тем, какими бы они гипотетически были, если бы агент исполнял некоторое безопасное поведение.
Для такого измерения нам нужна каузальная модель того, как возможные решения агента меняют предпочтения пользователя. Кэрролл и пр. показали, что такую модель можно вывести из наблюдений за взаимодействием пользователя и рекомендательной системы на многих временных шагах. Масштабирование этого вверх с игрушечного окружения на реальные системы – важное направление предстоящей работы.
Но у измерения влияния есть свои проблемы. Во-первых, у системы всё ещё есть стимул повлиять на предпочтения пользователя. Это видно из инструментального стимула контроля на графе выше. Во-вторых, система мотивирована предотвратить изменения предпочтений пользователя от начальных. Следовательно, она может попытаться не дать пользователю обрести новые интересы, так как это может изменить его предпочтения.
Придирчивые к пути цели
Одно из определений манипуляции – намеренное и скрытное влияние. Рекомендательные системы могут ему соответствовать, ведь они обычно обучены влиять на пользователя любыми средствами, включая «скрытные», вроде обращения к его, пользователя, предрассудкам и эмоциям. При этом инструментальный стимул контроля за предпочтениями пользователя, как обсуждалось выше, может привести к тому, что влияние на пользователя будет намеренным. (Манипулятивны ли современные системы на самом деле неясно.)
Хорошая новость – что это намекает нам на путь к созданию точно не-манипулятивных агентов. Например, агент, который не пытается повлиять на предпочтения пользователя, согласно этому определению манипулятивным не будет, ведь намерения нет.
Придирчивые к пути цели – способ спроектировать агентов, которые не пытаются повлиять на конкретные части окружения. При наличии структурной каузальной модели с предпочтениями пользователя, вроде модели для измерения влияния, мы можем определить придирчивую к пути цель, которая потребует у агента не оптимизировать по путям, использующим предпочтения пользователя.
Чтобы вычислить придирчивый к пути эффект по решению агента, мы приписываем ценность решения по умолчанию там, где хотим, чтобы агент игнорировал эффекты своего настоящего решения. Это тоже можно описать двойным графом:

Важное различие с измерением влияния – что придирчивые к пути цели требуют у агента оптимизировать гипотетический сигнал обратной связи, который был сгенерирован гипотетической неизменённой версией предпочтений пользователя. Это полностью убирает инструментальный стимул контроля предпочтений пользователя и, получается, обходит проблему (намеренной) манипуляции предпочтениями.
В двух словах: измерение влияния пытается не повлиять, а придирчивые к пути цели не пытаются повлиять. То есть, придирчивые у пути цели не пытаются изменить предпочтения пользователя, но и не пытаются предотвратить заведение пользователем новых интересов.
Слабость этого подхода – он не помогает с дегенеративными петлями обратной связи, вроде эхо-комнат и фильтрующих социальных пузырей. Для компенсации их можно скомбинировать с некоторыми из техник выше (хотя комбинация с измерением влияния вернула бы некоторые из плохих стимулов).
Дальнейшая работа может распространить придирчивые к пути цели на ситуацию нескольких временных шагов и изучить, помогает ли этот подход с проблемой манипуляции на практике. Чтобы оценить это, сначала может понадобиться лучшее понимание человеческой агентности, позволившее бы измерять улучшения от менее манипулятивных алгоритмов.
Выводы
Взлом вознаграждения – одно из ключевых препятствий на пути к созданию способных и безопасных ИИ-агентов. В этом посте мы обсудили, как каузальные модели могут помочь с анализом проблемы неправильного определения вознаграждения и её решений.
Некоторые направления для дальнейшей работы:
- От чего зависит, какой теории принятия решений учатся агенты, можно ли на это повлиять, чтобы исключить координацию агентов против людей? Теория принятия решений языковых моделей будет зависеть как от предобучения, так и от файн-тюнинга.
- Интерпретируемость может помочь с обнаружением намеренного обмана и манипуляций. Эти понятия зависят от субъективной каузальной модели агента, т.е. от (часто неявной) модели, на основе которой агент принимает свои решения. Как нам совместить поведенческие эксперименты с механистической интерпретируемостью для выяснения субъектиыной каузальной модели агента? Больше об этом будет в следующем посте.
- Как выводить достаточно точные каузальные модели, чтобы предотвратить манипуляцию предпочтениями при помощи измерения влияния и придирчивых к пути целей?
- Какие метрики уместны для измерения того, помогает ли техника с обманом и манипуляциями? Для обмана есть бенчмарки правдивости. Вот для манипуляций всё хитрее, может понадобиться информация о мета-предпочтениях и/или лучшее понимание человеческой агентности.
- Распространить метод придирчивых к пути целей на много временных шагов и реализовать его в не настолько игрушечных окружениях.
В следующем посте мы ближе посмотрим на неправильные обобщения, которые могут заставить агентов плохо себя вести и преследовать неправильные цели даже при правильном определении вознаграждения.